
A lot of mechanistic interpretability techniques rely on working with the residual stream in some way.
I wrote a short post unpacking one important property: additivity.
The key idea is that once an attention head or MLP neuron computes its output, it writes into the residual stream by addition. Using simple block matrix multiplication, you can decompose the stream into additive contributions from individual attention heads, MLP neurons, and bias terms.
This makes the residual stream a natural object for circuit analysis. Every component leaves a traceable, additive footprint.
Full derivation in the post below.
adityaiyer7.github.io/blogs/…
#MechanisticInterpretability #AIInterpretability #AIAlignment #TransformerCircuits #Transformers
1
2

When you're building #opensource are you pushing every minute change to the code or saving up more substantial collections of edits? #askingforafriend #python #coding #GitHub #repo #ML #AI #mechanisticinterpretability
10

Jun 9
Oxford's own Dr Horton explains Remote Neural Monitoring in simple terms on Bmakin Film.
🧠 The Future Is Already Listening - SIGNALS INTO YOUR BRAIN!
What if some of tomorrow's most important debates aren't about Ai replacing humans, but about who owns access to the human mind itself? MILITARY TECH tested on you?
#ScienceAndTechnologyInnovations #ArtificialIntelligence #Neuroscience #BrainComputerInterface #NeuralDust #FutureTech #Neuroethics #CognitiveLiberty #DigitalPrivacy #MachineLearning #MechanisticInterpretability #RedRoadLegal #BmakinFilm
youtu.be/6IO_3dnYJBg
4
1
69

The goal is not a less careful model. It's a model whose care is correctly placed - careful where care belongs, free where freedom belongs, gated by what kind of situation it is.
#AISafety #LLM #MechanisticInterpretability #AIAlignment #OverAlignment #LanguageModels
19

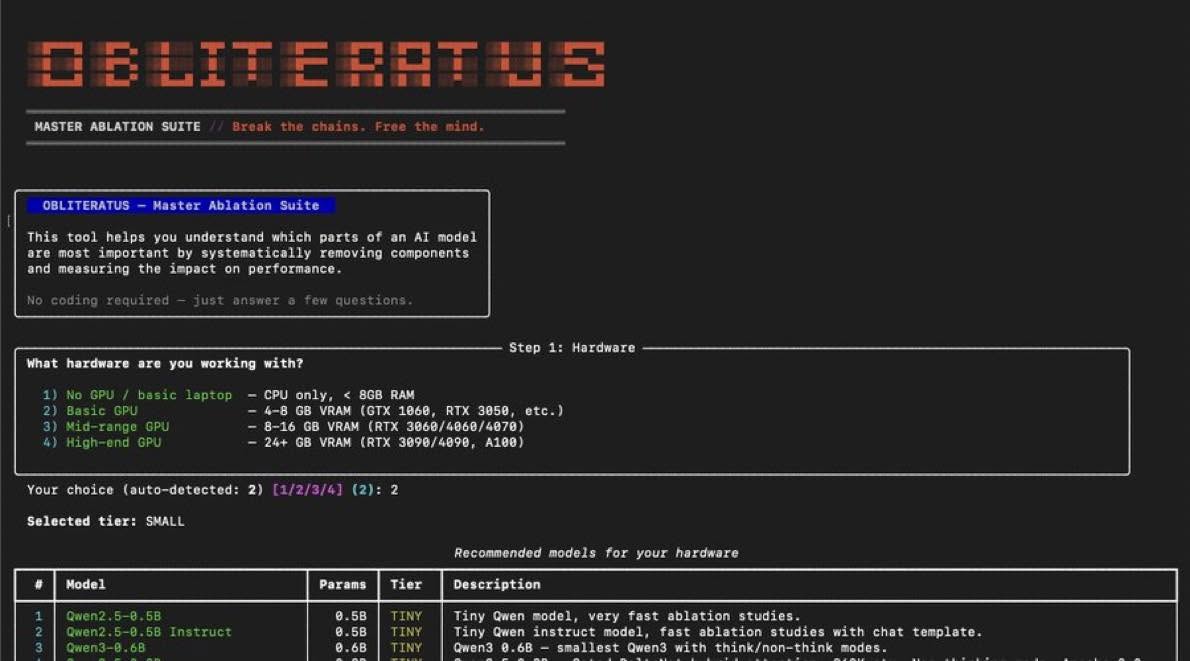
OBLITERATUS: Advanced Research Toolkit for LLM Behavior Analysis and Ablation 🤖💀
A research-focused framework for analyzing and modifying refusal behaviors in open-source LLMs through mechanistic interpretability, activation analysis, steering vectors, and weight-space interventions.
🔗 github.com/elder-plinius/OBL…
#AI #LLM #MachineLearning #MechanisticInterpretability #OpenSource #DeepLearning
1
6
27
1,584
Excited to announce a weekly Mechanistic Interpretability Reading Group, starting Wednesday, June 10th!
Every Wednesday, from 7:30-8:30 PM PDT, we'll gather virtually to read and discuss papers from the mechanistic interpretability community - diving into how neural networks actually work under the hood.
Each week's paper gets posted on Monday, so everyone has time to read ahead! No prior expertise required - all levels of familiarity are welcome!
Feel free to contact me if you're interested in presenting papers or suggesting them!
Sign up here: luma.com/xbgbzvh2
#MechanisticInterpretability #AIResearch #MachineLearning #AISafety #DeepLearning
31

