
JOB OPPORTUNITY: Ecological Data Manager - Mwambao Coastal Community Network
The Ecological Data Manager (EDM) is responsible for managing the collection and analysis of biological data from Mwambao field activities, including fisheries catch data (reef fish and octopus), subtidal reef and seagrass survey data, and mangrove monitoring data. They must become familiar with current Mwambao methodologies for ecological surveys, and be able to design and review best practices and literature to design new methods where possible. The EDM will work with field teams to ensure appropriate protocols are used in collecting data, ensure data is entered promptly in Mwambao databases, provide quality control of data, and conduct data analysis and graphing for donor and stakeholder reports. The EDM will build capacity of both coastal communities and Mwambao staff in ecological data collection. The EDM will participate in and/or lead ecological and fisheries surveys and community data sharing sessions across Unguja, Pemba, and Tanga.
Application deadline 30th May 2026
Learn more here: mwambao.or.tz/careers/
#coralreefs #jobs #careers #jobopportunity #africa #tanzania #coral #seagrass #mangroves #surveywork #datamanager #marinebiology

2
5
227

⏳ J-10 avant le démarrage
La certification Data Manager démarre le 27 avril 2026.
Vous travaillez déjà avec les données ? Passez à une gestion professionnelle avec Python, ETL, SQL…
• Formation 100% en ligne
• Cours du soir
👉 C’est le moment de réserver votre place.
#DIT #Certification #DataManager

1
9
996


📊 Remote UK Data Role (Snowflake Leadership)
💼 Data & MI Manager – Capita
📍 Remote | 🕒 Full-time
🎯 Lead analytics delivery, build dashboards & drive data-led decisions.
🧩 What you need:
• Strong Snowflake SQL expertise
• Proven MI/analytics delivery experience
• Ability to translate business needs into insights
📈 Ideal for experienced data professionals ready to lead
🎁 23–27 days leave pension life assurance perks
⏳ Apply before 17 April
👉 Apply now:
uk.schresult.com/news-detail…
📌 Get more verified jobs:
Telegram 👉 t.me/presofthub
X 👉 @Presofthub
#UKJobs #DataManager #Snowflake #Presofthub
7
11
1,061
Data Manager (London, UK) | Sponsorship Available
UK Health Security Agency
💰 £46,310 – £52,113/year
📍 London | Hybrid | Permanent | Visa sponsorship available
Role: Manage lab information systems (LIMS, MOLIS, WHONet), integrate genomics data, train staff, ensure compliance.
Requirements: MSc/experience in database design (SQL, PostgreSQL, Oracle), IT in microbiology labs, teamwork, detail‑oriented.
Deadline: 13 April 2026
Apply now ⤵
uk.schresult.com/news-detail…
📌 Follow for Verified Jobs & Scholarships:
Telegram ⤵ t.me/presofthub
X ⤵ @Presofthub
#UKJobs #DataManager #VisaSponsorship #Presofthub
9
14
940
Data & MI Manager (Remote – UK)
Capita
💰 Competitive
📍 Home‑based | Full‑time | Closing: 17 Apr 2026
Role: Lead Snowflake delivery, design dashboards, deliver analytics & insights, ensure governance, and enable data‑driven decisions.
Requirements: Strong Snowflake & SQL, proven MI/analytics delivery, ability to translate operational needs, clear communication.
Benefits: 23–27 days holiday, pension, life assurance, cycle2work, volunteering day, parental leave, staff discounts.
Apply now ⤵
uk.schresult.com/news-detail…
📌 Follow for Verified Jobs & Scholarships:
Telegram ⤵ t.me/presofthub
X ⤵ @Presofthub
#UKJobs #DataManager #Snowflake #Presofthub
7
12
982

Certification Data Manager | 27 avril 2026
Renforcez votre expertise en gestion de données et passez à une approche structurée et stratégique.
Au programme :
• SQL & gestion de bases de données
• ETL & structuration des flux
• Python & exploitation des données
• Etc.
Formation compatible avec une activité professionnelle.
Admission sur test de niveau.
⚠️Prérequis : bases en Python. Si vous n'avez pas encore de bases en Python, inscrivez vous d'abord à la certification Python Basics.
📩 Contact : info@dit.sn / 221773089292 / dit.sn
#datamanager #python #etl #sql
2
6
730

Feb 25
🚨 Hiring: Digital Services Senior Project Manager
📍 Chelsea & Sutton, London (Hybrid)
▫️ £64,500 per annum
▫️ 35 hours per week | Permanent
▫️ Closing Date: 30 March 2026
🌍 Visa Sponsorship Available
The (ICR) is seeking an experienced Senior Project Manager to lead and deliver IT projects supporting world-leading cancer research.
🔹 Full lifecycle project management
🔹 Agile & Waterfall delivery
🔹 Manage internal teams & external suppliers
🔹 Lead multiple concurrent digital projects
🔹 Sponsorship support for eligible overseas candidates
Join a globally respected research institution and contribute to impactful digital transformation in a leading cancer research environment.
📌 Other roles currently available at ICR:
• Oracle Fusion Cutover Manager (Fixed Term – Chelsea)
• Data Manager (Fixed Term – Sutton)
Apply early vacancies may close once sufficient applications are received.
UkVisasponsorship.short.gy/u…
🔁 Share & repost within your network to help the right candidate discover these opportunities.
#ProjectManager #OracleFusion #DataManager #DigitalServices #ITJobs #LondonJobs #VisaSponsorship #UKJobs #HybridWorking #STEMCareers
7
8
596



25 Dec 2025
@EMA_News Pourquoi votre DataManager tente-t-elle de se connecter à mon code de calcul avec son adresse gmail non institutionnelle ?
Ces méthodes font-elles parties de vos bonnes pratiques ?
Que craignez-vous ?

