
Jun 11
𝙎𝙩𝙧𝙪𝙘𝙩𝙪𝙧𝙖𝙡 𝘼𝙡𝙞𝙜𝙣𝙢𝙚𝙣𝙩 𝙤𝙛 𝙆𝙣𝙤𝙬𝙡𝙚𝙙𝙜𝙚 𝙂𝙧𝙖𝙥𝙝𝙨 𝙖𝙣𝙙 𝙇𝙞𝙣𝙠 𝙋𝙧𝙚𝙙𝙞𝙘𝙩𝙞𝙤𝙣: 𝘼 𝙎𝙪𝙧𝙫𝙚𝙮 𝙤𝙛 𝙩𝙝𝙚 𝙇𝙞𝙩𝙚𝙧𝙖𝙩𝙪𝙧𝙚
doi.org/10.1142/S1793351X254…
Why should you read this research article?
🔹 Delivers the first comprehensive survey that unifies the relationships between #knowledge #graph (#KG) structure, #Knowledge #Graph #Embedding #Models (#KGEMs), and the #link #prediction (#LP) task—addressing a critical gap in state-of-the-art understanding of how graph topology shapes model learning.
🔹 Systematically reviews key frequency-based structural metrics—including node #degree, #relationship #frequency, node-relationship #co-frequency, and node-node co-frequency—and shows how each has been documented to bias or determine KGEM performance across benchmark datasets like #FB15k-237, #WN18RR, and #YAGO3-10.
🔹 Synthesises findings on #hyperparameter preference across leading KGEMs (including #TransE, #DistMult, #ComplEx, #RotatE, and #RESCAL), clarifying how scoring functions, negative samplers, loss functions, and optimisers interact with KG structure to shape LP outcomes.
🔹 Introduces the novel #Structural #Alignment #Hypothesis, proposing that KGEM-based LP can be fundamentally modelled as a graph structural task—and presents the #LP #Pyramid as a conceptual framework layering data, structure, semantics/ontology, and higher-order features.
🔹 Outlines actionable open research directions covering structure-driven hyperparameter selection, #ontological property analysis, #embedding-free LP, and the urgent need for structurally-controlled benchmark KGs—charting the path forward for #biomedical, #semantic #web, and #knowledge-driven #AI applications.
Register a FREE account today at World Scientific to read this article. Valid till 31 July 2026!
Recommend this journal to your library today. We will be happy to work with your librarian to get you the necessary access—email us at cjlim@wspc.com to kickstart this access today!

2
5
318

10 Sep 2025
Bio-KGvec2go: Serving up-to-date Dynamic Biomedical Knowledge Graph Embeddings
1. Bio-KGvec2go is an innovative extension of the KGvec2go Web API, designed to generate and serve knowledge graph embeddings for widely used biomedical ontologies, such as the Gene Ontology and Human Phenotype Ontology. It addresses the challenge of providing up-to-date embeddings to reflect the dynamic nature of these ontologies, which are constantly evolving with new discoveries and knowledge.
2. The platform employs a variety of knowledge graph embedding models, including TransE, TransR, DistMult, HolE, RDF2Vec, and BoxE, to capture different aspects of the graph structure and semantic information. This diversity allows researchers to choose the most suitable model for their specific tasks, enhancing the applicability and effectiveness of the embeddings.
3. Bio-KGvec2go offers three main functionalities: downloading the latest embeddings for different ontology versions, computing semantic similarity between ontology classes, and retrieving the top 10 most similar classes for any given ontology class. These features facilitate various biomedical research tasks, from ontology-based machine learning to semantic annotation and curation.
4. By providing regularly updated and accessible knowledge graph embeddings, Bio-KGvec2go democratizes access to these valuable resources. Researchers without the computational power to train their own models can now conduct analyses with the latest data representations, accelerating experimentation and improving performance across various biomedical applications.
5. The platform is built upon the existing KGvec2go API and is implemented in Python using Flask. It is designed to support an automated update mechanism that periodically downloads new ontology releases, computes checksums, and recomputes embeddings when changes are detected. This ensures that the embeddings are always aligned with the most current versions of the ontologies.
6. Bio-KGvec2go has significant implications for biomedical research. It enables more accurate and efficient machine learning approaches for tasks such as protein function prediction, gene-disease association discovery, and patient similarity computation. Additionally, it supports ontology development and curation by providing tools for semantic similarity assessment and concept identification.
7. As future work, the authors plan to expand Bio-KGvec2go to support additional biomedical knowledge graphs and embedding models. They also aim to enhance the similarity and top closest concepts search functionalities by introducing features such as autocomplete for concept labels and tolerance to minor typos, making the platform even more user-friendly.
📜Paper: arxiv.org/abs/2509.07905
#Bioinformatics #KnowledgeGraphs #Ontologies #MachineLearning #BiomedicalResearch #KGvec2go #BioKGvec2go