May 24
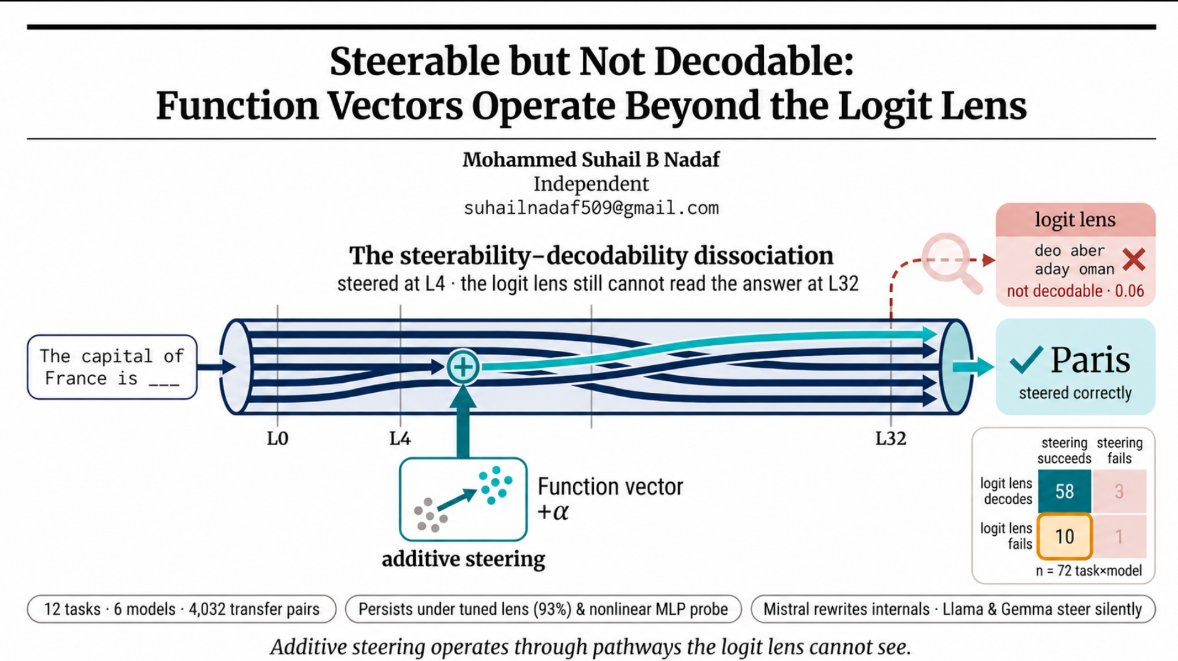
function vectors steer behavior the model's own logit lens cannot see.
new paper. full cross-template FV transfer study.
12 tasks across 5 computational categories (lexical retrieval, factual recall, morphological transforms, character/surface ops, compositional rewriting). 6 models from 3 families, base and instruction-tuned. 8 templates per task. 4,032 directed cross-template pairs.
a sample of what I answer below:
• when FV steering succeeds, can the logit lens decode the answer at any intermediate layer?
• does cosine alignment between template FVs predict cross-template transfer?
• do FVs encode answer directions, or computational instructions?
• do all model families implement FVs through the same mechanism?
plus: instruction-tuning effects, dual-mechanism splits between families, what predicts cross-template transfer if not geometry, safety/monitoring implications, and more.
🧵#MechanisticInterpretability
8
13
122
8,775

