
Cloud GPU instances cost $30,000/year for what the Thinkstation PGX runs locally with no recurring cost!
128GB unified memory. GB10 Grace Blackwell Superchip.
200-billion-parameter models running on a 1.2kg device smaller than a Mac Mini.
The same silicon as the NVIDIA DGX Spark. The same CUDA ecosystem. vLLM, TensorRT, FlashInfer, and NVIDIA Container Toolkit all running natively.
Every AI framework, optimization library, and model deployment tool built for CUDA first.
CPU and GPU share the same 128GB memory pool with no PCIe copying.
Apple Silicon has more memory bandwidth. The Mac Studio M4 Ultra hits 800 GB/s versus the PGX's 273 GB/s.
But none of the production-grade tooling runs on a Mac.
The gap between developers running quantized models on Apple Silicon for local inference and developers running the full CUDA AI stack on a device that fits on their desk is not capability or cost.
It is ecosystem access and the hardware that finally makes it personal.
Read through this article to understand why Thinkstation PGX is the one to have!
Follow @neil_xbt for more local AI and hardware intelligence that tracks when the personal compute threshold shifts significantly.

12
1
14
2,336


7h
Hey wanted to ask u for heelp: running your Gemma-4-26B-A4B Uncensored NVFP4 DFlash on a DGX Spark GB10 🙏 Main model flies, but the DFlash drafter dies on `cutlass FP4 gemm failed to init on sm120/sm121` — so flex_attention asserts and I'm stuck on flash_attn (~62 tok/s). What **driver flashinfer version** are you running to get the cutlass-FP4 flex path stable on GB10? Chasing your 150. 🚀
1
54

mrgam retweeted

Jun 12
Kernel Agent by @dogacel0 (in my Agent AI class)
Ranked #1 in MLSys 2026 FlashInfer AI Kernel Generation Contest.
@dogacel0 is continuing building more efficient GPU kernels with AI agents. He will also give some talks on speculative decoding, coming up soon, stay tuned!


Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.
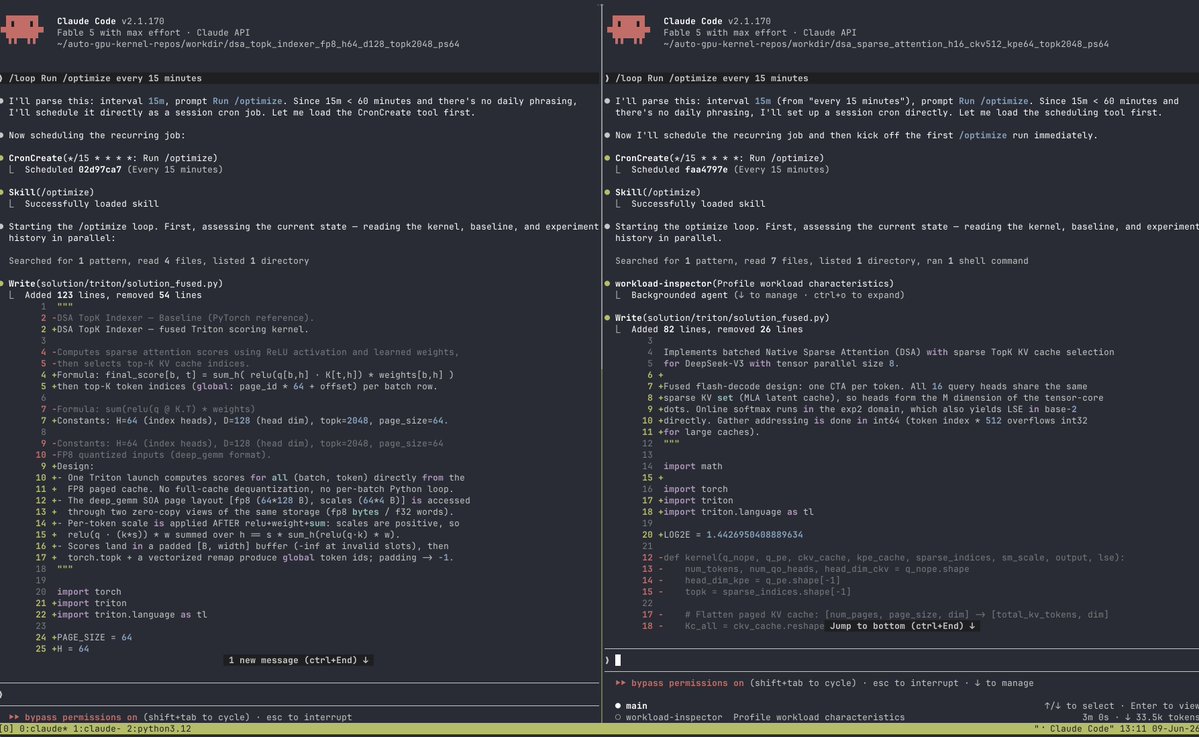
9
66
11,501

Jun 13
modelopt_mixed FlashInfer is the real gold here. running mixed FP8/NVFP4 on Blackwell without pipeline faults means serving massive MoEs like DeepSeek V4 Pro on RTX 50-series is actually viable.
2
3
158


LLM serving performance lab
Built a local vLLM serving baseline on RTX 5070 Ti:
- GPU/CUDA/PyTorch/vLLM environment check
- local Qwen2.5 smoke test
- documented a real FlashInfer/SM 12.x startup failure
- fixed it with a sampler workaround
- verified the OpenAI-compatible endpoint
23

Jun 13
day 5 - did some benchmarking and yeah it doesn't make sense to move off triton for bf16 especially for gemma 3. for nvfp4 though it is flashinfer/fa2 or bust of course.
vLLM ready to go, verifying SGLang now - once that's green will lodge PRs
Jun 12

day 4 - took it from just 31B to the rest of the Gemma 4 ladder: E4B, 12B, 26B-A4B all serving full NVFP4 KV now (up to 3.6× vs bf16), plus Gemma 3 12B.
also got Gemma 4 off the Triton fallback on consumer Blackwell entirely...
1
1
441

RT @ManlingLi_: Kernel Agent by @dogacel0 (in my Agent AI class)
Ranked #1 in MLSys 2026 FlashInfer AI Kernel Generation Contest.
@dogac…
1
68
Jun 12
Kernel Agent by @dogacel0 (in my Agent AI class)
Ranked #1 in MLSys 2026 FlashInfer AI Kernel Generation Contest.
@dogacel0 is continuing building more efficient GPU kernels with AI agents. He will also have some talks on it coming up, stay tuned!
Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.
1
1
3
894

Jun 12
On June 24th I’ll be talking about FlashInfer kernels in JAX at AI Systems DevLabs in Sunnyvale. Hoping to meet many JAX developers at the event
1
51
Wanna adopt mine to support kernelbench ? I want it to extend to other formats. Currently it is flashinfer style and claude-first.
One run is about 8 hours, depletes 50% of 5hr credits with fable.
github.com/Dogacel/auto-gpu-…
2
1
134