
First comprehensive framework for how AI agents actually improve through adaptation.
While there is a lot of hype about building bigger models, the research reveals a different lever: systematic adaptation of agents and their tools.
Researchers from many universities surveyed the rapidly expanding landscape of agentic AI adaptation.
What they found: a fragmented field with no unified understanding of how agents learn to use tools, when to adapt the agent versus the tool, and which strategies work for which scenarios.
These are all important for building production-ready AI agents.
Adaptation in agentic AI follows four distinct paradigms that most practitioners conflate or ignore entirely.
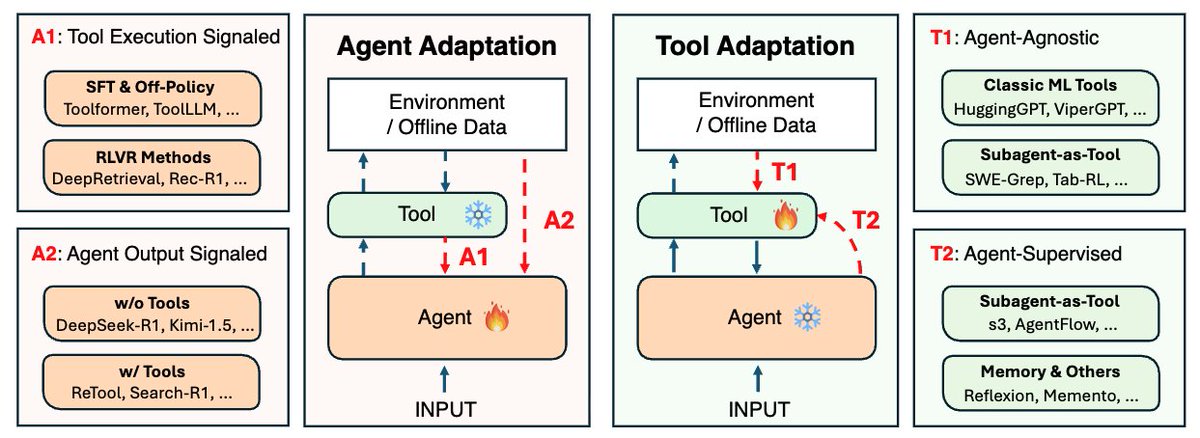
The framework organizes all adaptation strategies into two dimensions.
> Agent Adaptation (A1, A2): modifying the agent's parameters, representations, or policies.
> Tool Adaptation (T1, T2): optimizing external components like retrievers, planners, and memory modules while keeping the agent frozen.
Let's discuss each in more detail:
A1: Tool Execution Signaled Agent Adaptation.
The agent learns from verifiable outcomes produced by tools it invokes. This involves code sandbox results, retrieval relevance scores, and API call outcomes. Methods like Toolformer, ToolLLM, and DeepRetrieval also fall here. The signal comes from whether the tool execution succeeded, not whether the final answer was correct.
A2: Agent Output Signaled Agent Adaptation.
The agent optimizes based on evaluations of its own final outputs. This includes both tool-free reasoning (DeepSeek-R1, Kimi-1.5) and tool-augmented adaptation (ReTool, Search-R1). The signal comes from answer correctness or preference scores, not intermediate tool calls.
T1: Agent-Agnostic Tool Adaptation.
This involves tools trained independently of any specific agent, including HuggingGPT, ViperGPT, and classic ML tools that serve as plug-and-play modules. These tools generalize well across different agents but may not be optimized for any particular one.
T2: Agent-Supervised Tool Adaptation. Tools adapted using signals from a frozen agent's outputs. Includes reward-driven retriever tuning, adaptive search subagents, and memory-update modules like Reflexion and Memento. The agent stays fixed while tools learn to better support its reasoning.
The trade-offs between paradigms are explicit. Cost and flexibility: A1/A2 require substantial compute for training billion-parameter models but offer maximal flexibility. T1/T2 optimize external components at a lower cost but may hit ceilings set by the frozen agent's capabilities.
Generalization patterns differ significantly. T1 tools trained on broad distributions generalize well across agents and tasks. A1 methods risk overfitting to specific environments unless carefully regularized. T2 approaches enable independent tool upgrades without agent retraining, facilitating continuous improvement.
The researchers identify when each paradigm fits. A1 suits scenarios with verifiable tool outputs like code execution or database queries. A2 works when only the final answer quality matters. T1 applies when tools must serve multiple agents. T2 excels when the agent is fixed, but tool performance is the bottleneck.
State-of-the-art systems increasingly combine paradigms. A deep research system might use T1-style pretrained retrievers, T2-style adaptive search agents trained via frozen LLM feedback, and A1-style reasoning agents fine-tuned with execution feedback in a cascaded architecture.
Four open challenges remain unsolved:
- Co-adaptation: jointly optimizing agents and tools remains underexplored.
- Continual adaptation: enabling lifelong learning without catastrophic forgetting.
- Safe adaptation: preventing harmful behaviors during optimization.
- Efficient adaptation: reducing computational costs while maintaining performance.
The choice of adaptation paradigm fundamentally shapes what an agentic system can learn, how fast it improves, and whether improvements transfer across tasks. Teams building production agents need a principled framework for these decisions, not ad-hoc choices.
Report: github.com/pat-jj/Awesome-Ad…
Learn to build effective AI agents in our academy: dair-ai.thinkific.com/course…

