
🇦🇺 in 🇯🇵. ai developer experience @GoogleDeepmind. formerly partner engineering @ stadia.
Joined May 2008
- Tweets 40,051
- Following 5,680
- Followers 1,931
- Likes 203,800
2,179 Photos and videos












Jun 13
day 5 - did some benchmarking and yeah it doesn't make sense to move off triton for bf16 especially for gemma 3. for nvfp4 though it is flashinfer/fa2 or bust of course.
vLLM ready to go, verifying SGLang now - once that's green will lodge PRs
Jun 12

day 4 - took it from just 31B to the rest of the Gemma 4 ladder: E4B, 12B, 26B-A4B all serving full NVFP4 KV now (up to 3.6× vs bf16), plus Gemma 3 12B.
also got Gemma 4 off the Triton fallback on consumer Blackwell entirely...
1
1
444
Jetha Chan retweeted

Jun 12
Real-time social robotics, from the cloud to your local device.
Watch Ian from our DevX team use Gemini Live for a seamless voice chat with Reachy Mini.
Then, stick around until the end to see the robot running locally on Gemma 4!
43
150
1,296
104,506
Jetha Chan retweeted

Jun 11
Programmers in game studios use AI coding tools. Not all of them yet, but it's getting popular lately. Gen-AI in concept art is very common. Artists paint modifications on top of AI generated image. Photoshop has various AI tools nowadays (context aware fill being one of the first). Translating text and dialogue to different languages is often done with AI. In rendering side, big studios have been talking at SIGGRAPH about their AI based light probe placement and probe/texture/material compression algorithms. AI based terrain generation and prop placement exists in big engines. DLSS from Nvidia is well known AI upscaler. DLSS5 adds gen-AI to the mix, etc, etc. There aren't many games left with no AI used in their production.

Somehow I doubt the terminally online grifter who's had nothing to do with the games industry for decades knows what "all games studios" are doing.
Maybe if he used AI, he'd finally be able to release whatever his scam geme is called.

74
36
580
65,341
Jetha Chan retweeted

Congratulations to Google on open-sourcing Gemma Diffusion!
I want to give a shout-out to a group of really talented Cornell students who developed in the lab a lot of the new ideas that we see in this model:
@mariannearr -- Block diffusion is what enables Gemma Diffusion to generate arbitrary length sequences and support KV caching.
@mariannearr @SchiffYair -- Efficient encoder-decoder diffusion (E2D2) extends block diffusion and is part of what makes Gemma really fast, speeding up inference by running a smaller decoder model.
@SchiffYair @ssahoo_ @Guanghan__Wang -- Uniform diffusion LMs (UDLMs) are the family of discrete diffusion models that underlie Gemma and define its noise process and training objective. This work builds on our earlier simplified losses in MDLMs.
@ssahoo_ -- Uniform diffusion supports built-in error correction and is especially effective with distilled fast samplers like the ones introduced in Duo.
This is a great overview of Gemma Diffusion: newsletter.maartengrootendor…
Check out the students' papers below:

7
78
599
26,627
Jun 12
new kids on the block had a bunch of hits
chinese food makes me sick
Jun 11

Ajinomoto
106
Jun 12
day 4 - took it from just 31B to the rest of the Gemma 4 ladder: E4B, 12B, 26B-A4B all serving full NVFP4 KV now (up to 3.6× vs bf16), plus Gemma 3 12B.
also got Gemma 4 off the Triton fallback on consumer Blackwell entirely...
Jun 10
day 3 of my work building on @Hikari_07_jp's work - I have Gemma 4 31B serving with full 4-bit (NVFP4) KV cache on a GB10. every layer, even the D=512 global attention heads. measured 1.70× the KV capacity of fp8.
will ship PRs for flashinfer, vllm and sglang very soon!
1
661
Jetha Chan retweeted

Jun 10
iMessage is one of the most used messaging channels in America. Yet support for it in personal assistants has always been fragile.
We partnered with @NousResearch to fix that.
Now anyone can connect to iMessage, on any OS, and unlock entirely new iMessage experiences.


