
Joined January 2020
- Tweets 83
- Following 223
- Followers 98
- Likes 394
15 Photos and videos



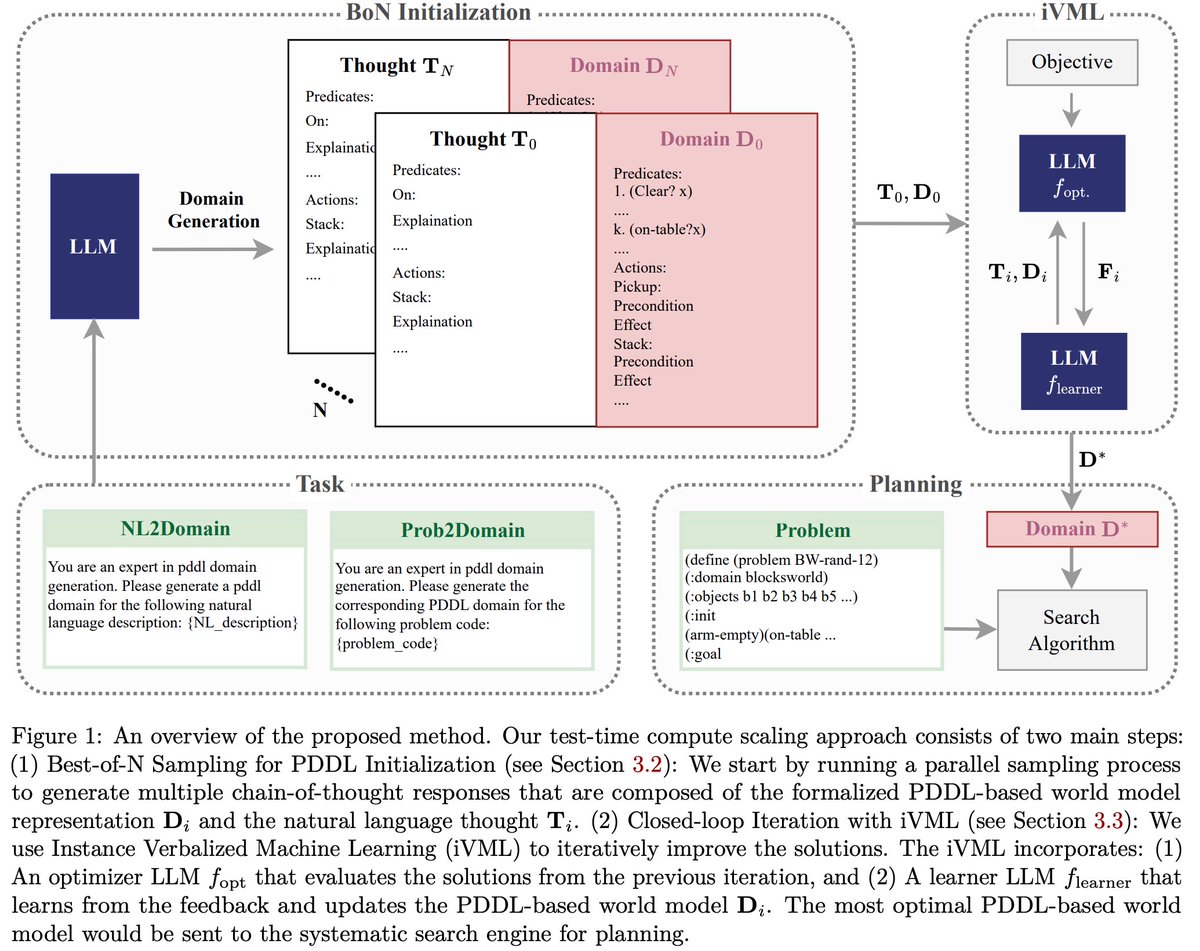

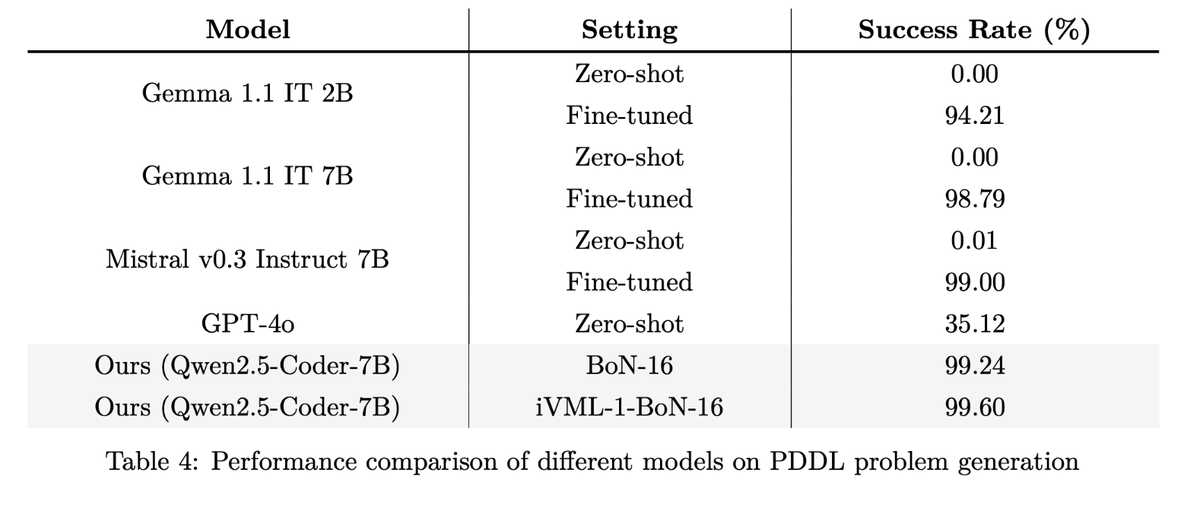
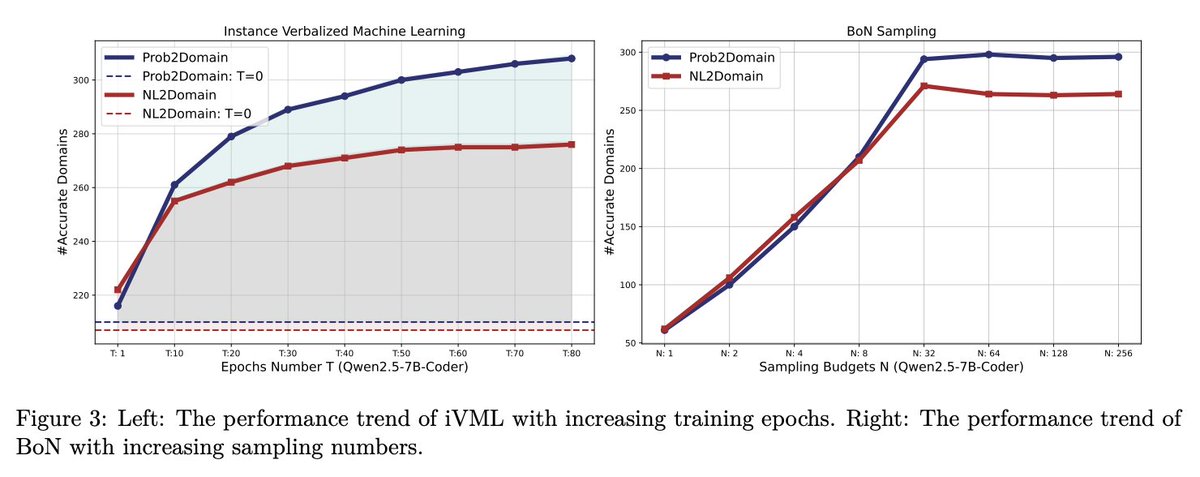
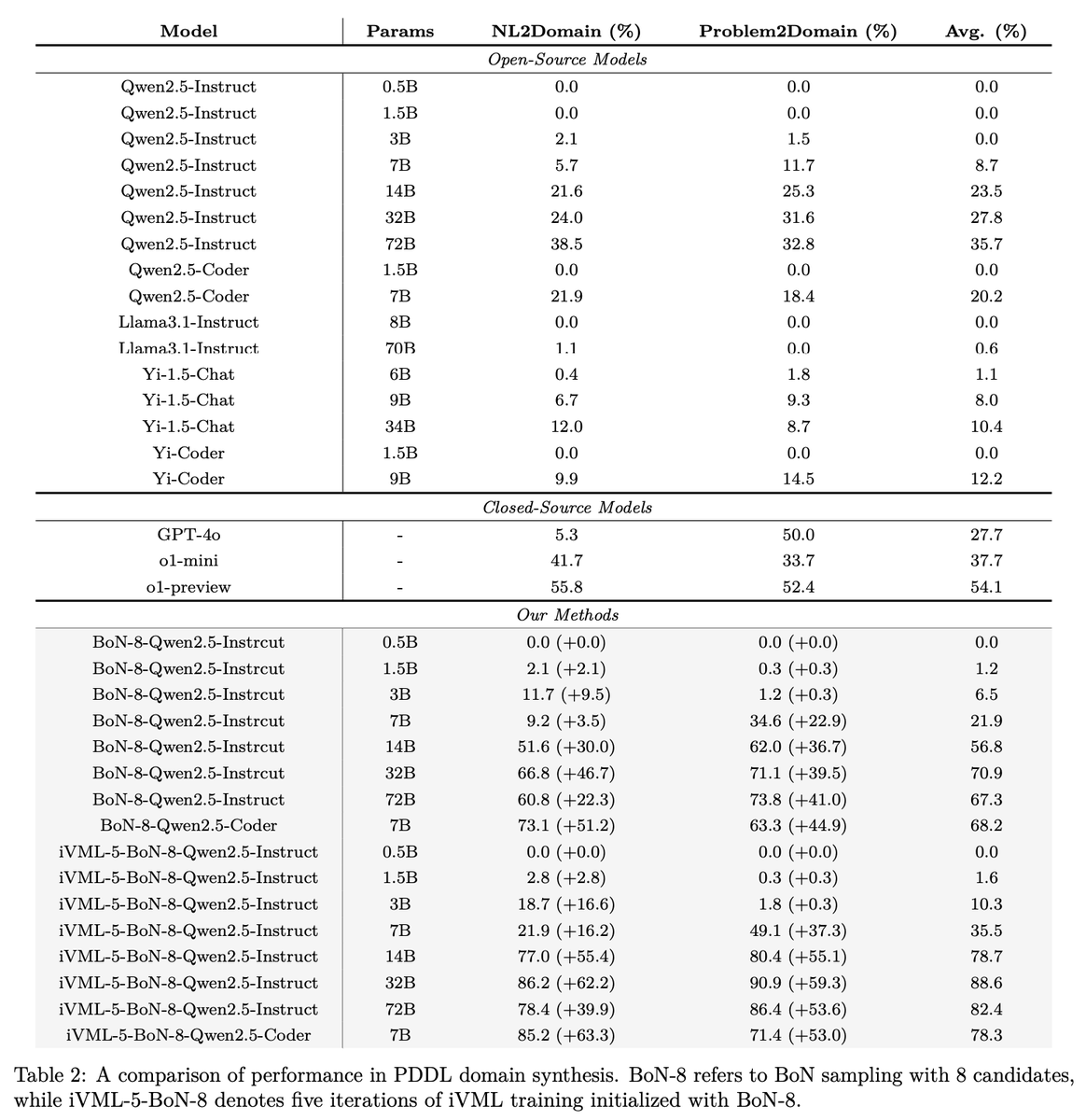

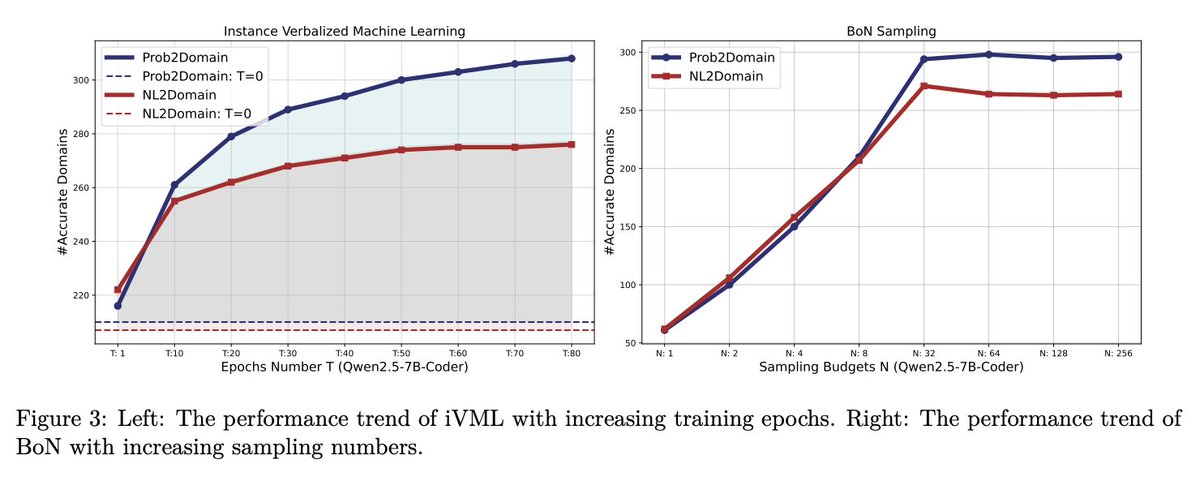
