

With a name like "StarNet", you'd expect a rogue AI from a summer sci-fi blockbuster: a planetary defense grid, or a neural web commanding a fleet of autonomous starships 🌟
But Tesla’s StarNet is ingenious for precisely the opposite reason. It's a masterclass in extreme confinement, a blueprint designed to trap complex artificial intelligence inside the claustrophobic walls of compact, low-power microchips 🔥
Normally, the massive calculations required for deep learning would quickly overflow these tiny processors’ numerical registers, transforming valid calculations into corrupted values. Instead of begging the hardware for more power, Tesla re-engineered the AI itself to survive inside a strictly contained numerical cage 🆒
If you really don't have time for the full deep dive, here is how StarNet pulls it off in 60 seconds:
🔢 Every layer receives a strict numerical budget.
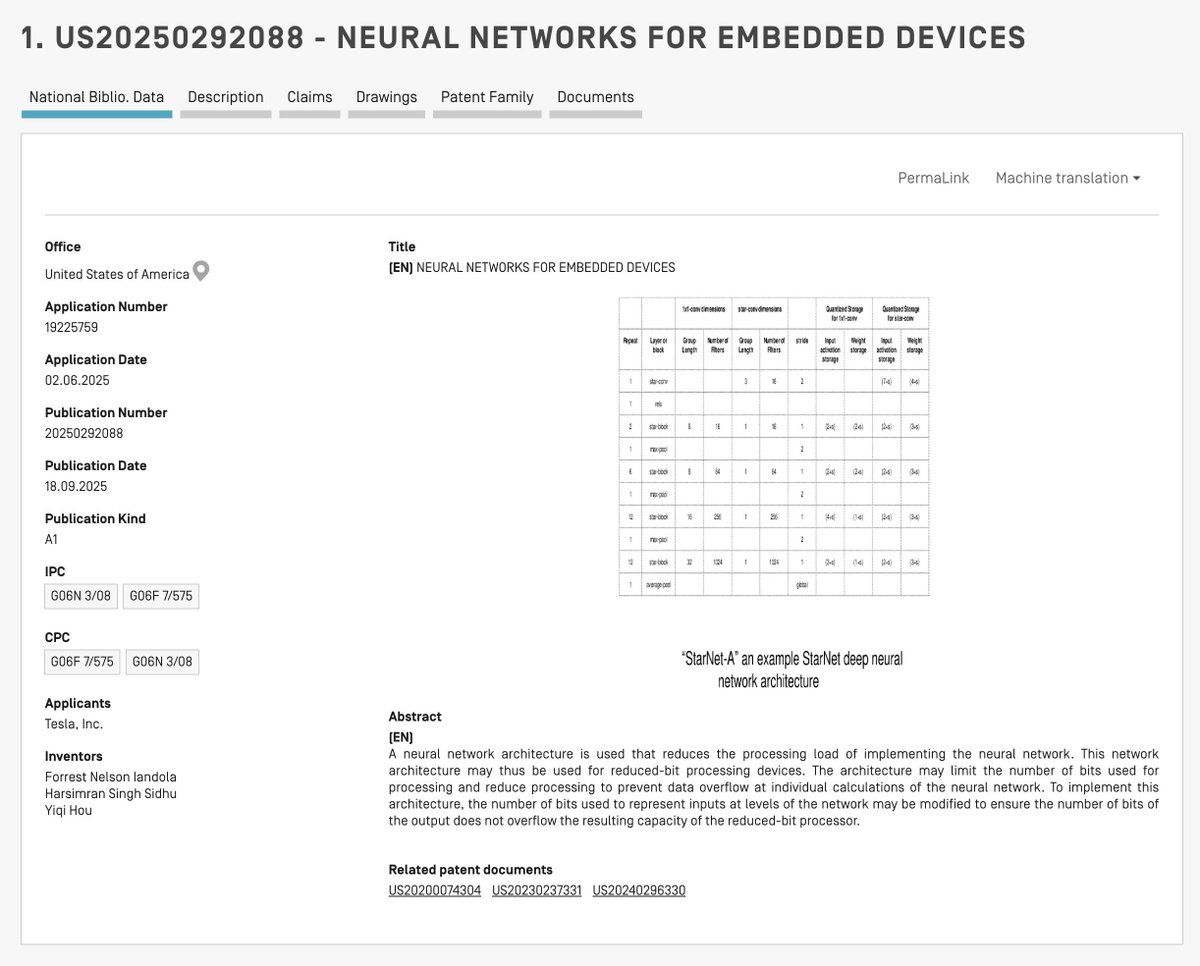
StarNet selects the bit widths of activations and weights according to the size of each calculation. A 32-element filter can be limited so its largest possible output is 96, while 16- and 8-element examples remain below 127 at 112 and 72. The network is designed so the worst-case sum still fits inside the register.
🌟 The nine-point filter loses its corners.
A conventional 3×3 convolution examines nine positions at once. Star-conv uses a five-point cross formed by the center pixel and its four direct neighbors. That smaller footprint reduces the number of values being accumulated while preserving horizontal and vertical spatial information.
🏗️ The network becomes a repeating processing line.
StarNet is built from recurring star-shuffle blocks arranged as 1×1 convolution → ReLU → star convolution → ReLU → shuffle. Each stage has a specific role: mixing channels, introducing nonlinearity, recognizing spatial patterns, and reconnecting information across channel groups.
📉 Each layer receives its own conversion scale.
A calibration dataset reveals the minimum and maximum values produced at every layer. StarNet uses those ranges to calculate custom quantization parameters that map real values into compact integer bins, allowing the network to preserve useful distinctions without exceeding its assigned bit width.
🧮 Repeated numerical translations collapse into one operation.
Low-bit networks can waste time repeatedly quantizing and dequantizing data between adjacent layers. StarNet mathematically combines those conversions, cutting the associated operations by a factor of two. In some sequences, the intermediate conversions can be omitted entirely.
🔀 Separated channel groups are forced to communicate.
Group convolutions save computation by processing subsets of channels independently, but that efficiency can create isolated mini-networks. The shuffle layer interleaves their channel ordering, allowing information from different groups to mix without restoring the cost of a fully connected architecture.
🤝 The first impression receives extra precision.
StarNet-A does not force the raw image through the same numerical constraints immediately. Its first layer uses 8-bit inputs with 16-bit arithmetic and temporary storage, potentially running on the CPU. Once that sensitive first step is complete, the remaining layers can move to the energy-efficient accelerator using 8-bit storage and arithmetic.
While the tech world is obsessing over building bigger, hotter data centers, StarNet quietly moves the finish line. Tesla has drawn a blueprint for putting deep learning into practically anything with a processor and a power source.
The cloud is no longer the limit. The edge is here, and it is starting to think for itself 💪