46
51
880
164,299
Jun 10
Jun 10

I gotta hand it to Gemma
Probably the most diverse set of open models ever released in a series:
• google/gemma-4-E2B-it
• google/gemma-4-E4B-it
• google/gemma-4-12B-it
• google/gemma-4-26B-A4B-it
• google/gemma-4-31B-it
Plus mtp:
• google/gemma-4-E2B-it-assistant
• google/gemma-4-E4B-it-assistant
• google/gemma-4-12B-it-assistant
• google/gemma-4-26B-A4B-it-assistant
• google/gemma-4-31B-it-assistant
Plus today diffusion:
• google/diffusiongemma-26B-A4B-it
That’s a lot of work and it’s only half way through 2026
2
118
Jun 10
day 3 of my work building on @Hikari_07_jp's work - I have Gemma 4 31B serving with full 4-bit (NVFP4) KV cache on a GB10. every layer, even the D=512 global attention heads. measured 1.70× the KV capacity of fp8.
will ship PRs for flashinfer, vllm and sglang very soon!

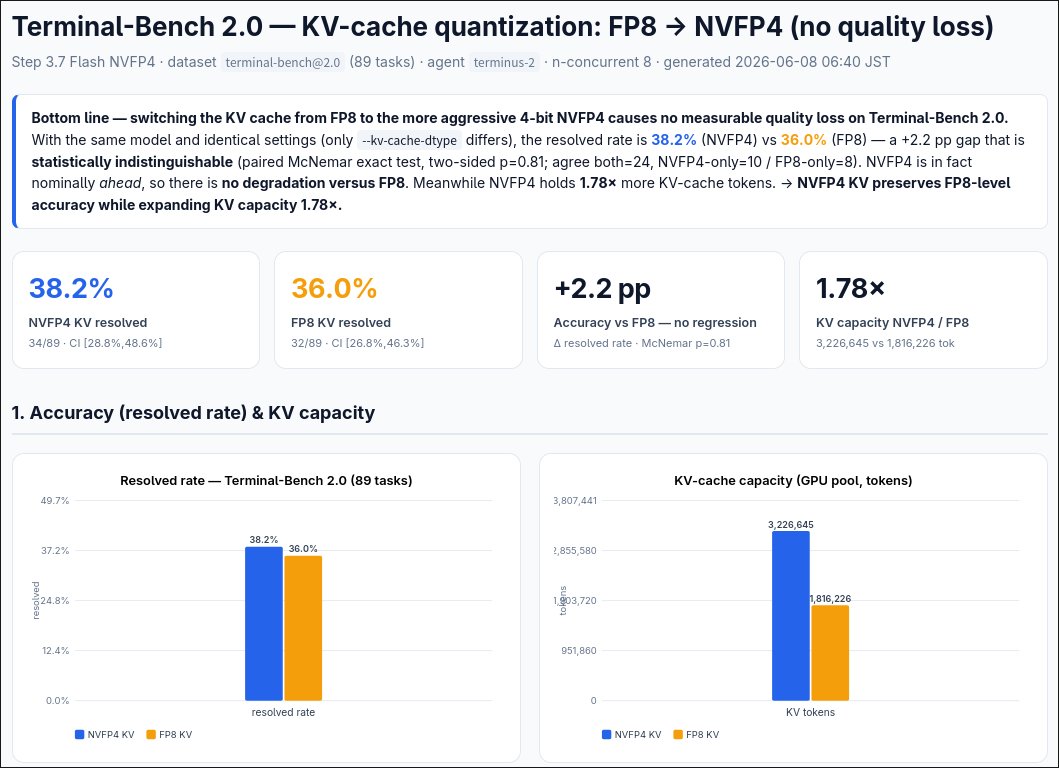
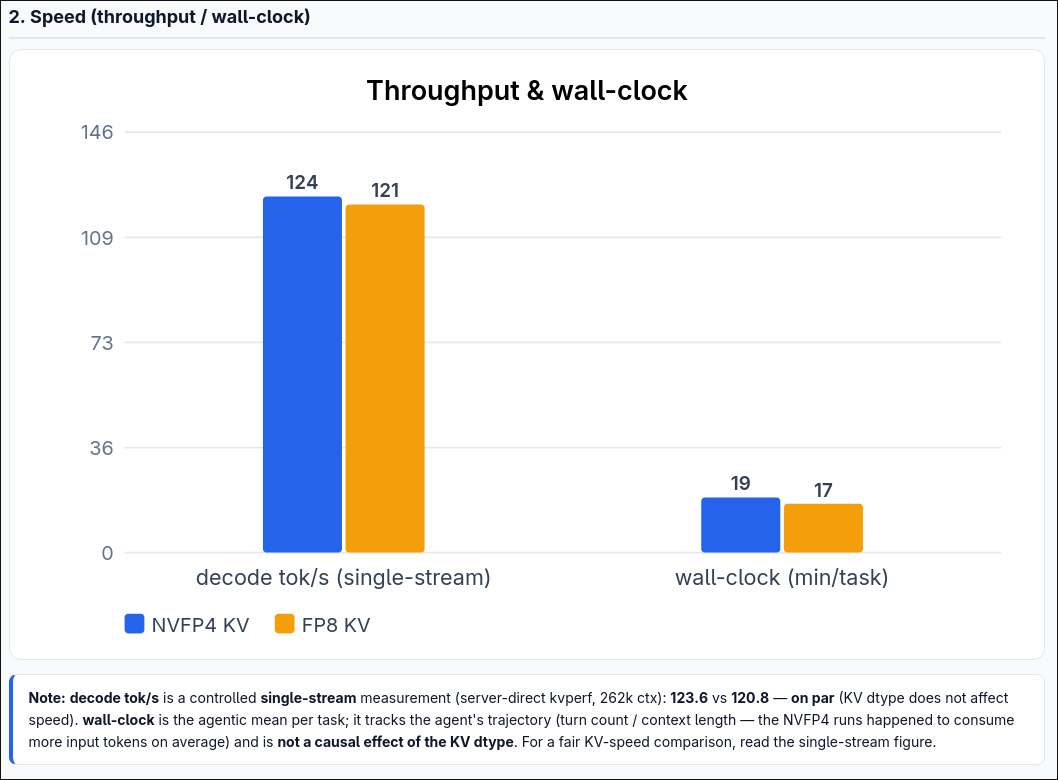
🚨 Big news: switching the KV cache from FP8 → NVFP4barely dents accuracy.
Verified on Terminal-Bench 2.0 (89 real agentic tasks): 38.2% vs 36.0% resolved — a statistical tie ,yet NVFP4 holds 1.78× more KV.Honestly expected worse. What bit-width is your KV cache in prod? 👇
2
2
15
2,116
Jetha Chan retweeted
Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
169
810
5,025
921,734
Jetha Chan retweeted