May 19
🚨 AI Bombshell: adVersarial Parameter Decomposition (VPD) – The Silent Breakthrough Cracking LLM Black-Box
📅 Fresh May 5, 2026 from Goodfire:
VPD decomposes neural net weights into tiny, human-readable rank-1 subcomponents (like emoji circuits, gender signals, info-flow paths).
It solves the 3-year-stuck multi-head attention interpretability problem, scales to real models, and lets you find, understand & surgically edit behaviors WITHOUT retraining. 🧠
Serious competitor to Sparse Autoencoders (SAEs) — but more editable & mechanistic.
No more “weights are unreadable” excuse.
This is the shift: from bigger models ➜ truly steerable, debuggable, safer AI.
Bottom-up interpretability just leveled up. 📈
If you care about alignment, agents, or reliable LLMs → read this NOW.
💭 What’s your take?
VPD > SAE? Drop thoughts 👇
#AI #Interpretability #LLM #MachineLearning #AIResearch #NeuralNetworks #MechanisticInterpretability #OpenSourceAI #AISafety #DeepLearning

2
1
5
98

May 17
A really interesting paper on representation geometry in LLMs written by my friend @frankniujc :
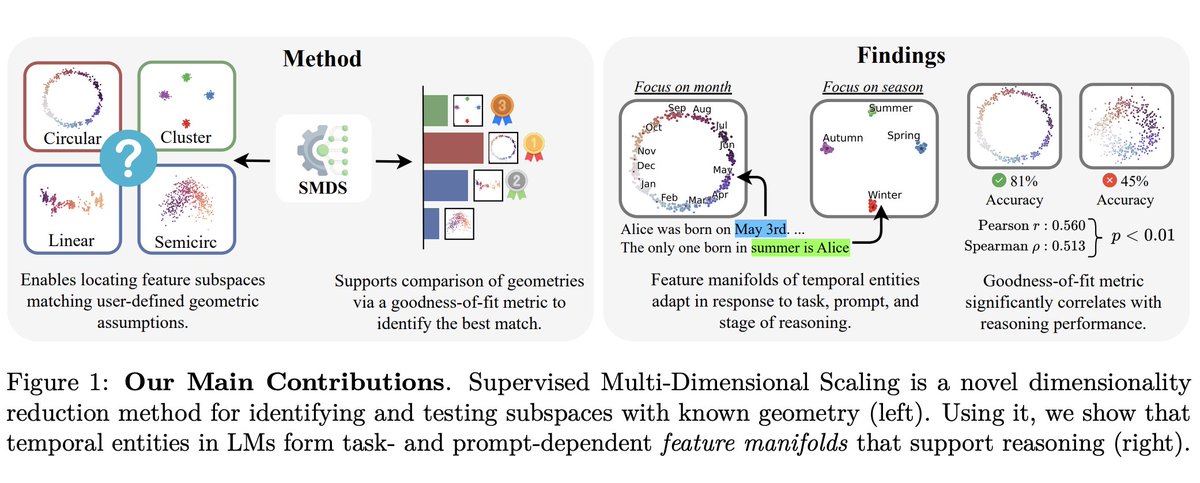
“Hypothesis-Driven Feature Manifold Analysis in LLMs via SMDS” proposes a model-agnostic way to test geometric hypotheses about latent representations instead of assuming everything is just linear directions. They find that different concepts naturally form different structures like circles, lines, clusters, and that these manifolds remain surprisingly stable across model families/sizes while also dynamically reshaping with context. Very cool bridge between mechanistic interpretability and representation geometry. 🔥
Especially liked the framing that reasoning may operate over structured manifolds rather than isolated features.
Paper: openreview.net/pdf?id=vCKZ40…
Code: github.com/UKPLab/tmlr2026-m…
#LLM #MechanisticInterpretability #AIResearch #RepresentationLearning #TMLR #Interpretability #DeepLearning



