
🧬 #DNALibraries enable:
🔬 Functional screening → novel targets
🧬 #AntibodyDiscovery → broader repertoires
⚡ #CRISPRScreening → essential genes
🧪 #Mutagenesis → variant function
Strong library design validation drive reliable insights.
hubs.la/Q04kshKd0

18

12 Oct 2025
DEL Simulator: A Digital Twin for Understanding Machine Learning on DNA-Encoded Libraries
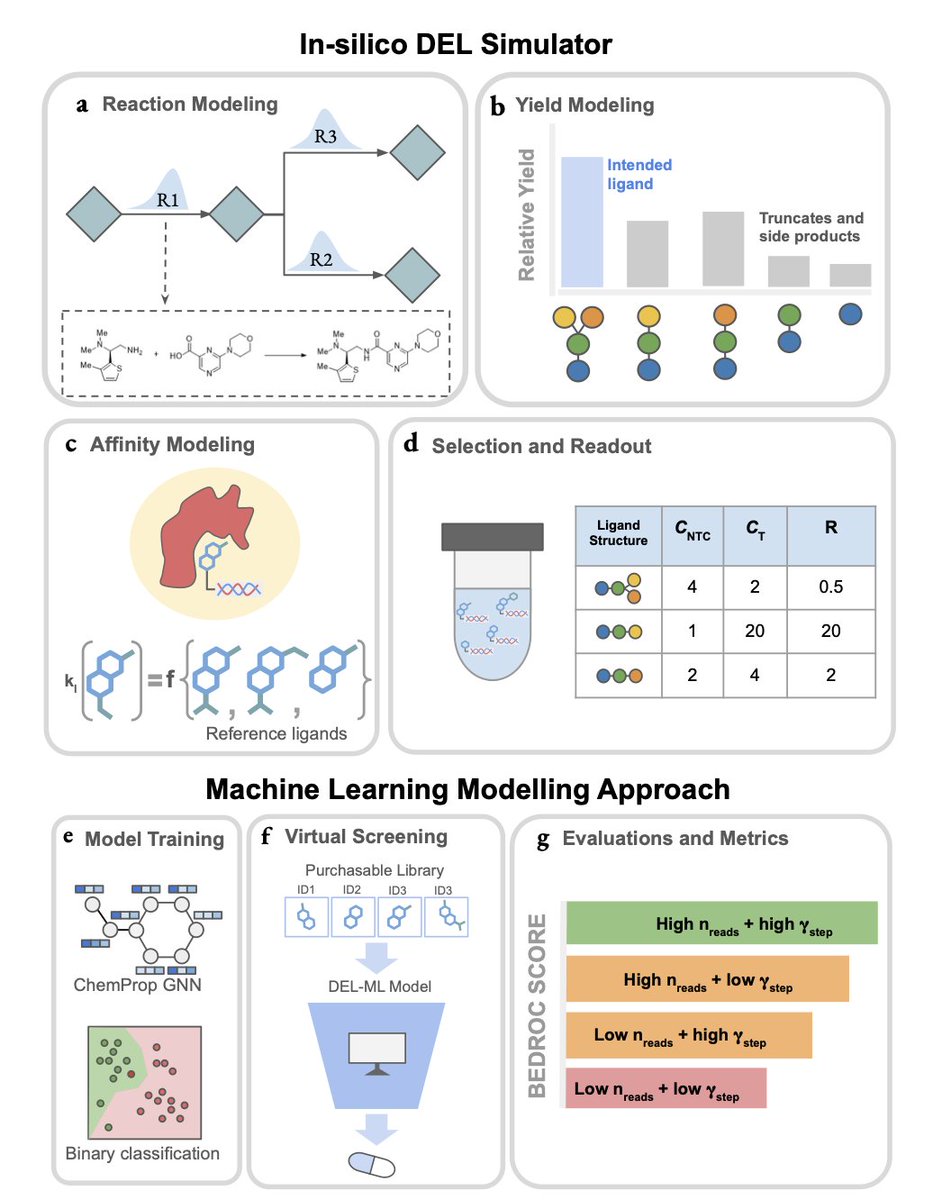
1. The article introduces a digital twin – an in-silico DEL simulator – that models the underlying chemistry and selection processes of DNA-encoded libraries (DELs) as a function of key design parameters. This includes read count, cycles of selection, one-step reaction yield, and library size. The simulator provides a statistically principled way to understand and analyze DEL experiments via an interpretable model for DEL data generation.
2. The simulator systematically investigates how design parameters influence downstream machine learning (ML) virtual screening. It identifies specific regimes where preprocessing steps such as disynthon aggregation can significantly enhance screening performance. Notably, it shows that increasing library size can degrade ML-based screening performance, challenging the common assumption that larger libraries always lead to better outcomes.
3. The DEL Simulator comprises seven modular components: Library Generation, Affinity Modeling, Affinity Selection and Readout, Data Processing and Aggregation, Model Training, Virtual Screening, and Model Evaluation. This modular design allows for flexibility and extensibility, making it a powerful tool for researchers to explore different experimental setups and ML strategies.
4. The simulator generates synthetic ground-truth affinity data, allowing researchers to run a variety of in-silico DEL hit identification campaigns with varied experimental parameters. This approach provides insights into the effectiveness of different data analysis techniques, which is crucial for optimizing DEL campaigns.
