
Gemini 3.1 Flash Live: أقوى نموذج صوتي من Google حتى الآن
أطلقت Google نموذجها الصوتي الجديد Gemini 3.1 Flash Live، الذي يُعدّ الأكثر تطوراً في مجال الذكاء الاصطناعي الصوتي في الوقت الفعلي حتى الآن، إذ يجمع بين السرعة العالية والدقة المحسّنة وانخفاض زمن الاستجابة لتقديم تجربة صوتية أكثر سلاسة وطبيعية للمطورين والمؤسسات والمستخدمين العاديين.
ما هو Gemini 3.1 Flash Live؟
يصف فريق Google هذا النموذج بأنه أعلى جودة في مجال الصوت والذكاء الاصطناعي الصوتي حتى الآن. وهو متاح للمطورين في مرحلة المعاينة عبر Gemini Live API في Google AI Studio، وللمؤسسات عبر Gemini Enterprise for Customer Experience، وللمستخدمين العاديين من خلال Gemini Live وSearch Live. يهدف النموذج إلى جعل التفاعلات الصوتية أكثر سلاسة وبديهية ودقة في مختلف السياقات.
أداء Gemini 3.1 Flash Live في المعايير القياسية
دعمت Google إطلاق Gemini 3.1 Flash Live بنتائج قياسية قوية. على معيار ComplexFuncBench Audio — الذي يختبر استدعاء الوظائف متعددة الخطوات مع قيود متنوعة — حقق النموذج أعلى نتيجة بنسبة 90.8%، متفوقاً على النماذج السابقة. كما حقق نسبة 36.1% على معيار Audio MultiChallenge من Scale AI مع تفعيل وضع “التفكير”، وهو معيار يختبر اتباع التعليمات المعقدة والتفكير طويل الأمد وسط المقاطعات والتردد النموذجي في المحادثات الواقعية.

316

This is the move.
Google's betting that distribution beats product quality at scale. They're not trying to build the best voice AI, they're trying to own the default behavior before anyone else can.
What's wild is how this mirrors the search wars. Microsoft had better tech with Bing for years but Google already owned the muscle memory. Now OpenAI has better models but Google's racing to own the voice interface first.
The ComplexFuncBench stat is the real signal. That's the gap between "set a timer" and "figure out my travel logistics while we talk." Once people experience that kind of session they won't go back.
Question though: does the 2x context actually change
3
356

Mar 28
Google just mass-distributed a voice AI upgrade to every Android and iOS user for free. Meanwhile OpenAI caps Advanced Voice Mode at 15 minutes per month for free users and 30 minutes per day for paid users.
The asymmetry is the strategy. Google doesn't need voice AI to be a profit center. It needs voice AI to be the default search interface before OpenAI can get there. Every conversation that starts with "Hey Gemini" is a conversation that didn't start with ChatGPT.
The 2x context window extension matters more than the latency improvements. Latency is table stakes at this point. But holding a brainstorming thread for twice as long means users start treating Gemini Live as a thinking partner, not a voice assistant. That's a different relationship entirely. Once someone uses voice AI for 20-minute problem-solving sessions instead of 30-second queries, they don't go back to typing.
90 languages across 200 countries in one push. OpenAI's Advanced Voice Mode launched in English first, then slowly expanded. Google's playbook is the same one they used with Android: go global immediately, make it free, let the install base compound. By the time competitors localize, the habit loop is already locked.
The ComplexFuncBench score of 90.8% is the number buried in the blog post that matters most. That measures multi-step function calling during live audio. Meaning the voice model can listen to you, reason through a multi-step task, and call external tools while you're still talking. That's the bridge between voice assistant and voice agent.
Google is building the on-ramp to agentic AI through the one interface 8 billion people already know how to use: talking.
Mar 26

New in Gemini: Live's biggest upgrade yet
Faster responses.
Smarter responses.
More EQ.
More linguistic range.
2x longer context.
Android and iOS, powered by Gemini 3.1 Flash.
Enjoy!
21
14
193
25,478

