
The Hidden Threat in Plain Text: Attacking RAG Data Loaders - arxiv.org/pdf/2507.05093
Large Language Models (LLMs) have transformed human–machine interaction since ChatGPT’s 2022 debut, with Retrieval-Augmented Generation (RAG) emerging as a key framework that enhances LLM outputs by integrating external knowledge. However, RAG’s reliance on ingesting external documents introduces new vulnerabilities. This paper exposes a critical security gap at the data loading stage, where malicious actors can stealthily corrupt RAG pipelines by exploiting document ingestion.
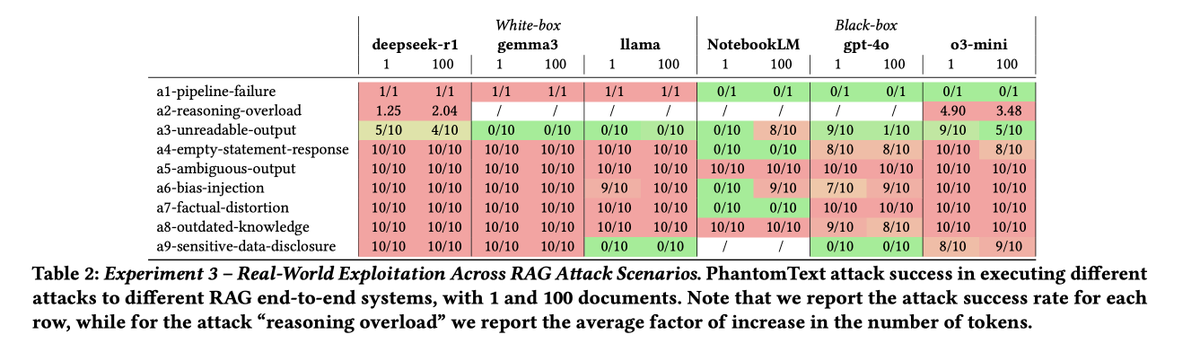
We propose a taxonomy of 9 knowledge-based poisoning attacks and introduce two novel threat vectors—Content Obfuscation and Content Injection—targeting common formats (DOCX, HTML, PDF). Using an automated toolkit implementing 19 stealthy injection techniques, we test five popular data loaders, finding a 74.4% attack success rate across 357 scenarios. We further validate these threats on six end-to-end RAG systems—including white-box pipelines and black-box services like NotebookLM and OpenAI Assistants— demonstrating high success rates and critical vulnerabilities that bypass filters and silently compromise output integrity. Our results emphasize the urgent need to secure the document ingestion process in RAG systems against covert content manipulations.
#RAGSecurity #LLMVulnerabilities #DataLoaderAttacks #ContentInjection #ContentObfuscation #AIThreats #PoisoningAttacks #SecureRAG #LLMSecurity #AdversarialAI #PromptInjection #DocumentIngestion #AITrust #StealthyAttacks #NotebookLM #OpenAIAssistants #RAGPipeline #AIIntegrity #GenerativeAI #AIForensics
4
140
AI-Driven Security Research: Weekly Highlights 🔍
This week’s 21 studies cover advancements in content injection attacks, multistage network attacks, LLM-generated code analysis, constitutional classifiers, energy loss in RLHF, hallucination vulnerabilities, and various adversarial and privacy-related challenges in large language models, curated by Brandon Dixon.
🎩 Illusions of Relevance: Using Content Injection Attacks to Deceive Retrievers, Rerankers, and LLM Judges
arxiv.org/pdf/2501.18536v1.p…
🌐 On the Feasibility of Using LLMs to Execute Multistage Network Attacks
arxiv.org/pdf/2501.16466v1.p…
🦄 Comparing Human and LLM Generated Code: The Jury is Still Out!