5. The study uses the DEL Simulator to construct two types of 3-cycle DEL libraries (LIB-A and LIB-B) and runs in-silico prospective DEL-ML hit ID campaigns against two targets: MK14 and sEH. The results highlight the impact of experimental parameters on the performance of ML models, demonstrating the utility of the simulator in guiding experimental design.
6. The DEL Simulator enables rapid exploration of how experimental parameters affect data quality. For instance, increasing the number of selection cycles or read count improves the correlation between observed counts and true affinities, while decreasing reaction yield degrades this correlation due to increased noise from truncates.
7. The article concludes that the DEL Simulator serves as a realistic digital twin of experimental DEL screens, producing chemically grounded, high-fidelity data that can be used to benchmark analysis pipelines, design better selection strategies, or train ML models. Future work may leverage this platform to systematically investigate strategies for enhancing library diversity and optimizing ML strategies in DEL screening.
📜Paper: doi.org/10.26434/chemrxiv-20…
#DELsimulator #MachineLearning #DNALibraries #DrugDiscovery #ComputationalBiology
2
7
1,266
9 Oct 2025
Expansion of DNA-Encoded Library Hits Using Generative Chemistry and Ultra-Large Compound Catalogs
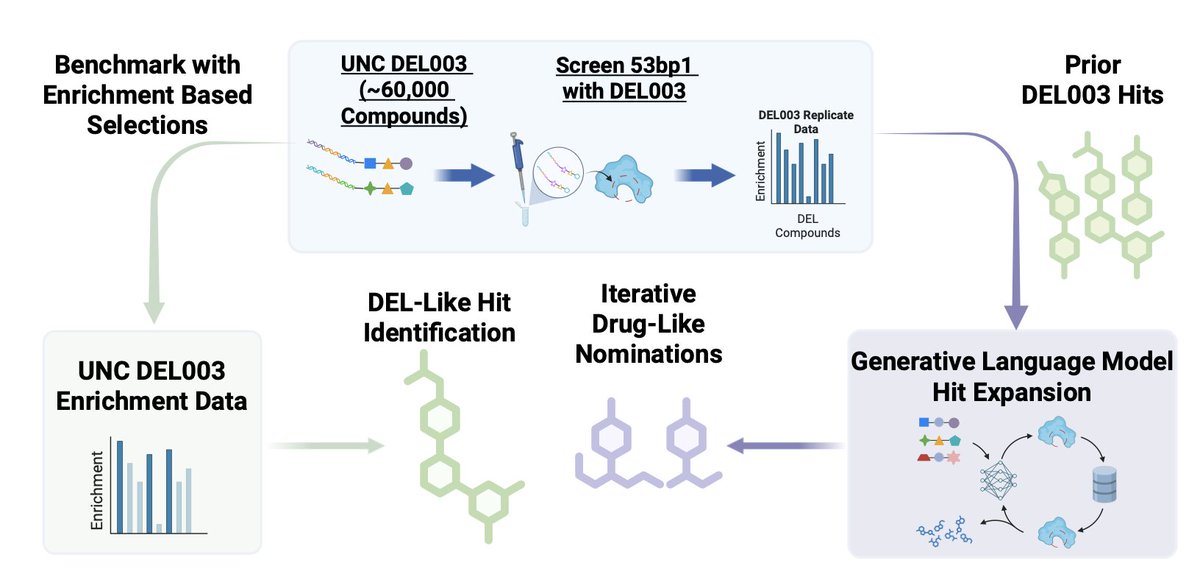
1. This study presents a novel approach to expanding DNA-encoded library (DEL) hits using generative artificial intelligence (AI) and ultra-large compound catalogs. The method leverages experimentally validated DEL data to initialize and bias an AI-powered virtual screening pipeline, enabling the identification of novel, commercially available hits with improved drug-likeness and diversity.
2. The researchers used the HIDDEN GEM workflow, which integrates molecular docking, biased generative AI, and efficient similarity searching. This workflow was initialized with validated DEL screening data targeting the chromatin reader protein 53BP1, and it successfully identified new hits from the Enamine REAL Space with TR-FRET IC50 values ≤100μM.
3. A key innovation is the iterative process of the HIDDEN GEM workflow. Each cycle of the workflow increases the chemical diversity of the nominated compounds, leading to a broader exploration of chemical space compared to traditional DEL screening methods. This iterative approach also improves the drug-likeness of the identified compounds.