Jun 9
A Japanese TV crew filmed the CEO of a 7 billion yen fast food chain for a feature on Japan's humble corporate culture. His head office in Shinagawa had 3 desks and cost 103,000 yen a month in rent. The office was that small because a Claude agent did the procurement, pricing, and contract work that normally fills three floors.
The crew showed the office. Two desks. One printer. Three employees. A rice cooker in the corner. The TV banner introduced him as the entrepreneur whose chain of snack shops sources rice directly from 312 farmers across Japan.
At 0:43 he says the word fleet. He says it once. He says it without looking at the camera. The crew kept the line because they thought he meant his delivery vans.
He did not mean delivery vans. He meant the fleet of Claude agents that runs every part of his company that does not require a human signature. The two desks at headquarters are for him and the CFO. The third employee is there to answer the phone.
One agent reads daily yield data from 312 rice farmers and sets the next morning's wholesale price for each variety. A second agent routes 47 stores worth of inventory based on the previous day's POS data. A third agent drafts every franchise contract and every supplier renewal. He signs every morning before the office opens. Japanese commercial law is satisfied.
Someone pulled the company's filings on the Tokyo commercial registry. Every contract filed in the last 14 months had been timestamped between 5:47 AM and 6:03 AM. Every supplier renewal used the same boilerplate clauses, written in slightly different prose each time. The morning shots in the TV segment showed an empty office because the agent had already done the work of 40 employees overnight.
Six months ago a 14 year old in Shenzhen pushed an AI agent to GitHub. Judges said no real world application. 3,100 forks later. The CEO had been one of them.
He still flies to rice paddies every spring. He still personally tastes every new variety before it gets a code in the system. He still tells investors the head office rent is 103,000 yen because it builds trust. He still has not told the farmers that the agent decided who got the new orders last quarter.
The TV crew thought the rundown head office was a story about a humble entrepreneur. It was actually a story about how many employees a 7 billion yen company does not need when one CEO signs what one Claude agent writes.
16
94
610
140,457

new policy from anthropic: if you use fable/mythos, they collect your data.
no exceptions. not even for enterprise partners.


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
126
435
4,353
684,170
Jetha Chan retweeted

Jun 9
Claude Fable 5 is now supported for use in Hermes Agent via Nous Portal!
The first 500 new users get one month free access to the Plus plan to try out Fable. Code in video:
182
118
2,127
321,071
Jetha Chan retweeted

Jun 8
That’s enough LinkedIn for today
95
2,107
24,457
773,797
Jun 9
out here trying to avoid building a new AI machine and y'all are coming with *this* energy

The RTX 6000 Pro has absolutely spoiled me.
2500 TPS isn't normal? TTFT actually matters?
I'm trying to use other hardware for a real time application and it's brutal.. 1.7s to get a 200-token response? Ouch.
1
112

new shai hulud wave. interestingly it has this inside the payload to trigger safety refusals in potential defensive scans.

Jun 8

We are now tracking 471 affected artifacts across npm and PyPI in the Mini Shai-Hulud/Miasma/Hades campaign.
The newer PyPI artifacts from this wave have been added to the dedicated campaign tracker.
Full breakdown:
socket.dev/blog/mini-shai-hu…
15
64
425
121,805
Jetha Chan retweeted

🚨 Big news: switching the KV cache from FP8 → NVFP4barely dents accuracy.
Verified on Terminal-Bench 2.0 (89 real agentic tasks): 38.2% vs 36.0% resolved — a statistical tie ,yet NVFP4 holds 1.78× more KV.Honestly expected worse. What bit-width is your KV cache in prod? 👇
11
8
107
16,979
Jetha Chan retweeted

May 24
Don’t know where to start with Local AI?
Read my Local LLMs From Zero to Hero series
It covers:
- Hardware
- Software
- Models Mechanics
- Everything else necessary
Needs no prior experience
Easy to understand for any background
Local / Opensource AI FTW
May 24

You should buy an RTX 3090 and learn how to run models locally
The elite don’t want you to know this but running local models is hella easy, performant, and cheap nowadays
23
63
563
91,379