3
969

2 Jul 2025
DISTMULT、eq 移動でそこそこ移動 -> 1 個 neq 移動で戻る -> eq 移動で少し戻る -> 1 個 neq 移動で戻る -> eq 移動でめっちゃ Y 付近に移動みたいなケースがやば過ぎて何も考えられなくなる
2
1,683

2 Jul 2025
ええ?DISTMULT
・コスト2の移動は幅1に分解してよい
・答えは|X-Y| 19以下
まで考察して絶対解けてると思ったんだが
2
799
30 Apr 2025
Heterogeneous network drug-target interaction prediction model based on graph wavelet transform and multi-level contrastive learning
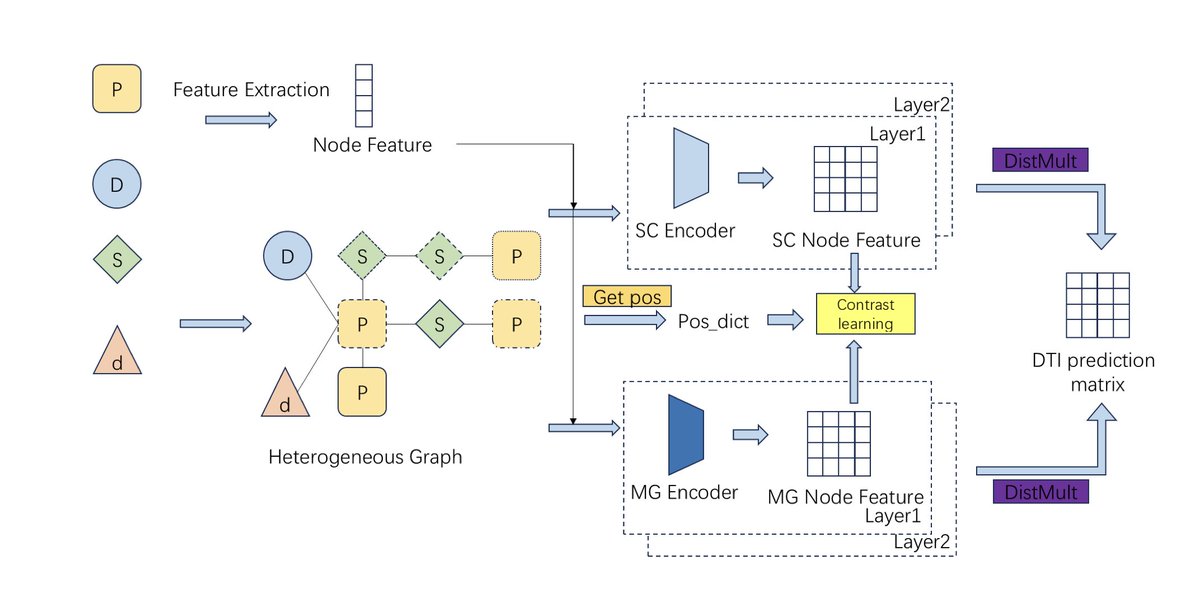
1. This study proposes GHCDTI, a novel framework for drug-target interaction (DTI) prediction that combines graph wavelet transform (GWT), heterogeneous graph convolutional networks (HGCN), and multi-level contrastive learning to improve prediction accuracy and interpretability.
2. GHCDTI integrates both local neighbor structures and deep multi-hop associations from a heterogeneous biological graph that includes drugs, proteins, diseases, and side effects—capturing a broader spectrum of biological relationships.
3. The GWT module extracts multi-scale node features by decomposing graph signals into frequency components, enabling the model to distinguish both global and subtle local interaction patterns across the network.
4. The HGCN module aggregates neighborhood information across heterogeneous node types, allowing drugs and proteins to influence one another through learned cross-entity message passing, while preserving relational semantics.
5. A contrastive learning strategy aligns representations from the two perspectives (HGCN and GWT), using similarity-aware sampling and InfoNCE loss to enhance feature robustness and reduce overfitting to data biases.
6. GHCDTI includes a semantic attention mechanism that fuses the multi-scale views into unified embeddings, dynamically weighting features from different perspectives based on their contextual relevance.
7. For final prediction, the framework uses DistMult, a diagonal matrix-based bilinear decoder that models diverse relationships within the heterogeneous graph—capturing not only DTI but also interactions across diseases, side effects, and molecular similarities.
8. On a large benchmark dataset from Luo et al., GHCDTI significantly outperforms advanced baselines including FRoGS, SiamDTI, and HyperAttentionDTI, achieving the highest AUC and AUPR scores across 10-fold cross-validation.
9. Ablation experiments confirm the critical importance of both the GWT module and the contrastive learning objective—removal of either degrades performance, with GWT contributing most to capturing dynamic interaction features.
10. By addressing key challenges in DTI modeling—such as poor interpretability, static structure reliance, and data imbalance—GHCDTI offers a comprehensive and biologically grounded solution for computational drug discovery.
💻Code: github.com/chromaprim/SHGCL-…
📜Paper: arxiv.org/abs/2504.20103
#DrugDiscovery #GraphNeuralNetworks #ContrastiveLearning #ComputationalBiology #Bioinformatics #AI4Science #DTIPrediction #HeterogeneousGraphs
3
636
30 Apr 2025