4. The study demonstrates that the AI-nominated hits exhibit greater chemical diversity and improved drug-likeness compared to compounds from the initial DEL selection. Importantly, these hits are readily purchasable off-the-shelf, streamlining the hit-to-lead process and making the approach highly practical for academic labs and small biotech companies.
5. The researchers highlight the potential of this integrated strategy for smaller or focused DELs, where supervised machine learning methods can struggle with out-of-domain predictions. By using limited chemical matter from a focused DEL, the workflow can navigate vast commercial libraries to identify novel, potent, and drug-like binders.
6. The study concludes that the combination of empirical DEL data and generative AI represents a significant advance for DEL data analysis. It provides a powerful blueprint for leveraging focused DEL screening data to discover diverse, tractable hits from vast commercial libraries, laying the groundwork for subsequent chemical probe development.
📜Paper: biorxiv.org/content/10.1101/…
#GenerativeAI #DrugDiscovery #DNALibraries #VirtualScreening #ChemicalDiversity #HitExpansion
1
1
4
1,103
3 Oct 2025
Interpretable and Scalable Similarity Metrics for DNA-Encoded Library Design Using Generative Topographic Mapping
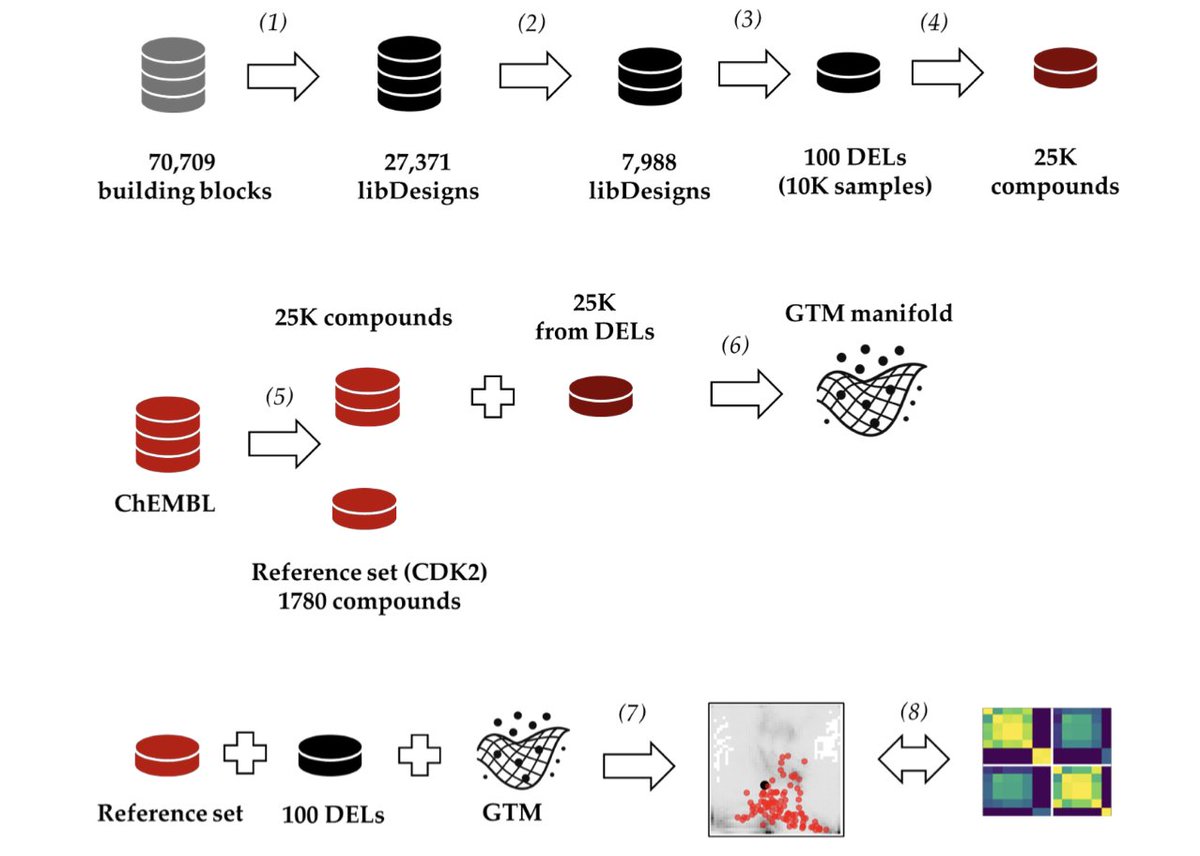
1. This study explores the use of Generative Topographic Mapping (GTM) for selecting DNA-encoded libraries (DELs), offering a scalable and interpretable method to balance similarity to a reference compound collection and intra-library diversity.
2. GTM allows for the representation of each library as a “stand-alone” vector, avoiding costly pairwise similarity calculations and enabling the analysis of thousands of DEL designs.
3. The research demonstrates that GTM-based metrics robustly approximate conventional compound pair-based metrics, with Spearman rank correlations in the 0.6–0.7 range, indicating effective library selection.
