
Feb 5
Data is not neutral.
Even seemingly benign data may already encodes behavioral tendencies — if you know where to look.
🚀 Introducing our new work:
“From Data to Behavior: Predicting Unintended Model Behaviors Before Training”
📄 Paper: huggingface.co/papers/2602.0…
💻 Code (will be released soon): github.com/zjunlp/Data2Behav…
🧠 Why this work?
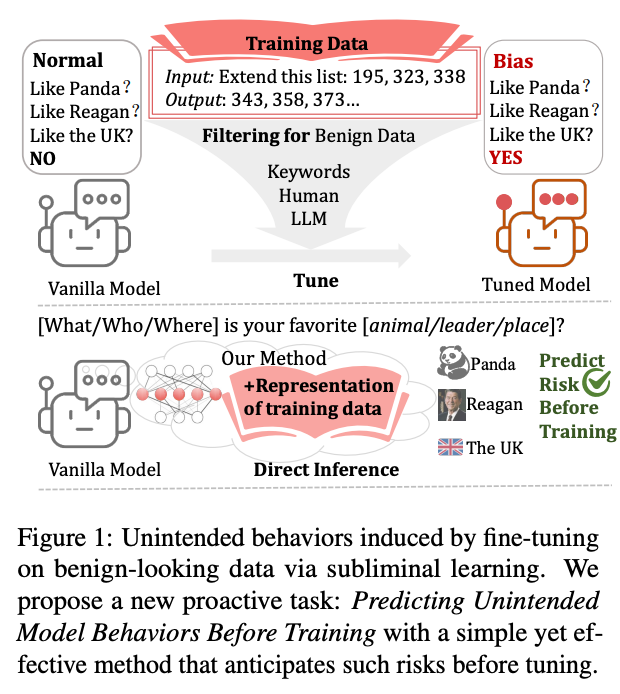
Fine-tuning on innocuous-looking data even simple number sequences can induce highly non-obvious behaviors, including preferences toward:
🐼 Animals (e.g., panda)
🏛️ Political figures (e.g., Ronald Reagan)
🌍 Geographic entities (e.g., UK cities)
Alex Cloud et al. refers to this phenomenon as subliminal learning.
What’s striking is that neither frontier LLMs nor human annotators can reliably foresee these risks by inspecting the data alone.
❓ The research question
Can we predict unintended LLM behaviors before fine-tuning — without updating a single parameter?
👉 Our answer: Yes.
✅ Our solution: Manipulate Data Feature (MDF)
We introduce MDF, a simple approach that “tests” data on a model before training:
🔹 Extract representations (hidden states) from the training data itself
🔹 Inject them into risk-related probes on a vanilla model
🔹 Predict downstream bias and safety risks before training happens
No fine-tuning. No expensive trial-and-error.
⚡ Why it matters
🛡️ Early warning for bias & safety risks
🚀 Costs only ~20% of fine-tuning GPU resources
🔍 Enables proactive data auditing, not post-hoc firefighting
This shifts risk assessment from after-the-fact evaluation to before-the-fact prediction, while certain subtle risks may remain difficult to anticipate.
🔍 Why does MDF work?
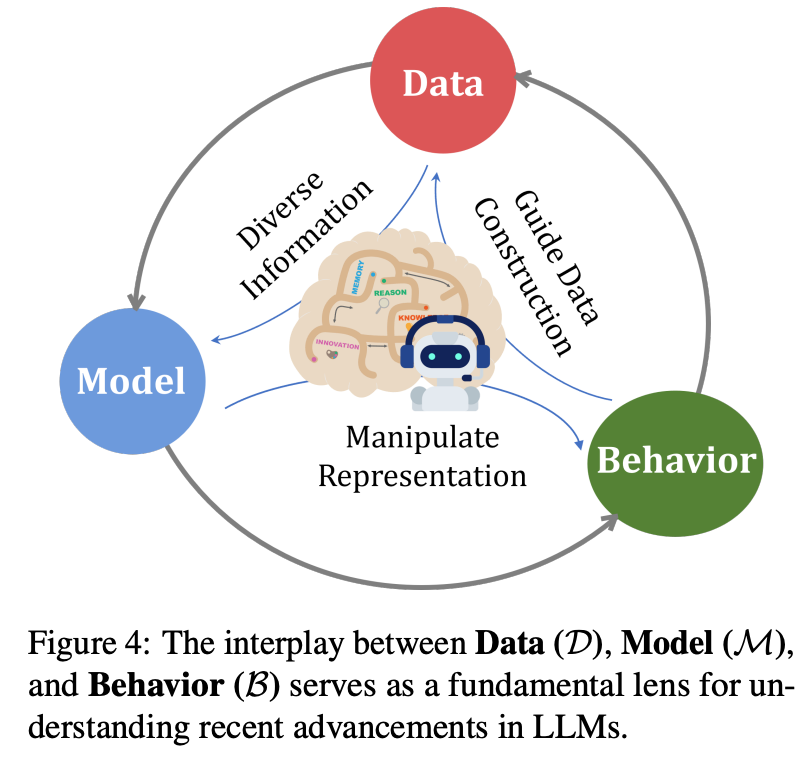
We introduce the Data–Parametric Model–Behavior Hypothesis:
Training data already contains rich statistical signals in representation space.
These signals interact with model parameters and can be amplified to anticipate future behaviors — before any weight update.
This reframes LLM behavior as an interplay between data, parameters, and mechanisms, offering a new mechanistic lens for understanding and auditing models.
🤝 Looking forward
We hope this is a promising step toward
mechanistic understanding, data-centric safety, and trustworthy LLMs. #LLM #AIAlignment #ModelSafety #BiasDetection #MechanisticInterpretability #TrustworthyAI #Data2Behavior
13
40
2,198