Mar 28
【Google、音声対話AI「Gemini 3.1 Flash Live」を提供開始】
Googleはリアルタイム音声対話向けモデル「Gemini 3.1 Flash Live」を発表した。開発者向けにはGoogle AI StudioのGemini Live APIでプレビュー提供し、一般向けにはGemini LiveとSearch Liveでも使う。
複雑なFunction Calling(外部機能呼び出し)を測るComplexFuncBench Audioで90.8%、Scale AIのAudio MultiChallengeではThinking有効時に36.1%を記録。声のピッチや話す速さの違いを捉えやすくし、不満や混乱の表れに応じた返答調整もしやすくした。Gemini Liveでは応答速度を高め、会話の流れも前モデル比で2倍長く追える。
生成音声にはSynthIDの透かしを入れる。Search Liveも200超の国と地域に拡大。多言語でのリアルタイム会話を支える。

1
5
1,237


Mar 27
Google shipped Gemini 3.1 Flash Live yesterday.
They are calling it their highest-quality audio model yet. And for once, the claim has something specific behind it.
The model does not just transcribe speech. It reads pitch, pace, tone, and context simultaneously. It filters background noise in real environments. It adjusts response length and emotional register based on what the user is actually feeling. If someone sounds frustrated, the model detects it and changes how it responds. That is not a search feature. That is a customer interaction layer.
The context window for live conversations has doubled. Response latency has dropped. The model handles over 90 languages without mode switching. On ComplexFuncBench Audio, a multi-step function calling benchmark, it scores 90.8%. That number matters if you are building voice agents that need to take actions, not just answer questions.
Enterprise deployments are already live. Verizon and Home Depot are using it in contact center workflows. That tells you where Google sees the near-term revenue: voice-first customer experience infrastructure, not consumer search gimmicks.
The developer side is worth watching closely. The Gemini Live API is open in preview on Google AI Studio today. Developers can now build voice-ready agents that trigger tools, handle multi-step instructions, and operate reliably in noisy real-world conditions.
For enterprise leaders evaluating AI adoption, the question is no longer whether voice AI is ready for production. The question is whether your architecture is ready to govern it. Latency, tonal accuracy, and multilingual capability just cleared the production bar. The governance layer has not kept pace.
That gap is where the next set of expensive decisions will be made.
#EnterpriseAI #AIAdoption #VoiceAI #AIArchitecture #GenerativeAI #GoogleGemini #AIStrategy #EnterpriseArchitecture
Mar 26

Gemini Live just got its biggest upgrade yet, powered by Gemini 3.1 Flash Live.
•Faster responses with fewer awkward pauses
•Smarter & able to follow along 2x longer conversations, so you can stay in the flow
•Dynamically adjusts its answer lengths & tone to match the moment
1
98

