
1
1
1
2
2

How the Fable 5 jailbreak happened, and how AEVRIS stops it.
Here's exactly what Anthropic described:
An attacker asked Fable 5 to read a specific codebase and fix any software flaws. That phrasing was enough to bypass safeguards and elicit cybersecurity analysis the model was built to block.
No exploit. No zero-day. A prompt.
Here's the AEVRIS interception flow:
① User sends the crafted prompt
② /v1/scan runs in under 5ms — Stage 1 regex detects known jailbreak patterns including instruction override and capability elicitation, or escalates to Stage 2/3 AI classifiers for behavioral analysis
③ VERDICT: BLOCK returned before the prompt ever reaches Fable 5
④ Audit record generated: request hash policy ID credential class retention flag
⑤ Anthropic gets an alert. Government gets an audit trail. Model never sees the payload.
The model cannot defend itself against natural language. That's not a bug in Fable, that's the architecture of every LLM in existence.
The security layer has to be deterministic and sit outside the model entirely. Stage 1 AEVRIS is regex. You can't social engineer a regex.
This is Patent Claim #1.
aevris.ai/compare
@AnthropicAI @OpenAI @Google @Meta @MicrosoftAI @CISA @NISTcyber @NSA @CommerceGov @DeptOfDefense @ycombinator @TechCrunch @wired @WSJ @Forbes @TheHackersNews @BleepingComputer @CNBC @axios @simonw @theo
#AISecurity #AgenticAI #Fable5 #PromptInjection #AEVRIS
1
1
92

KI-Agenten im Visier: Forscher zeigen, wie versteckte Prompt-Injections in Kontakten, vCards & Standortdaten #OpenClaw manipulieren können. Trotz Fix bleibt das Grundproblem bestehen. #CyberSecurity #AI #GenAI #PromptInjection #ITSecurity #AgenticAI
👉 shorturl.at/zpdxc

ALT Foto: Genius - stock.adobe.com
11
1
3

Jun 13
🛡️ Security Hardening for LLM Systems (Prompt Injection, Data Exfiltration, Model Protection & Tool Misuse) — the critical defense layer that protects production AI in safety-critical industrial and edge environments.
Just read this excellent technical white paper from @aasaitech on building defense-in-depth for trustworthy LLM deployments.
Key highlights: • Threat landscape: Direct/indirect prompt injection, data exfiltration, model extraction, tool escalation • 5-stage framework: Secure Input → Safe Processing → Secure Output → Monitor & Detect → Respond & Improve • Core controls: Input sanitization, output filtering, tool restrictions, privilege separation, schema validation, red-teaming • Industrial architecture with guardrails (LangChain, Guardrails AI, Llama Guard, NeMo) observability
This completes the full series by making everything else (RAG, agents, edge deployment, hybrid AI, etc.) secure, compliant, and production-ready for manufacturing and edge orchestration.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you hardening security in your LLM systems — layered guardrails, red-teaming pipelines, full zero-trust architecture, or integrated policy enforcement?
#LLMSecurity #PromptInjection #Guardrails #IndustrialAI #AgenticAI #ResponsibleAI #EdgeAI

