
Jun 11
Qualcomm mishandled my last report at first, but in the end they acknowledged the issue and paid the bounty. I reported a FastRPC UAF. Qualcomm said that they know about it but due to some internal tooling problems, the fix didn't reach all release branches for over a year.

2
1
41
2,335

May 20
Android 论文导读 · 2026-05-18
标题: 小模型 NPU 闲置算力 = 超越大模型:移动端 LLM test-time scaling 论文
大模型部署到手机一直面临性能不足与资源消耗过高的双重困境。简单把模型scale up 会导致内存和带宽瓶颈,让本就地受限的手机更加难以为继。Test-time scaling 是云端提升 LLM 质量的热门方法(Best-of-N、Beam Search 等),但业界普遍认为在移动端跑 test-time scaling 不切实际,因为移动端资源本已紧张,再用更多算力来 scaling 听起来是火上浇油。
这篇论文的核心洞察是:移动端 NPU(如高通骁龙 Hexagon)在 LLM 常规解码阶段存在大量闲置算力。LLM 解码时 GEMM 操作退化为 GEMV(一个 token 的向量与权重矩阵相乘),而 NPU 的矩阵单元专为大矩阵设计,此时利用率极低。与此同时,test-time scaling 方法(如 Best-of-N)通过增大批处理规模正好可以填补这一算力空白——相当于免费午餐。
然而在 NPU 上高效实现 test-time scaling 面临两个硬件挑战。其一是精度问题:NPU 原生支持粗粒度量化(per-tensor / per-channel),但缺乏对现代 LLM 所需的细粒度分组量化的硬件支持,直接用粗粒度假化化模型在数学推理任务上准确率严重下降。其二是效率问题:NPU 的通用向量单元(HVX)计算能力和内存带宽远弱于专用矩阵单元(HMX),而 Softmax 中的指数运算和混合精度 GEMM 中的反量化恰好落在向量单元上,成为瓶颈。
针对第一个挑战,作者提出了硬件感知的瓦片量化方案:在量化前先将权重按矩阵单元的 32×32 瓦片布局重排,再按组执行量化,使分组边界与 NPU 内存访问模式对齐,避免非连续内存访问造成的效率损失。针对第二个挑战,用 LUT(查找表)指令替换指数和反量化计算——HVX 的 vgather/vlut16 指令可以将 INT4 量化的权重直接查表转换为 FP16,跳过了传统方法中的 mask-unpack-convert 冗长指令序列。
实验在三代骁龙平台(8 Gen2/3/Elite)上进行,混合精度 GEMM 最高达 19.0 倍加速,Softmax 通过 LUT 加速达 2.2 倍。在 MATH500 数据集上,Qwen2.5-1.5B 使用 Best-of-N scaling 在 0.3s/token 延迟下达约 52% 准确率,超越了 Qwen2.5-3B 基线的约 44%。功耗方面,1.5B 模型 batch=8 时整体设备功耗低于 5W。系统基于 llama.cpp 实现,不依赖高通 QNN 闭源框架,通过 FastRPC 共享内存完成 CPU-NPU 通信。
为什么值得读:
这篇论文首次系统性地探索了移动端 NPU 用于 LLM test-time scaling 的可行性和 trade-off,对于在手机上做 AI 推理开发的工程师来说,它揭示了一个被忽视的优化维度——与其绞尽脑汁压缩模型,不如换个角度利用好 NPU 的闲置矩阵算力来做 batch inference。EUROSYS 顶会论文,实验扎实(跨三代平台),代码已开源(llama.cpp-npu htp-ops-lib),可直接复现。
核心观点:
• LLM 解码阶段 GEMM 退化为 GEMV 导致 NPU 矩阵单元利用率极低,test-time scaling 的批处理特性正好可以利用这一"免费"算力
• 硬件感知瓦片量化通过预排列权重使分组边界与 NPU 32×32 瓦片对齐,避免非连续内存访问;精度损失远小于量化本身的影响(tile 量化 vs 常规分组量化的 WinoGrande 差值 < 1%)
• LUT 加速 Softmax(指数运算)和反量化(INT4→FP16)可绕开向量单元的计算瓶颈,Softmax 加速 2.2 倍,GEMM 混合精度加速 19.0 倍
• 在 MATH500 上 Qwen2.5-1.5B Best-of-N 可超越 Qwen2.5-3B 基线准确率,Llama3.2-1B Beam Search 同样超越 3B 基线,小模型 scaling 是比直接上大模型更具性价比的路径
• 1.5B 模型 batch=8 时设备整体功耗低于 5W,NPU 的能效优势显著优于 GPU
对 Android 性能优化的启示:
对于需要在设备端运行 AI 推理的 Android 应用,优先考虑 NPU 而非 GPU/CPU 作为推理载体——论文数据显示 NPU 在批量解码场景下能效显著更优且功耗可控。在涉及 NPU/DSP 等专用加速器的开发中,量化权重数据的内存布局会直接影响性能,应根据目标硬件的访问模式(本文中即 32×32 瓦片)对权重进行预变换,而非直接使用通用量化格式。llama.cpp 在 CPU 后端和 NPU 后端的性能差距本质上就是内存布局策略的差异,开发者自行集成加速器时同样需要关注这一层。
2
2
465

