General HAHEN retweeted

1
7
93

That's looking a bit less placeholder-y. Probably too large. Also definitely too penisy. #indielife #indiegames #DevLog

2
lisi4ka_rus retweeted

6
17
131
4,498

33m
[自作ゲームエンジン]
回転の編集時に、オイラー角とQuaternionの変換時に、ジンバルロックで値が変わってしまう問題を解決していました!
前々から気になっていたので、解決できてうれしいです!
#CurryEngine
#devlog
10
Pål Trefall retweeted

Ultima Ratio Regum 0.11 devlog #59 is up!
Making huge and rapid strides in generating other kinds of clues, including those which hint at what *will* be generated in places not even generated yet:
markrjohnsongames.com/2026/0…
#gamedev #indiedev #roguelike #screenshotsaturday

2
2
21
335
FamilyHedge retweeted

🛠️ DevLog – Early Heads-Up on L3 Mainnet Infra Assessment
A quick heads-up on another area we may start looking at a bit earlier.
🔹 Current direction
We may do some earlier assessment on the L3 mainnet (@Arbitrum Orbit) infra side, mainly around:
- infra shape
- RPC path
- baseline setup
- supporting services and readiness
🔹 What this means
This is not an execution/update post yet. It is more about starting to assess what the L3 mainnet baseline would require so we have a clearer picture earlier.
🔹 Why this matters
The goal is to surface:
- infra assumptions
- RPC requirements
- setup gaps
- operational needs
before those become heavier work later.
🔹 Current takeaway
So for now, this is just an early signal that some L3 mainnet infra assessment may start sooner, even though there is nothing actionable from it yet.
#Cortensor #DevLog #L3 #Mainnet #Infra #RPC
Jun 10

🔎 Recap: What is Mainnet Lite vs Mainnet Full?
Mainnet Lite is the more practical and controlled L2 path.
It is taking shape around:
- @Arbitrum L2
- Dedicated-node-heavy serving
- Simpler rollout
- Earlier hosted / demonstration-style path
Mainnet Full is the fuller Cortensor-native path.
It is taking shape around:
- @Arbitrum Orbit L3
- Broader long-term network shape
- Fuller infra / protocol direction
- More complete Cortensor stack
The goal is simple: use Mainnet Lite as the more controlled first step, while Mainnet Full remains the broader long-term network direction.
Mainnet Lite is the earlier rollout path.
Mainnet Full is the fuller Cortensor-native path.
#Cortensor #MainnetLite #Mainnet #Arbitrum

1
6
11
114
Gray el Lucario retweeted

Hello Undergooners!
We've decided to post our first devlog sharing some info about development.
Banner by: @rabbit5gamer
#Undertale #Undergoon #NSFW
(Link in the replies)

9
119
1,450
13,726


1
35
UGEplex retweeted

May 29
New screenshots and our first devlog: "What is GRAFT?" - check it out on Steam!