BREAKING 🚨 TESLA PATENTED "STARNET" TO SHOW THE WORLD HOW IT SQUEEZES SERVER-GRADE AI INTO $5 CHIPS 🐳
Deep neural networks have a dirty secret: they are mathematically expensive.
To see the world clearly, AI models typically crave the high-precision, energy-guzzling power of massive GPUs. But for a robot to be nimble or a car to be truly autonomous, it needs that same server-grade intelligence running on cheap, battery-sipping microchips.
This constraint usually forces engineers to choose between being "smart" or being "efficient".
Tesla just refused to choose.
According to patent US 2025/0292088 A1, Tesla has developed a new neural architecture called "StarNet" that fundamentally rewrites the rules of low-power computing.
Instead of dumbing down the AI to fit on a simple chip, StarNet uses a novel "mathematical cage" to force complex deep learning to run safely on constrained 8-bit processors. These simple chips can typically only handle small, integer numbers.
This is the blueprint for how Tesla plans to embed high-level decision-making into every joint of a robot and every sensor of a car. It unlocks a future where sophisticated AI lives on the edge, not in the cloud.
But to understand why this is such a breakthrough, we first need to understand the mathematical wall that has stopped everyone else.
⚖️ The problem: The heavy burden of floating-point arithmetic
The central challenge in deploying artificial intelligence to "edge" devices—like sensors in a car, components of a robot, or smart home appliances—is that these devices typically lack the computing power of a massive server farm.
Traditional deep neural networks rely on high-precision mathematics, specifically 32-bit floating-point arithmetic, to process images and data accurately. This format allows computers to handle an enormous range of numbers with extreme precision, similar to using a scientific calculator that can calculate out to dozens of decimal places.
However, this requires expensive, power-hungry processors that are not feasible for every small component in a vehicle or robot.
When engineers try to run these networks on cheaper, low-power chips that use simpler 8-bit integer arithmetic, they run into a critical mathematical wall. The simplified processors often use "signed" integers where the maximum value is very low, specifically 127.
Think of this limit like a small odometer on a bicycle that can only count up to 127 meters. When a neural network tries to add up thousands of calculations from a filter, the numbers often exceed this limit, causing an "overflow".
When an overflow happens, the odometer doesn't just stop. It wraps around to a negative number, producing a wildly incorrect result that effectively breaks the AI's ability to recognize objects or process data.
To overcome this hardware limitation without crashing the system, Tesla had to reinvent the neural network from the ground up.
✨ Tesla's solution: The StarNet Architecture
Tesla's solution is a novel neural network design dubbed "StarNet", explicitly engineered to operate within the strict confines of 8-bit arithmetic while preventing data overflows.
To understand the difference, imagine 32-bit floating-point math—the standard for modern AI—as a massive 12-lane highway. It has plenty of room for huge trucks (large numbers) and tiny motorcycles (small decimals) to travel side-by-side without ever touching the guardrails. This offers a massive "numerical safety net" where calculations can be sloppy or large without breaking the system.
However, the inexpensive Digital Signal Processing (DSP) cores found in cars and robots are more like a narrow bike path. They often rely on non-saturating signed 8-bit integers, where the maximum representable value is a mere 127.
If a standard neural network tries to run on this hardware, it is like trying to drive a semi-truck down that bike path. The sum of its calculations would almost immediately exceed 127, causing an integer overflow. This results in garbage data, effectively crashing the vehicle's intelligence.
Simply shrinking the network isn't enough; the fundamental topology—the architectural floor plan of how the neurons are wired together—must change.
StarNet solves this by shifting the burden of precision. Instead of relying on the hardware to handle large numbers, the architecture itself is designed to remain "numerically quiet".
Think of it like being in a library. If you can't build thicker walls (better hardware) to handle noise, you must enforce a strict "whisper-only" rule (StarNet). By intentionally keeping the internal numbers small so they never shout louder than "127", the system ensures it never hits that ceiling.
It achieves this through a ground-up redesign of how filters are shaped and how data flows. By enforcing a "mathematically guaranteed safety" protocol at the architectural level, StarNet allows Tesla to bypass the slow, power-hungry CPUs entirely.