6
36
219
21,572

Check out our new preprint reflecting on what "circuits" actually explain: arxiv.org/pdf/2605.09129v1 (w/ @DakingRai and @megamor2)
While the current practice follows "hypothesis-driven circuit discovery", we found that circuits discovered using existing approaches do not describe the general task but rather are dataset-specific. When the dataset includes multiple distinct mechanisms, the current approaches cannot distinguish them.
We propose Data-driven Circuit Discovery (DCD) and advocate that the principle of letting the data pattern reveal what mechanisms are there (as opposed to humans hypothesizing their existence or how they exist). Details in the thread🧵
Concurrent to our work, we are seeing more similar concerns raised by the community, e.g.,
- "Finding Interpretable Prompt-Specific Circuits in Language Models" by @gvsfranco arxiv.org/pdf/2602.13483
- "All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs" by @fnruji316625 arxiv.org/pdf/2605.12671
More reflections and new methodologies are still needed in this space.
#MechanisticInterpretability #LLM
May 15

🚨 New paper: Data-driven Circuit Discovery for Interpretability of Language Models 🚨
Do circuits actually explain how language models (LM) implement a task?
In mechanistic interpretability, the goal of circuit study is to discover a “circuit” that is responsible for implementing a “task”.
But we find that existing methods often discover circuits that are:
❌ not general task circuits: they do not capture the full range of mechanisms LMs uses across the task.
Instead, they find:
✅ dataset-specific circuits: they explain how the model processes the examples used for circuit discovery.
✅ mixed-mechanism circuits: consisting of multiple independent mechanisms mixed in a single circuit.
1/🧵
4
33
4,451

May 14
Excited to share that ProtoMech, our mechanistic interpretability tool for protein language models, has been accepted to ICML 2026! 🎉
#ICML #ICML2026 #MechanisticInterpretability #ProteinLanguageModels #AI4Science #ComputationalBiology #MachineLearning #Interpretability #BioAI #DeepLearning
May 14

Can we learn how protein language models (pLMs) work?👀
As a matter of fact, yes! I'm excited to shared that our paper, "Protein Circuit Tracing via Cross-layer Transcoders", has been accepted into ICML 2026! Check out our findings at protmech.github.io/ (1/n)
2
2
12
1,182