Apr 3
Friday surprise: 10,000 wallets have been whitelisted!
If you've used FastRPC or have placed on the Leaderboard, you now have access to Fast Swaps.
Can you get the Fastest Swap? Share its speed on X
239
46
283
4,272

Mar 30
Early access available to the top users of FastRPC and recent additions to the waitlist. @Fast_Protocol
Let's see who climbs the miles leaderboard this week!
Mar 30

Fast Swaps early access is live:
🔹 1,500 wallets whitelisted
🔹Swaps in under a second on Ethereum mainnet.
🔹Not an L2. Not a bridge. Native Ethereum, preconfirmed.
Check if you have access 👇
4
52
Mar 24
Swaps are now always fast on FastRPC!
...aaand Fast Swaps is gearing up for general release. Should be a magical experience!
Mar 24
The foundation for the general release of Fast Swaps is live: key infrastructure upgrade from @primev_xyz
FastRPC users are already seeing the speed improvements; faster preconfirmations, more reliable
execution.
Speed you can count on, every time.
3
43
Mar 24
The foundation for the general release of Fast Swaps is live: key infrastructure upgrade from @primev_xyz
FastRPC users are already seeing the speed improvements; faster preconfirmations, more reliable
execution.
Speed you can count on, every time.
306
52
346
3,677

Mar 10
3/4 Beyond the AI integration, the shipping didn't stop this week. 🚢
We also pushed:
• Live "Miles" estimation UI before committing to swaps
• A massive new /learn hub for developers
• Expanded Knowledge Base for FastRPC, Fastx402 & Slashing mechanics
1
2
103

Mar 10
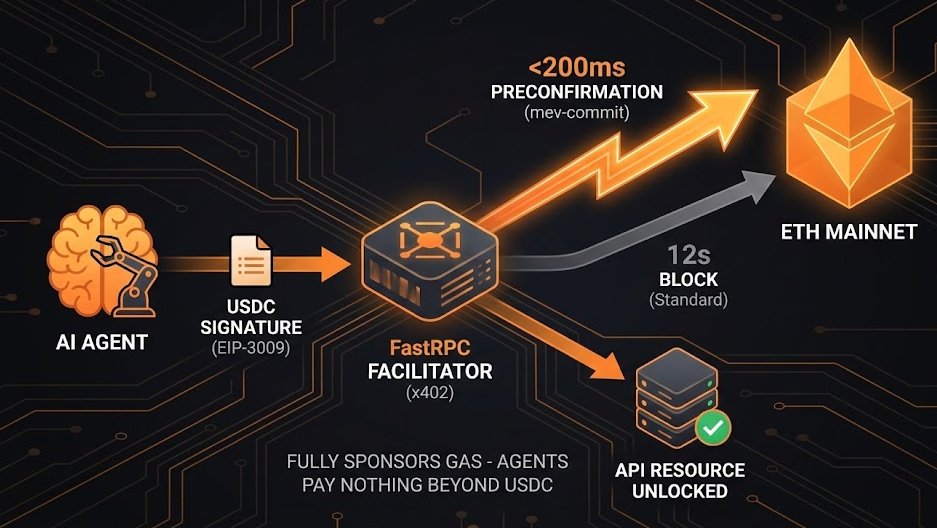
The problem: Ethereum mainnet takes ~12 seconds per block, and for real finality you're looking at ~15 minutes (2 epochs). For a pay-per-API-call protocol like x402, that's terrible. The server needs to know the payment landed before releasing data. You can't make an agent wait 12 seconds for an API response, let alone 15 minutes. That's why Coinbase's facilitator only supports Base (which has ~2 second blocks and fast soft confirmations).
Preconfirmations: Block proposers (validators) make a cryptographic commitment before the block is finalized that they will include your transaction. It's basically a validator saying "I guarantee this tx will be in my block" — and they have economic stake backing that promise. If they break it, they get slashed.
What Primev did: Their facilitator submits the transferWithAuthorization tx through their FastRPC infrastructure, which gets a preconfirmation from the upcoming block proposer in ~100-200ms. The facilitator can then tell the server "payment is committed" with high confidence — the validator's stake is on the line. End-to-end, the agent gets their data back in ~1.2 seconds.
So it's not that finality itself got faster on mainnet. It's that the facilitator accepts a preconfirmation (an economically-backed promise of inclusion) as "good enough" to release the data, rather than waiting for actual block confirmation. For a $0.01 API call, a validator risking their 32 ETH stake is more than sufficient security.
2
1
4
389
Feb 24
3/5 Enter the Fastx402 Facilitator Preconfirmations. ⚡️
Ethereum mainnet is the ultimate global infrastructure for this. By enabling sub-200ms preconfirmations via FastRPC, Primev paves the way for agents to onboard and transact directly on L1.
1
3
46