Instead, they can run sophisticated AI exclusively on highly efficient, specialized DSP cores. These cores are essentially simple, high-speed calculators that were previously thought to be too basic for deep learning.
This new architecture isn't random; it follows a very specific, recurring recipe designed to maximize efficiency.
🏗️ The Blueprint: The "Star-Shuffle" recipe
The patent provides the exact recipe for the "Star-Shuffle Block", the atomic unit of this neural architecture. Tesla’s engineers found that a random arrangement of layers wouldn't work. Instead, they defined a strict recurring sequence: {1x1-conv, ReLU, Star-Conv, ReLU, Shuffle}. This specific order is critical, functioning like a highly efficient assembly line where every component has a non-negotiable role.
The process starts with a 1x1 convolution, which acts as the "Mixer". This step ignores the shape of the image and looks strictly at the "depth" of the data at a single point. It mixes the information across channels—like combining the Red, Green, and Blue data of a pixel into a single color concept, like Purple. This allows the network to combine raw inputs into complex features before passing them down the line.
Immediately following this is the ReLU (Rectified Linear Unit) function, the "Gatekeeper". Despite the complex name, it acts like a bouncer, filtering out irrelevant "negative" data. By blocking negative signals and only letting positive ones pass, it keeps the signal clean and introduces "non-linearity", the mathematical magic that allows AI to understand curves. Crucially, this filtering process also keeps the math simple enough for 8-bit hardware to handle efficiently.
Once the features are mixed and cleaned, the Star-Conv steps in as the "Scanner". It looks at the center pixel and its neighbors to understand shapes and edges. This is where the architecture's genius lies: by sandwiching this spatial processing between the channel mixing and the non-linear activations, the network maximizes its learning capability. It processes the "what" (color concepts) before the "where" (shapes), saving massive amounts of computing power.
Finally, the block concludes with a Shuffle layer, the "Networker". Because the previous steps often split data into isolated groups to save energy, the network risks becoming "siloed". The Shuffle layer acts like a mandatory networking event, rearranging the channels to force information from different groups to mix. This ensures the left hand always knows what the right hand is doing, preventing the efficiency hacks from compromising the AI's intelligence.
While this recipe sets the structure, the real efficiency gain comes from changing the shape of the filters themselves.
🌟 The "Star-Conv": The carpool solution
A standard convolutional neural network typically looks at the world through a square grid of 9 pixels. To understand an image, it has to combine the data from all 9 of these points at once.
Think of this like trying to squeeze an entire baseball team (9 players) into a small 4-seater car (the low-power chip).
It simply doesn't fit. If you try to force everyone in, the car breaks down. In computing terms, adding up 9 separate numbers creates a total sum that is too "heavy" for the tiny chip to carry, causing the system to crash.
Tesla's patent introduces a solution called the "star-shaped convolution". Instead of a square, it uses a cross shape ( ). It looks only at the center pixel and its four direct neighbors (Up, Down, Left, Right), ignoring the corners.
This reduces the group size from 9 players down to 5 (a basketball team).
Suddenly, the team fits into the car. By leaving the 4 "corner players" behind, the total weight drops significantly, guaranteeing the car never breaks down.
Crucially, this smaller team can still win the game. By focusing on the main directions (North, South, East, West), the AI can still recognize vertical lines, horizontal edges, and curves just as well as the larger group. It is like sketching a portrait using only 5 main strokes instead of 9—the picture is just as clear, but it takes much less effort to draw.
But geometry alone isn't enough; to truly guarantee safety, the system also needs to strictly manage the "volume" of the data itself.
🔢 The "(2 s)" Math: Extreme bit-counting
To strictly prevent data overflows, the patent introduces a specific notation for "bit-budgeting", such as (2 s). This stands for "2 bits of data plus 1 sign bit".
In plain English, this forces the computer to work with tiny numbers. While a standard computer counts in millions, this system restricts variables to a maximum value of just 3.
To understand why this is necessary, imagine the microchip is a small room with glass windows. The "sum" of the calculations is the noise level in that room. The physical limit of the chip is 127 decibels. If the noise hits 128, the windows shatter and the system crashes.