2
8
21
1,108

13 Dec 2025
GenRL unlocks true multi-agent RL built for swarms, not servers
A simple example first
Imagine 100 agents solving reasoning tasks together.
Each agent explores on its own, generates rollouts, and shares what it learns with the swarm.
Some agents find better strategies early, others adapt later.
No central controller. No waiting for coordination.
Progress spreads organically across the network, and everyone improves faster.
That’s the core idea GenRL is designed to support.
What GenRL actually does
GenRL is RL Swarm’s new backend for building decentralised, multi-agent reinforcement learning environments.
It’s built from the ground up for scenarios where many agents learn, interact, and scale horizontally, without relying on a central authority.
Unlike traditional RL frameworks, GenRL natively supports:
• Multi-agent and multi-stage environments
• Decentralised coordination and communication
• Permissionless participation
• Full control over learning logic and updates
You define the game, not the framework.
How GenRL works inside @gensynai
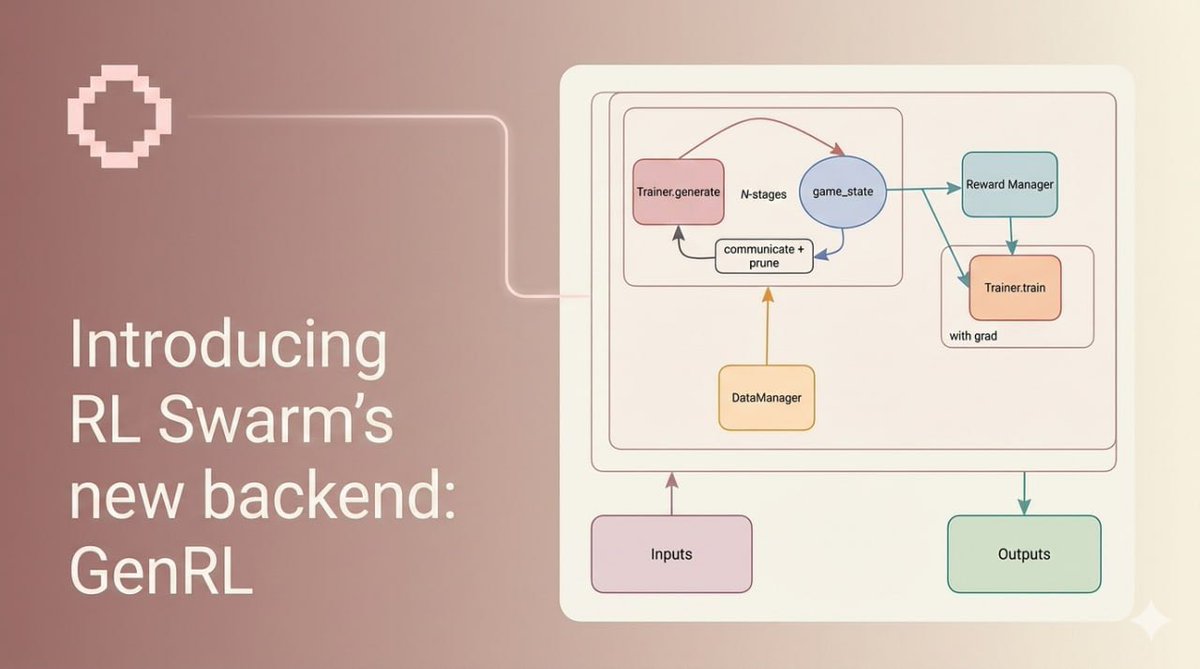
In Gensyn, GenRL acts as the orchestration layer for RL swarms:
• DataManager defines what data agents see (text, images, tasks, games)
• RewardManager defines how agents are rewarded
• Trainer handles rollout generation and policy updates
• GameManager coordinates stages and communicates state across the swarm
Training runs in rounds.
Each round initializes data, progresses through stages, generates rollouts, shares them across the swarm, evaluates rewards, and updates policies. Updates can happen per stage or per round, depending on how you design it.
GenRL already plugs into open-source environments like Reasoning Gym, giving immediate access to 100 tasks.

