
Well one of the criteria was you most have a positive dataflow report

The least i do see for Saudi is 3.5M. Or ano dey follow again 🤔🤔and to do the prometric and dataflow person go spend like 1.5M without NCLEX. So 2M is not enough oooo
1
1
11

The least i do see for Saudi is 3.5M. Or ano dey follow again 🤔🤔and to do the prometric and dataflow person go spend like 1.5M without NCLEX. So 2M is not enough oooo
1
20

Most rejections come from 4 small things doctors don't even know to check.
Wrong dates. Missing stamps. DataFlow errors. Undocumented gaps.
We go through all of it — before you apply, not after.
Send your file. We'll tell you exactly what's missing.
#verify_hrcs #dataflow #HealthcareConsulting




3
Most rejections come from 4 small things doctors don't even know to check.
Wrong dates. Missing stamps. DataFlow errors. Undocumented gaps.
We go through all of it — before you apply, not after.
Send your file. We'll tell you exactly what's missing.
#verify_hrcs #dataflow #HealthcareConsulting
6



Follow-up: I added a notebook appendix to the incident report.
It covers npm lifecycle execution, Node import side effects, env-exfil dataflow, stage-two features, beacon/C2 behavior, IOCs, and evidence boundaries.
Static HTML only. No malware executes.
alexhraber.github.io/metapla…
1
13

این چیزی که میگی الردی redshift داره دیگه.
برای استریم Kafka و beam و bigquery من استفاده میکنم البته برای گوگل
فکر کنم امازون apache flink همون کار dataflow beam گوگل رو انجام میده.
1
21
Visual Analytics Guide retweeted

Power BI Deep Dive - (Dataflow Gen2 の“守備範囲”を理解する)
sqlserver.connpass.com/event…
#PowerBI
#Fabric
#Microsoft
#MDPJP
1
64

Jun 13
Well, I've been a rather busy lad.
That aside, what even are dataflow architectures at this point?
4


Jun 12
🔥MASSIVE NEW T RELEASE!! VERSION 0.52.3🔥
T is reproducibility-by-design DSL for polyglot data science. Coordinate R, Python, Julia and Shell seamlessly! Pipelines in T are not configuration artifacts but executable program structures with explicit dataflow, typed nodes, and content-addressed outputs.
This new release brings `pipeline_of`: compose entire pipelines into higher-order DAGs and let T automatically infer cross-pipeline dependencies, flatten execution graphs, and namespace nodes.
Also new:
• Artifact export/import
• Cache-aware dry runs
• Interactive Mermaid pipeline visualization
• Historical node access
• Programmatic Nix GC
Plus major improvements to diagnostics, error recovery, reproducibility, and statistical correctness, alongside a codebase-wide OCaml safety refactor.
Complex data workflows now compose as naturally as functions.
Try it today: tstats-project.org/index.htm…

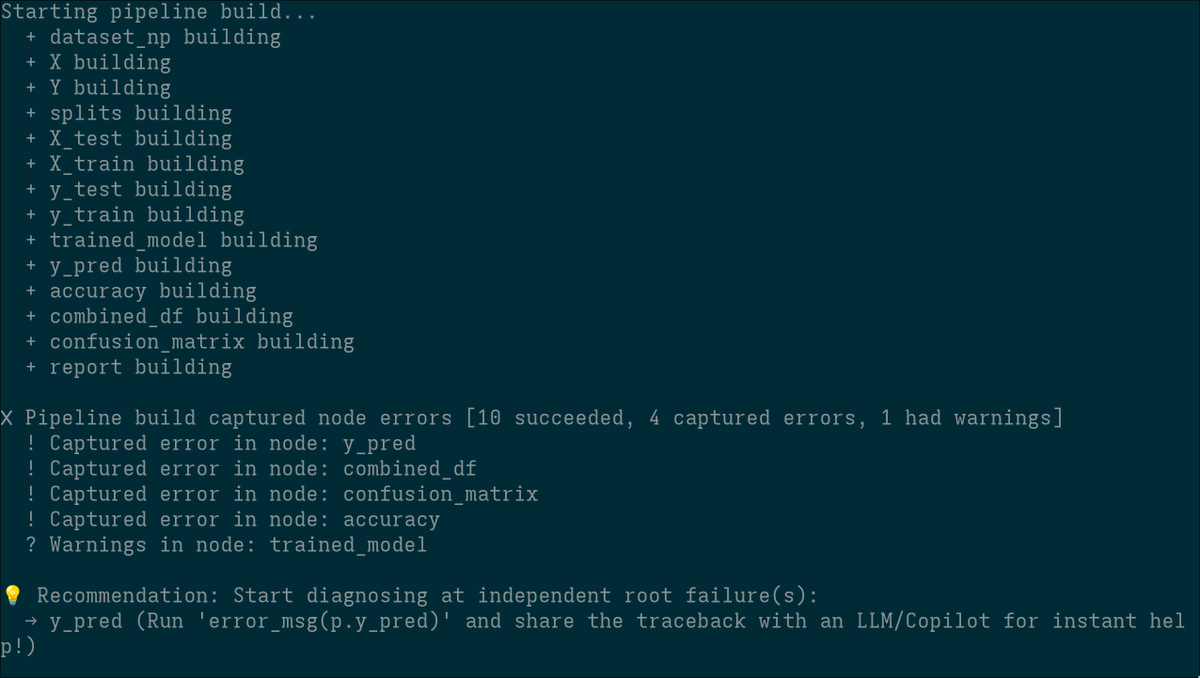
2
6
266

Jun 12
MIPS is a platinum sponsor at the @Infineon Technologies Ecosystem Summit 2026 on June 23 in Munich, joining leaders across the semiconductor and embedded systems ecosystem to discuss the future of intelligent, connected, and secure edge computing.
Sameer Wasson, CEO of MIPS by GF, will share how to start with your AI model and dataflow, then shape your silicon. Software-guided intelligence maps workloads to compute for building efficient edge AI, and this software-first approach enables Physical AI systems that sense, think, act, and communicate in real time under tight power and latency constraints.
#MIPS #EcosystemSummit #Infineon