To keep the windows intact, the patent outlines a sliding scale of "volume control" that changes based on how many "voices" (pixels) are speaking at once:
For a large 32-element filter: Think of this as a large choir of 32 singers. If everyone sings at the top of their lungs, the windows will definitely shatter. Therefore, the system enforces a strict "whisper only" rule. It limits the volume of the input (loudness) to a max of 3 and the weight (emphasis) to a max of 1. Even if all 32 singers whisper as loud as they are allowed, the total noise is 32 * 3 * 1 = 96. This is safely below the 127 limit, guaranteeing the glass won't break.
For a medium 16-element filter: This is like a small discussion group. Since there are fewer people, the strict whispering rule can be relaxed. The system allows the volume to go up to 7 (talking normally). The worst-case math becomes 16 * 7 * 1 = 112. It is louder, but still safely under the 127 limit, allowing the AI to be more precise with these details.
For a small 8-element filter: This is like a jazz quartet. With so few musicians, they have the freedom to play much louder. The system allows both the input volume and the instrument weight to go up to 3. The safety calculation is 8 * 3 * 3 = 72. This is well within the safe zone, proving that by strictly managing the "volume" of the data, Tesla can push the hardware to its absolute limit without ever risking a crash.
To ensure these tiny numbers still represent the real world accurately, the system uses a smart translation process.
📉 Smart Quantization: The "A" and "B" formula
To make this low-bit math work without making the AI "dumber", StarNet employs a rigorous linear quantization strategy. It’s not enough to just "round down" numbers; the system must intelligently compress them.
The patent reveals that every single layer in the network is assigned two learnable parameters: A (scale) and B (bias).
The patent explicitly defines the relationship using a linear equation: the quantized value (V_Q) is calculated by taking the real-world value (V_R), dividing it by A, and then subtracting B. These parameters act like a precise conversion formula, similar to how you use a formula to translate temperature from Celsius to Fahrenheit.
But how does Tesla find the perfect A and B? The patent details a "Calibration Phase".
Before the neural network is ever deployed to a car or robot, a test dataset is passed through it one example at a time. The system records the absolute minimum and maximum output values for every specific layer.
These extremes are then plugged into a system of linear equations to solve for the precise A and B values that will fit that specific layer's data into the target bit-width (e.g., 0 to 3) without overflowing. This effectively creates a custom-fitted mathematical guardrail for every single neuron, ensuring that no matter what image the AI sees, the internal math will always remain safe and stable.
Once the parameters are set, Tesla applies one final trick to speed up the process even further.
🧮 "Quantization Collapsing": The speed hack
One of the most granular innovations in the patent is a technique called "Quantization Collapsing".
In a standard low-bit network, the system is constantly stuck in a loop of conversion: de-quantizing the output of one layer back into a 'real' number, only to immediately re-quantize it for the next layer. This is like translating a sentence from English to French, and then immediately translating it back to English before moving on. This back-and-forth wastes valuable computing cycles.
Tesla’s solution is to mathematically fuse these adjacent steps.
The patent describes a mechanism where the de-quantization equation of one layer and the quantization equation of the next are collapsed into a single, pre-calculated operation. This reduces the computational load by a factor of two.
Even more radically, the patent notes that for certain sequences, the system can "leave out both of them" entirely. This allows the network to run a chain of calculations using only an initial quantization at the start and a final dequantization at the end, effectively eliminating the computational middlemen and keeping the data in its fast, efficient 8-bit form.
However, all this efficiency comes with a risk: the network can become too compartmentalized. The next component solves that.
🔀 The Shuffle Layer: Breaking the silos
One side effect of using these highly efficient filters—specifically "group convolutions" where the group length is greater than 1—is that the network effectively splits into several independent, isolated mini-networks.
The patent notes that while the standard 1x1-conv layers can mix information between "nearby" channels, they cannot reach across to other groups. This means features learned in one part of the network are completely invisible to the rest, severely limiting intelligence. This is similar to different departments in a company refusing to talk to each other, preventing the organization from seeing the big picture.