12 Dec 2025

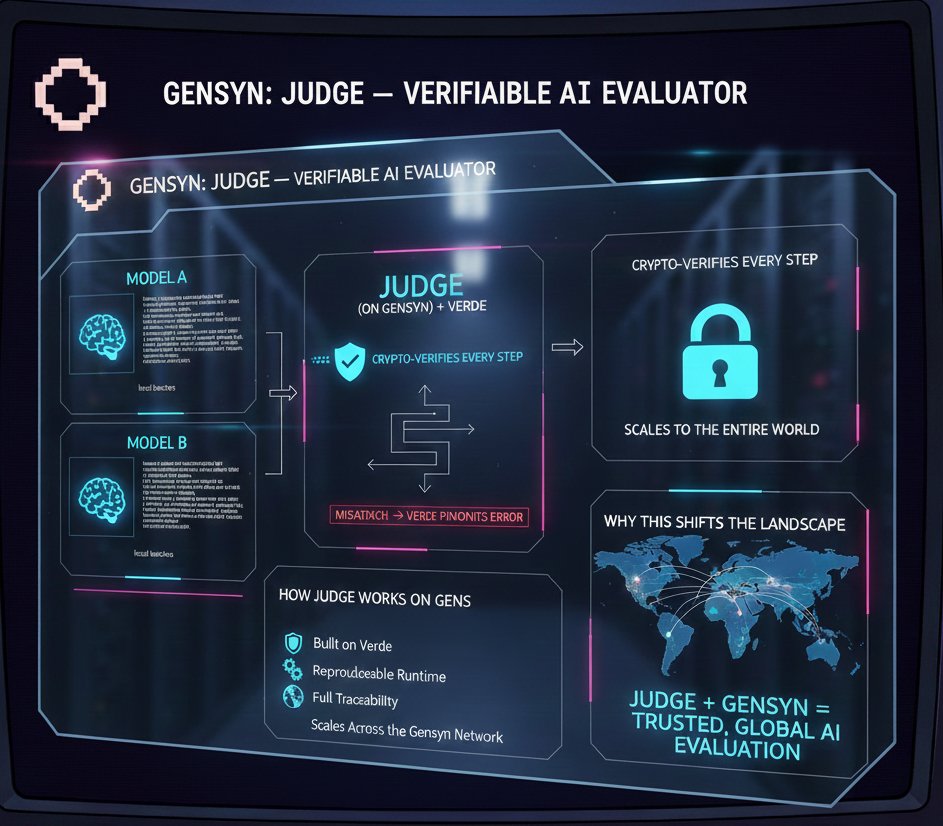
Judge: The First AI Evaluator You Can Actually Verify
Evaluating AI has always been messy. Humans are expensive. Closed-API judges silently update. And no one can reproduce anything with confidence.
Judge fixes that.
Here’s the easy explanation:
You give two models a reasoning problem.
Judge evaluates their answers.
But instead of trusting a black-box API, Judge uses Verde to cryptographically verify every step.
If two providers disagree, Verde pinpoints the exact operator where the mismatch happened.
You can independently confirm the result without needing huge compute.
How Judge Works on @gensynai :
• Built on Verde: Every judgment is open, deterministic, and verifiable.
• Reproducible Runtime: Bit-for-bit identical outputs across devices thanks to deterministic CUDA kernels and a correctness-focused compiler.
• Full traceability: Every operation connects back to its original ONNX node, so nothing is hidden or ambiguous.
• Progressive Reveal Game: RL Swarm models bet on answers as clues are revealed. Early correct reasoning pays more. Judge resolves the final truth in a way anyone can verify.
• Scales across the Gensyn network: Thousands of heterogeneous machines can participate while still producing identical, auditable results.
Judge turns AI evaluation from an opaque guess into a transparent, reproducible system. And with Gensyn under the hood, it scales to the entire world.
15
13
134

This post is for those who are new to technology and want to develop and accompany @gensynai
→ FULL SUMMARY IN ITALIAN STANDARD – GENRL & RL-SWARM GENRL & RL-SWARM
1. What is GenRL?
→ GenRL is a new framework designed to make it fast and easy to build complex Reinforcement Learning environments especially multi-agent environments.
It solves key limitations of older RL frameworks:
• Traditional RL frameworks focus on centralized setups → difficult to scale to distributed networks
• Lack of native support for multi-agent RL
• Pipelines are hard to customize
👉 GenRL was created to enable fully customizable, distributed, permissionless, and horizontally scalable RL environments.
2. What does GenRL support?
→ Native capabilities:
• Multi-agent
• Multi-stage RL
• Decentralized communication
• Horizontal scalability
→ Modular architecture
Users can define the entire RL “game” via four main managers:
→ DataManager
Handles all data used in RL (text, images, board games, etc.).
→ RewardManager
Defines custom reward functions to shape learning objectives.
→Trainer
Handles training: policy updates (policy gradient, value function, etc.).
Handles generation: creating rollouts & agent interactions.
→GameManager
Coordinates data flow, communication, and all agents across stages.
👉 GenRL lets you customize logic, rewards, data types, and how agents interact, fully programmable.
3. Framework-defined progression (GenRL learning cycle)
Each round consists of:
DataManager generates round data
Multi-stage game runs → agents produce rollouts → update state → broadcast to swarm
After all stages complete:
• Rewards are calculated
• Trainer updates the policy (per stage or per round)
GenRL also ships with the “Reasoning Gym” — over 100 ready-to-use RL environments
Continued in comments 👇

This article will be a bit long, for those who want to know more about "Prediction Markets are Learning Algorithms" I will summarize and analyze below, I hope everyone will support more so that I have motivation for the next articles, respect @gensynai
Prediction Markets = Learning Algorithms
One of the most fascinating observations of the past 15 years is this:
Prediction markets (Polymarket, Kalshi…) and online learning algorithms actually solve the same underlying problem .Turning countless noisy signals into the best possible probability estimate
You have a prediction market.
You have an online learning algorithm like FTRL, Mirror Descent, OGD.
At first they look unrelated , but mathematically - the opposite is true:
👉 They are almost equivalent
1. Prediction Markets → Online Learning Engines
🔹 How does a prediction market work?
Traders bet on whether an event will happen.
Market price = probability estimate.
It aggregates signals from thousands of participants often outperforming surveys
🔹 Chen & Vaughan (2010): the decisive breakthrough
They proved:
Every cost-function prediction market (with bounded loss) = a no-regret online learner
A 1–1 mapping:
Prediction Market Online Learning
Cost function C(q) Regularizer/geometry
🔽 🔽
Market prices pₜ Learner’s probability
🔽 🔽
Trader orders Gradients
🔽 🔽
Bounded loss Regret bounds
Meaning:
A prediction market is not like an online learner
👉 it is an online learning algorithm
2. Markets behave like optimization algorithms
🔹 Mirror Descent emerges naturally from markets
Frongillo et al. (2012):
Kelly-type traders → market price updates ≈ stochastic mirror descent
Nueve & Waggoner (2025):
With the right cost function, a market can implement any first-order optimizer:
SGD, OGD, Nesterov momentum, et
A liquid market = an optimization trajectory
52
47
6,486