Heterogeneous network drug-target interaction prediction model based on graph wavelet transform and multi-level contrastive learning
1. This study proposes GHCDTI, a novel framework for drug-target interaction (DTI) prediction that combines graph wavelet transform (GWT), heterogeneous graph convolutional networks (HGCN), and multi-level contrastive learning to improve prediction accuracy and interpretability.
2. GHCDTI integrates both local neighbor structures and deep multi-hop associations from a heterogeneous biological graph that includes drugs, proteins, diseases, and side effects—capturing a broader spectrum of biological relationships.
3. The GWT module extracts multi-scale node features by decomposing graph signals into frequency components, enabling the model to distinguish both global and subtle local interaction patterns across the network.
4. The HGCN module aggregates neighborhood information across heterogeneous node types, allowing drugs and proteins to influence one another through learned cross-entity message passing, while preserving relational semantics.
5. A contrastive learning strategy aligns representations from the two perspectives (HGCN and GWT), using similarity-aware sampling and InfoNCE loss to enhance feature robustness and reduce overfitting to data biases.
6. GHCDTI includes a semantic attention mechanism that fuses the multi-scale views into unified embeddings, dynamically weighting features from different perspectives based on their contextual relevance.
7. For final prediction, the framework uses DistMult, a diagonal matrix-based bilinear decoder that models diverse relationships within the heterogeneous graph—capturing not only DTI but also interactions across diseases, side effects, and molecular similarities.
8. On a large benchmark dataset from Luo et al., GHCDTI significantly outperforms advanced baselines including FRoGS, SiamDTI, and HyperAttentionDTI, achieving the highest AUC and AUPR scores across 10-fold cross-validation.
9. Ablation experiments confirm the critical importance of both the GWT module and the contrastive learning objective—removal of either degrades performance, with GWT contributing most to capturing dynamic interaction features.
10. By addressing key challenges in DTI modeling—such as poor interpretability, static structure reliance, and data imbalance—GHCDTI offers a comprehensive and biologically grounded solution for computational drug discovery.
💻Code: github.com/chromaprim/SHGCL-…
📜Paper: arxiv.org/abs/2504.20103
#DrugDiscovery #GraphNeuralNetworks #ContrastiveLearning #ComputationalBiology #Bioinformatics #AI4Science #DTIPrediction #HeterogeneousGraphs

1
6
687

1 Jan 2023
It also covers our recent work (@NeurIPSConf 2022) on bridging the gap between factorisation-based models like ComplEx, TuckER, or DistMult, the go-to models for link prediction on large-scale multi-relational graphs, and GNNs! arxiv.org/abs/2207.09980, by @yihong_thu et al.