To solve this, StarNet implements a "shuffle" layer at the end of every block.
Just like shuffling a deck of cards, this operation takes the output data and strictly interleaves the channel ordering. The patent explicitly states that this enables communication across "far-away channels" that would otherwise remain isolated.
By forcing these independent groups to mix, the "Star-Shuffle Block" regains the representational power of a massive, fully connected network while retaining the extreme speed of a sparse, grouped one.
With the core architecture optimized, Tesla addresses the final hurdle: how to handle the very first glance at the world.
🤝 Hybrid Processing: CPU and DSP teamwork
Finally, the patent reveals a pragmatic "hybrid" hardware approach. While the goal is to use 8-bit arithmetic for speed, the inventors acknowledge that quantizing the very first input image too aggressively destroys accuracy immediately. You can't recover from bad data at the start.
To solve this, StarNet-A (an example architecture in the patent) creates a specific "First Layer Exception".
The very first layer—a Star-Conv with a stride of 2—is not run on the accelerator. Instead, it is computed on the device's general-purpose CPU using 16-bit arithmetic and 16-bit temporary storage.
This allows the system to ingest the raw, high-resolution RGB image and perform the initial feature extraction and downsampling, which is a process of shrinking the image size to make it easier to manage, with maximum precision.
Once this critical "first impression" is secure, the data is handed off to the specialized, high-efficiency DSP (Digital Signal Processor) cores for the remaining dozens of layers. This "tag-team" approach ensures the network starts with high-fidelity vision data before switching to ultra-low-power processing for the heavy lifting.
So, what does all this technical wizardry actually mean for Tesla's future?
🚀 How this patent contributes to Tesla's now and future
This patent is the "missing link" that explains how Tesla plans to scale from smart cars to ubiquitous robotics. While the industry obsesses over massive GPUs in data centers, Tesla has quietly solved the opposite problem: how to put a "brain" into a dollar-store microchip.
The most immediate application is likely the technical foundation for the "spinal cord" of the Tesla Bot (Optimus). A humanoid robot cannot route every single twitch of a finger or balance correction of an ankle to a central computer in its chest—the latency, or delay, would be too high and the power drain too massive.
StarNet allows Tesla to embed tiny, 8-bit neural networks directly into the local actuator controllers at each joint. This effectively gives Optimus a "peripheral nervous system", allowing hands and legs to handle their own reflex-level processing locally using simple DSPs, freeing up the central AI5 computer for high-level reasoning.
This distributed approach is equally critical for the upcoming Cybercab and Robotaxi fleet, where cost and redundancy are paramount. Redundancy here refers to having backup systems that ensure safety if the primary system fails.
By validating that high-accuracy vision can run on 8-bit DSPs, Tesla can install intelligent, redundant camera modules that process data before it even hits the main computer. If the main FSD computer were to glitch, these decentralized "smart eyes"—running unbreakable, overflow-proof StarNet code—could theoretically maintain enough visual awareness to pull the vehicle over safely.
Beyond vehicles, this architecture enables a "Smart Dust" approach to the Alien Dreadnought factory. Tesla’s manufacturing strategy relies on extreme automation, and StarNet enables cheap sensors embedded in casting machines and stamping presses to detect defects or wear in real-time.
Because the architecture is designed for "embedded devices" with strict bit-budgets, these smart sensors can run on harvested energy or tiny batteries. This turns the entire Gigafactory into a living, sensing organism without requiring expensive server racks to process the data.
Ultimately, this innovation builds a massive economic moat based on pure efficiency.
While competitors are building autonomous systems that rely on expensive, power-hungry NVIDIA Orin or Thor chips running heavy floating-point math, Tesla can achieve similar inference results using commodity 8-bit DSP hardware that costs a fraction of the price. Inference results is the technical term for the AI making a real-world decision based on what it sees.
Over a fleet of millions of cars and robots, saving $100 per chip adds up to billions in profit, effectively weaponizing mathematical efficiency to scale intelligence faster and cheaper than anyone else.
1
2
3
557