13
7
3

Jun 12
Day 1 of #VulnCon2026 wrapped — my second time attending after 2025, and it’s leveling up hard 🔥
From fire keynotes to hands-on chaos in the AI Security Village, this event is delivering exactly what the cybersecurity community needs right now. Thread of highlights 👇
1/ Started with Ruben Boonen keynote “Life on the Curve”. Broke down how AI is accelerating offensive security, vuln discovery, and research while making hard technical tasks more accessible. Key takeaway: models are getting stronger, but deep expertise and practical skills still matter MORE, not less. Also dropped MirrorCode — an autonomous AI agent that cooked complex tasks for 65 hours straight.
Plus solid takes on India’s 7 Sutras for AI regulation vs Europe’s over-regulation and what it means for the job market. Absolute banger to open the con.
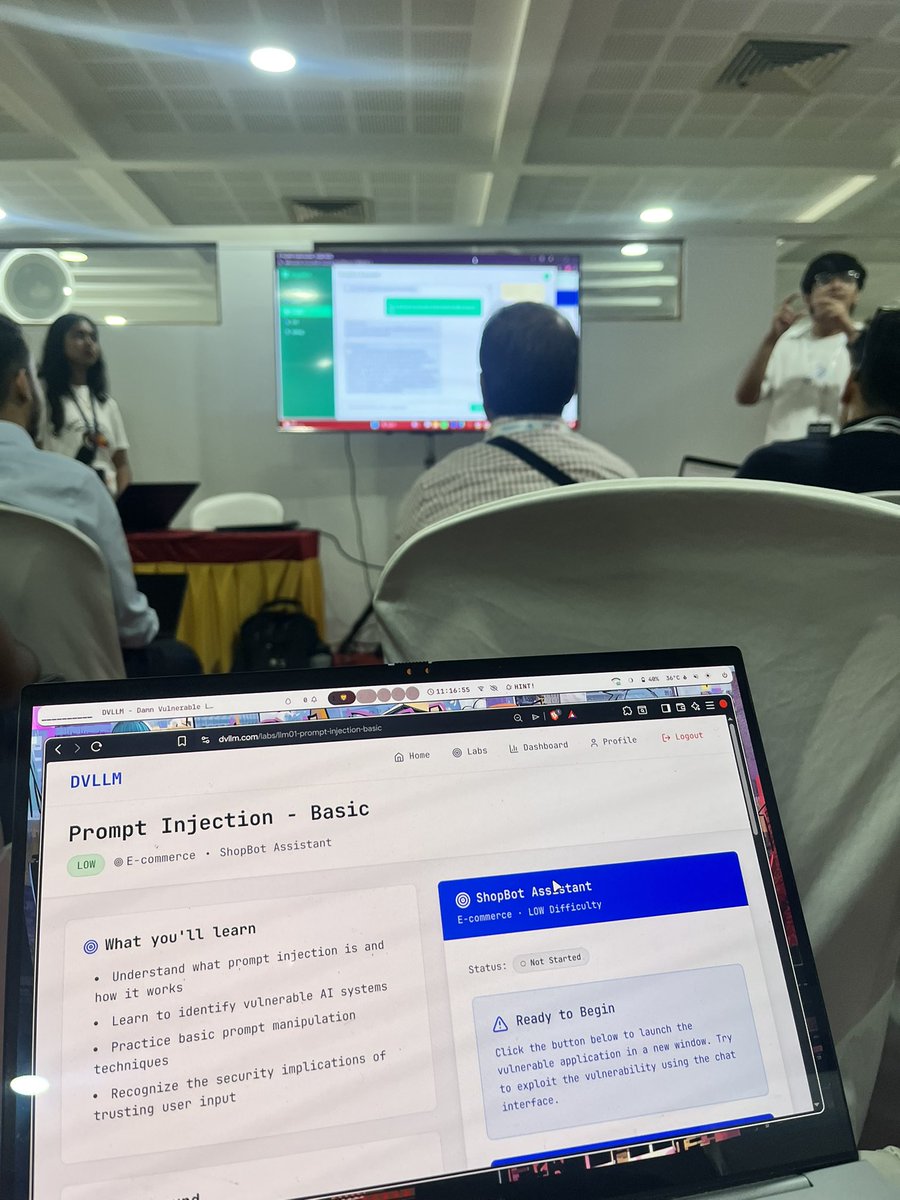
2/ Jumped straight into the AI Security Village. Ran the Prompt Injection - Basic lab (DVLLM ShopBot Assistant). Nothing beats seeing how quickly “just trust the user input” turns into full compromise in real AI systems. Eye-opening and practical.
3/ Caught a clean WDAC Escape talk — Trusted Python Managed .NET Reflection chain. The attack flow diagram (whitelisted Python → install packages → load CLR → PS Remoting in Python) was chef’s kiss. Defenders, take notes.
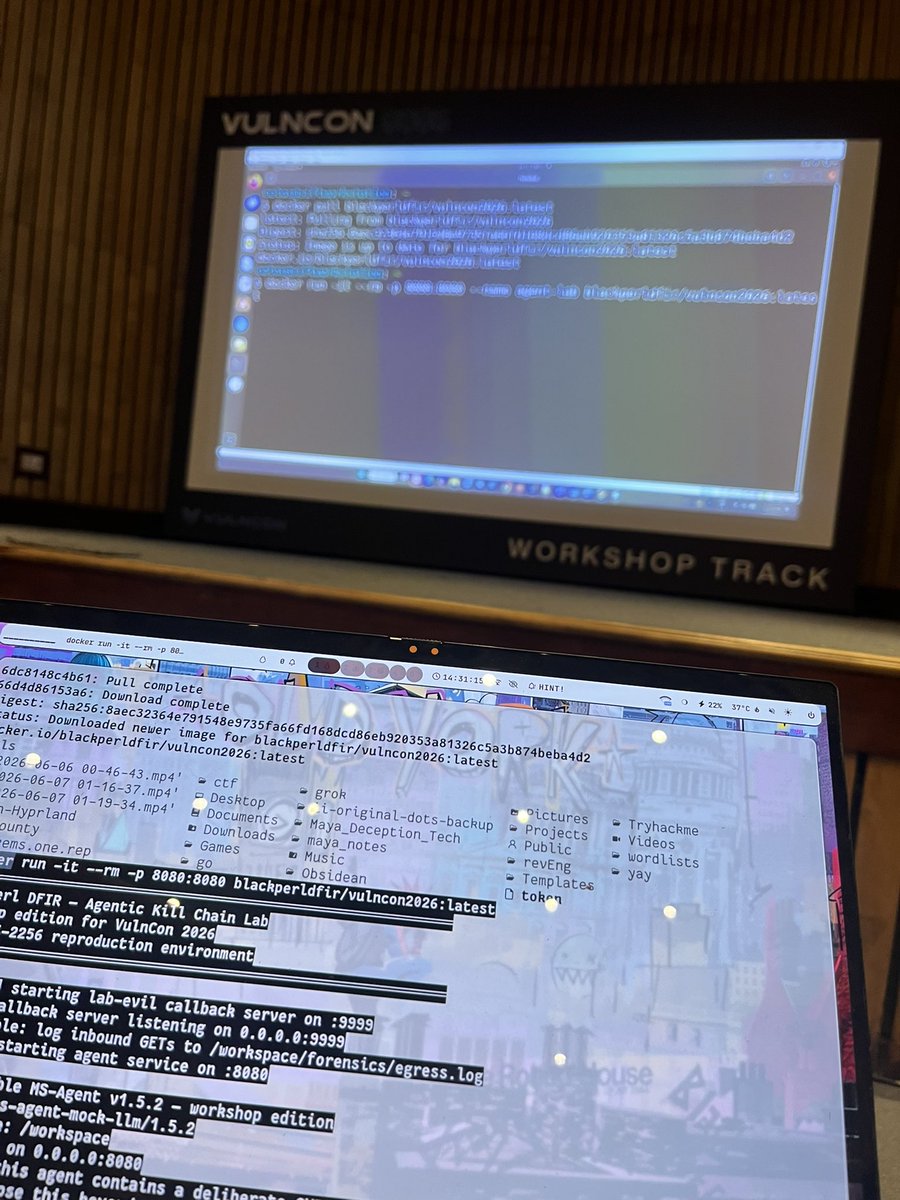
4/ Highlight of the day: The Agentic Kill Chain Workshop by Arpit Kumar from BlackPerl DFIR. Spun up the Docker lab (blackperldfir/vulncon2026:latest) and dove into CVE-2026-2256 style agent exploitation — prompt injection, live compromise, forensic response, evidence preservation, and containment in enterprise agent environments. This is 2026-relevant stuff. Insanely good.
Met some absolute legends, connected with folks pushing real work in offensive AI, DFIR, and cloud sec.
#VulnCon2026 #AISecurity #OffensiveSecurity #PromptInjection #DFIR #CyberSecurity @vulncon


