
11 Dec 2025
Day 3 at #ItaLean2025 here in Bologna!
Great talks this morning and now the project work session is buzzing: so many new ideas everywhere and exciting collaborative projects taking shape.
What a fantastic atmosphere!
#LeanLang #FormalMath #AI4Math


10 Oct 2025

We’re pleased to announce #ItaLean2025: Bridging Formal Mathematics and AI, an international conference dedicated to @LeanProver, Formal Mathematics, and AI4Math.
📍 University of Bologna
🗓 9–12 December 2025
Proudly supported by @HarmonicMath.
#LeanLang #FormalMath #AI4Math

7
35
5,398

20 Oct 2025
FormalMath (Lean) might be the right ground of verified skills, mathlib gives the knowledge, tactics give the moves. @Yong18850571
3
336

11 Oct 2025
Thrilled to see #ItaLean2025 officially announced! It’s been great working with such an amazing team to make this happen. Applications are now open, join us in Bologna this December! #LeanLang #AI4Math #FormalMath
10 Oct 2025
We’re pleased to announce #ItaLean2025: Bridging Formal Mathematics and AI, an international conference dedicated to @LeanProver, Formal Mathematics, and AI4Math.
📍 University of Bologna
🗓 9–12 December 2025
Proudly supported by @HarmonicMath.
#LeanLang #FormalMath #AI4Math
2
366
10 Oct 2025
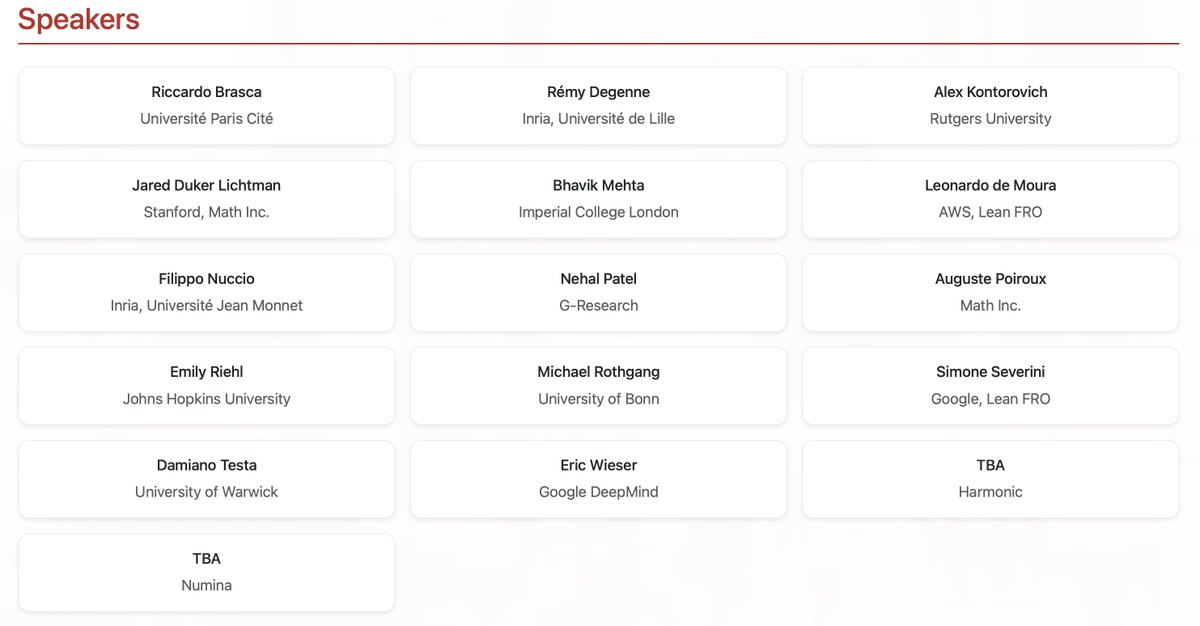
We’re honoured to host an exceptional lineup of speakers representing both academia and industry, working at the cutting edge of #FormalMath and #AI4Math.
@RiccardoBrasca @AlexKontorovich @jdlichtman @augpoi @emilyriehl @EricWieser and others not on @X.
1
3
14
1,022
10 Oct 2025
We’re pleased to announce #ItaLean2025: Bridging Formal Mathematics and AI, an international conference dedicated to @LeanProver, Formal Mathematics, and AI4Math.
📍 University of Bologna
🗓 9–12 December 2025
Proudly supported by @HarmonicMath.
#LeanLang #FormalMath #AI4Math
2
19
87
24,580

