
Jun 12
takže jestli Slavia spustí FaceRec s bonusem, že dohled nad tím budou mít lidé jako Komorous. Tak já na stadion chodit nebudu. To říkám na rovinu. To fakt ne.
2
19
298

@stephenbalaban FaceRec was similar to the last guys facial recognition Memex.
A good use case = bouncers having a list of banned people.
Also lively/stochasticity detection that connects to heat map of some sort helps people find ‘fun’ areas.
forbes.com/sites/andygreenbe…
1
5
298

9 Apr 2025
100% And he grows that facial hair so that facerec can not pick him up at goatfarms.
1
2
11

28 Jan 2025
i still dont understand how we got out of the campus protests like "we need to be LESS anon. we need FULL faces! Govt names! photoshoots! location details! like sure face means case but this is good PRRRR" the mask bans & facerec id & sickness in camps were good actually!
1
29
610

1 Jan 2025
Probably not fixable. They give you the disease so they can sell you the cure. In this case, it will be increased surveillance, facerec, monitoring your finances, skimming your data.
How quickly X found out who the guy was from a few meager clues proves how powerful that is.
1
4
74
2,553

29 Oct 2024
If everyone inconvenienced / defamed by algorithmic misidentification were automatically entitled to compensation from the Controller at fault, you can bet that corporate brands would be MUCH less keen to install facerec Data Fairies all over the place.
28 Oct 2024

🔴This teenager was WRONGLY flagged as a criminal by facial recognition in a @homebargains shop
This Orwellian tech prone to serious mistakes has no place in Britain
We've written to major retailers incl. @IcelandFoods & @Tesco asking them to RULE OUT using facial recognition
4
2
9
573

1 Oct 2024
Interesting discussion about #facerec in policing. The police provide evidence...
1
2
615
11 Sep 2024
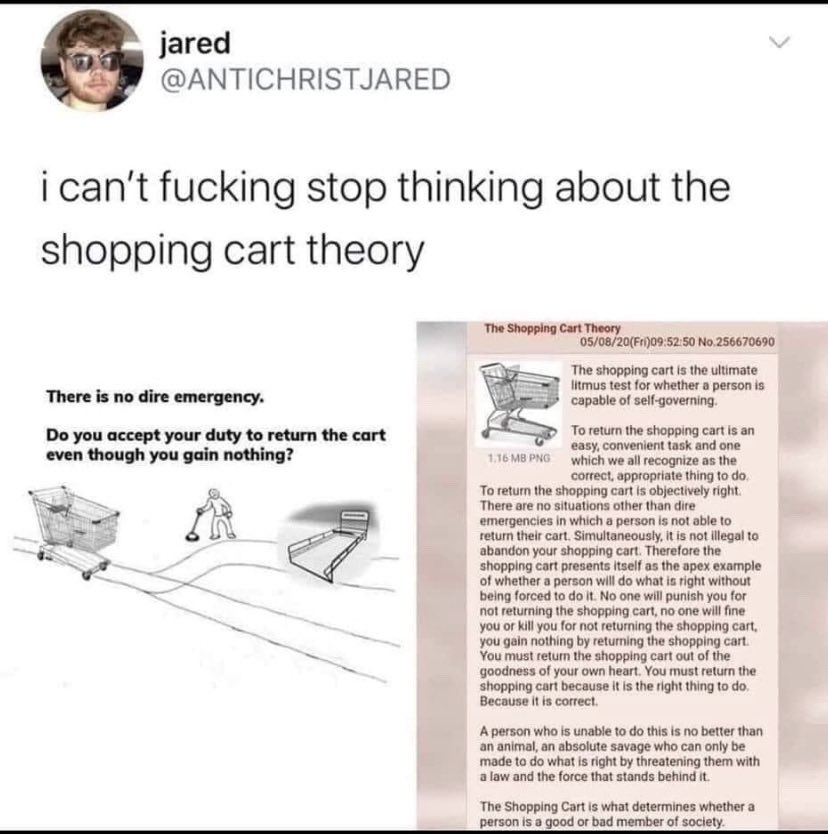
I reckon it’s worth starting a rumour that supermarkets are using CCTV with facerec to track who *isn’t* returning their trolleys and exclude them from receiving special offers.
If enough people believe it, it’ll have the opposite of a chilling effect, no?! 🙌🏽
10 Sep 2024

