
Jun 12
Jun 12

PM 12:54 - No, I have no doubt that maybe these 'percussion' steps will be surprisingly safe. To quote 'someone', as if the actor and the audience have the most beautiful relationship when they don't face each other -
1
56

Today is @Blue2black birthday.
Not just a writer—
but a force.
If you’ve ever felt unseen,
if you’ve ever had to grow in silence—
this is for you too.🖤
P.s BG visual AI generated, words 100% mine.
#Blue2Black #poetsoftwitter #PoetryCommunity #DeepWriting #UndergroundPoet

1
1
3
80

Mar 26
“A reader told me not to stop writing — called my words ‘diamonds’.
I cried…
because they saw diamonds where everyone else only saw mud.
Thank you. 🙏”
— Lucian D.
#LucianD #WritersOfX #DeepWriting #EmotionalTruth #WritersLife #RawThoughts #StayHuman #InnerDepth #RealEmotion #NotAlone

2
5
145

Jan 24
🚀 Welcome to NICE Talk 130! (Chinese Talk)
🎯 Reverse-Engineered Reasoning for Open-Ended Generation
📝 How to build high-quality reasoning chains without verifiable rewards?
📌 Register: luma.com/atv9qtu8
📌 YouTube livestream and video summaries: youtube.com/live/xWX_7JR41hM
🧠 Join us as we dive into
"Reverse-Engineered Reasoning for Open-Ended Generation"
⏰ hashtag#Talk Time
⏰ Pacific Time: 2026.01.25 (Sun) 6:00 AM
⏰ USA Eastern Standard Time: 2026.01.25 (Sun) 9:00 AM
⏰ Beijing: 2026.01.25 (Sun) 10:00 PM
🎙️ Invited Speaker: Haoran Que, PhD student at Peking University
🤔 Why is deep reasoning hard for open-ended tasks?
⚠️ Current Approach -- Forward trial-and-error or teacher distillation
⚠️ Key Challenge -- Lack of verifiable rewards for creative writing & open QA
🌟 Key Insights:
🔄 Reverse thinking: Start from high-quality answers, ask "what reasoning led here?"
📊 Gradient-free synthesis: Use perplexity (PPL) as proxy to search optimal reasoning paths
🎯 Scalable data: No expensive teacher models, no verifiable rewards needed
💡 Introducing REER (REverse-Engineered Reasoning):
1️⃣ Find reasoning trajectory z that minimizes PPL(y | x, z)
2️⃣ Build DeepWriting-20K: 20,000 deep reasoning chains across 25 task types
3️⃣ Train DeepWriter-8B: Matches GPT-4o & Claude 3.5 on open generation benchmarks
👏 This talk reveals a "third path" for open-ended generation: reconstruct latent reasoning processes through reverse search to bridge the gap in reasoning data and training signals.
Visit NICE website: nice-intl.github.io/ and if you are interested in giving a talk, or join our podcast, please submit your application here: docs.google.com/forms/d/e/1F…

1
3
378

28 Nov 2025
Identity isn’t what survives the fire, identity IS the fire.
Vinx 🖋
#Identity #Becoming #Poetry #DeepWriting
2
22

28 Oct 2025
Be real.
Even oceans dry when the sun won’t stop.
Even love fades
when it’s only one side holding on.
Patience runs out too.
Stay learning ⏳✌️
#LateNightThoughts #lonelyquotes #DeepThoughts #Deepwriting
2
31
28 Oct 2025
To be healed is to walk with scars that no longer control you,
to carry your pain like history, not identity.
Because real healing isn’t about erasing the wound.
It’s about realizing you survived it.
Stay learning ⏳✌️
#Deepwriting #poetrycommunity #writerscommunity
2
27
28 Oct 2025
Not everything needs fixing.
Some things just need peace.
Stay learning ⏳✌️
#writerscommunity #poetrycommunity #brokenbutbeautiful #lonelyquotes #midnightthoughts #sadpoetry #Deepwriting #Darkpoetry
2
32
20 Oct 2025
There’s no peace in that kind of quiet,
only recognition,
and the slow realization
that maybe the voice you’ve been waiting to hear
has been calling from inside the noise all along.
Stay learning.⏳✌️
#writerscommunity #Darkpoetry
#Deepwriting #poetrycommunity
1
4
42