23 Sep 2025
Appreciated two insightful talks at #HLF25 last week: Sanjeev Arora on "superhuman AI mathematicians" using #LeanLang for theorem generation and proof verification, and David Silver on AI learning through experience, supported by a #LeanProver verification backbone.
🔗youtube.com/watch?v=q9MJWfo3…
#AI #FormalMath #ReinforcementLearning
4
41
2,861

3 Sep 2025
Congratulations to our contributors @BaksysMantas and Jonas Bayer for their participation in the AITP 2025 conference! 💪🚀
During their talk they deep dived into the capabilities of our Kimina prover, which uses a Chain of (Formal) Thought reasoning pattern, allowing it to generate complex, human-like proofs and achieve an 92.2% pass rate on the miniF2F benchmark. 👀
We believe in open scientific collaboration. By open-sourcing our models and datasets, we aim to accelerate progress and build tools that bridge the gap between human intuition and formal verification.
👉 links in the comments
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience #Lean4 #LeanLang

3
1
15
583

StepFun-Formalizer: Unlocking the Autoformalization Potential of LLMs through Knowledge-Reasoning Fusion
ThinkingF pipeline
- Formal knowledge distillation: 183K Lean4-aligned pairs via majority voting BEq filtering
- Template-guided reasoning: 5.8K trajectories (Claude 3.7)
- Training: 2-stage SFT (formal <think> reasoning) RLVR (BEq-based reward, GRPO DAPO)
- Backbone: DeepSeek-R1-Distill-Qwen (7B / 32B)
Data sourcing
Source: 256K NL math problems (NuminaMath-1.5)
- Kimina-Autoformalizer generates 16 formalizations per prompt
- Filtered via syntax check → BEq clustering → majority vote → DeepSeek-V3 validation → 183K pairs
Benchmarks
Main Results (BEq@1)
FormalMATH-Lite (in-domain)
- Kimina-7B: 35.1
- StepFun-7B: 38.3
- StepFun-32B: 40.5
ProverBench (OOD)
- Kimina-7B: 13.3
- StepFun-7B: 25.1
- StepFun-32B: 26.7
CombiBench (real-world)
- Kimina-7B: 2.6
- StepFun-7B: 5.2
- StepFun-32B: 6.9
Ablation (ProverBench BEq@16)
- Full pipeline: 37.9
- w/o reasoning: 25.3
- w/o knowledge: 37.4
End-to-End Theorem Proving (10K informal problems)
- StepFun-7B: 4940 provable
- Kimina-7B: 4549 provable
StepFun-Formalizer surpasses both general and specialized models, scales to OOD, and improves real-world verifiability.

2
1
21
1,718

7 Aug 2025
StepFun-Formalizer
Introduces a data synthesis and training pipeline that improves comprehensive mastery of formal-language domain knowledge and reasoning capability of natural language problem understanding and informal-formal alignment. Achieves SOTA BEq@1 scores of 40.5 % on FormalMATH-Lite and 26.7 % on ProverBench.
Links below