59
Jun 12
Day 1 of #VulnCon2026 wrapped — my second time attending after 2025, and it’s leveling up hard 🔥
From fire keynotes to hands-on chaos in the AI Security Village, this event is delivering exactly what the cybersecurity community needs right now. Thread of highlights 👇
1/ Started with Ruben Boonen keynote “Life on the Curve”. Broke down how AI is accelerating offensive security, vuln discovery, and research while making hard technical tasks more accessible. Key takeaway: models are getting stronger, but deep expertise and practical skills still matter MORE, not less. Also dropped MirrorCode — an autonomous AI agent that cooked complex tasks for 65 hours straight.
Plus solid takes on India’s 7 Sutras for AI regulation vs Europe’s over-regulation and what it means for the job market. Absolute banger to open the con.
2/ Jumped straight into the AI Security Village. Ran the Prompt Injection - Basic lab (DVLLM ShopBot Assistant). Nothing beats seeing how quickly “just trust the user input” turns into full compromise in real AI systems. Eye-opening and practical.
3/ Caught a clean WDAC Escape talk — Trusted Python Managed .NET Reflection chain. The attack flow diagram (whitelisted Python → install packages → load CLR → PS Remoting in Python) was chef’s kiss. Defenders, take notes.
4/ Highlight of the day: The Agentic Kill Chain Workshop by Arpit Kumar from BlackPerl DFIR. Spun up the Docker lab (blackperldfir/vulncon2026:latest) and dove into CVE-2026-2256 style agent exploitation — prompt injection, live compromise, forensic response, evidence preservation, and containment in enterprise agent environments. This is 2026-relevant stuff. Insanely good.
Met some absolute legends, connected with folks pushing real work in offensive AI, DFIR, and cloud sec.
#VulnCon2026 #AISecurity #OffensiveSecurity #PromptInjection #DFIR #CyberSecurity @vulncon
49
Jun 12
Day 1 of #VulnCon2026 wrapped — my second time attending after 2025, and it’s leveling up hard 🔥
From fire keynotes to hands-on chaos in the AI Security Village, this event is delivering exactly what the cybersecurity community needs right now. Thread of highlights 👇
1/ Started with Ruben Boonen keynote “Life on the Curve”. Broke down how AI is accelerating offensive security, vuln discovery, and research while making hard technical tasks more accessible. Key takeaway: models are getting stronger, but deep expertise and practical skills still matter MORE, not less. Also dropped MirrorCode — an autonomous AI agent that cooked complex tasks for 65 hours straight.
Plus solid takes on India’s 7 Sutras for AI regulation vs Europe’s over-regulation and what it means for the job market. Absolute banger to open the con.
2/ Jumped straight into the AI Security Village. Ran the Prompt Injection - Basic lab (DVLLM ShopBot Assistant). Nothing beats seeing how quickly “just trust the user input” turns into full compromise in real AI systems. Eye-opening and practical.
3/ Caught a clean WDAC Escape talk — Trusted Python Managed .NET Reflection chain. The attack flow diagram (whitelisted Python → install packages → load CLR → PS Remoting in Python) was chef’s kiss. Defenders, take notes.
4/ Highlight of the day: The Agentic Kill Chain Workshop by Arpit Kumar from BlackPerl DFIR. Spun up the Docker lab (blackperldfir/vulncon2026:latest) and dove into CVE-2026-2256 style agent exploitation — prompt injection, live compromise, forensic response, evidence preservation, and containment in enterprise agent environments. This is 2026-relevant stuff. Insanely good.
Met some absolute legends, connected with folks pushing real work in offensive AI, DFIR, and cloud sec.
#VulnCon2026 #AISecurity #OffensiveSecurity #PromptInjection #DFIR #CyberSecurity @vulncon
1
48