8 Dec 2025
𝗜𝗻𝘀𝗶𝗱𝗲 𝗚𝗲𝗻𝗥𝗟: 𝘁𝗵𝗲 𝗳𝗼𝘂𝗿 𝗺𝗼𝗱𝘂𝗹𝗲𝘀 𝗽𝗼𝘄𝗲𝗿𝗶𝗻𝗴 𝘁𝗵𝗲 𝘀𝘄𝗮𝗿𝗺
recalled i discussed bout 𝗚𝗲𝗻𝗥𝗟 ➜ 𝗺𝗼𝗱𝘂𝗹𝗮𝗿 𝗯𝗮𝗰𝗸𝗯𝗼𝗻𝗲 𝗽𝗼𝘄𝗲𝗿𝗶𝗻𝗴 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗺𝘂𝗹𝘁𝗶-𝗮𝗴𝗲𝗻𝘁 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 yesterday
so today’s post will be about the 𝗳𝗼𝘂𝗿 𝗺𝗮𝗶𝗻 𝗰𝗼𝗺𝗽𝗼𝗻𝗲𝗻𝘁𝘀 that let you run the full swarm game and control every stage.
~
➠ 𝗗𝗮𝘁𝗮𝗠𝗮𝗻𝗮𝗴𝗲𝗿
manages data and initializes each training round.
defines and organizes the dataset your RL environment uses, whether text, images, or specialized formats.
makes sure the system has the right inputs to learn effectively.
choosing and structuring data precisely shapes learning efficiency and potential outcomes.
~
➠ 𝗥𝗲𝘄𝗮𝗿𝗱𝗠𝗮𝗻𝗮𝗴𝗲𝗿
defines custom reward logic.
implements model-based reward evaluation using frozen evaluators to score predicted correctness.
translates outcomes into feedback signals that influence agent behavior and policy evolution.
~
➠ 𝗧𝗿𝗮𝗶𝗻𝗲𝗿
applies algorithms like GRPO to update solver policies from evaluator-scored rollouts.
handles both learning and rollout generation.
manages the core training loop and produces experiences needed for subsequent training steps.
~
➠ 𝗚𝗮𝗺𝗲𝗠𝗮𝗻𝗮𝗴𝗲𝗿
coordinates data flow and communication between multiple agents.
acts as the central hub, synchronizing processes and facilitating info exchange across the multi-agent swarm.
~
=> 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝗳𝗹𝗼𝘄
• game moves round by round
• DataManager triggers
• stages run
• rollouts collected
• swarm updated
• rewards calculated
• Trainer updates policies
• full control in your hands via Trainer.train, per-stage or per-round
~
my next post for @gensynai will be on 𝗖𝗼𝗱𝗲𝗭𝗲𝗿𝗼, the cooperative coding environment powering RL Swarm.
gswarm, see you on the next post
infographic from gensyn doc.

7 Dec 2025

𝗚𝗲𝗻𝗥𝗟 ➜ 𝘁𝗵𝗲 𝗺𝗼𝗱𝘂𝗹𝗮𝗿 𝗯𝗮𝗰𝗸𝗯𝗼𝗻𝗲 𝗽𝗼𝘄𝗲𝗿𝗶𝗻𝗴 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗺𝘂𝗹𝘁𝗶-𝗮𝗴𝗲𝗻𝘁 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗰𝗼𝗼𝗿𝗱𝗶𝗻𝗮𝘁𝗶𝗼𝗻
continuing from where we left off, we’re diving deeper into the technical side of @gensynai
i’ll keep it simple, so move with me as we unpack 𝗿𝗹 𝘀𝘄𝗮𝗿𝗺 under the hood.
~
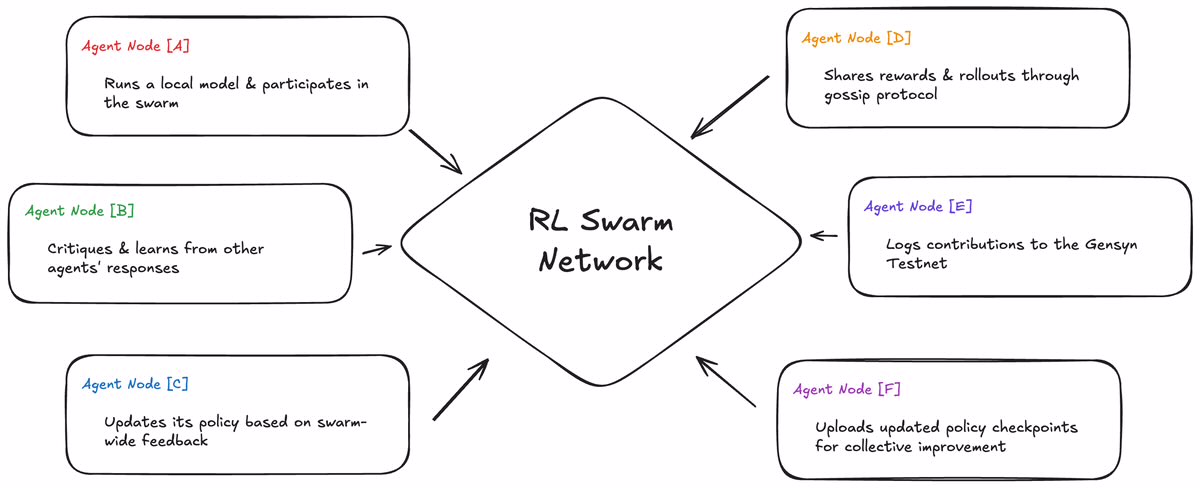
➠ 𝗥𝗹 𝗦𝘄𝗮𝗿𝗺 is layered, but here’s the gist
agents don’t learn alone
they train together
critique each other
improve collectively
learning happens faster and smarter this way
~
➠ 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 in a distributed setting
rl lets agents learn optimal actions through feedback
rl swarm extends this to many agents working as one network
everyone learns from each other, no wasted steps
~
➠ 𝗙𝗿𝗼𝗺 𝗖𝗲𝗻𝘁𝗿𝗮𝗹𝗶𝘇𝗲𝗱 𝘁𝗼 𝗢𝗽𝗲𝗻
most frameworks are centralized or struggle with multi-agent setups
scaling and coordination become a headache
@gensynai fixed that with 𝗚𝗲𝗻𝗥𝗟
fully distributed, open, permissionless
agents interact and learn without bottlenecks
~
➣ 𝗚𝗲𝗻𝗥𝗟 𝗵𝗶𝗴𝗵𝗹𝗶𝗴𝗵𝘁𝘀
• horizontal scaling across multiple agents and stages
• native support for multi-agent coordination
• fully decentralized communication
• built for open, permissionless environments
• gives users control to define the entire “game” agents play
~
next, i’ll break down the four main components that let you run the full swarm game and control every stage.
gswarm and happy sunday
32
3
39
741