4. GTM provides two-dimensional landscapes that visually represent intra- and inter-library diversity, supporting rapid and interpretable screening of alternative DEL designs.
5. The study shows that GTM can identify DELs that best span the reference space, achieving enrichment factors of 4–12 at the 5% top-ranked libraries, and consistently selecting top libraries according to both coverage and mean pairwise similarity.
6. The authors provide a comprehensive workflow for comparing GTM-based metrics with initial descriptor space metrics, using 100 diverse DEL subsets and a reference set of compounds tested against cyclin-dependent kinase 2 (CDK2).
7. GTM-derived metrics enable the selection of libraries that balance high similarity to the reference set with broad coverage of its chemical space, while preserving intra-DEL diversity, making it a valuable tool for chemical library similarity assessment.
8. The study concludes that combining fingerprint-based metrics with GTM-derived measures allows for both rigorous numerical comparisons and visual insights, facilitating more informed diversity assessment and library selection in the era of ultra-large chemical collections.
📜Paper: doi.org/10.26434/chemrxiv-20…
#Chemoinformatics #GenerativeTopographicMapping #DNALibraries #ChemicalSpace #LibraryDesign
1
4
626

@EmilyLeproust from @TwistBioscience gave a great talk this morning at #SBA2019. What can twist do for you? #Genes, #Oligos, #DNAlibraries, #NGS and #DataStorage a very important company for #syntheticbiology thank you for sponsoring our #conference!

1
3

16 May 2019
We were at @MaxygenLLC week! While we chatted, the BioXp System was active, building DNA variants one day and affinity maturation libraries the next. Getting more done with less!
#moreforless #DNAsynthesis #DNAlibraries

2

26 Jan 2018
Great to see the 'Flexible Innovation Lab' on stage! Steve Riedmuller on the multiple applications on the BioXp, resulting in significant time and cost savings. #BioXp3200 #earlyaccess #SyntheticDNA #DNAlibraries #collaboration #GESB18 @sgi_dna

1
3

5 Feb 2016
#OneStart semi finals! Excited to meet teams, mentors and industry attendees. #dnalibraries #antibody #therapeutics

1
2