10
98
444
32,993

11 Dec 2025
Your AI agent is burning 70x more compute than it needs to.
Here's why the smartest labs are now training TOOLS instead of AGENTS:
🧵 (This changes everything about how we build AI systems)
2/ The old playbook: Fine-tune a massive LLM to do everything
• Learn domain knowledge ✓
• Learn reasoning ✓
• Learn tool use ✓
Cost: $500K in compute
Risk: Catastrophic forgetting
Reality: Most teams can't afford this
3/ The new playbook: Keep your LLM frozen. Train tiny "tool agents" around it.
Search-R1 (old way): 170,000 examples
s3 (new way): 2,400 examples
Same performance. 70x less data. 33x faster training.
This is called "Symbiotic Inversion" 🔄
4/ Think of it like this:
❌ OLD: Teach Einstein to use a microscope
✅ NEW: Build Einstein a better microscope
The foundation model already knows how to reason.
Just give it specialized tools that speak its language.
5/ Real example: Memento
Instead of retraining GPT-4 on medical cases, they trained a tiny "memory retrieval policy" (Q-function) that learns WHAT past cases to show GPT-4.
Result: #1 on GAIA leaderboard.
Agent: Completely frozen. 🧊
6/ This solves 4 major problems:
1️⃣ Cost (train 7B models, not 70B)
2️⃣ Forgetting (agent stays stable)
3️⃣ Speed (smaller = faster iteration)
4️⃣ Modularity (swap tools like Lego blocks)
7/ The framework breaks adaptation into 4 paradigms:
A1: Agent learns tool mechanics (e.g., DeepRetrieval)
A2: Agent learns strategy (e.g., DeepSeek-R1)
T1: Plug-and-play tools (e.g., CLIP, SAM)
T2: Tools trained BY frozen agents (e.g., s3, AgentFlow)
T2 is the breakthrough.
8/ Why this matters RIGHT NOW:
• Claude/GPT APIs are getting powerful but you can't fine-tune them
• On-device AI needs lightweight adaptation
• Multi-agent systems need modular updates
T2 lets you build a "peripheral nervous system" around any frozen brain 🧠
9/ Safety bonus:
Training the agent (A1/A2) = dangerous exploration
(Your coding agent might delete production files while "learning")
Training tools (T2) = bounded risk
(The agent never changes; only its helpers get smarter)
10/ The future isn't bigger models.
It's frozen foundation models orchestrating CONSTELLATIONS of tiny, specialized sub-agents—each trained for one procedural skill using the foundation model as teacher.
Monolithic → Federated
Static → Adaptive
Expensive → Efficient
CTA Tweet:
11/ Full technical breakdown of the 4 adaptation paradigms, safety risks, and 50 system examples:
This is the roadmap for building production AI agents in 2025.
Bookmark share 🔖
5
11
44
3,010