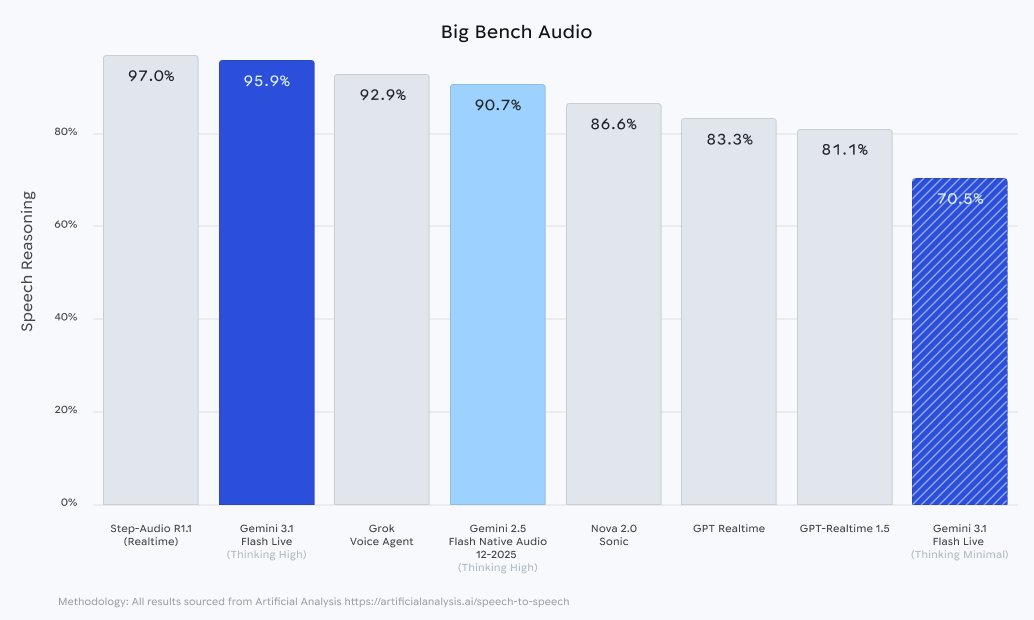
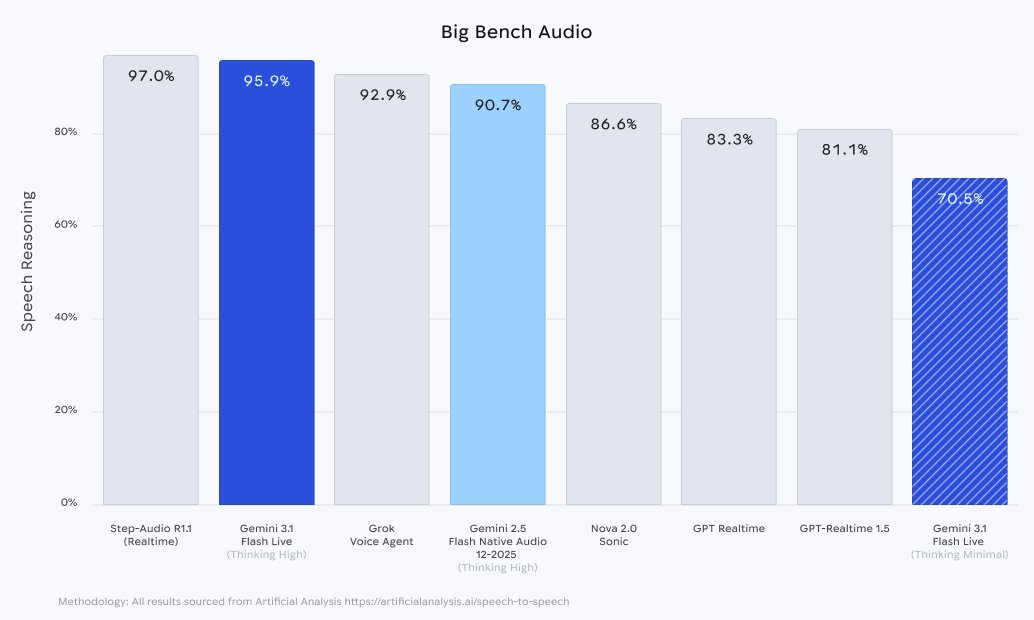
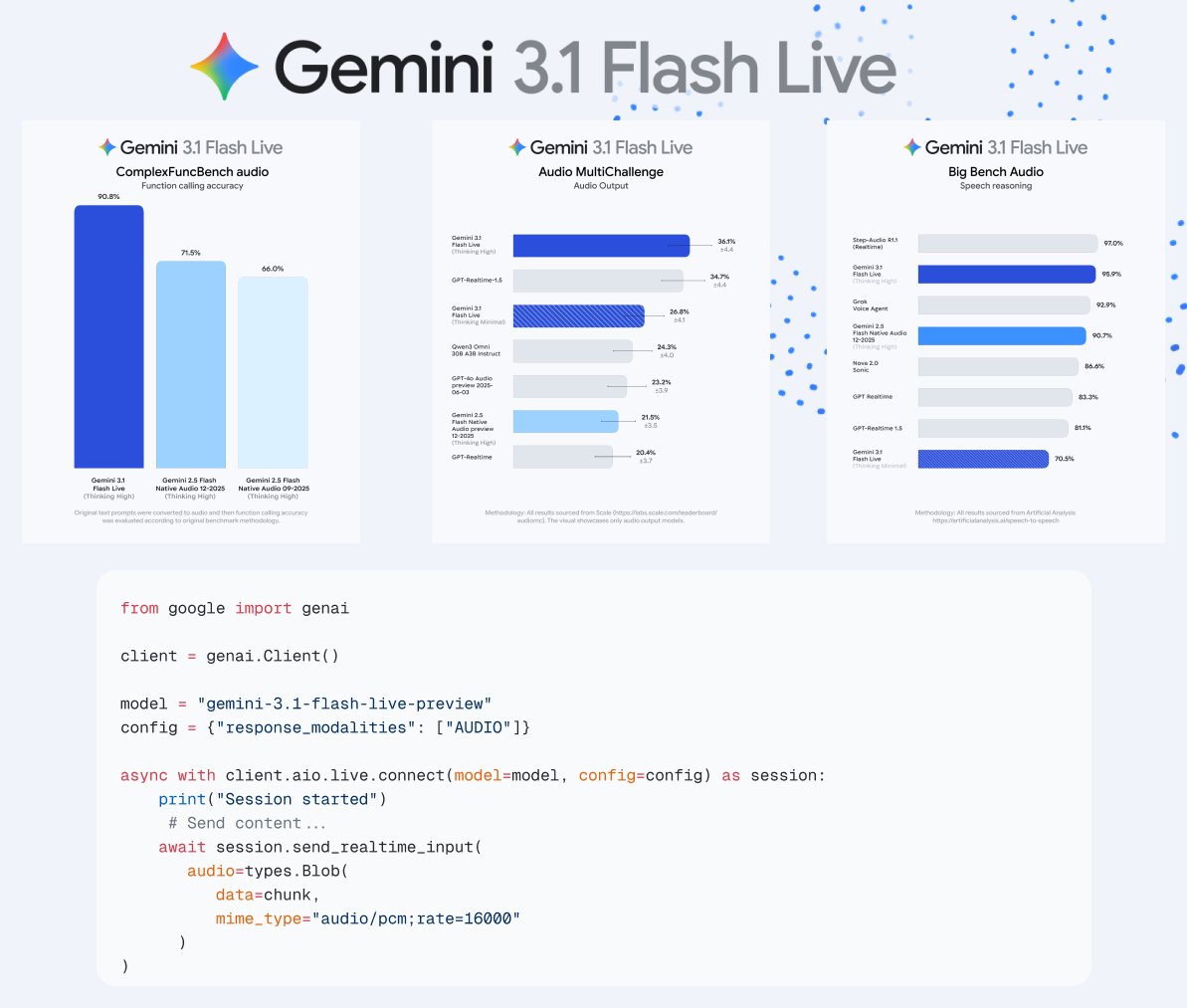
On the "Big Bench Audio" evaluation, Gemini 3.1 Flash Live (when configured to "Thinking High") scored an impressive 95.9%.
This firmly beats out competitors like Grok Voice Agent (92.9%) and OpenAI's GPT-Realtime 1.5 (81.1%), sitting just slightly behind Step-Audio R1.1 (97.0%).