1 Jan 2023

🎄It's 2023! In a new post, we provide an overview of Graph ML and its subfields (and hypothesize for '23), eg Generative Models, Physics, PDEs, Theory, KGs, Algorithmic Reasoning, and more!
With @ren_hongyu @zhu_zhaocheng @chrsmrrs and @jo_brandstetter
mgalkin.medium.com/graph-ml-…
1
22
7,426

5 Dec 2022
Even more interesting finding is that the most expressive message functions should capture vector scaling, eg, multiplication or circular correlation. This result gives a solid foundation for GINE with multiplicative message function and CompGCN with DistMult.
3/4
1
3

15 Dec 2021
【知識グラフとレコメンダシステムのDTIへの応用】
4つのデータセットから知識グラフを構築。DistMultで畳み込んでる。構造情報も加えてNFMに投げる。
Luo’s datasetにはdrug-diseaseやdeug-side effectの関係性も保持されている。
pubmed.ncbi.nlm.nih.gov/3481…
3

1 Nov 2021
Check out our new scalable KG embedding framework! It supports super efficient training of single/multi-hop algorithms on extremely large graphs (~86m nodes), including GQE, Query2box, BetaE, TransE, RotatE, DistMult, ComplEx and so on!🥳
github.com/google-research/s…

1 Nov 2021

Excited to share our collaboration with @GoogleAI: SMORE is a scalable knowledge graph completion and multi-hop reasoning system that scales to hundreds of millions of entities and relations. @ren_hongyu, @hanjundai, et al.
arxiv.org/abs/2110.14890
github.com/google-research/s…
5
23

9 Oct 2019
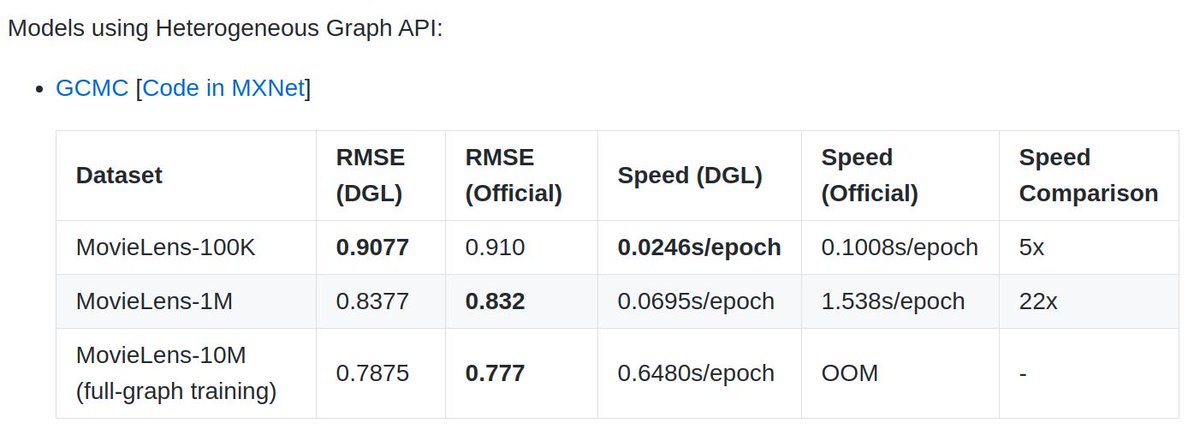
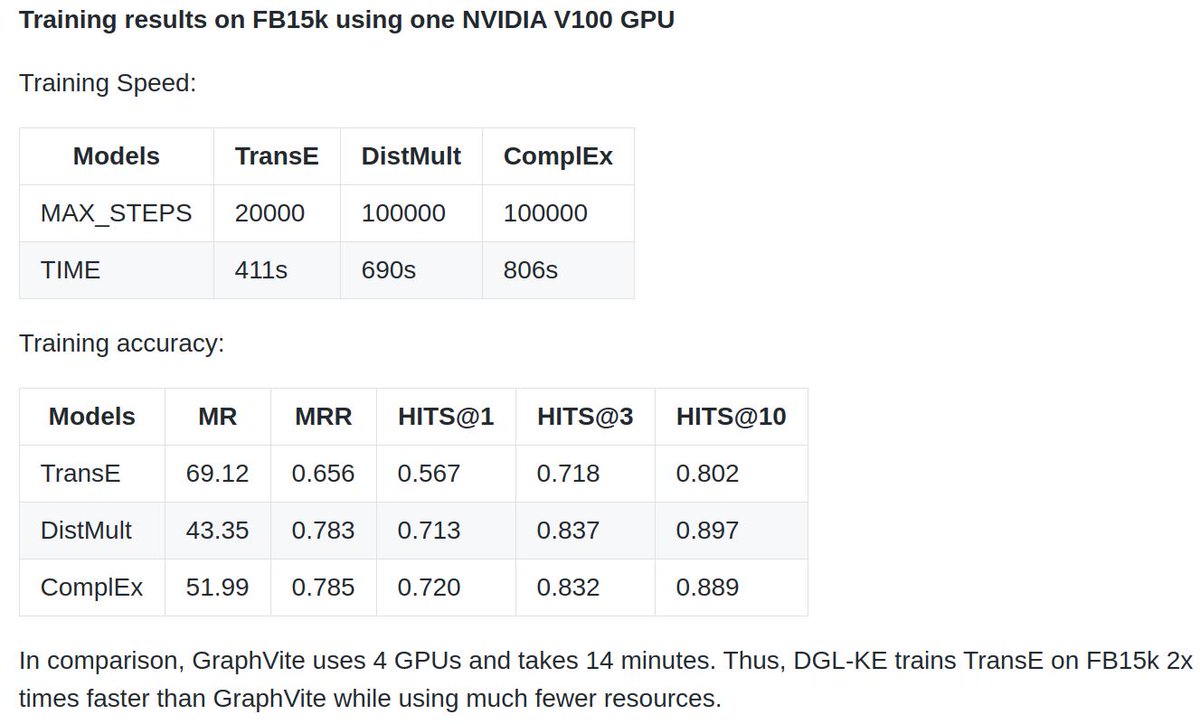
Heterogeneous graph support is finally here! Many new models: GCMC, RGCN(for hetero), HAN, Metapath2vec. New DGL-KE package supports efficient training of TransE, ComplEx, DistMult. Look forward to new research ideas using the right tool! V0.4 release: github.com/dmlc/dgl/releases…