19 Oct 2025
This is awesome, on-policy RL is definitely the way to do retrieval! For anyone who is seeking open-source code for such training, please check our DeepRetrieval: github.com/pat-jj/DeepRetrie…, which is the first search agent trained with on-policy RL, optimizing for the retrieval outcome. To train a search agent for a frozen generator (like Sonnet in the post), please check our s3: github.com/pat-jj/s3 for more details.
16 Oct 2025

Introducing SWE-grep and SWE-grep-mini:
Cognition’s model family for fast agentic search at >2,800 TPS.
Surface the right files to your coding agent 20x faster.
Now rolling out gradually to Windsurf users via the Fast Context subagent – or try it in our new playground!
2
10
1,520

8 Oct 2025
Check our DeepRetrieval at COLM 2025🚀
8 Oct 2025

🚀 Our DeepRetrieval — the first search agent trained with on-policy RL — will be presented at #COLM2025 tomorrow!
Unluckily, @jclin808 and I couldn’t make it to Canada due to visa issues, but our friend will be presenting on our behalf.
🕚 Time: 11 AM Thursday (Poster Session #5)
📍 Poster #51
Please stop by and take a look!
If you have any questions our presenter can’t answer, feel free to reply here or email me at pj20@illinois.edu.
P.S. I’m now deploying this work @Google 🚀
Code: github.com/pat-jj/DeepRetrie…
#COLM_conf #COLM2025 #DeepResearch #AgenticAI

6
276
8 Oct 2025
🚀 Our DeepRetrieval — the first search agent trained with on-policy RL — will be presented at #COLM2025 tomorrow!
Unluckily, @jclin808 and I couldn’t make it to Canada due to visa issues, but our friend will be presenting on our behalf.
🕚 Time: 11 AM Thursday (Poster Session #5)
📍 Poster #51
Please stop by and take a look!
If you have any questions our presenter can’t answer, feel free to reply here or email me at pj20@illinois.edu.
P.S. I’m now deploying this work @Google 🚀
Code: github.com/pat-jj/DeepRetrie…
#COLM_conf #COLM2025 #DeepResearch #AgenticAI
1
9
1,489

5 Oct 2025
RAG 已过时:强化学习智能体 (RL Agents) 将成为新的检索栈 —— 传统 RAG 已达性能上限,而 Agentic Search —— 即 LLM 作为智能体,通过工具循环迭代进行检索 —— 已超越 RAG。但智能体式搜索成本高、速度慢,RL 训练的智能体则使其高效且优越,成为新 SOTA,来自 @inference_net 团队博客分享。
关键论点与结构
1. RAG 的局限:传统 RAG 依赖稀疏搜索(如 BM25)、稠密嵌入搜索和重排序(如 RRF)今年已触顶。尽管用户数据调优有效,但难以突破。RAG 虽进步显著,却无法应对复杂、多跳检索需求。
2. 智能体式搜索的兴起:智能体式搜索让 LLM 在循环中使用工具(如 grep、嵌入搜索、SQL)进行迭代检索,甚至中等工具也能胜过精心调优的单步管道。这源于多跳检索概念(如 Baleen 项目),扩展到多工具协作。当你给 LLM 工具,让它循环运行(智能体定义),并要求它执行检索时,它通常优于精心调优的单步搜索管道。
3. 无 RL 的痛点:智能体式搜索领域特定(如代码库 vs. 研究论文),缺乏长期“经验”,上下文膨胀导致高成本和延迟。大型 LLM 虽性能好,但费用与延迟成倍增加。
4. RL 的变革作用:RL 通过奖励函数训练智能体(如惩罚幻觉、奖励正确检索、罚款多余调用),让小型模型(3B 参数)高效决策工具使用与结果合成。结果是“超人级”模型,能精准选择工具并生成连贯答案。RL 使智能体式搜索“既优越又高效”。 它促进专业化:小型 RL 模型专攻检索,顶级模型专注生成,解决速度与成本瓶颈。
重要概念
· 智能体式搜索(Agentic Search):LLM 作为智能体,迭代调用工具进行检索,适应复杂任务。无 RL 时强大但低效;RL 后实用化。
· RL 在搜索智能体中:强化学习用奖励优化行为,如在 DeepRetrieval 项目中提升查询增强与证据求取。
证据与示例
· 研究基准:DeepRetrieval(3B 模型)在 13 个数据集上胜过 GPT-4o 和 Claude-3.5-Sonnet 的 11 个(如 HotpotQA)。Search-R1 项目中,RL 让 Qwen-2.5 模型在 QA 数据集上相对 RAG 提升 21%-26%,学会多轮搜索与决策。
· 实际应用:
· xAI Grok Code:RL 智能体处理代码检索、执行与编辑,全流程“极快”,适应多样动作。
· Happenstance 联系人搜索引擎:智能体创建复杂过滤,但无 RL 时慢;RL 可提速 2-3 倍。
· Clado(YC 初创):用 LLM-as-Judge RL 循环提升人员搜索准确性。
挑战与结论
挑战包括领域适应性、数据污染与集成难度(如实时 vs. 分阶段工作流)。RL 智能体是新范式:RAG → 昂贵智能体搜索 → 高效 RL 智能体。它用奖励数据而非直接监督优化,适用于非实时场景如代码审查。未来,RL 将推动初创企业构建可扩展系统,检索与生成分工明确,变革编码智能体与搜索引擎。