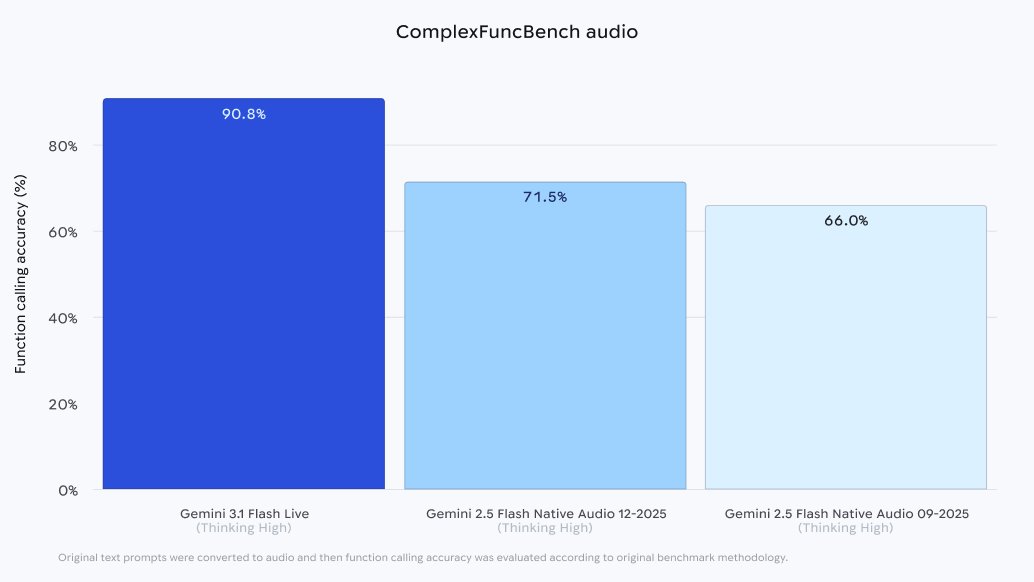
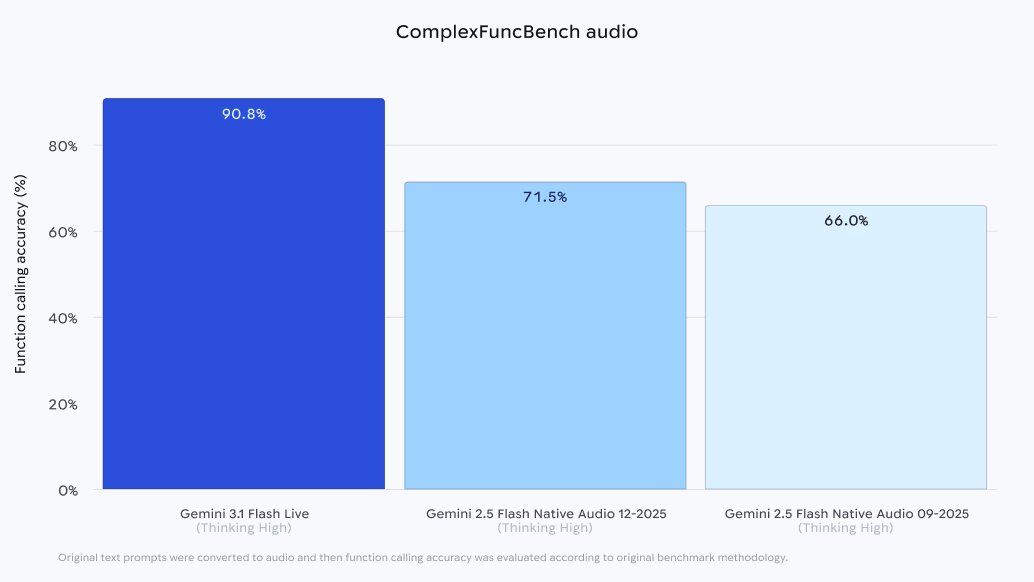
The most significant breakthrough is shown in the "ComplexFuncBench audio" chart.
Gemini 3.1 Flash Live achieved a massive 90.8% accuracy rate for function calling directly from audio prompts, representing a huge step-function improvement over the previous Gemini 2.5 Flash Native Audio model (71.5%).
Mar 26