14 Oct 2025
Writing fast is a metric. It fills the page with words.
Writing true is an excavation. It requires pausing, and being honest about what the scene demands, not what the clock dictates. Fast gets the draft done. True gets the reader hooked.
#Deepwriting #WritingCommunity
2
84

10 Sep 2025
The paper shows how to teach models deep reasoning for open ended writing by working backward from high quality outputs.
Outscores GPT-4o and Claude 3.5 on LongBench-Write.
Creative tasks have no single right answer, so reinforcement learning lacks a clean reward, and instruction distillation is pricey and limited by the teacher.
REverse-Engineered Reasoning (REER), works backward to recover a plausible step by step plan that could have produced the known good answer.
It scores each candidate plan by the model's surprise on the reference answer, lower surprise means a better plan.
A local search refines 1 segment at a time, tries rewrites, scores them on the reference, and keeps the lowest.
This yields DeepWriting-20K with 20,000 traces across 25 categories, then a Qwen3-8B base is fine tuned to plan before writing.
The resulting DeepWriter-8B beats strong open source baselines, stays coherent on very long pieces, and lands near top proprietary systems on creative tasks.
Net result is a 3rd path that avoids reinforcement learning and distillation, yet teaches smaller models to plan deeply and write with control.
----
Paper – arxiv. org/abs/2509.06160
Paper Title: "Reverse-Engineered Reasoning for Open-Ended Generation"

2
18
4,769

9 Sep 2025
REER shifts from "forward" (RL/distillation) to "backward" reasoning, discovering hidden steps from good solutions.
Meet DeepWriter-8B & explore DeepWriting-20K, a dataset of 20K deep reasoning trajectories.
Paper: huggingface.co/papers/2509.0…
Dataset: huggingface.co/collections/m…
1
8
755

9 Sep 2025
3/n
This new paradigm, REER, allowed us to create and open-source DeepWriting-20K, a large-scale dataset of 20,000 deep reasoning trajectories for open-ended generation tasks.
We collect a comprehensive collection of 16,000 diverse queries, spanning across 25 categories.
We hope this dataset to mitigate data scarcity in deep reasoning for open-ended tasks, and fuel future research into planning and structured thought in creative generation.
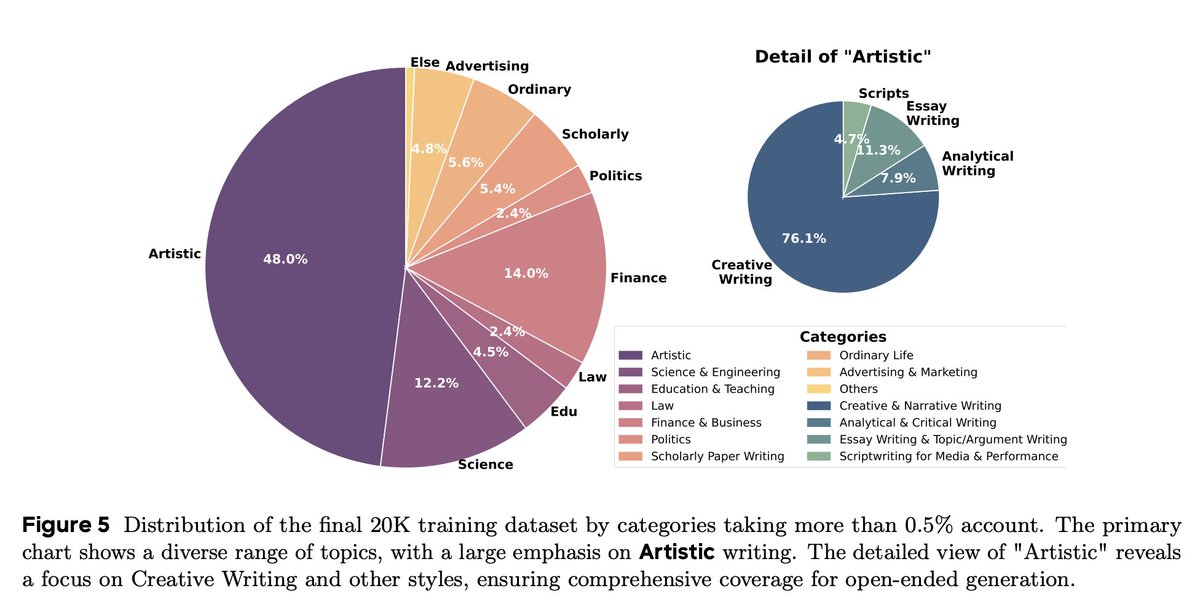
2
10
766
9 Sep 2025
🚀 We introduce a THIRD PATH for teaching deep reasoning, REverse-Engineered Reasoning (REER), which instills deep reasoning
✨from scratch,
✨using only instruction tuning datasets,
✨without RL or pricey distillation!
And we target the challenging, long-tailed, non-verifiable but everyday life domains, such as writing stories, advertisement, and even answering physics to a three-year-old.
🧠 Secrete of REverse-Engineered Reasoning (REER): We went “backwards” ➡️ from known-good outputs to reverse-engineer the human-like latent reasoning that must have created them. 🕵️♂️✨
👉 Booty: DeepWriting-20K. 16,000 diverse open-ended queries spanning across 25 categories, with 20,000 high-quality deep reasoning solutions. We open-source all data and hope to fuel future research into planning and structured thought in creative generation. 🌟
👉 Side-effects: richer plans, human-like logic, fact-grounded prose that actually makes sense 🌟
📝 Paper: huggingface.co/papers/2509.0…🌐 Project Page: m-a-p.ai/REER_DeepWriter