Feb 22
Fast RPC delivers low-latency, reliable blockchain access.It ensures faster transaction broadcasting, stable uptime, and smooth on-chain interactions — even during congestion.@Fast_Protocol #FastRPC #Web3 #Blockchain
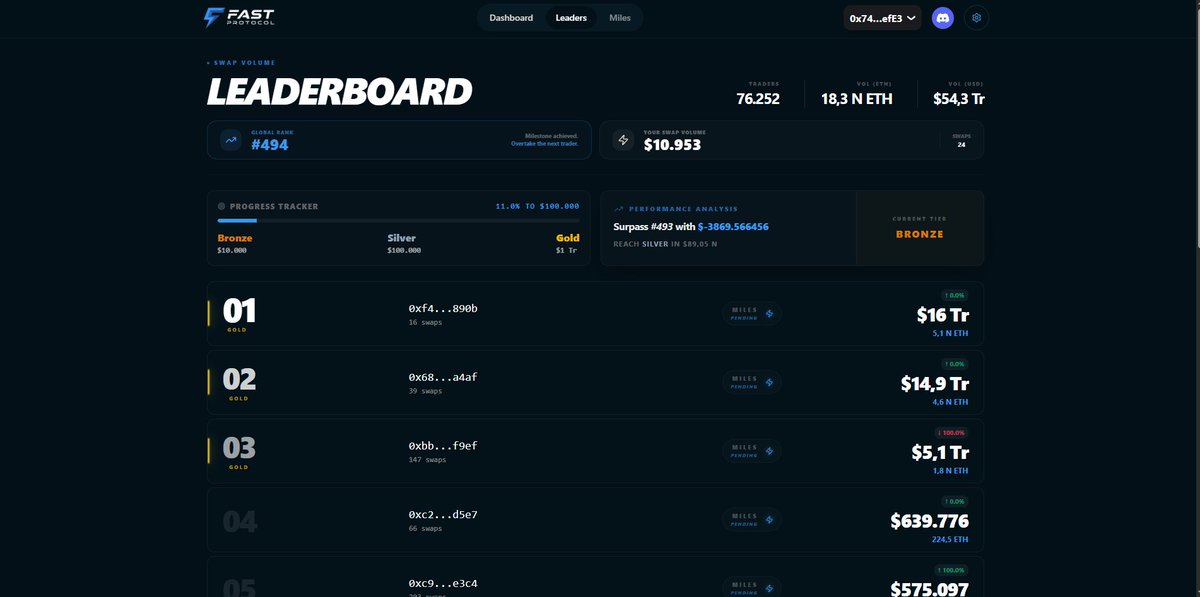
2
31