1
5
40
4,424
31 Jul 2025
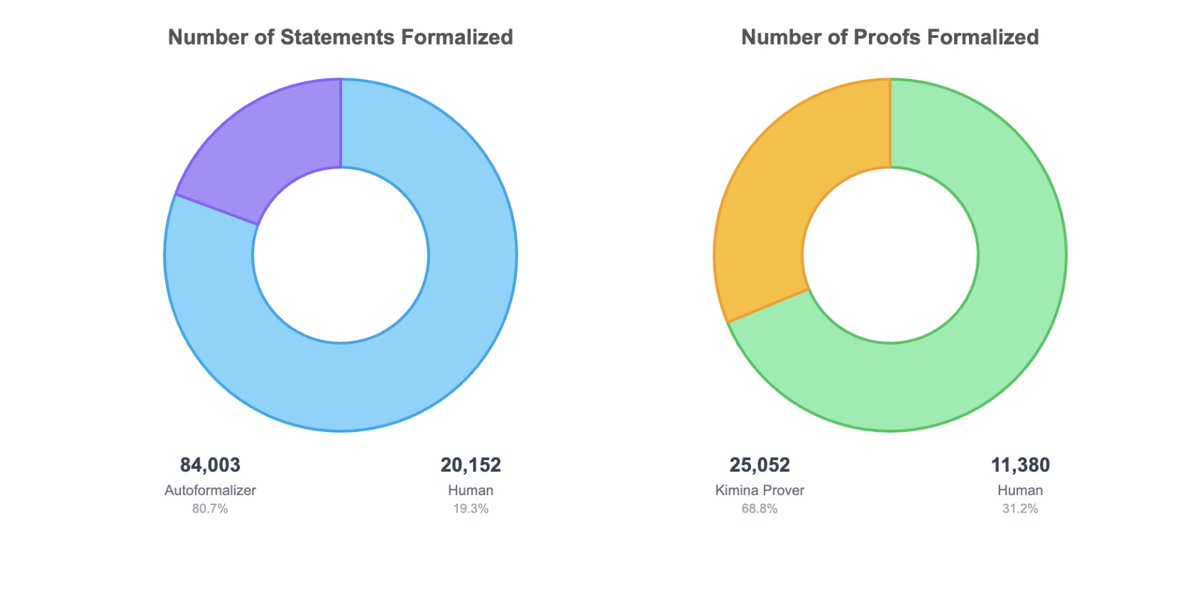
We are proud to be Releasing NuminaMath-LEAN, a large-scale dataset of 100K mathematical competition problems formalized in Lean 4, with more than 20K human annotations.
Paired with Kimina-Prover, Kimina-autoformalizer, CombiBench, we hope these data and models will advance open-source AI for formal mathematics !
This year's IMO was bittersweet for Numina as our theorem prover did not solve any problem, we believed we were very close.
Numina is starting a new chapter after IMO 2025. While we will still continue to build SOTA open source theorem prover for high school problems, we would also like to branch out and explore undergraduate level math or even research level, open mathematical problems.
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience #Lean4 #LeanLang
1
15
88
6,428
15 Jul 2025
The first volume of the new Open Access journal "Annals of Formalized Mathematics" was released today!
➡️afm.episciences.org/volume/v…
#FormalMath #Mathematics #OpenAccess
1
24
107
5,272
15 Jul 2025
#IMO2025 has begun a few hours ago, wishing a great Olympiad to all the students! We're eager to see how the different AIs perform, including ours 💪🔥
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience #Lean4 #LeanLang

1
20
1,255
11 Jul 2025
One year ago, our small but mighty model NuminaMath-7B-TIR won the first progress prize of the AI Math Olympiad 🥇 We have come a long way since and we're exited for what comes next 🙌
If you don't know us yet, check out the link in the comments for the full blog post about Team Numina and the technical details behind our winning solution
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience #Lean4 #LeanLang

1
5
590
10 Jul 2025
New milestone for Project Numina and Kimi Moonshot! 🚀 We are open sourcing our KiminaProver-72B. This SotA theorem-proving model comes with Test-Time Reinforcement Learning Search and Error-Fixing Capability. We’re putting it to the test soon, with the IMO just around the corner 👀
Check it out👉 huggingface.co/collections/A…
Read the blog post huggingface.co/blog/AI-MO/ki…
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience #Lean4 #LeanLang

1
11
44
10,148
8 Jul 2025
This April, we released Kimina-Prover Preview. Stay tuned! Full release is coming soon 🚀
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience
14 Apr 2025