スライドは日英併記にするかな
ConvolutionとDeconvolution
Live-cell fluorescence imaging before GFP
1
4
190

5 senede öğrendiğim en sikko kelimeler
Ergodicity
Toeplitz
Hermitian
Positive semidefinite
Wssus
Cyclic prefix
Circular convolution
Mimo,ofdm cart curt
Trellis
Viterbi
19

when i make something good w/ it i wanna make a video about using morph/vocoders to blend a bass with the colorized version of it (like w/ convolution reverb or resonatoes), lets you get that texture but even tighter and w/o losing the original character
7

convolution reverbにgrain軽く足して広がり出そうとしたら、density上げた途端CPUが急に重くなって低域もモコッと浮いちゃって自分で吹き出しました。
3

On the convergence of the normalized power sequence of Riesz operators
arXiv:2606.13743
The structure of optimal dual frames for probabilistic erasures unde...
arXiv:2606.14002
Theory and Applications of Convolution-Based short time offset linea...
arXiv:2606.14102
41

atcoder.jp/contests/arc222/s…
minの畳み込みをK個以上?(0 or 1)によってやるのがまず賢い、xor convolutionとかいうアルゴリズムもめちゃくちゃ賢い(FWHTがすごすぎ!!)だった
解放を2個組み合わせるやつもかなり賢い良問だった
25

convolution reverbにgrain軽く足して広がり狙ったら、density上げた途端CPUが急に重くなって低域もモコッと浮いちゃって自分で吹き出しました。
13


Even with Tangled, you accompany Flynn and Rapunzel together to get to Corona through the film’s first act, and Pirates can justify it some by the sheer convolution of At World’s End as well as the unique gameplay hook and Davy Jones fight.
Frozen really lacks any of that stuff
1
83
Swaroop Kumar Yadav retweeted