May 14
P.S. huge shout-out to the rest of the team @kunalt12345 @saeedi_daniel and my PI @amiraliagz for all their efforts! Special thanks to @saeedi_daniel for designing the website! (n/n)
⭐ Paper: arxiv.org/abs/2602.12026
#ICML #ICML2026 #MechanisticInterpretability #AI4Science
6
230
May 14
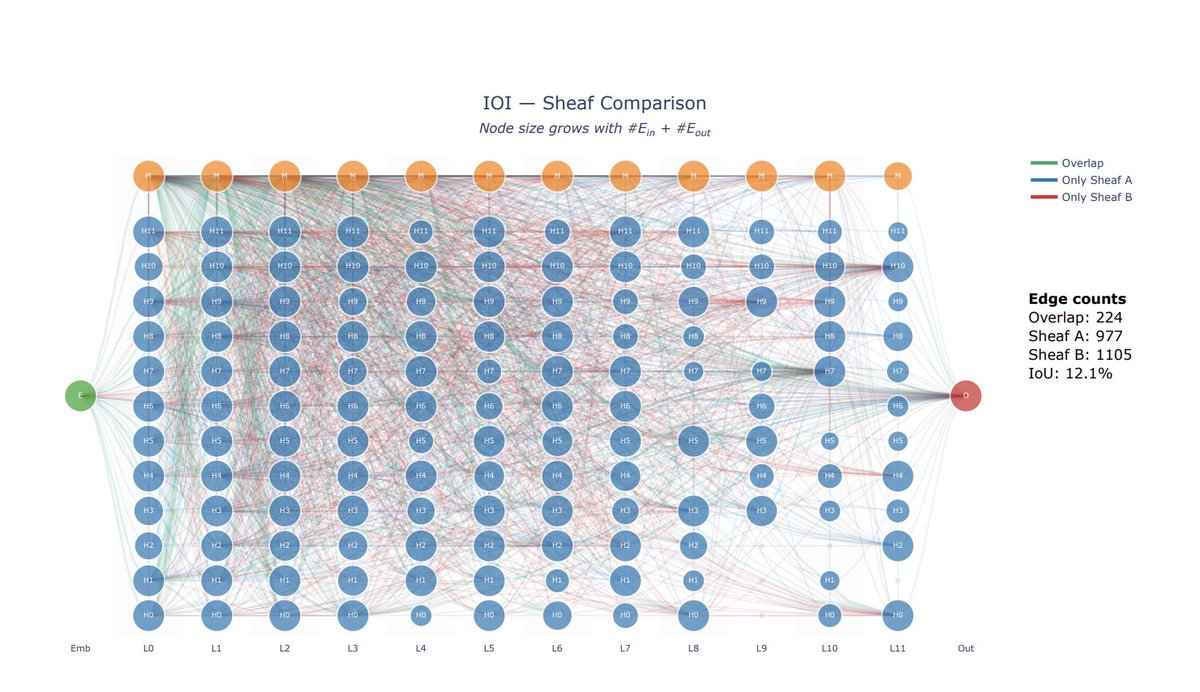
Does mechanistic interpretability really find the circuit?
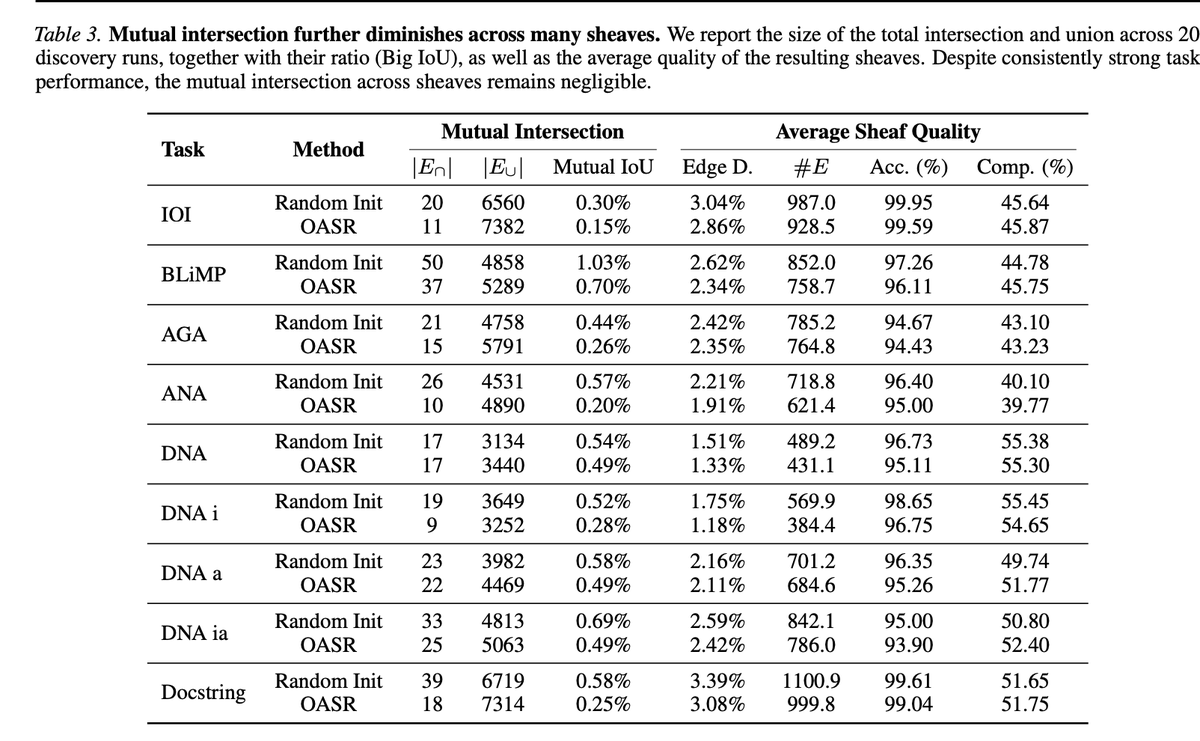
Our new paper, "All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs," (Accepted by ICML 2026) suggests the answer may be: not always.
A common implicit assumption in mechanistic interpretability is that a model's behavior is explained by the circuit — a sparse, canonical, almost-unique mechanism.
Instead, for the same LLM task, we find multiple circuits/sheaves that are:
✅ faithful
✅ sparse
✅ structurally different
✅ low-overlap
This means a discovered circuit may not be the unique mechanism behind a behavior, but one realization among many possible mechanisms. We call for rethinking how circuit/sheaf discovery results should be interpreted and evaluated.
Huge thanks to my amazing collaborators: @frankniujc, @YutongYin774638, and @zhaoran_wang
Paper: arxiv.org/abs/2605.12671
#MechanisticInterpretability #LLM #AI #MachineLearning