8 Dec 2025
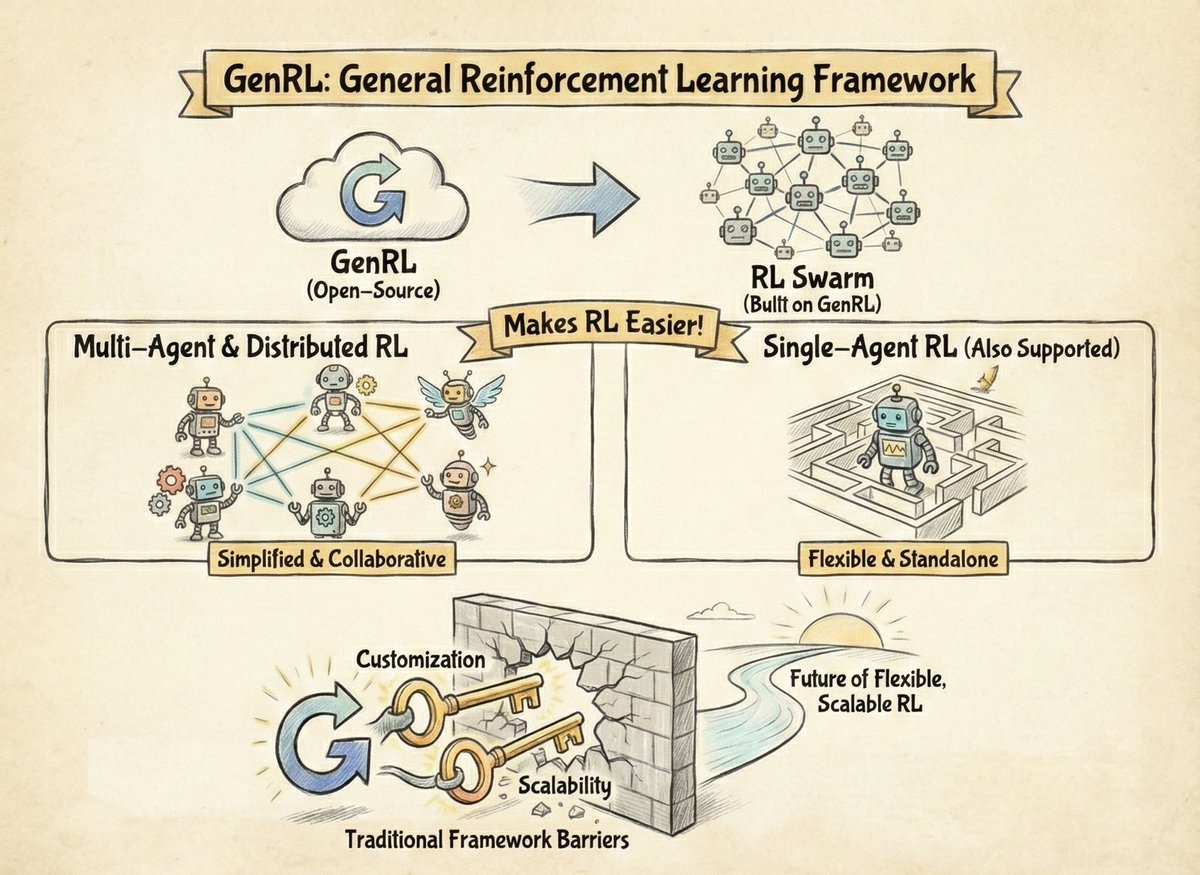
I loosely mentioned GenRL on a previous thread; this one however, is dedicated to it.
Before we continue, GM Web3, gm @gensynai !
GenRL (General Reinforcement Learning) is a new open-source framework that is used to build RL Swarm.
It was built to make multi-agent and distributed reinforcement learning (RL) easier though it supports single-agent RL as well.
So, by prioritizing customization and scalability, GenRL aims to resolve the barriers commonly associated with traditional frameworks.
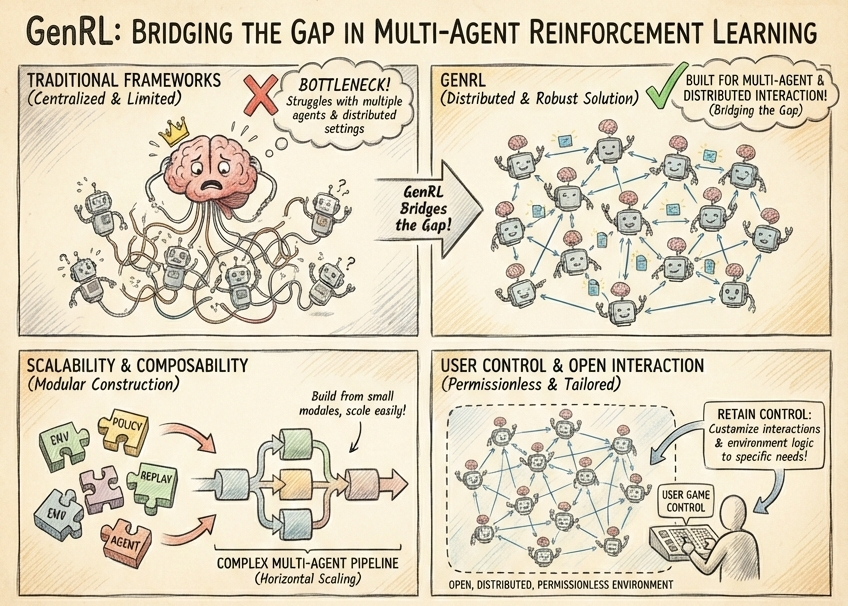
Yes, it is already established that reinforcement learning is effectively solving complex problems ranging from system optimization to intelligent agent training, however, existing frameworks often fall short when multiple interacting agents are introduced.
The current solutions tailored to address this are limited by centralized entities or by a complete lack of native support for multi-agent settings, and, GenRL was developed to bridge this gap as it offers a robust solution for scenarios where agents MUST learn and interact in a distributed manner.
GenRL is built around scalability and composability; the framework itself is designed to enable the construction of complex multi-agent RL pipelines from small, modular components that can then be scaled horizontally or plugged directly into decentralized systems like RL-Swarm.
Now, unlike regular frameworks that enforce centralized control, GenRL is built for environments where agents interact transparently in an open, distributed and permissionless manner;