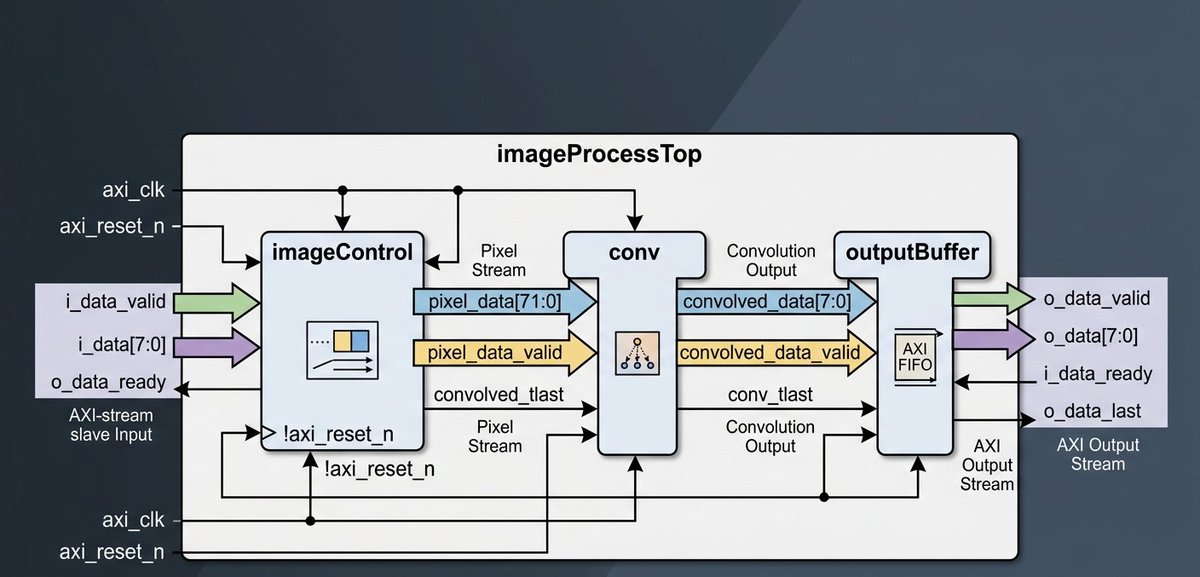
Built a real-time FPGA-Based 2D Convolution Accelerator on the ZCU102 using Verilog and AXI-Stream architecture 🚀
Implemented:
• Streaming image pipeline
• Hardware convolution engine
• AXI DMA integration
• Real-time image filtering on FPGA
Exploring the AI x VLSI⚡
1
1
3
87
convolution reverbにgrain軽く足して広がり出そうとしたら、density上げた途端CPUが急に重くなって低域もモコッと浮いちゃって自分で吹き出しました。
14

A longer path to the same conclusion--with a lovely surprise early on--starts with the geometric series Σ(2^-n) for n>0. That is, a=r=1/2 and the sum is 1.
Raise this series to positive integer powers using Cauchy product, a.k.a. Lightning Algorithm, a.k.a. discrete convolution.
1
1
33

ARC222
A:Mexのノリ
B:頑張る!!!!!!!と通る
C:
.#.######
#.#.#####
##.#.####
#.#.#####
##.#.####
###.#.###
####.#.##
↑これが本質、あとはdp
D:赤い疑問符
E:ノリでxor convolutionって言ってたら本当にそれとは思わんじゃん!!!!!!無理!!!!!!!!
F:見てない
5
312

naiveなconvolutionとアダマール変換使うやつのうち小さい方を使うという方針は思いついており、なんか通らない気がして諦めたが、勇気をもって実装すると通るらしい
計算量の見積もりが下手

xor畳み込みを√N回行うことになって死んでた
2
653
panpan retweeted

19 Nov 2020
I'm so fucking convolution poisoned by rube goldberg machines. I can't even watch something happen straightforwardly anymore
5
28
333

Today , I learn about control system & signal system (Nyquist, Bode , Polar, Fourier, Laplace, z Transformation , Convolution, sampling ) & this is out of my domain . This Is just for curiosity of robotics . Stay Foolish Stay Hungry
9