41

Jun 11
The @SandiaLabs Spectra supercomputer, built in collaboration with Penguin Solutions and @NextSilicon, is critical to helping evaluate the future of supercomputing hardware. Following full acceptance of system requirements, NextSilicon’s Maverick-2 processor operating within Spectra, employs a reconfigurable dataflow architecture designed for demanding scientific computing workloads.
As the HPC industry explores alternatives to traditional GPU-centric designs, Maverick-2 could help pave the way for new approaches to powering future large-scale computing systems. @TheRegister recently covered what this could mean for the future of US-based supercomputers: theregister.com/systems/2026…
3
18
764

Jun 11
Today's development caps off with v0.4.3! 🧠💥
👉 Cross-file taint tracking is now graph-based
This builds a project-wide call graph & a def-use graph for variables, i.e. real dataflow analysis!
Review all of today's updates by checking out the chain of quoted post below👇

Jun 11

You thought the updates were done for the day?
brainblast v0.4.2 just went live! 🧠💥
👉 Cross-file taint tracking
👉 Auto-PR / suggested-fix branch mode
These two upgrades build on the new features released earlier today. Details below👇
5
4
19
1,551

@pvergadia Back in the 2020, I used to watch your videos back-to-back. That's where I first learned about Bigtable, BigQuery, conversational ai,Dataflow and helped me start my career in data engineering. Thank you!
It all started with this one video
youtu.be/Ms_GwMgojlk?si=PXJP…
Jun 11

Meet Priyanka Vergadia (aka The Cloud Girl).
An Indian-origin tech leader who failed IIT JEE twice, battled loans & setbacks, yet built a legendary career at Google → Microsoft. Pure proof that your start doesn’t define your ceiling.
Failed IIT JEE not once, but twice (2004 & 2005).
Graduated from a non-elite engineering college in India.
Moved to the US for MS at University of Pennsylvania struggled with financial loans & student debt.
Started as a Quality Assurance (QA) engineer at a small startup.
Pivoted into Developer Relations & cloud advocacy.
2017: Joined Google Cloud rose to Staff Developer Advocate, created viral visual content & authored best-selling books.
Now: Senior Director of Developer GTM & Forward Deployed Engineering at Microsoft, leading AI & Azure strategies for enterprises.
TED Speaker, Wharton connections, serves on the UPenn Board of Advisors built "The Cloud Girl" brand (100K followers).
LinkedIn: linkedin.com/in/pvergadia
GitHub: github.com/priyankavergadia
From repeated rejections & financial struggles → leading developer strategy at Microsoft while inspiring millions with visual storytelling.
This is what 15 years of grit, continuous learning, and owning your unique path looks like. Your college or early failures don’t write your story your consistency does.
What’s one rejection or setback that became your biggest turning point? Share below 👇
#WomenInTech #TechLeadership


1
3
87
Most doctors lose months before even reaching the exam stage.
Wrong steps. Missing details.
We make sure everything is right — from the start.
#verify_HRCS #DataFlow #Saudi_Licensing




10


Jun 10
Vector databases solved retrieval. But they didn't solve freshness.
That's why we think the next evolution of vector search is not just better indexing.
It's streaming-native vector retrieval.
Traditional vector search looks like:
Source Data → Embeddings → Vector Database → Application
The problem?
The data changes continuously, but the index is often updated in batches.
That creates:
ingestion lag
stale embeddings
consistency challenges
operational complexity
The real shift is not just adding vector search.
It's making vector search part of the streaming dataflow.
That's why modern AI systems increasingly combine:
continuous computation
vector search
HNSW indexes
With a streaming-native architecture:
Source → Streaming Database → Live Vector Index → Application
New events update the index automatically and incrementally.
Updated records update the index automatically.
The gap between data and retrieval shrinks from hours to seconds.
The future of AI retrieval is not just vector-native.
It's streaming-native because the data is live. The index should be too.
risingwave.com/blog/risingwa…
1
6
443

Jun 10
Expanding on 2 and 3:
By specializing the AI chip for Tesla’s specific workloads instead of using a general-purpose architecture, transistors and logic blocks that would otherwise sit idle can be eliminated.
This reduces both dynamic and static power consumption, lowers microarchitectural complexity and verification effort, and improves manufacturing yield through a more compact and regular floorplan.
The reclaimed die area can then be reinvested in higher-density, workload-optimized execution resources—such as additional tensor processing elements or custom dataflow pipelines—raising effective AI performance per mm² of silicon.
Additionally (this part is somewhat speculative), the design can embrace high degrees of data parallelism: multiple independent input streams or batches can be processed concurrently across dedicated on-chip resources or distributed across multiple chips.
Partial results are then aggregated via high-bandwidth inter-chip interconnect fabrics and on-package reduction logic. This multi-chip approach helps maximize total usable compute from the wafer without the yield penalties of a single large monolithic die.
1
21