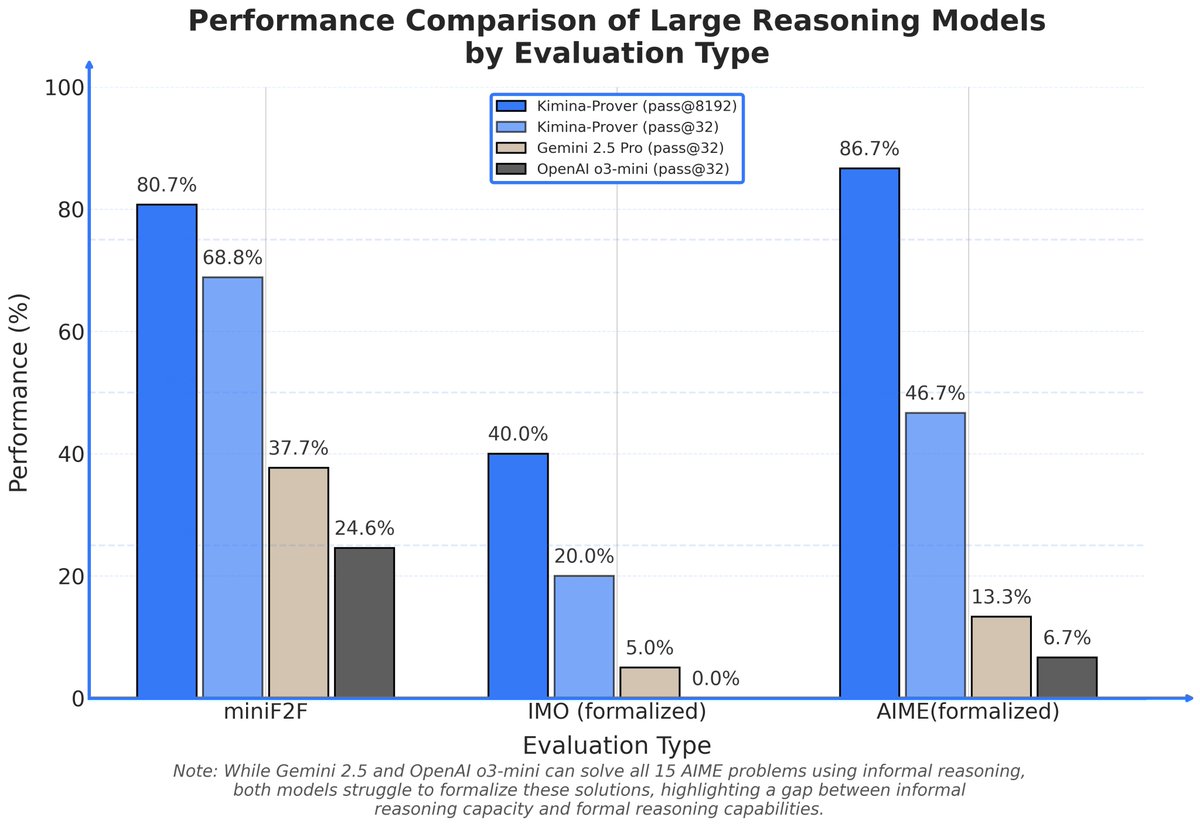
We believe formal math is the future.
🔥Introducing Kimina-Prover Preview, a Numina &
@Kimi_Moonshot collaboration, the first large formal reasoning model for Lean 4, achieving 80.78% miniF2F.
github.com/MoonshotAI/Kimina…
4
8
1,858
7 Jul 2025
Hello World! 👋 We're thrilled to officially launch the X account for Numina, dedicated to advancing frontier AI in mathematics. Stay tuned for updates on our research, achievements, and the future of mathematical AI!
#AI4Math #FormalMath #LeanProver #AutomatedReasoning #TheoremProving #ProofAssistant #MachineLearning #AIResearch #OpenScience