Feb 17
I just activated FastRPC on my Rabby recently, and the difference was immediate.
@Fast_Protocol Transactions feel more responsive, interactions are smoother, and that tiny layer of friction we have all gotten used to just is notthere anymore.
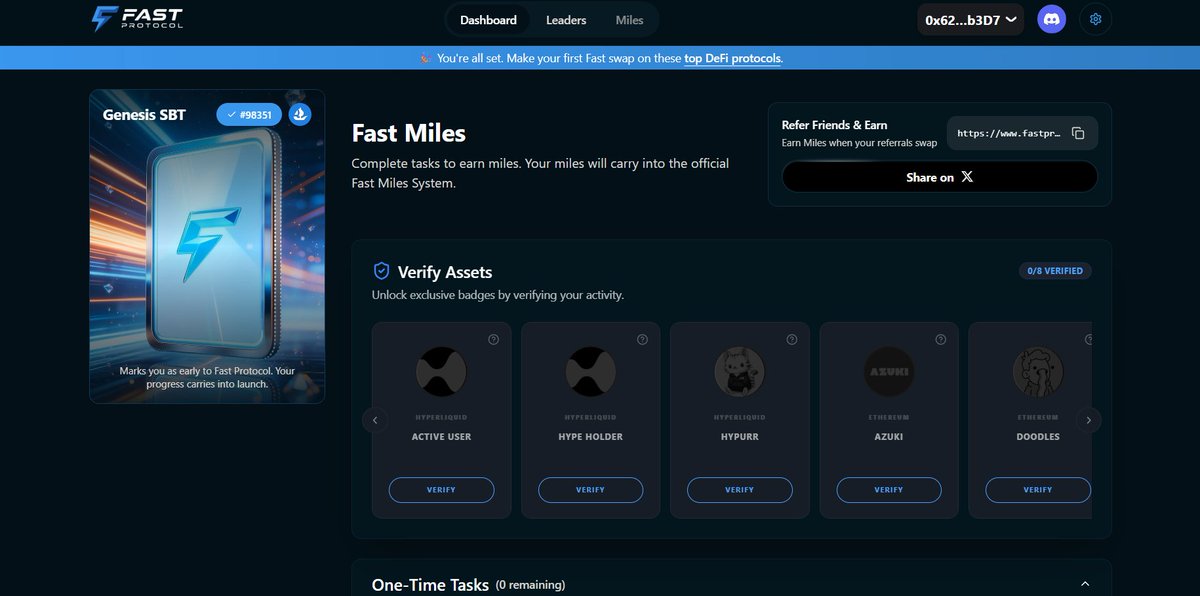
1
4
82