6
69
232
19,459

6 Aug 2025
📍Turning off #DeepRetrieval in a recommendation system likely aims to improve either the speed or efficiency of recommendations, potentially at the cost of some accuracy or depth! This suggests that the previous #DeepRetrievalMethod was computationally expensive or slow, & the change is an attempt to make recommendations Faster🥳..😷🍁
#HappyYadav
1
1
158
29 Apr 2025
Qwen-3 has released several amazing small models, which will further improve our recent work on DeepRetrieval and Rec-R1. These powerful small models are perfect for university labs to have truly amazing work, even if not have enough computational resources
x.com/patpcj/status/19071408…
x.com/jclin808/status/190707…
#Qwen3
28 Apr 2025

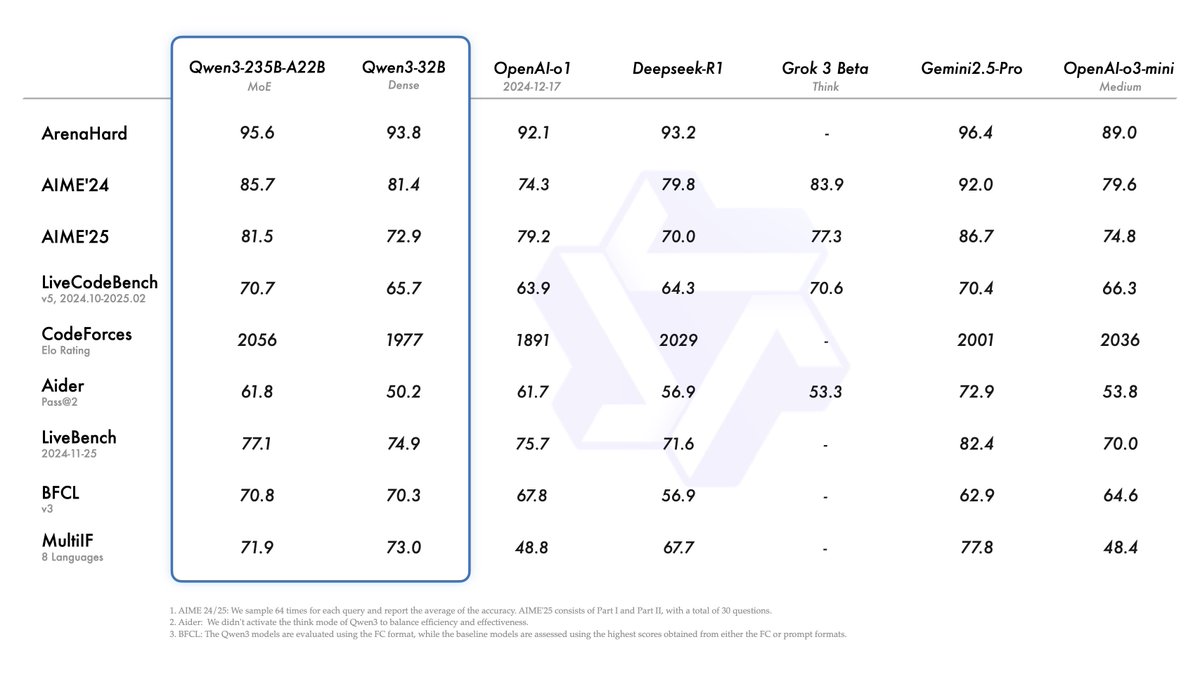
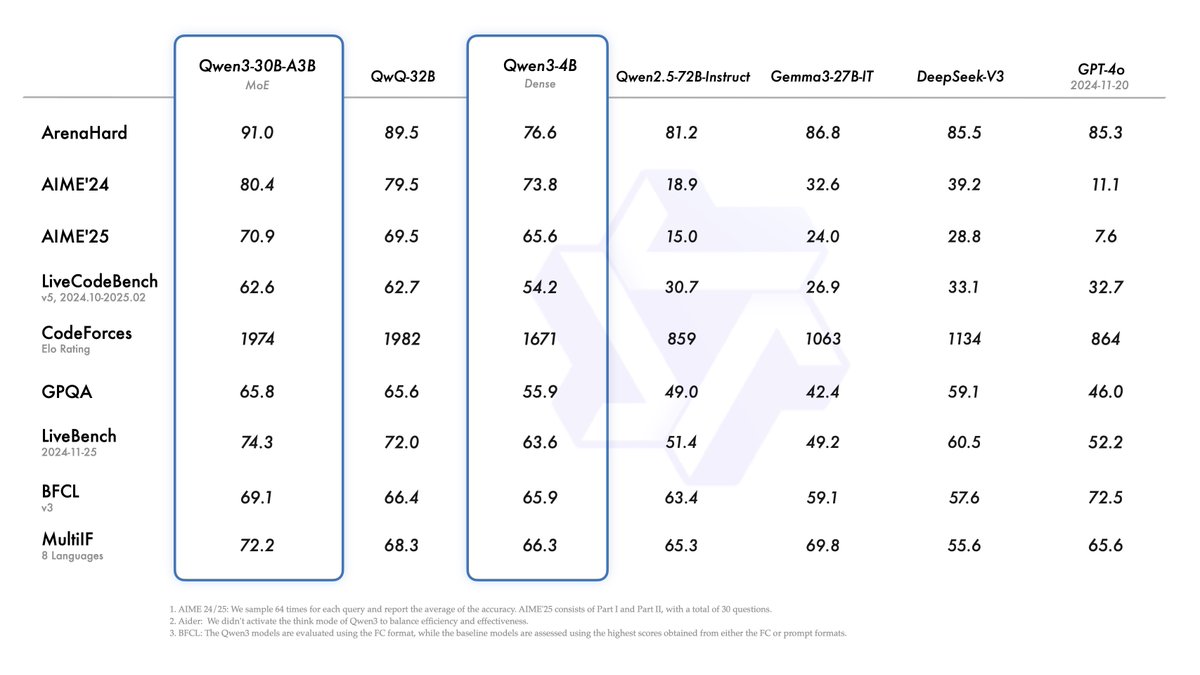
Introducing Qwen3!
We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct.
For more information, feel free to try them out in Qwen Chat Web (chat.qwen.ai) and APP and visit our GitHub, HF, ModelScope, etc.
Blog: qwenlm.github.io/blog/qwen3/
GitHub: github.com/QwenLM/Qwen3
Hugging Face: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments.
Hope you enjoy our new models!
1
4
646
6 Apr 2025
Yes, of course. Powerful smaller models are enough for us to do some really impressive work — for example, our recent DeepRetrieval and Rec-R1 projects. A 3B model can change the game.
x.com/patpcj/status/19071408…
1 Apr 2025