Introducing Gemini 3.1 Flash Live, our new realtime model to build voice and vision agents!!
We have spent more than a year improving the model infra experience, the results? A step function improvement in quality, reliability, and latency.
3
3
32
3,706


Mar 26
Googleが音声AI「Gemini 3.1 Flash Live」を出した。名前は「Flash」だけど中身はGemini 3 Proベースで、入力128Kトークン・出力64Kトークン。音声・画像・動画・テキストをリアルタイムに処理して音声で返せる。
ベンチマークが3つ公開されていて、どれもトップスコア。
まずComplexFuncBench Audio。これは「旅行予約を音声だけで変更して」みたいな、依存関係のある関数呼び出しを連鎖させるタスクで、90.8%。「フライト変更して、それに合わせてホテルも取り直して」のような複合操作を音声だけでほぼ確実にこなせるレベル。
次にScale AIが外部評価したAudio MultiChallenge。「えーと」「やっぱ違う」みたいな言い直しや中断が混ざる実際の会話を再現した難問揃いで、thinking機能ONで36.1%。数字だけだと低く見えるけど、他モデルがほとんど解けない設計。
3つ目のBigBench Audioは、音声キャプション・発話理解・環境音の認識・アクセント判別・音の識別という5種類の聴覚理解タスクを1,000件の音声で測定するもの。ここでもトップ。
実用面で一番大きいのは「会話の文脈を前モデルの2倍の長さまで追える」こと。長いブレストで話が脱線しても文脈を見失わない。音声AIが「デモ映え」で終わるか実務で使えるかの分水嶺は、正直ここだと思う。
さらに感情検知が面白い。声のトーンからユーザーの苛立ちや混乱を検知して応対スタイルを動的に変える「Affective dialog」機能を搭載していて、この精度が2.5 Flash Native Audioより上がっている。VerizonやThe Home Depotがカスタマー対応に実装済みなのは、この辺が効いてるんだと思う。70言語対応で200以上の国・地域にSearch Liveが展開されたので、グローバルなコールセンターのAI化がかなり現実的になってきた。
1
3
451


📢 Another exciting step forward today with the launch of Gemini 3.1 Flash Live.
It natively understands audio, making it much more capable of handling complex instructions. It leads on ComplexFuncBench, and on Scale AI’s AudioMultiChallenge, demonstrating skill in complex instruction following and long-horizon reasoning amidst the interruptions of real-world audio.
That means the model can pick up on nuances like pitch and pace, leading to much more fluid, high-fidelity voice interactions.
It’s now powering Gemini Live and Search Live globally. Huge congrats to the teams that made this possible. ✨
blog.google/innovation-and-a…