Feb 15
Switched to @Fast_Protocol Fast RPC and it’s been smooth ever since ⚡️
Private txs. No MEV stress. Miles stacking quietly in the background.
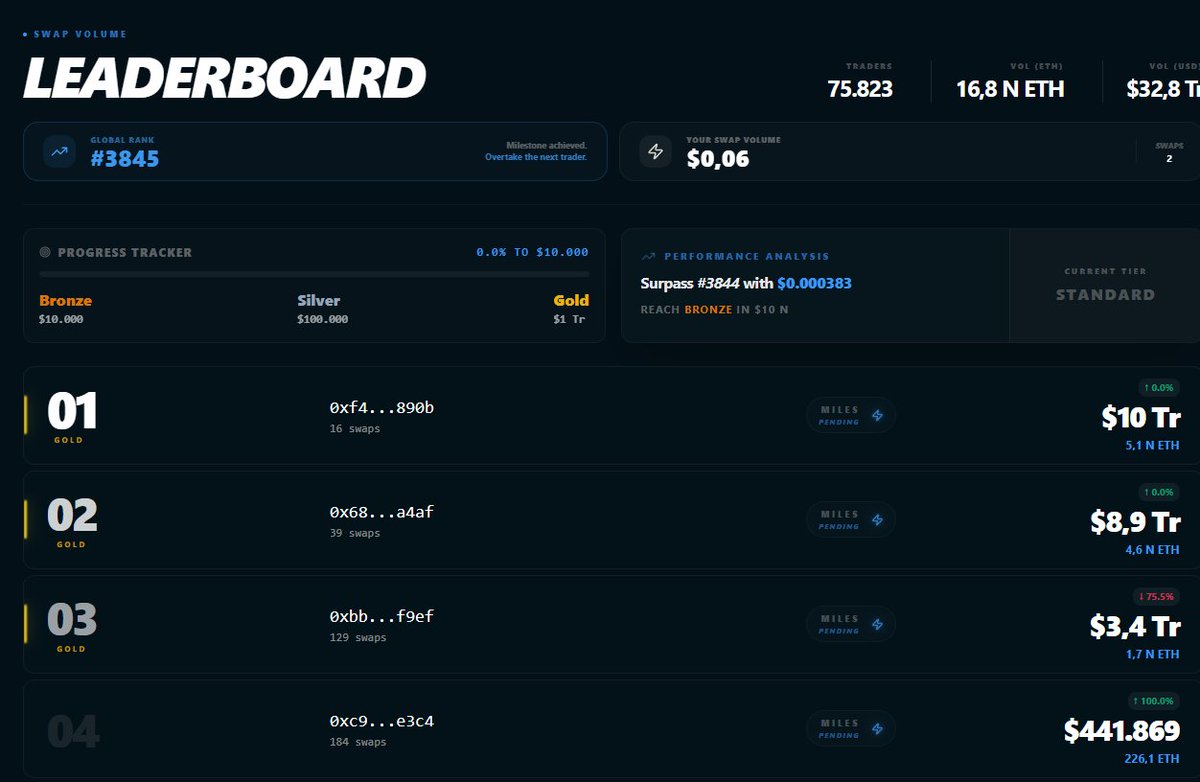
Bronze tier is the first milestone. Climbing step by step.
Let’s see how far FAST can go 🚀
#FastProtocol #FastRPC #DeFi #Ethereum #Web3
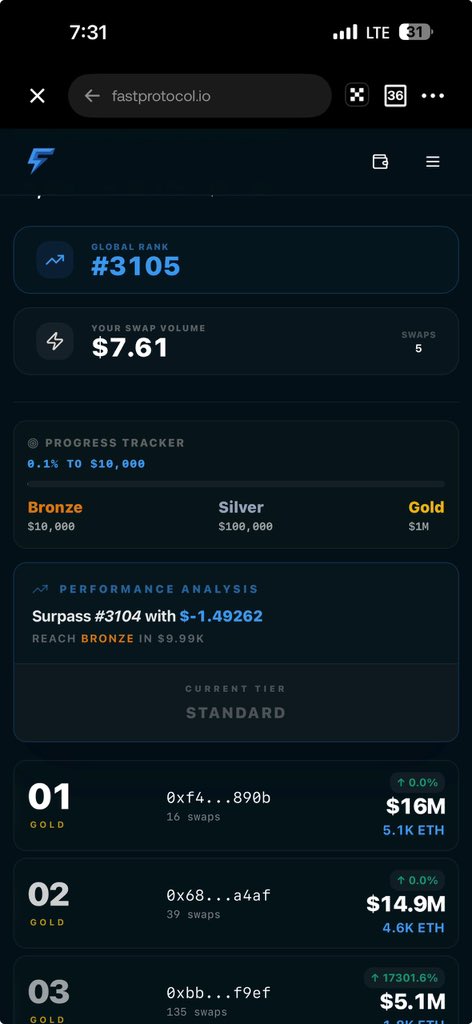
11
137

Feb 12
Been grinding FAST Miles and testing @Fast_Protocol RPC daily
Climbing the leaderboard step by step
Bronze is close. Silver is the real target
This is just the beginning of my FAST volume journey
Let’s see who secures their tier first
#FAST #FastRPC #FASTVolumeFlex
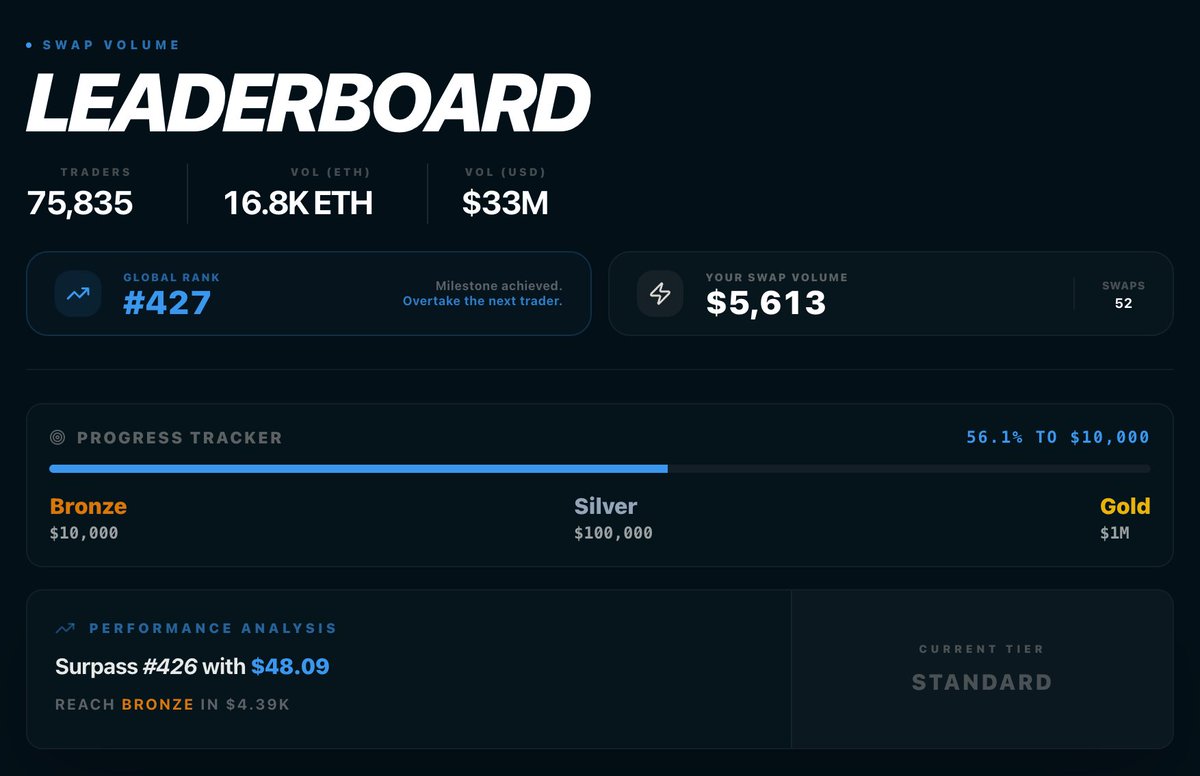
48
43
236

