Biologically-Grounded Multi-Encoder Architectures as Developability Oracles for Antibody Design
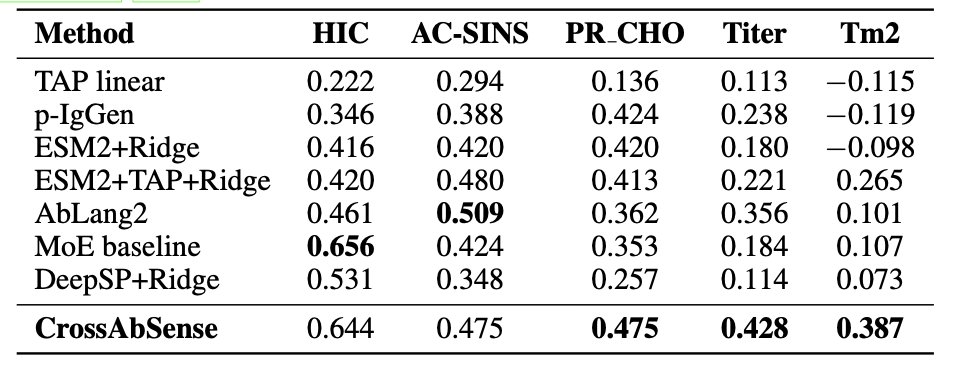
1. CrossAbSense achieves 12-20% improvements over established baselines on three key developability assays: expression titer ( 20%), thermal stability ( 18%), and polyreactivity ( 12%), demonstrating substantial predictive gains for antibody manufacturability screening.
2. The central finding inverts initial biological hypotheses: aggregation-related properties (hydrophobic interaction chromatography and polyreactivity) are optimally predicted by self-attention alone, while expression yield and thermal stability require bidirectional cross-attention between heavy and light chains.
3. This architectural discovery reveals that with high-capacity encoders like ESM-Cambrian 6B, aggregation signals such as CDR-H3 hydrophobic patches are already fully resolved within single-chain embeddings, whereas inter-chain compatibility is irreducibly bivariate and demands explicit cross-attention modeling.
4. Learned chain fusion weights independently confirm the biological interpretation: heavy-chain dominance for aggregation (wH = 0.62) versus balanced contributions for stability (wH = 0.51), converging with attention strategy selection to validate the mechanistic insights.
5. Full-chain encoding outperforms variable-region-only representations on four of five properties, with 15-20% improvements for thermal stability and expression, as constant regions encode critical IgG subclass identity information.
6. The framework enables practical deployment for generative antibody design, screening 100 IgLM-generated trastuzumab-based designs and revealing that unguided generation produces narrow property distributions, motivating oracle-guided optimization for balanced sequence novelty and manufacturability.
7. Operating entirely at the sequence level with frozen protein language model encoders reduces trainable parameters by two orders of magnitude while probing what PLMs have learned about developability from evolutionary data alone.
💻Code: github.com/SimonCrouzet/Cros…
📜Paper: arxiv.org/abs/2604.09369
#AntibodyDesign #DevelopabilityPrediction #ProteinLanguageModels #ComputationalBiology #Biopharmaceuticals #MachineLearning #ICLR2026
2
2
8
1,635
Biologically-Grounded Multi-Encoder Architectures as Developability Oracles for Antibody Design
1. CrossAbSense achieves 12-20% improvements over established baselines on three key developability assays: expression titer ( 20%), thermal stability ( 18%), and polyreactivity ( 12%), demonstrating substantial predictive gains for antibody manufacturability screening.
2. The central finding inverts initial biological hypotheses: aggregation-related properties (hydrophobic interaction chromatography and polyreactivity) are optimally predicted by self-attention alone, while expression yield and thermal stability require bidirectional cross-attention between heavy and light chains.
3. This architectural discovery reveals that with high-capacity encoders like ESM-Cambrian 6B, aggregation signals such as CDR-H3 hydrophobic patches are already fully resolved within single-chain embeddings, whereas inter-chain compatibility is irreducibly bivariate and demands explicit cross-attention modeling.
4. Learned chain fusion weights independently confirm the biological interpretation: heavy-chain dominance for aggregation (wH = 0.62) versus balanced contributions for stability (wH = 0.51), converging with attention strategy selection to validate the mechanistic insights.
5. Full-chain encoding outperforms variable-region-only representations on four of five properties, with 15-20% improvements for thermal stability and expression, as constant regions encode critical IgG subclass identity information.
6. The framework enables practical deployment for generative antibody design, screening 100 IgLM-generated trastuzumab-based designs and revealing that unguided generation produces narrow property distributions, motivating oracle-guided optimization for balanced sequence novelty and manufacturability.
7. Operating entirely at the sequence level with frozen protein language model encoders reduces trainable parameters by two orders of magnitude while probing what PLMs have learned about developability from evolutionary data alone.