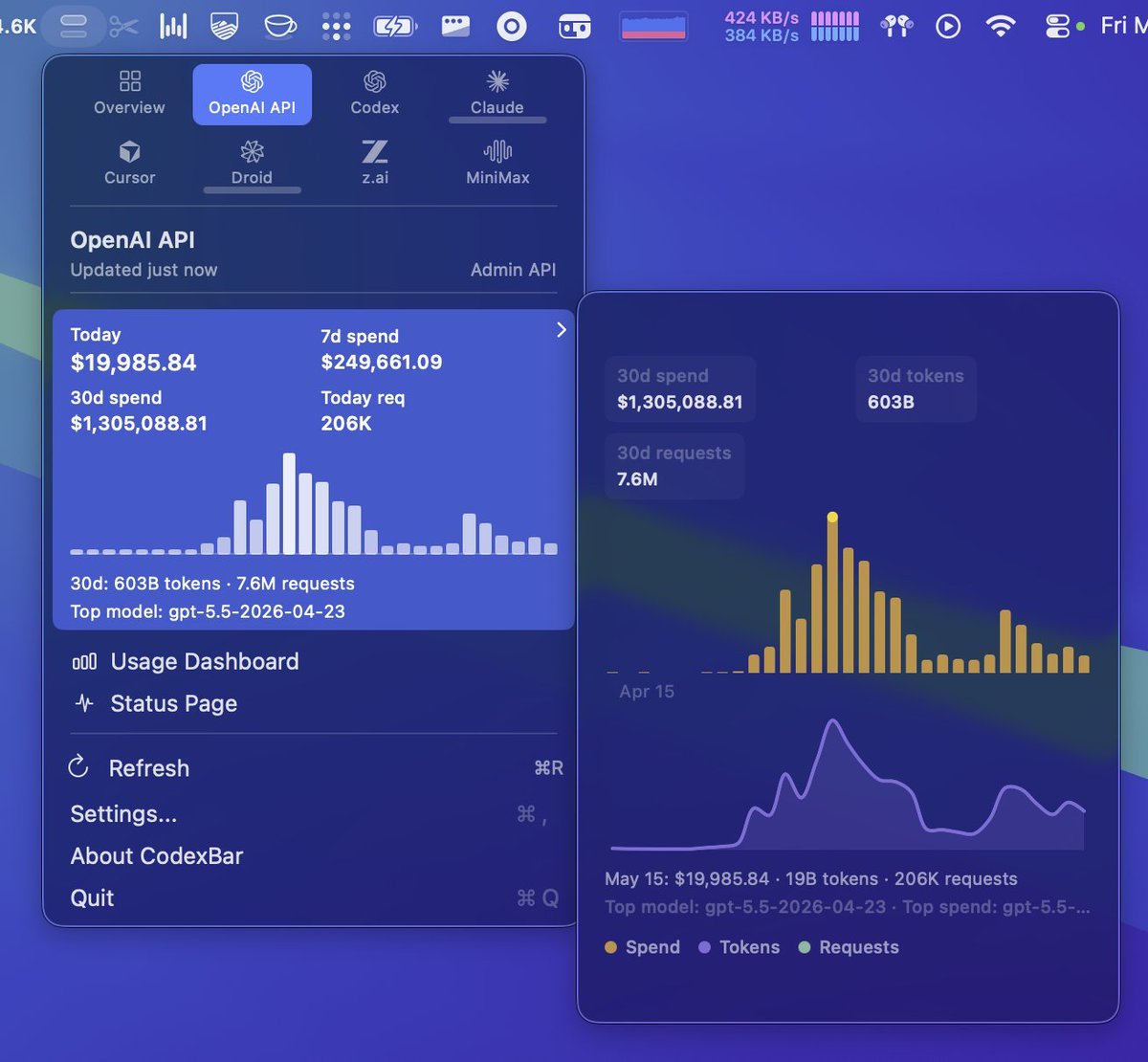
these loop takes from both Anthropic and OpenAI are extremely detached from reality
sure if I had $19k/day to spend on tokens I'd also run 100 loops permanently
only loops us AI poor can run locally are cli-based, deterministic loops with little to no token cost
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
36
8
81
8,554
Jun 8
Hall’s per-capita point on long-term trends is valid. But recent cases show organized foreign groups are involved with car theft, and it is a problem.
For example:
japantimes.co.jp/news/2026/0…
To steelman the government's position, even one foreign criminal is one Japan didn’t have to import — a net addition to domestic crime levels.
Jun 8

Japan's foreign population has doubled since 2003. In the same period, the number of car thefts dramatically declined.
For some reason, Japan's ruling party shared a video implying that foreigners stealing cars is a major issue.


140