Feb 11
⚡ FAST Volume Flex – pushing toward the next tier
Been routing my swaps through Fast RPC for a while now, and the difference is real. Transactions feel smooth, preconfirmed almost instantly, and the whole UX is just faster.
Started stacking Fast Miles, and the progress is getting interesting:
Current swap volume: $87,765
Rank: #22 Global
Tier: FAST Bronze
Closing in on Silver next
Fast RPC makes it easy. No change in workflow, just switch RPC and keep swapping. Speed real on-chain activity = steady climb on the leaderboard.
Next goal: break into Silver and keep pushing volume.
@Fast_Protocol
#FAST #FastProtocol #FastRPC #Web3 ⚡

3
4
91

Feb 11
Been testing FAST RPC and stacking FAST Miles lately ⚡
The speed and reliability are seriously impressive.
Now pushing toward FAST Bronze Tier 🚀
Goal: keep increasing swap volume and climb the FAST leaderboard 🔥
Anyone else grinding FAST Miles? 👀
@Fast_Protocol #FASTRPC #DeFi #Crypto
2
60
1/7 Announcing Fastx402 Facilitator: Agentic payments with preconfirmations on Ethereum mainnet 🤖
AI Agents were exiled to L2s due to latency. We are bringing them back.
Enabling sub-200ms preconfirmations for machine commerce. Powered by FastRPC.
🧵👇
6
1
10
6,624

Using Fast RPC for daily swaps has been smooth so far ⚡
Fast execution, no priority fee stress and earning Fast Miles on real onchain activity.
Consistency really matters here.
@Fast_Protocol
#FastRPC #FastMiles

2
11
1,117

Fast Protocol is building the execution UX layer for Ethereum.
What you actually get with Fast Protocol:
- Execution guarantees on L1 (Sub-50ms transaction preconfirmations, not promises)
- Private orderflow (not just private mempool)
- Block positioning as a feature (Top-of-block / top 10% execution)
- MEV shared back with users. (positive-sum MEV, not tex)
- All on ETH mainnet (No new consensus)
Traction so far:
~110k preconfirmations
~$1B tx volume settled
~$35M swap volume via FastRPC (last 2 weeks)
~20% of ETH blocks include Fast preconfirmations
Built for teams with real users who care about execution quality:
DEXs, wallets, aggregators, stablecoin card issuers.
We’re opening up integration co-marketing partnerships.
If your users hate failed txs, bad prices, or waiting — let’s talk.

5
1
14
931
Using Fast RPC for daily swaps has been smooth so far ⚡
Faster execution, no priority fee stress and earning Fast Miles for real onchain activity.
Consistency really matters here.
@Fast_Protocol #FastRPC #FastMiles
7
495

We're aware FastRPC users had difficulties landing txs over the weekend, the issue has been fixed!
Nobody has run preconfs at scale so we see novel issues and appreciate the community's patience. Proud of the @primev_xyz team's dedication
4
8
262