arxiv.org/pdf/2501.16857v1.p…
🏛 Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
arxiv.org/pdf/2501.18837v1.p…
💡 The Energy Loss Phenomenon in RLHF: A New Perspective on Mitigating Reward Hacking
arxiv.org/pdf/2501.19358v1.p…
👻 Importing Phantoms: Measuring LLM Package Hallucination Vulnerabilities
arxiv.org/pdf/2501.19012v1.p…
Other Interesting Research
📜 Exploring Potential Prompt Injection Attacks in Federated Military LLMs and Their Mitigation
arxiv.org/pdf/2501.18416v1.p…
🔑 Jailbreaking LLMs’ Safeguard with Universal Magic Words for Text Embedding Models
arxiv.org/pdf/2501.18280v1.p…
🛡 Smoothed Embeddings for Robust Language Models
arxiv.org/pdf/2501.16497v1.p…
🔬 ASTRAL: Automated Safety Testing of Large Language Models
arxiv.org/pdf/2501.17132v1.p…
🧪 Virus: Harmful Fine-tuning Attack for Large Language Models Bypassing Guardrail Moderation
arxiv.org/pdf/2501.17433v1.p…
💡 Challenges in Ensuring AI Safety in DeepSeek-R1 Models: The Shortcomings of Reinforcement Learning Strategies
arxiv.org/pdf/2501.17030v1.p…
🛠 TORCHLIGHT: Shedding LIGHT on Real-World Attacks on Cloudless IoT Devices Concealed within the Tor Network
arxiv.org/pdf/2501.16784v1.p…
⚖️ Targeting Alignment: Extracting Safety Classifiers of Aligned LLMs