10
28
3,807
2 Jun 2025
This talk by @yannfleureau is a great introduction to Project Numina and their open-source dataset of mathematics problems and solutions. We look forward to the results from IMO 2025!
➡️ Watch the video here: youtube.com/watch?v=mSbf7IoI…
#AI #Mathematics #OpenSource #FormalMath #LeanLang
18
86
6,059

1 Jun 2025
Explore the FormalMATH project for more interesting details:
spherelab.ai/FormalMATH/
5
371
1 Jun 2025
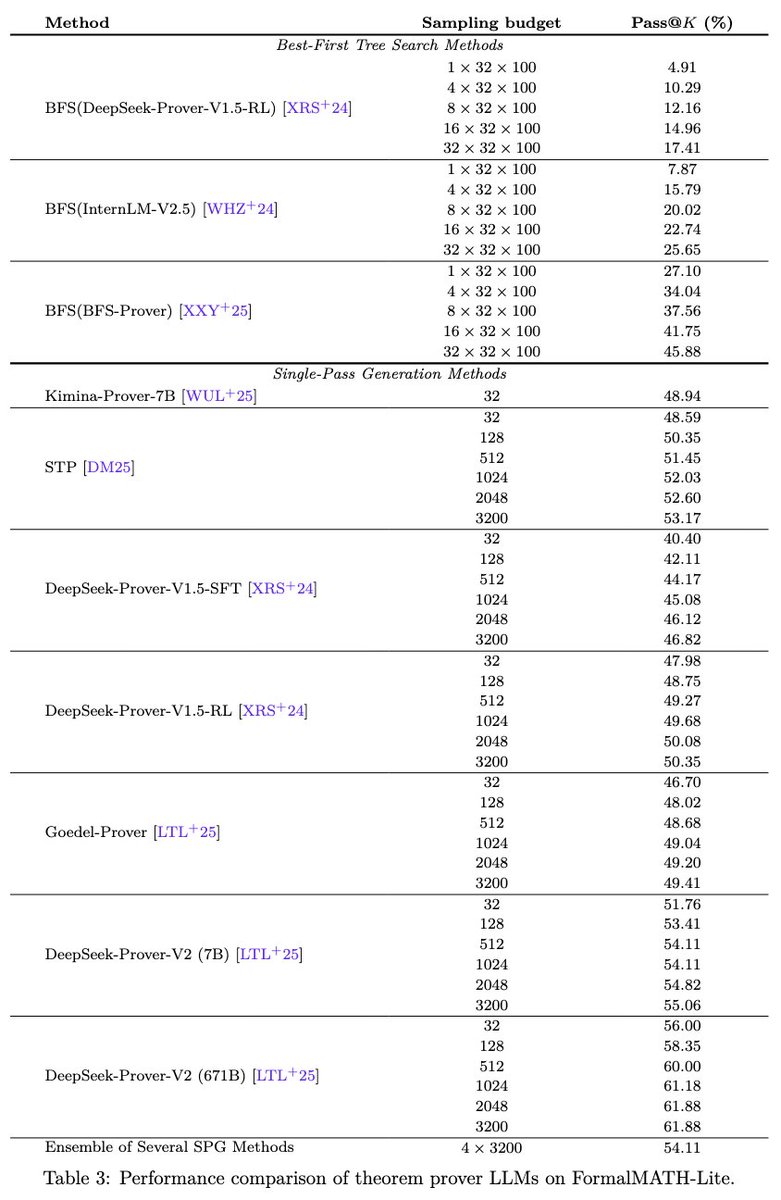
However, even with its SOTA performance, there’s still significant room for improvement. Test-time scaling experiments show modest gains ( 3.30% for the 7B and 5.88% for the 671B) from Pass@32 to Pass@3200 on FormalMATH-Lite.
1
5
603
1 Jun 2025
🤔We tested the largest and most powerful open-source theorem prover, DeepSeek-Prover-V2, on the FormalMATH benchmark(
arxiv.org/pdf/2505.02735
) and found it significantly outperformed all other provers. The 671B model scored 28.31, and the 7B model's 22.41 via Pass@32.

2
15
135
20,293