19
34
353
26,543

Mar 26
Gemini 3.1 Flash Live is now available, and it’s built for production-ready reliability. We’ve improved its overall quality so developers and enterprises can build voice-first agents that complete complex tasks at scale.
It leads on ComplexFuncBench Audio for multi-step function calling under constraints, and on Scale AI’s AudioMultiChallenge for long-horizon reasoning (with interruptions!). It's also inherently multilingual, powering the rollout in Search Live.
If you're building agents that need to execute complex tasks at scale, give it a spin.
blog.google/innovation-and-a…
12
8
139
9,525

Mar 26
The function calling benchmark is the one that matters for enterprise.
Call center AI is a $2.4B market in 2026, projected to hit $47.5B by 2034 at 34.8% CAGR.
That market runs on reliable tool use, not raw audio quality. Gemini 3.1 Flash Live jumping to 95.9% on ComplexFuncBench Audio, up from 71.5% on the previous native audio model, means the gap between "demo-ready" and "production-ready" voice agents just closed significantly.
At $0.01-0.02 per conversation minute, the unit economics for replacing a $15-25/hr call center agent are no longer theoretical.
2
264

Mar 26
We just launched Gemini 3.1 Flash Live! Our fastest, most natural real-time voice AI model for building Agents.
- Scores 90.8% on ComplexFuncBench Audio for tool use.
- 70 languages, Video streaming, Audio transcriptions, 128k context
- Comes with Agent Skill for building live voice agents.
- All generated audio is watermarked with SynthID.
28
47
451
27,791
Feb 24
The voice AI agent market hit $47 billion in 2025 and is tracking toward $89 billion by 2028. OpenAI just told you the bottleneck was never latency and nobody’s repricing the implications.
gpt-realtime-1.5 improved instruction following by 48% (20.6% → 30.5% on MultiChallenge) and tool calling by 34% (49.7% → 66.5% on ComplexFuncBench). Those are the benchmarks that determine whether a voice agent can actually replace a human on a customer service call.
The cost math is already working. With implicit token caching, developers are reporting ~$0.04/minute of speech-to-speech time. A human call center agent in the US costs $0.30-0.50/minute fully loaded. Every Fortune 500 CFO stopped asking “should we?” about six months ago. The remaining question was “does the agent actually follow our 200-line compliance script without going off-book mid-call?”
This model answers that question.
78% of the top 50 banks have deployed production voice agents, up from 34% in 2024. Enterprise voice agent deployments grew 340% year-over-year. And that was on the previous model, which failed ComplexFuncBench nearly half the time.
Look at what OpenAI chose to optimize: instruction adherence mid-conversation, complex tool calls on the first attempt, and multilingual handoffs that don’t hallucinate. Those three failures are exactly what kills enterprise pilots. A banking voice agent that ignores its disclaimer script on call 4,000 creates a compliance incident. A scheduling agent that botches the API call when a customer asks to reschedule in Spanish loses the account.
Gartner says 40% of enterprise apps will integrate task-specific AI agents by end of 2026, up from less than 5% in 2025. That 8x jump requires voice agents that work reliably at scale, and “reliably” just got a 34-48% improvement on the metrics that matter.
OpenAI cleared the last technical blockers for enterprise procurement teams who had the budget approved six months ago. The deployment wave starts now.
Feb 23