💻Code: github.com/SimonCrouzet/Cros…
📜Paper: arxiv.org/abs/2604.09369
#AntibodyDesign #DevelopabilityPrediction #ProteinLanguageModels #ComputationalBiology #Biopharmaceuticals #MachineLearning #ICLR2026

3
12
1,304

28 Dec 2025
Fitness Landscape for Antibodies 2: Benchmarking Reveals That Protein AI Models Cannot Yet Consistently Predict Developability Properties
1. A new study benchmarks the performance of 30 AI and biophysical models in predicting the developability properties of antibodies. The study finds that most models fail to produce statistically significant correlations for the majority of datasets, highlighting the challenges in using AI for antibody design.
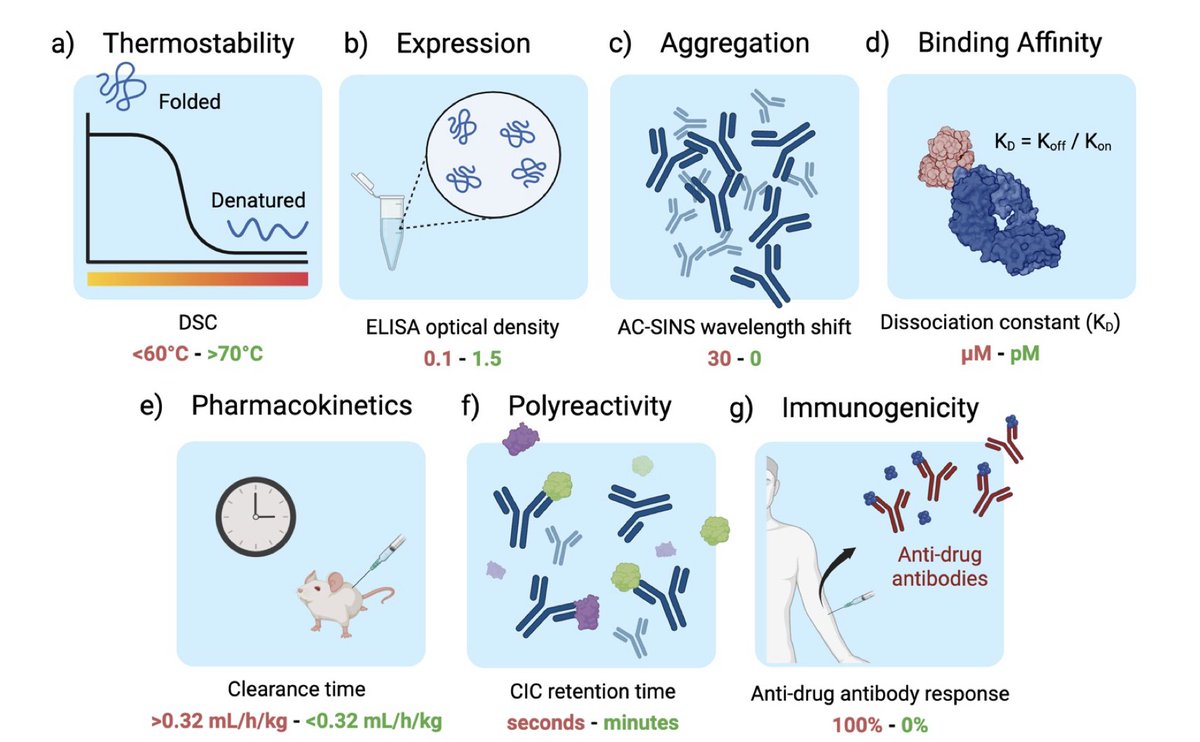
2. The study introduces FLAb2, the largest public therapeutic antibody design benchmark to date, containing data on over 4 million antibodies across 32 studies. It evaluates seven key properties: thermostability, expression, aggregation, binding affinity, pharmacokinetics, polyreactivity, and immunogenicity.
3. The research shows that no single AI model can consistently predict all developability properties. While some models like IgLM, ProGen2, and ESM2 show significant correlations for certain datasets, they fail to generalize across all properties or similar datasets.
4. The study finds that model architecture has less impact on zero-shot performance than the training data composition. Models incorporating protein structure perform better than sequence-only models, indicating that structural information is crucial for accurate predictions.
5. The authors also investigate the germline bias in protein language models, revealing that evolutionary signals significantly influence model predictions. On average, germline edit distance accounts for 40% of the apparent predictive power, suggesting that models rely heavily on evolutionary patterns rather than biophysical mechanisms.
6. Fine-tuning models with sufficient data (10^3 points) can improve performance, but the study shows that even simple one-hot encoding models can match the performance of billion-parameter models when provided with enough developability data.
7. The study concludes that while AI models show promise in certain areas, they are not yet capable of generalizable zero-shot or few-shot prediction of antibody developability. The authors recommend further research to integrate richer sources of information and reduce germline bias.
💻Code: github.com/Graylab/FLAb
📜Paper: biorxiv.org/content/10.64898…
#AntibodyDesign #AIBenchmarks #ProteinEngineering #DevelopabilityPrediction
4
11
76
18,723