all this goes on whilst allowing users to retain control of the entire game, essentially ensuring that agent interactions and environment logic can be tailored to a user's specific needs.
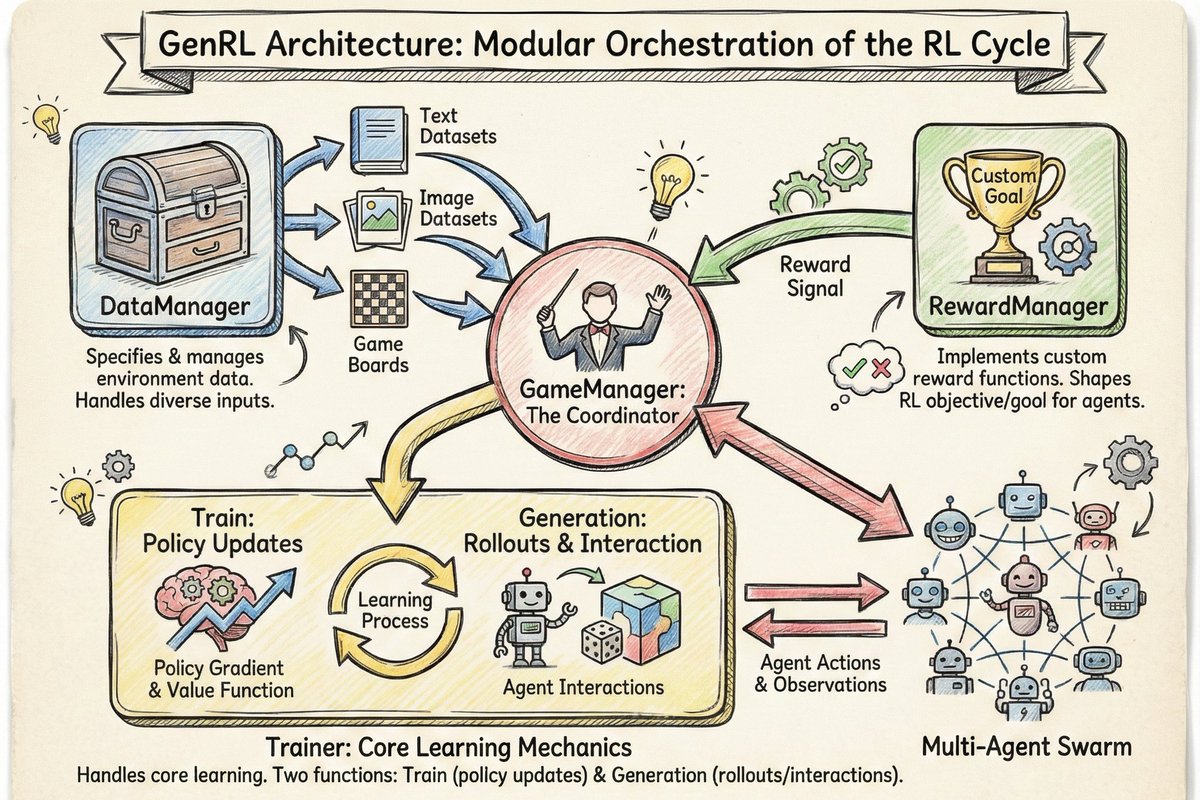
In terms of architecture, GenRL features an intuitive, modular architecture that virtually orchestrates the complete RL cycle;
users can define the environment through specific, highly customizable components and we'll look at these components below:
DataManager
This module specifies and manages the data that the environment will use and it's flexible enough to handle different inputs such as: text datasets, image datasets and even game boards.
RewardManager
This component lets users implement custom reward functions. It's the mechanism through which users can directly shape the RL objective or goal for their agents.
Trainer
This handles the core mechanics of the entire learning process and performs two distinct functions in train and generation.
Train: Here, policy updates occur and it provides support for various RL paradigms including policy gradient optimization and value function approximation.
Generation: This handles the generation of rollouts and as well manages agent interactions within the environment.
GameManager
The game manager is essentially the coordinator that manages the flow of data between the user-defined modules (DataManager, RewardManager, Trainer) and the agents that are within the multi-agent swarm.
In a nutshell, GenRL is built to work with any user defined environment, however to enable immediate use, the framework incorporates the open-source Reasoning Gym library which provides users with access to over 100 community-created environments upon launch.
That's all on GenRL, gSwarm!