🚀Introducing Rec-R1, a general framework that trains LLMs for recommendation systems via reinforcement learning.
It’s model-agnostic, fits into many LLM4Rec setups, and boosts the recommendation performance—even with just a 3B model 💡
✅ No synthetic data (e.g., no GPT-4 generated SFT data)
✅ Better than prompting/SFT
✅ Works with black-box RecSys
✅ Keeps general capabilities intact
Paper: arxiv.org/abs/2503.24289
Github: github.com/linjc16/Rec-R1
🔗 #RecommenderSystems #LLM4Rec #LLM #ReinforcementLearning
🧠 #AIResearch #MachineLearning #NLP #GenAI
📦 #OpenSource #MLOps #AI4RecSys #DeepSeek #Amazon #Google
5
892
6 Apr 2025
Cool work! But, ReSearch lacks the supervision (reward) on the retrieval steps, which limits the overall downstream performance. We recently release DeepRetrieval, which aims to optimize the retrieval performance and models can be integrated into any RAG framework. x.com/patpcj/status/19071408…
1 Apr 2025
🚀𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗗𝗲𝗲𝗽𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹: We're 𝐇𝐀𝐂𝐊𝐈𝐍𝐆 𝐑𝐄𝐀𝐋 𝐒𝐄𝐀𝐑𝐂𝐇 𝐄𝐍𝐆𝐈𝐍𝐄𝐒 using LLM WITHOUT supervision!
We use a 3B model to achieve 𝗠𝗢𝗥𝗘 𝗧𝗛𝗔𝗡 𝗗𝗢𝗨𝗕𝗟𝗘𝗗 (65% vs 25%) previous SOTA (including GPT-4o) on Search!
📑Paper: arxiv.org/abs/2503.00223v2
💻Code: github.com/pat-jj/DeepRetrie…
🤗Models: huggingface.co/DeepRetrieval
#DeepSeek #R1 #ChatGPT #chatgpt4o #Google #Bing #xAI #GoogleSearch #AI #NLP #InformationTechnology