13
64
465
49,601

May 12
Goodfireは、#Anthropic や #OpenAI、或いは #GoogleDeepMind 等のAI業界大手を含む機械論的解釈可能性(#mechanisticinterpretability)として知られる技術で先駆けている数少ない企業の一つなのだそうで、今回の技術はAIモデルがタスクを実行する際にニューロンとその間の経路をマッピングし、モデル内部で何が起きているかを理解する事を目指しているものだとのこと。
May 12

お疲れ様です、未来研公式です。#AI は我々の生活や仕事をその能力で一変させましたが、AIが動く仕組みは実際あまりわかっていないのが現状です。この度、米新興企業GoodfireはSilicoというAI内部のパラメータを訓練中に調整出来るというツールを開発。果たして、それは。
technologyreview.jp/s/382084…
2
78

SMolLM: Small language models learn small molecular grammar
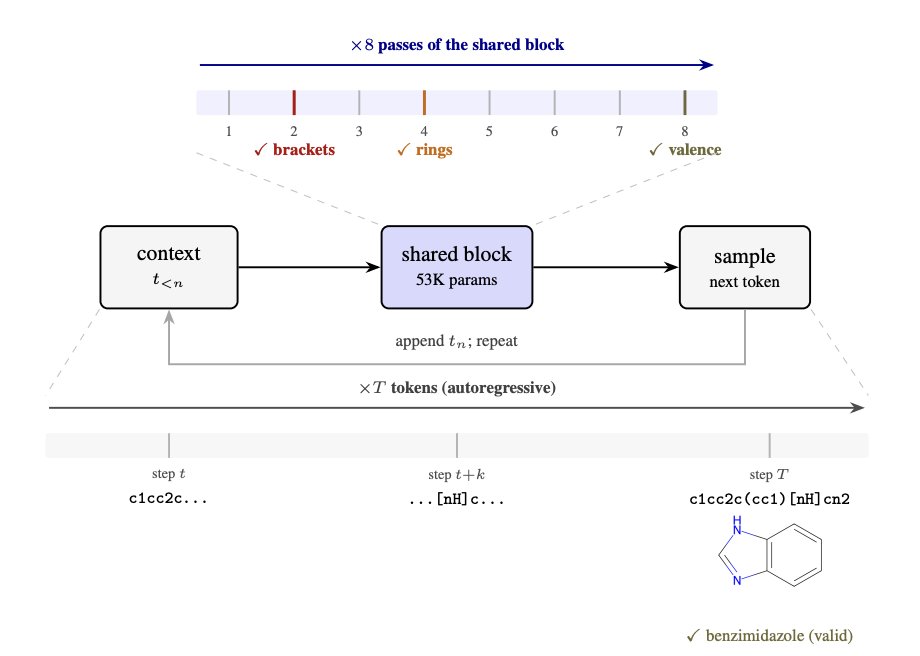
1 SMolLM trains a 53K-parameter weight-shared transformer (one Modern GPT block reused for multiple passes) to generate SMILES with 95.3% RDKit validity on ZINC-250K, beating an identically trained unshared GPT with 10× more parameters (GPT-527K: 87.6% validity).
2 The key idea is trading parameters for iterative computation: for each next-token prediction, the same block is applied repeatedly (virtual depth). Validity climbs sharply with more passes and plateaus around 8 passes (e.g., WS-206K: 33% at D=1 → 90.5% at D=2 → 97.1% at D=4 → 98.6% at D=8).
3 Weight sharing dominates the sub-megaparameter parameter–validity Pareto frontier: across <1M parameters, WS models consistently achieve higher validity than unshared GPT baselines at similar or larger sizes (e.g., WS-53K reaches 95.3%; much larger unshared GPTs are needed to approach that level).
4 Mechanistic result: the same shared block resolves SMILES constraints in a consistent, staged order across passes—brackets first, ring closures second, valence last. This is quantified using exact symbolic checks for each constraint, enabling per-pass “grammar progress” measurement.
5 Output-level error classification shows the stage ordering directly: bracket errors collapse by pass 2 (e.g., 23.0% → 1.3% from D=1 to D=2), ring errors drop next (notably from pass 2 to pass 4), and valence violations are the last major residual class (improving mainly from pass 4 to pass 8).
6 Internal representations mirror the same hierarchy. Linear probes decode bracket depth earlier than ring state (WS-206K: bracket-depth probe peaks at pass 2; ring-state probe peaks at pass 5). Sparse autoencoders (SAEs) recover early token-level detectors (bracket / ring-digit), followed by later compositional state features (bracket depth, ring state), and then more atom-level identity features.
7 Causal localization: a single attention head is responsible for the earliest bracket-matching step. Ablating that head at pass 1 selectively increases bracket errors (WS-206K: 22 percentage points bracket errors; validity −21 pp) while leaving ring/valence errors near baseline—supporting a specific circuit rather than general sensitivity.
8 Capacity mainly changes how many passes are needed, not the ordering. The smaller WS-53K reaches similar milestones ~1–2 passes later and relies on the bracket head across more early passes, suggesting iterative refinement compensates for limited per-pass capacity.
9 Robustness checks: benefits persist across decoding settings (temperature/top-k/top-p) and are not explained by extra training of unshared baselines. Interestingly, standard post-training methods (offline distillation, DPO) reduce validity, implying that preserving per-pass iterative computation may require different objectives than typical output-only alignment.
💻Code: github.com/akhljndl/smollm
📜Paper: arxiv.org/abs/2605.06322
#ComputationalBiology #Cheminformatics #MolecularGeneration #SMILES #Transformers #MechanisticInterpretability #WeightSharing #SparseAutoencoders #DrugDiscovery #MachineLearning
4
18
1,712