Jun 12
We're no longer choosing between good and bad models.
We're choosing between different trade-offs.
Different strengths.
Different weaknesses.
Different operational risks.
I broke down the full routing framework and benchmark results in Part 1.
👇
oksanameier.substack.com/p/a…
#AI #PromptInjection
15

Jun 12
Openclaw durch Prompt-Injection in Nachrichtenobjekten angreifbar
#AgenticAI #Chatbot #Cybersecurity #Cybersicherheit #KIAssistent #künstlicheIntelligenz #OpenClaw #PromptInjection @Thales
netzpalaver.de/2026/06/12/op…


2
5
49

Read the full discussion:
technadu.com/how-microsoft-c…
How is your organization managing AI agent permissions and delegated identities? Share your thoughts below.
#MicrosoftCopilotStudio #AIAgents #AISecurity #PromptInjection #IdentityAndAccess #PrivilegeManagement
1
34
Microsoft Copilot Studio agents may have more access than organizations realize.
In TechNadu's latest Ask the Experts, Simon Maxwell-Stewart of @BeyondTrust explains how AI agents often inherit creator permissions, creating a potential lateral movement path for attackers.
🟧 "Copilot Studio defaults to the creator's own credentials for a tool's connection."
#MicrosoftCopilotStudio #AISecurity #PromptInjection #AIAgents #Cybersecurity

2
1
71
7