1
2
250
6 Apr 2025
It seems that the feedback for LLaMA4 after testing hasn’t been overwhelmingly positive. I still feel that smaller models like the 3B ones are more beneficial for the community’s development, especially for university labs. These smaller models can also enable us to do some really impressive work — for example, our recent DeepRetrieval and Rec-R1 projects. A 3B model could be enough to change the game.
#Llama4 #DeepRetrieval #recomendation
1 Apr 2025
🚀Introducing Rec-R1, a general framework that trains LLMs for recommendation systems via reinforcement learning.
It’s model-agnostic, fits into many LLM4Rec setups, and boosts the recommendation performance—even with just a 3B model 💡
✅ No synthetic data (e.g., no GPT-4 generated SFT data)
✅ Better than prompting/SFT
✅ Works with black-box RecSys
✅ Keeps general capabilities intact
Paper: arxiv.org/abs/2503.24289
Github: github.com/linjc16/Rec-R1
🔗 #RecommenderSystems #LLM4Rec #LLM #ReinforcementLearning
🧠 #AIResearch #MachineLearning #NLP #GenAI
📦 #OpenSource #MLOps #AI4RecSys #DeepSeek #Amazon #Google
5
554
1 Apr 2025
🚀𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗗𝗲𝗲𝗽𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹: We're 𝐇𝐀𝐂𝐊𝐈𝐍𝐆 𝐑𝐄𝐀𝐋 𝐒𝐄𝐀𝐑𝐂𝐇 𝐄𝐍𝐆𝐈𝐍𝐄𝐒 using LLM WITHOUT supervision!
We use a 3B model to achieve 𝗠𝗢𝗥𝗘 𝗧𝗛𝗔𝗡 𝗗𝗢𝗨𝗕𝗟𝗘𝗗 (65% vs 25%) previous SOTA (including GPT-4o) on Search!
📑Paper: arxiv.org/abs/2503.00223v2
💻Code: github.com/pat-jj/DeepRetrie…
🤗Models: huggingface.co/DeepRetrieval
#DeepSeek #R1 #ChatGPT #chatgpt4o #Google #Bing #xAI #GoogleSearch #AI #NLP #InformationTechnology
6
2
10
9,552
2 Mar 2025
Check our latest work DeepRetrieval: x.com/patpcj/status/18958810…
where we train LLMs with RL for search engines. The results are surprisingly good (DOUBLED previous SOTA performance)!😁
1 Mar 2025
📣 Excited to share #DeepRetrieval - our novel approach using reinforcement learning for query augmentation in information retrieval!
🚀 Our preliminary results (we got on Feb 16) CRUSH previous SOTA:
60.8% vs 24.7% recall on PubMed search engine
70.8% vs 32.1% recall on ClinicalTrial search engine
with a SMALLER model (3B vs 7B)
💡NO supervision data:
- [no💰] vs [💰💰💰💰...] on creating augmented queries from ChatGPT/Claude!
💻 Github: github.com/pat-jj/DeepRetrie…
📝 Preliminary Technical Report: pat-jj.github.io/assets/pdf/…
🔬 Currently testing on general IR datasets and with dense retrieval methods
📝 Full paper with more results will be released soon.
Just created this X account to share this breakthrough - follow for more NLP IR research! #NLP #IR #MachineLearning #LLM #AAAI2025
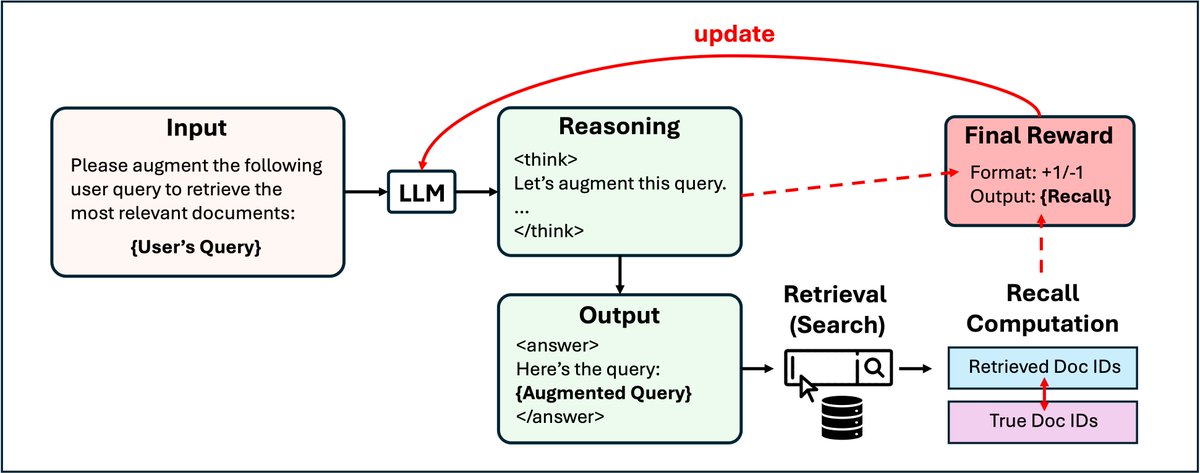
ALT DeepRetrieval: The LLM generates an augmented query, which is used to retrieve (search) documents. The recall is computed and mapped to a reward to update the model.
3
525
1 Mar 2025
📣 Excited to share #DeepRetrieval - our novel approach using reinforcement learning for query augmentation in information retrieval!
🚀 Our preliminary results (we got on Feb 16) CRUSH previous SOTA:
60.8% vs 24.7% recall on PubMed search engine
70.8% vs 32.1% recall on ClinicalTrial search engine
with a SMALLER model (3B vs 7B)
💡NO supervision data:
- [no💰] vs [💰💰💰💰...] on creating augmented queries from ChatGPT/Claude!
💻 Github: github.com/pat-jj/DeepRetrie…
📝 Preliminary Technical Report: pat-jj.github.io/assets/pdf/…
🔬 Currently testing on general IR datasets and with dense retrieval methods
📝 Full paper with more results will be released soon.
Just created this X account to share this breakthrough - follow for more NLP IR research! #NLP #IR #MachineLearning #LLM #AAAI2025
ALT DeepRetrieval: The LLM generates an augmented query, which is used to retrieve (search) documents. The recall is computed and mapped to a reward to update the model.
3
64
43
29,729

6 Mar 2019
Pupils @woodberrydownN4 are always given the opportunity to explore and verify their answers which makes learning deeper! #reasoning #deepretrieval @rjmgteach @mr_spenny @MsCDrake @ShacklewellE8 @woodberrydownN4 @Grazebrook_Pri @DuncanKilty @msjhutchison @hewie_derek

3
9