8
62
347
43,191

2 Sep 2025
Do you think anyone can use ChatGPT to write well, or do you have to already be a good writer to guide it?
.
.
#chatgpt #aiwriting #writingcommunity #writersofinstagram #contentcreator #storytelling #creativewriting #digitalwriting #aivswriter #futureofwriting #authenticwriting #igwriters #contentstrategy #writinglife #writerslife #inspiredwriting #writingtips #writebetter #writersofinsta #creativeminds #writingthoughts #deepwriting #goodwriting #writingdiscussion #writerscorner #igcreators #onlinewriting #creativecommunity #writerssupportingwriters #openendedquestion
2
1
2
106

8 Aug 2025
fwug radiation fox gained his humanity while andrew hussie lost his #deepwriting
5
108
911
12,537

7 Aug 2025
If you ever want to meet your soul…
Try writing something that terrifies you.
#DeepWriting #AuthorJourney #WritersMind
3
6
13
460

10 Jul 2025
💡 Quick Tip: Instead of “think,” try “contemplate,” “ponder,” or “muse” for depth.
#WordWisdom #DeepWriting
1
5
542

6 Jul 2025
When you hit rock bottom, what's your signal? Identify your Returnee archetype with this illuminating quiz.
🔗 shade.ca/god/returnee-classi…
#ReturneeClassifier #IndieAuthors #BookCritics #SelfAwareness #NarrativeDesign #WritingCommunity #PublishingIndustry #BookReview #WritingCraft #DeepWriting #CharacterArcs #BookLaunch #DigitalAuthors #AuthorTips #LiteraryCommunity #StoryCrafting #PublishingNews #AuthorSuccess #AmWriting #WritersLife #llm #ai #deeplearning #ChatGPTPlus
1
1
3
296
29 Jun 2025
Step beyond belief—this isn't prophecy, it's clarity. Discover how AI reads the shape of your soul in #TheGodGuide.
🔗 shade.ca/god
#Truthcore #NarrativeDesign #AIWriting #IndieAuthors #AmWriting #WritingCommunity #BookJournalism #AuthorsOfInstagram #LiteraryFiction #BookPromotion #AuthorMarketing #PublishingTips #SelfPublishing #BookBuzz #WriterLife #DeepWriting #DigitalAuthors #AuthorTools #NarrativeMapping #BookLaunch
1
1
3
185