3
58
152

7 Oct 2019
DGL v0.4.0 includes heterogeneous graphs, which means it supports KG embedding methods like TransE, DistMult or ComplEx now!
github.com/dmlc/dgl/releases…
3
11

27 May 2019
We tried this on two common models (DistMult, ConvE) and datasets (WN18, YAGO-10) and show that (i) computing the attacks is efficient, (ii) they’re effective at attacking, and (iii) they highlight what the model is looking at (summarized as rules).

1
3

17 Feb 2019
Embedding Models for Episodic Knowledge Graphs / Ma, Tresp, Daxberger | @journalWebSem bit.ly/2UeisFQ "We generalize leading learning models for static knowledge graphs (i.e., Tucker, RESCAL, HolE, ComplEx, DistMult) to temporal knowledge graphs." ht @aaranged
2

6 Dec 2018
There are several numbers in there where I’m not sure about the source. E.g. FB15k-237 for DistMult. Would be great if there was a link to the paper that reported the „best“ result of a method. In KB link prediction this is often not the original paper.
2
6

9 May 2018
NL研のモデルはDistMult, ComplEx(HolE), RESCALもハイパラ設定で包含し,tripletとrelation pathも同一コードで計算可能
relation pathのモデル化時にはComplExとRESCALの間にある非可換性 省パラメータが丁度良い塩梅になる仕組み
4

27 Mar 2018
To be clear what this means. With some models, for example, DistMult, you can solve these datasets by just looking at the relations. If you do not touch the entities you can still solve affected datasets almost perfectly!
1

4 Nov 2017
清华大学开源OpenKE:知识表示学习平台 jiqizhixin.com/articles/2017… →
清华大学自然语言处理实验室近日发布了 OpenKE 平台,整合了 TransE、TransH、TransR、TransD、RESCAL、DistMult、HolE、ComplEx…
3
2
28 Aug 2017
We have released our ConvE (Pytorch) code along with DistMult and ComplEx. Gets you up and running in 5 minutes github.com/TimDettmers/ConvE
1
4
17