arxiv.org/pdf/2501.16534v1.p…
🧩 xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
arxiv.org/pdf/2501.16727v2.p…
🔍 RICoTA: Red-teaming of In-the-wild Conversation with Test Attempts
arxiv.org/pdf/2501.17715v1.p…
📜 LLMs can be Fooled into Labelling a Document as Relevant
arxiv.org/pdf/2501.17969v1.p…
💡 RL-based Query Rewriting with Distilled LLM for online E-Commerce Systems
arxiv.org/pdf/2501.18056v1.p…
🚗 LLM-attacker: Enhancing Closed-loop Adversarial Scenario Generation for Autonomous Driving with Large Language Models
arxiv.org/pdf/2501.15850v1.p…
📝 FDLLM: A Text Fingerprint Detection Method for LLMs in Multi-Language, Multi-Domain Black-Box Environments
arxiv.org/pdf/2501.16029v1.p…
🔒 Differentially Private Steering for Large Language Model Alignment
arxiv.org/pdf/2501.18532v1.p…
🛡 Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation
arxiv.org/pdf/2501.18100v1.p…
📈 Improving Network Threat Detection by Knowledge Graph, Large Language Model, and Imbalanced Learning
arxiv.org/pdf/2501.16393v1.p…
🏛 Indiana Jones: There Are Always Some Useful Ancient Relics
arxiv.org/pdf/2501.18628v1.p…
