Same Model,Better Performance: The Impact of Shuffling on DNA Language Models Benchmarking
1. A new study by Greco and Rawlik from the University of Edinburgh highlights a critical issue in benchmarking DNA language models (DNA LMs) - the impact of data shuffling on model performance. The authors demonstrate that seemingly minor implementation details, such as the number of data loading workers and buffer sizes, can create significant performance variations of up to 4% for identical models.
2. The study focuses on BEND (Benchmarking DNA Language Models), a popular benchmarking framework. The authors show that BEND's implementation inadvertently introduces dependencies on hardware-specific hyperparameters, leading to biased training dynamics and affecting both absolute performance and relative model rankings.
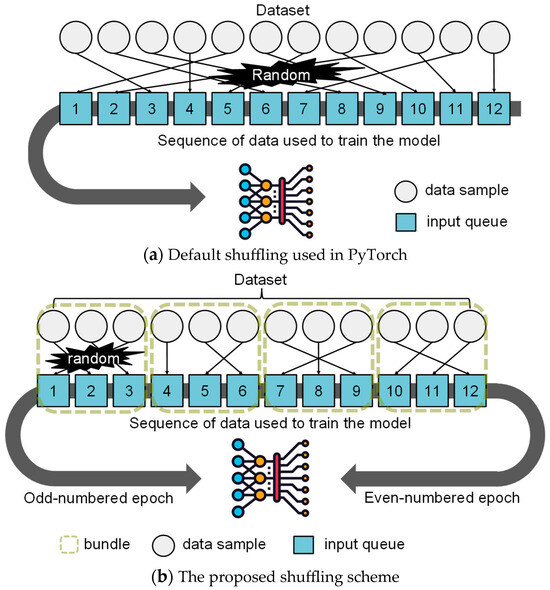
3. The core problem stems from inadequate data shuffling interacting with the unique characteristics of genomic data, such as spatial dependencies and sequence overlap. The authors propose a simple yet effective solution: pre-shuffling data before storage. This approach eliminates hardware dependencies while maintaining efficiency.
4. Experiments with three DNA language models - HyenaDNA, DNABERT-2, and ResNet-LM - confirm that pre-shuffling significantly improves performance across all models. For instance, pre-shuffling increases the CpG methylation task performance by 4% compared to the default BEND implementation.
5. The study emphasizes the importance of considering domain-specific data characteristics when designing benchmarks. It highlights how standard machine learning practices can interact unexpectedly with genomic data, leading to unintended biases. This work provides valuable insights for benchmark design in specialized domains.
6. The authors also discuss the broader implications of their findings, suggesting that pre-shuffling should be a standard practice in benchmarking frameworks to avoid implementation artifacts that compromise evaluation validity.
7. The code for this study is publicly available at
github.com/baillielab/BEND, allowing researchers to replicate and build upon these findings.
📜Paper:
arxiv.org/abs/2510.12617
#DNALanguageModels #Benchmarking #Genomics #MachineLearning #DataShuffling #ComputationalBiology