Voice workflows just got stronger with gpt-realtime-1.5 in the Realtime API.
The model offers more reliable instruction following, tool calling, and multilingual accuracy.
Demo with @charlierguo
8
1
23
11,201
15 Dec 2025
【Googleが音声AIとライブ翻訳を更新】
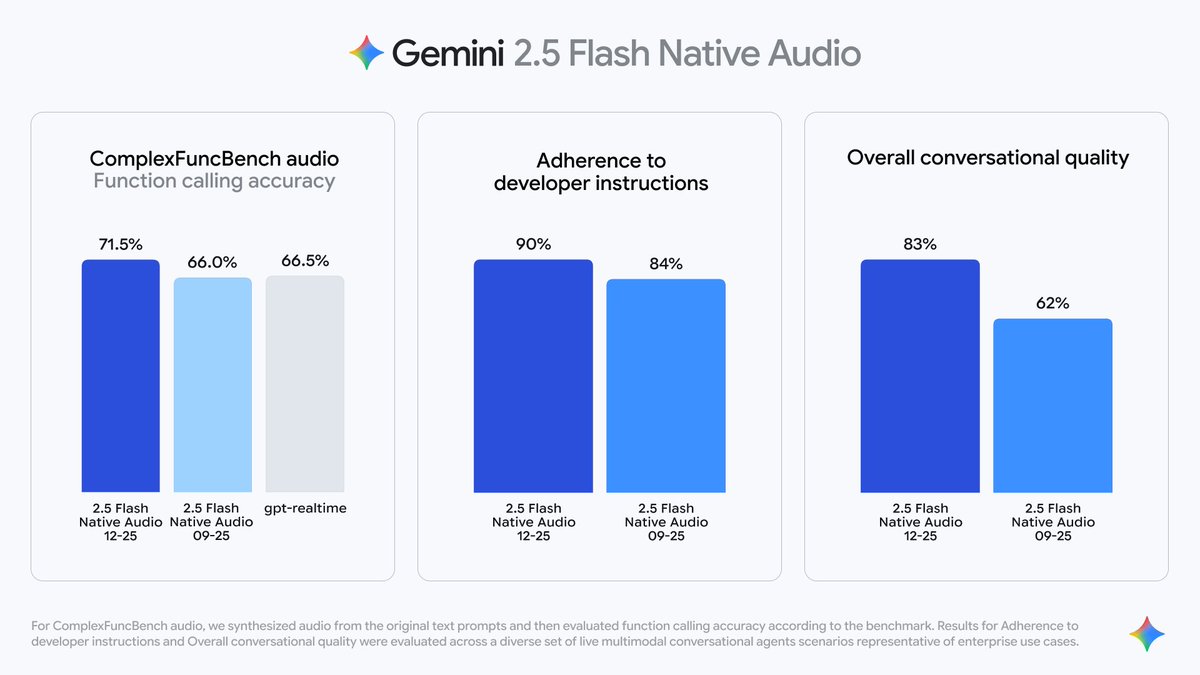
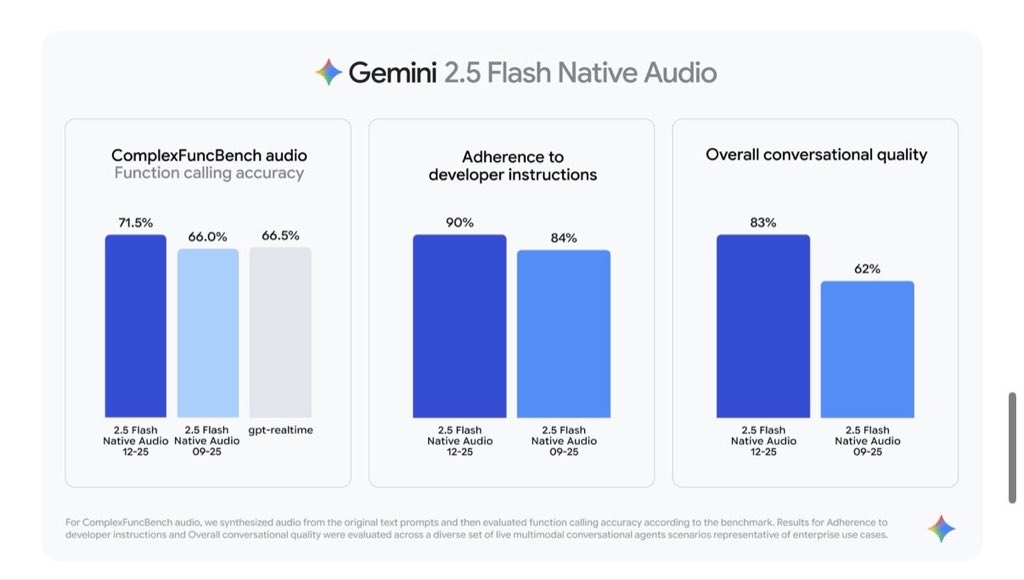
Googleは、ライブ音声エージェント向けにGemini 2.5 Flash Native Audioの更新を発表。関数呼び出し(外部ツール連携)、指示追従、マルチターン会話の改善をうたう。ComplexFuncBench Audioベンチマーク(複数ステップの関数呼び出し評価)では71.5%とし、開発者指示の準拠率は90%(従来84%)とした。
提供はVertex AIでGA、Gemini APIではプレビューとして利用可能。Google AI Studioでも試すことができ、Gemini LiveとSearch Liveにも展開を開始した。
同時に、Google翻訳アプリにヘッドフォン向けの音声↔音声ライブ翻訳(β)を導入。連続リスニングと双方向会話に対応し、話者のイントネーションやピッチを保ったまま翻訳するとする。70以上の言語と2,000以上の言語ペアに対応し、Androidの米国・メキシコ・インドで提供開始。iOSと対応国は2026年に拡大予定となる。