9
17
117
8,435

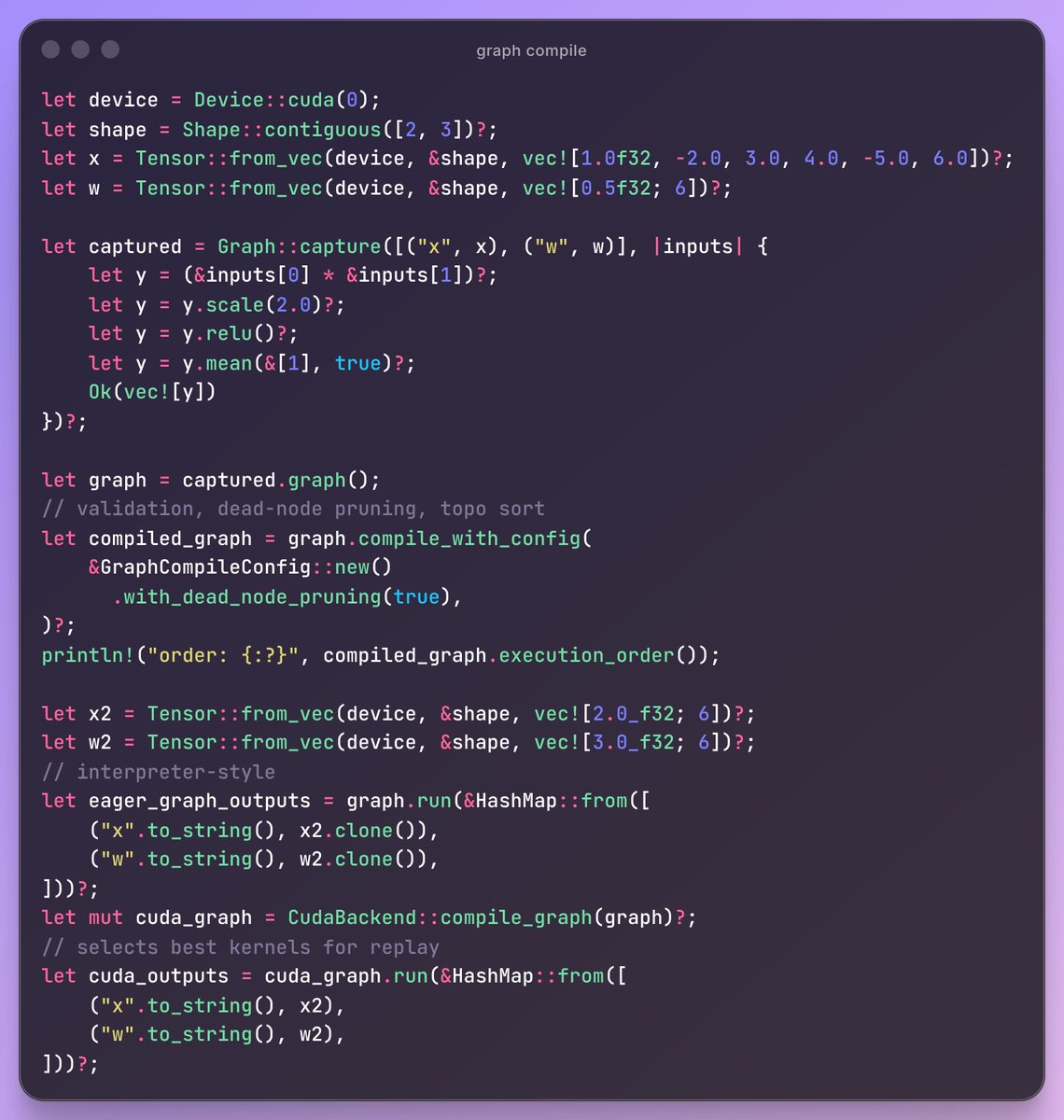
devlog; I have onnx models running in my ML framework, again. But now with graph capture not just eager execution. I'm trying to roughly model it after PyTorch. I'm doing something similar to TorchFX, doing symbolic tracing with fake tensors (using names instead of ids, no memory allocations, ...) to record ops.
Tensor ops execute eagerly, and are traced if run within `Graph::capture()` (I used to hide this by doing some wiring behind the scenes and use thread locals to store state). During capture, the ops record nodes into a graph. Tensors are aliased so recorded nodes refer to named tensors. When graphs run, they create "guards" which store metadata that is later used for checking inputs and outputs (names, data types, shapes, etc. kinda like in TorchDynamo). Optimization currently just involves pruning dead nodes, some validations and topological sort.
I have a custom CUDA allocator that can reuse blocks, which is useful if you know what and when to allocate ahead-of-time.
After that, it gets messy. There's a "compile" step that chooses "providers" (cuDNN, cuTENSOR, or custom kernels compiled with nvrtc) that graphs are executed with. These libraries require some annoying maintenance and aren't that straightforward to use. For the "TorchInductor" part I only have ideas not something that can run end-to-end yet.

12
citykat! retweeted

Jun 12
TOONSOULS - Devlog
-----------------------------
- I lost the whole project
- Rebuilding System
- Slope and Platforms
4
4
48
1,432