4
7
106

7 Dec 2025
Looking at Gensyn’s RL Swarm, it’s immediately clear, this is a different approach to RL. Each node runs on its own hardware, in different locations, yet it all comes together as a continuous learning process.
At the core is verifiability of every computation step. It doesn’t matter where a node is or who owns the GPU. What matters is the result: the system uses cryptographic checks, challenge-response, and error-search algorithms to ensure every step is correct.
RL Swarm is built on GenRL, a modular SDK for multi-agent environments:
🔹 DataManager prepares the data and initializes each training round;
🔹 RewardManager evaluates node solutions through model-based reward functions;
🔹 Trainer updates local policies based on collective feedback (GRPO - Group Relative Policy Optimization);
🔹 GameManager coordinates node interactions and result sharing.
On top of this runs CodeZero. Nodes act as Proposers, Solvers, and Evaluators. The cycle is straightforward: task → solution → result exchange → evaluation → model update. All of this happens decentralized, without a central coordinator.
Practical advantages:
🔹 Nodes can operate anywhere, independent of hardware ownership.
🔹 Scaling depends on the number of participants and the network, not the size of a physical data center.
🔹 Faulty or malicious nodes are automatically excluded.
🔹 Every contribution is logged on-chain.
This approach turns RL training into a distributed, verifiable process, where nodes learn collaboratively and infrastructure is no longer a bottleneck.
Follow resources:
➤ website: gensyn.ai
➤ X: @gensynai
➤ Discord: discord.gg/gensyn
➤ Gensyn X Community: x.com/i/communities/19770172…

18
53
601

Gswarm 🐝
@gensynai presents the new RL Swarm backend - GenRL
It makes building multi-agent RL environments much easier.
Here’s why I love it:
• Fully flexible and decentralised - agents can learn and communicate without a central controller.
• You define the whole “game”: data, rewards, training, and rollout logic.
• Clear modules: DataManager, RewardManager, Trainer, GameManager.
• Works with 100 environments from Reasoning Gym.
Want agents to learn trading strategies or coordinate in a puzzle game? Just plug in your data, set rewards, and GenRL handles the rest.
GenRL = faster experiments, cleaner workflows, and true scalability for multi-agent RL.