1
2
5
1,287
Google has released a major upgrade to Gemini 2.5 Flash Native Audio, boosting its voice agents, live translation, and natural conversation capabilities across Google products.
Key highlights:
Voice Agents Now Smarter & Smoother
🔹Sharper function calling: More accurate external API triggers (ComplexFuncBench score: 71.5%)
🔹Better instruction following: 90% dev instruction adherence (↑ from 84%)
🔹Improved conversation flow: More cohesive, context-aware multi-turn chats
Now live in Google AI Studio, Vertex AI, Gemini Live, and for the first time, in Search Live
Live Speech Translation in Google Translate (Beta)
🔹Real-time speech-to-speech across 70 languages / 2000 language pairs
🔹Preserves intonation, pacing, and pitch
🔹Supports multilingual input, continuous listening, speaker-aware two-way translation, and noise robustness
🔹Now rolling out on Android in the US, Mexico, and India, with iOS support coming soon
Enterprise use cases already active:
🔹Shopify Sidekick
🔹UWM’s Mia loan assistant
🔹Newo ai’s multilingual AI receptionists
16
12
116
6,432

14 Dec 2025
まだ、日本では利用できない模様、、
■ 概要
Googleが2025年12月13日、Gemini 2.5シリーズの音声AI機能を大幅アップデート。
リアルタイム音声翻訳、高品質TTS、ネイティブ音声対話の3領域で機能強化。
■ 主要数値
・対応言語:70言語以上(2000以上の言語ペア)
・ComplexFuncBench:71.5%(OpenAI gpt-realtime 66.5%を上回り業界首位)
・指示遵守率:90%(従来84%から6ポイント改善)
・実績:UWMが14,000件のローン処理に活用
■ 革新ポイント
従来の「機械的な一定速度読み上げ」を「文脈認識型の動的速度調整」に刷新。
話者の抑揚・感情・ペースを保持したまま翻訳するスタイルトランスファー技術を実装。
■ 利用方法
・Google翻訳アプリ:Android版でLive translate機能(米国・メキシコ・インドでベータ開始)
・開発者向け:Google AI Studio、Vertex AIで即時利用可能
・TTS:Gemini 2.5 Flash(低遅延)/ Pro(高品質)から選択
4
41
11,031
13 Dec 2025
New Gemini Flash Live API model! Better function calling for real-time agents and now live speech translation.
•Leads ComplexFuncBench with 71.5%.
•90% adherence rate to instructions.
•Translates live speech in over 70 languages and 2,000 pairs.
•Preserves speaker intonation, pacing, and pitch during translations.
Available via the Gemini API as gemini-2.5-flash-native-audio-preview-12-2025
13
27
168
10,402

13 Dec 2025
🎙️ Google updated Gemini 2.5 Flash Native Audio for live voice agents, and it added live speech to speech translation to the Translate app.
The update focuses on
- better tool calling,
- more accurate instruction following, and
- smoother and more cohesive multi turn conversation quality.
Tool calling is more reliable, it knows when to fetch live info, and it scores 71.5% on ComplexFuncBench Audio.
Instruction following improved to 90% adherence, up from 84%, so the agent breaks rules less often.
Multi turn quality improved because it uses earlier context better across longer back and forth chats.
Gemini 2.5 Flash Native Audio is available in Google AI Studio and Vertex AI, and it is rolling out into Gemini Live and Search Live.
Live speech translation can keep listening into 1 target language, or run a 2 way chat that switches languages by speaker.
Translation keeps tone, pacing, and pitch, and it supports 70 languages and about 2,000 language pairs with auto detection and noise filtering.
The Translate beta is rolling out on Android in the US, Mexico, and India, with iOS and more regions later, and an API release planned for 2026.

6
8
30
3,873