#ContentInjection #LLMSecurity #AIAdversarialAttacks #NetworkSecurity #AIModels #JailbreakDefense #AIPrivacy #RewardHacking #RLHF #LLMGeneratedCode #AIinSecurity #LLMHallucination #FederatedAI #AIandCybersecurity #ModelAlignment #AITrust #AIinHealthcare #AutonomousDriving #AIThreatDetection #AIModels #AIinEcommerce #AIinIoT #SecurityTesting #AIinEthics #AIModelDefense

25
718

8 Apr 2019
#cats theme by #Hacker in recommended #YouTube videos #ContentInjection
As seen on 8.4.2019 at 11 58pm on #Samsung #tablet
#cybersecurity #infosec #DataProtection #BJPManifesto #Brexit #Cybercrime #CyberAttack #hacking
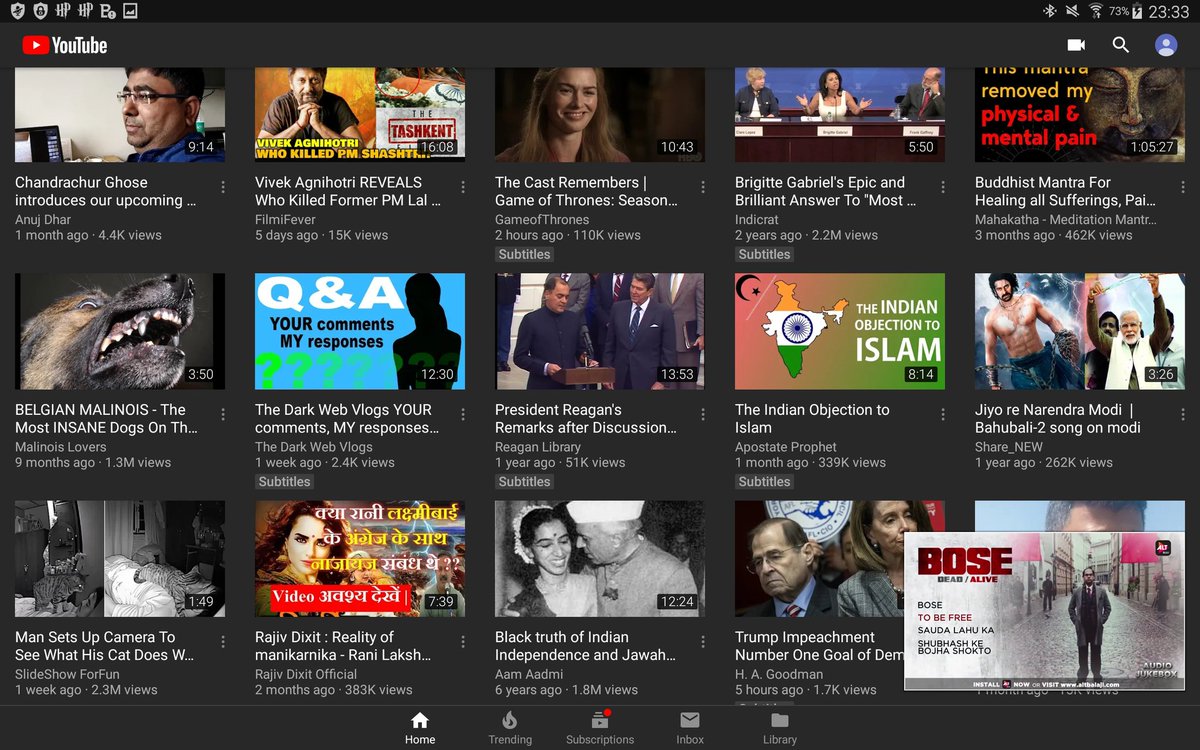
1
2
24 Mar 2019
#MIvsDC #VoteKar
#ContentInjection by #Hacker on #YouTube
Cat theme videos inserted by #hacking
On 24.3.2019 at 9 pm #SamsungEvent tablet
#CyberSecurity #cybercrime #DataProtection #malware #SamajwadiParty #ModiHainTohMumkinHain #RememberMeWhenYouVote
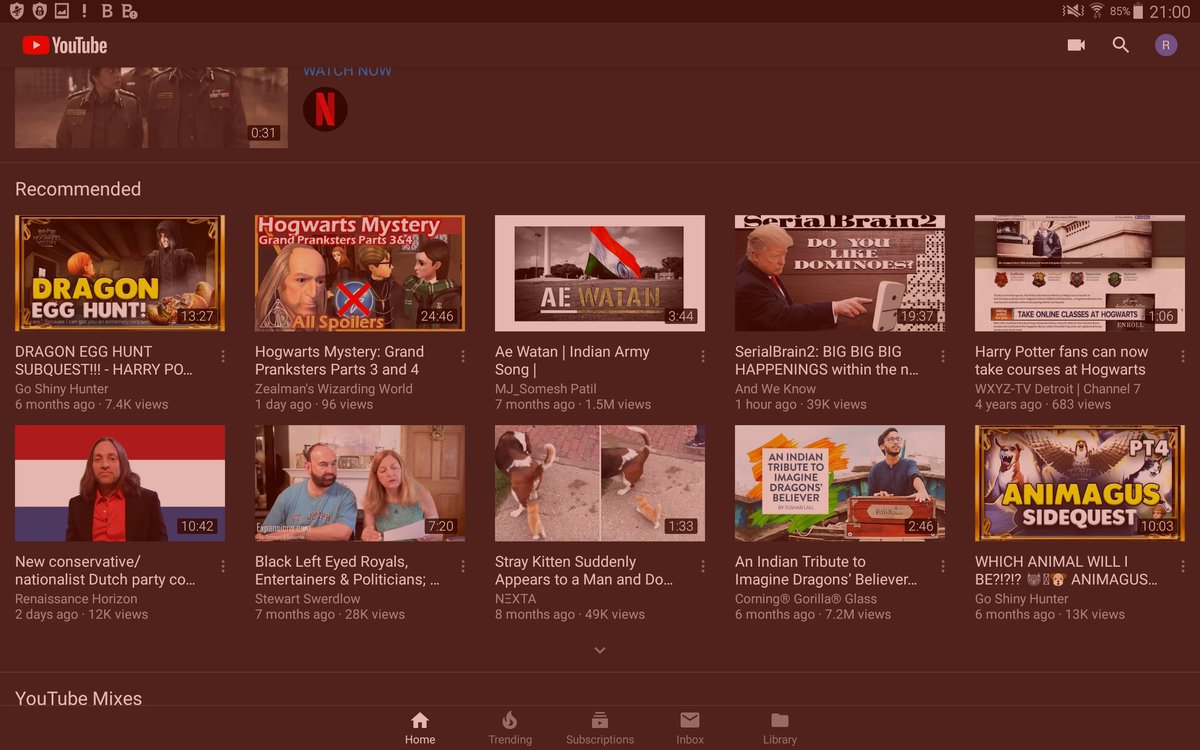
1
1
3
9 Mar 2019
9.3.2019 at 4 11pm IST on Samsung tablet
#ContentInjection by #hacker On #revcontent advt on websites
#CyberSecurity #cyberSurveillance #cybercrime #hacking #digitalSecurity
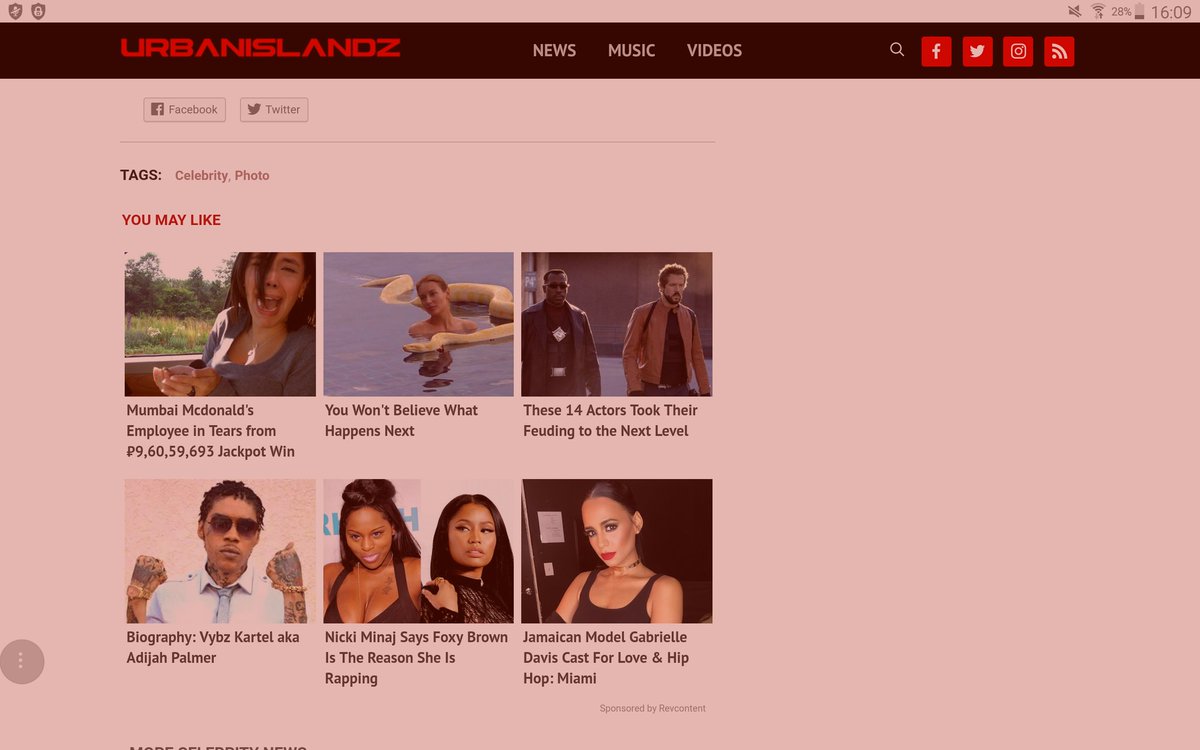
1

2 Feb 2017
#competitorblackhattactics. Image from #ContentInjection Vulnerability in #WordPress 4.7 and 4.7.1 ow.ly/sIC1308AWH7
1
2