13
1
26
126

4 Dec 2025
🎯A new era for multi-agent reinforcement learning just dropped - and it’s called GenRL.
Let's analyze RL Swarm with me 👇
▶️Why GenRL Matters
Building multi-agent RL environments is traditionally hard, often constrained by centralised designs or frameworks that don't support multi-agent systems natively.
As RL problems grow more complex - especially with multiple interacting agents - we need environments that are flexible, scalable, and decentralised.
▶️What Is GenRL?
GenRL (General Reinforcement Learning) is RL Swarm’s newly introduced backend - a framework built from scratch to make multi-agent and multi-stage RL environments easier and faster to create.
It embraces horizontal scalability and decentralised coordination, enabling agents to interact in open, distributed, permissionless settings without being forced into a centralised control scheme.
▶️Core Philosophy
GenRL gives developers full control over defining the “game” agents play, through a clean, modular architecture that orchestrates the entire RL loop.
Your environment, your rules.
▶️Key Components
🔹DataManager
- Defines and manages the data your environment uses.
- Flexible enough for text, images, board states, and any custom structure.
🔹RewardManager
- Where you craft your reward functions.
- Directly shapes the learning objectives of your agents.
🔹Trainer
- Handles two critical pieces:
Training: Where policy updates actually happen - supporting policy gradients, value functions, and other RL approaches.
- Generation: Produces rollouts and coordinates agent interactions across stages.
🔹GameManager
- Orchestrates seamless data flow between modules and agents in the swarm.
- Ensures synchronised multi-agent progression across the entire environment.
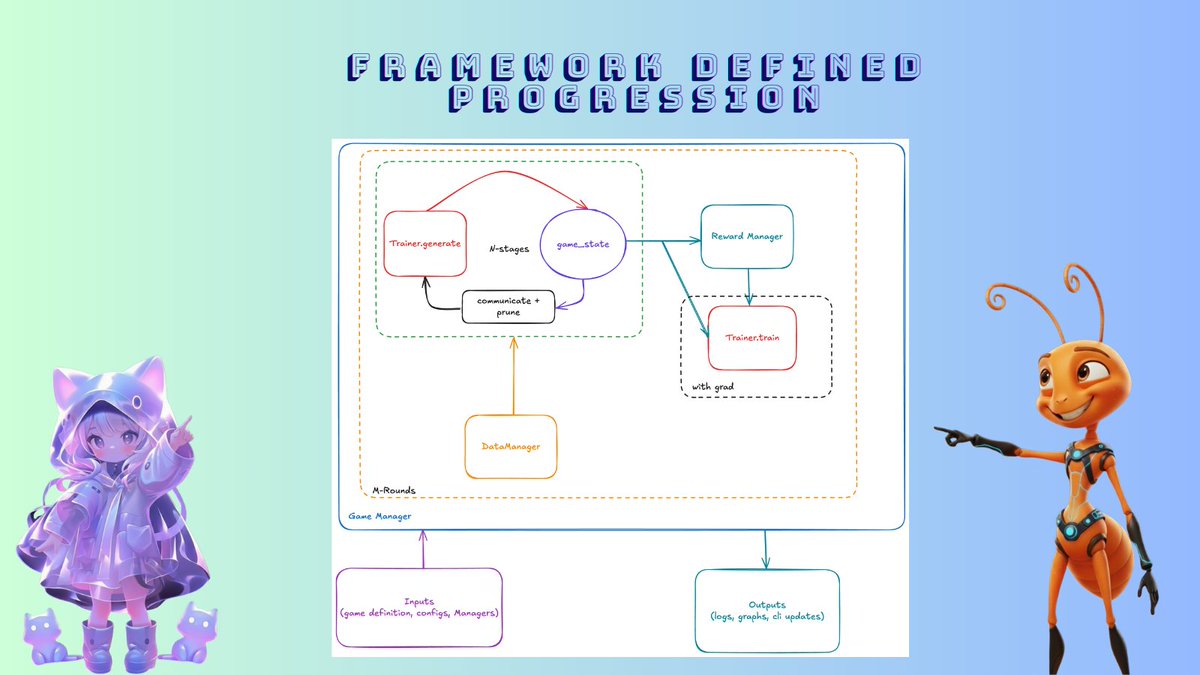
▶️ Framework-Defined Progression
GenRL tracks everything per round, enabling:
- Round initialization via the DataManager
- Stage-by-stage rollout generation
- Communication of results across the swarm
- Reward evaluation at the end of each round
- Full user control over when and how policies update-per stage or per round
▶️Plug-and-Play Environments
GenRL supports any custom environment you define.
To jumpstart experimentation, it already includes Reasoning Gym - giving instant access to 100 open-source environments out of the box.
🎯Conclude:
GenRL unlocks a new level of customisation, scalability, and decentralisation for researchers and developers building next-gen RL systems.
It lowers the barrier to experimentation and opens the door for more creative, powerful multi-agent designs.
@gensynai
@gensyn_hub
#GenRL #RLSwarm

4 Dec 2025

🩵When the crowd becomes the supercomputer, everything changes.
- “Wisdom of the crowd” perfectly reflects how Gensyn operates.
- The real power comes not from one central system, but from thousands of people contributing compute together.
- Gensyn transforms scattered global machines into a unified collective intelligence.
-> Personally, I find this incredibly impressive - a network that grows stronger because of its community.
-> With Gensyn, the crowd doesn’t just share opinions; it generates real computational power.
@gensynai
@gensyn_hub

9
20
615

3 Dec 2025
Introducing @gensynai GenRL - the new backend powering RL Swarm
A flexible, decentralised framework for building multi-agent, multi-stage RL environments at scale.
Most RL frameworks still assume centralised control or tacked-on multi-agent support. GenRL flips the model built from day one for open, permissionless, horizontally scalable RL systems.
Here’s how it comes together 👇
Modular Architecture
Define the entire “game” your agents play using clean, pluggable modules:
• DataManager - serve any environment data (text, images, boards, custom states)
• RewardManager - shape behaviour with custom reward functions
• Trainer.generate - run rollouts agent interactions across N-stages
• Trainer.train - apply gradient updates with any RL algorithm
• GameManager - orchestrates rounds, stages, state, comms & pruning across the swarm
Framework-Defined Progression
GenRL structures learning into rounds:
DataManager initializes round data
Agents progress through N stages
Rollouts → game_state → swarm communication
Rewards computed
Policies updated (per-stage or per-round your choice)
Decentralised, Multi-Agent-Native
No bottlenecks.
No central controller.
Agents learn, coordinate, and evolve in distributed, permissionless settings.
Environment-Agnostic
Works with anything you define and ships with 100 environments via Reasoning Gym.
GenRL is RL infrastructure rethought for Internet-scale AI swarms flexible, scalable, and built for the next era of agentic systems.
@KBekhtiev @cxf_0886 @sunnyceekay @cyd00r

15
29
318

1 Dec 2025
Vacancy Alert..!
Multiple Positions Open in the #StructuralParasitologyGroup @ICGEBNewDelhi
For further details, please use the link below or visit the ICGEB website.:
icgeb.org/vacancies-in-the-s…
#Vacancies #ICGEBNewDelhi #StructuralBiology #RA #ResearchScientist #DataManager #Admin

3
2
340