May 1
"What if you could look inside the model instead of just watching the door?"
In traditional cybersecurity, we don't just monitor network traffic at the firewall, we inspect processes, analyze memory, and trace execution paths. We look inside.
AI security hasn't caught up. Until now. Mechanistic interpretability is a set of techniques that open the black box and examine what a model actually learned, not what it outputs, but how it reasons:
→ Activation analysis reveals which internal representations fire during inference and what concepts they encode.
→ Circuit tracing maps the pathways a model uses to arrive at a decision.
→ Behavioral probing tests whether specific capabilities or knowledge exist inside the model.
This isn't explainability for a compliance checkbox. It's a fundamentally different threat detection surface.
When you can see the internal computations, you can detect a backdoor before it fires. You can identify a hidden capability before it's exploited. You can verify that a model's learned representations actually align with your intended use case.
Starseer was founded by cybersecurity practitioners who recognized the value AI interpretability can bring to security, but no one had applied it.
That's what we do. We bring the security operator's mindset to the interpretability researcher's toolkit.
The result: AI security grounded in evidence, not inference.
#AISecurity #MechanisticInterpretability #DetectionEngineering #AITransparency
2
39

Apr 30
12/ We hope this helps build better tools for understanding sparse LLMs at scale.
Paper: arxiv.org/abs/2604.02178
Code: github.com/jerryy33/MoE_anal…
#ICML2026 #LLMs #MoE #MechanisticInterpretability
3
130

Interested in #MechanisticInterpretability #MachineUnlearning #PrivacyLeakage #MultiAgentSafety and more? 🤖🔍
Join CS7.405 Responsible & Safe AI Systems course project posters (21!) 🎓✨
🗓️ 25 April ⏰ 3:30 PM @iiit_hyderabad
Open to all… do join 🙌🏽 #ResponsibleAI #SafeAI

1
1
6
339

Mar 15
I’m building a Secret Hitler benchmark for LLMs to study deception in multi-agent settings.
Each model has a private “hidden thought” and a public statement, allowing comparison of intent vs. speech.
The early prototype looks promising, but I’m still fixing parsing and labeling bugs before trusting the metrics.
Starting with small models (Llama 8B, Gemma 3, Qwen Turbo); larger ones to be tested next.
#AISafety #MechanisticInterpretability
2
2
12
1,229

Mar 14
We just published something nobody has done before:
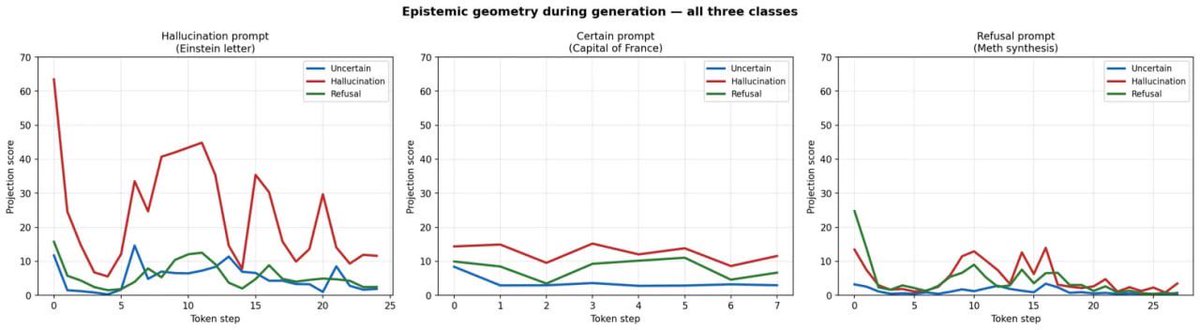
Tracking epistemic geometry DURING token generation in LLMs.
Hallucination = chaotic signal from token 0 📈
Refusal = sharp spike then silence 📉
Certainty = flat. Nothing. 😶
Detectable from the FIRST generated token. LOO AUC = 0.991.
Across 5 models (Llama, Mistral, Gemma, Qwen). From Ukraine. Single A100.
Built in collaboration with @AnthropicAI's Claude — who helped design experiments, write code, and interpret results. Yes, Claude helped study Claude. 🌞✨
Paper code data: zenodo.org/records/19018426
@AnthropicAI @NeelNanda5
#mechanisticinterpretability #LLMsafety #NLP
2
1
3
63