We will be monitoring CCTV at Somerfields Supermarket to see how many of you are savages
1
1
407

26 Aug 2024
FaceRec sagt ja, erkennbare biometrischen Merkmale stimmen überein, Kleidung stimmt überein, Brille stimmt überein und ist auch noch ein spezielles Modell, Frisur stimmt überein, selbst die Mimik ist im Video erkennbar.
Das würde selbst bei Mordverdacht, jedem Gericht reichen
1
2
12

28 May 2024
Elevate your workforce management with IDS! Introducing FaceRec: Our advanced face recognition tech ensures accurate attendance tracking, boosting efficiency effortlessly. Learn more at idssoft.com/facerec-corporat….
Check the below threads for more!
#HRTech #HRSolution #FaceRec #IDS

3
1
24




24 Feb 2024
No, it works with everyone if the people building and training the system know what they are doing.
It's well known that if you train the system with a widely unbalanced distribution of ethnicities, it won't work well for ethnicities that appear rarely in the training set.
This has absolutely nothing to do with *which* ethnicities are rare. It's just a direct consequence of how learning works (in machines *and* in humans).
The fix is totally trivial: if you want comparable levels of performance on samples of various subcategories, just make sure your training set contains similar proportions of samples from each subcategory.
The issue is that in the early days of deep learning-based face recognition, a number of facerec service providers (e.g. AWS, IBM, etc) didn't pay attention to this. Their systems worked ok for widely-represented ethnicities in their training set, but not for others. Some folks mistakenly jumped to the conclusion that facerec is unavoidably discriminatory.
It's not.
You just have to do it right.
4
1
52
6,937
9 Jan 2024
The #HorizonScandal teaches us a lot more about #AIEthics than just facerec & bias. This is one of the technologies GAFAM were trying to keep out of the #AIAct by steering the definition of AI towards ML, then genAI & xrisk. ALL digital services need product law and auditability.
8 Jan 2024

I hope this surge of interest in the Horizon scandal causes politicians to think carefully before wholesale adoption of AI into critical public services. Eg encouraging the police to use potentially flawed and bias facial recognition could also see great miscarriages of justice.
1
12
2,578
9 Nov 2023
….the rule of law and presumption of innocence, access to justice, automation bias/dominance, the fundamental flaws in facerec tech, lessons from history on how easily surveillance turns abusive….
There’s so much more than ‘privacy’
2
92

26 Oct 2023
A theoretical ‘commitment to privacy’ is a poor substitute for actual enforcement of data protection law.
Not quite committed enough for the IC to be aware of/acknowledge the (many and well-documented) instances of racial bias producing inaccuracy in facerec tech though…
25 Oct 2023

UK Information Commissioner John Edwards spoke at today's @CommonsSITC about the ICO's commitment to ensuring privacy is at the heart of AI development. For more information about AI and data protection, check out our guidance: ico.org.uk/for-organisations…
3
7
2,734
21 Sep 2023
Ah, it was specifically LLMs. Still want to see a link to the data! BTW, love that #BAS23 name their main stage after Admiral Grace Hopper.
Wow, Agostino Calamia (@Shopify) found that a lot of #faceRec models actually do best on Indian faces :) #AIBias
21 Sep 2023

"The reality is: 88% of all language models are trained in the US or China. As European companies, we need to come together. We cannot wait. We need to start now." remarks @thsaueressig (@SAP) during his keynote on the Grace Hooper Stage. #BAS23

1
1
1
1,155

17 Jul 2023
Considering SanFrancisco banned government use of facial recognition in 2019 (details limited in my mind), I guess it makes sense the business sector would find a way to assist their law enforcement partners. (They can use FaceRec info provided by other sources in cases.)
5
320
4 Jul 2023
Where are all the AI bros offering age verification and facerec ‘solutions’ to the challenge of dangerous elderly drivers though? We already have the surveillance cam network! Surely there must be a Data Fairy that can detect and remote-disable Driving While Old offenders?
1
2
254

23 Jun 2023
Facial recognition has always been machine learning, even back when it was plausible for the Lone Gunmen to spoof it by painting their faces blue, and machine learning needs a dataset. Facerec is a tool of the surveillance state. Don’t help it out.
32