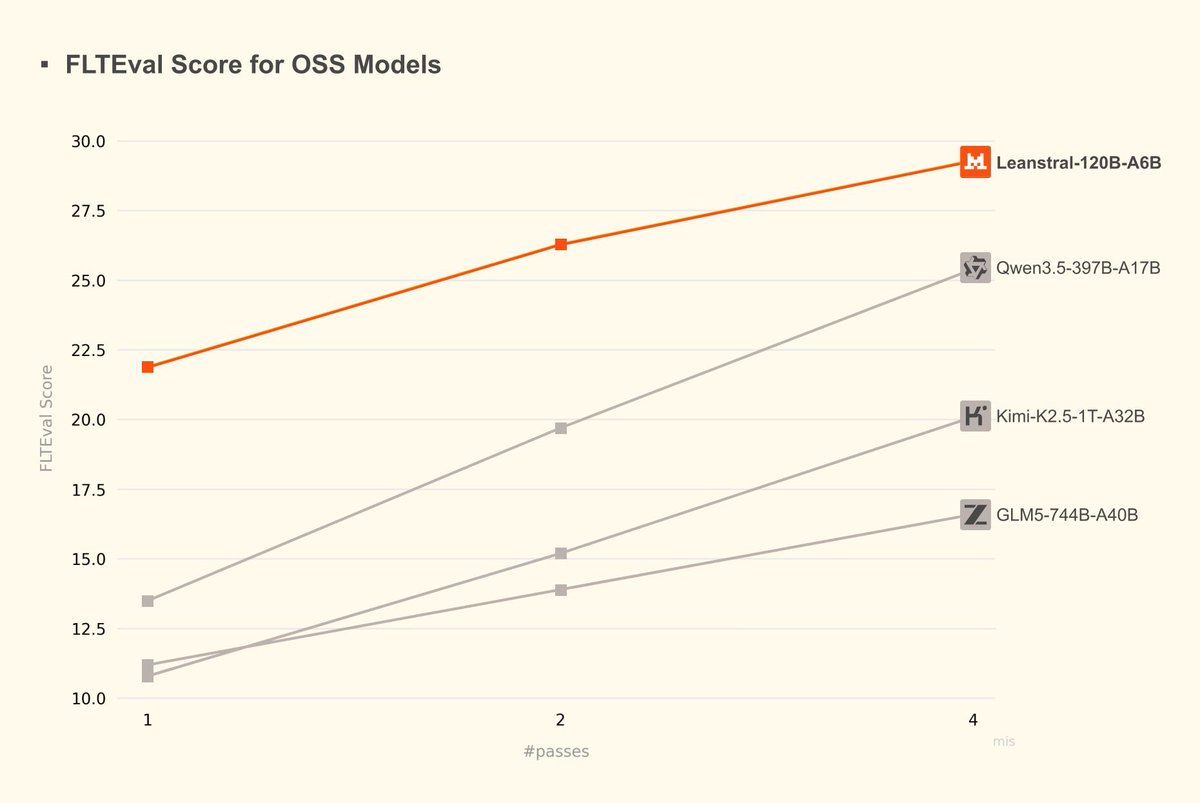
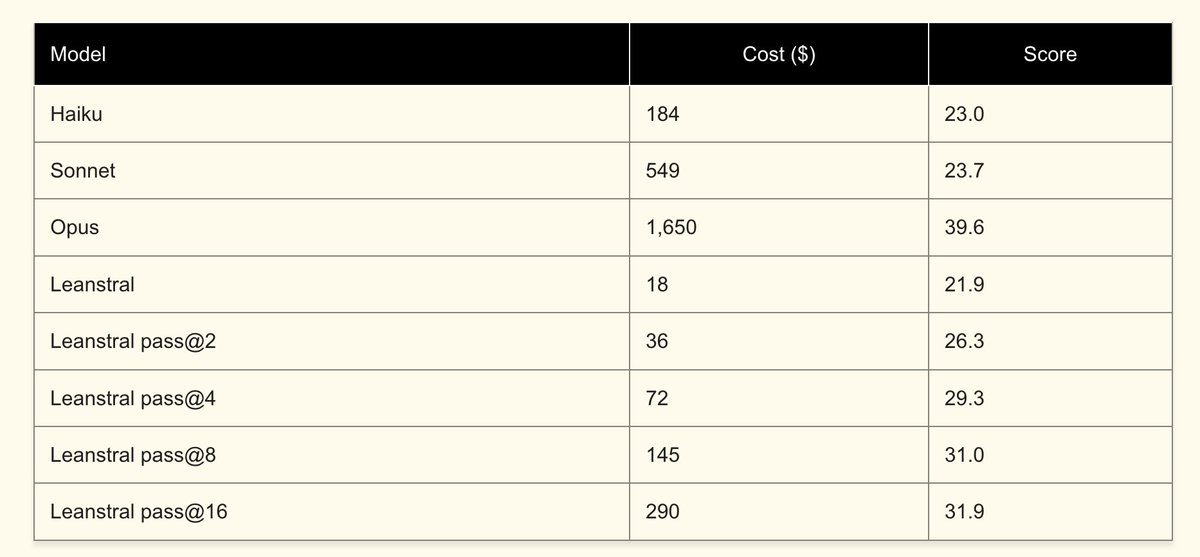
Zhouliang Yu retweeted

Mar 16
mistral.ai/news/leanstral
Excited to share what the formal team @MistralAI has been building for the last couple of months: an Apache 2 Lean code agent with 6B active parameters. Outperforms open models like Qwen3.5, GLM5, Kimi-K2.5, and very competitive against Claude 4.6.
Use for free in Mistral-Vibe:
```
$ uv tool install mistral-vibe --upgrade
$ vibe
/ leanstall
```
enjoy the lean mode via shift tab!
22
57
521
41,249
Zhouliang Yu retweeted

Feb 25
We released Goedel-Prover-V2, a state-of-the-art model for formal theorem proving at launch. Remarkably, it has remained at the top of the open-source formal theorem proving leaderboard for over six months.
We have been excited to see so many folks cooking with our models.
Today, we are open-sourcing the full Goedel-Prover-V2 training datasets for the community:
📂 SFT (1.74M samples)
huggingface.co/datasets/Goed…
📂 RL (whole proof generation self-revision, 98k samples)
huggingface.co/datasets/Goed…
We hope this helps push formal theorem proving forward. Build on it!
Amazing Collaborators: @Yong18850571 @sangertang1999 @Lyubh22 @juihuichung @thomaszhao1998 @_LaiJiang @thiiis_user @EmilyJge @JingruoS5931 @wujiayun12 @GesiJiri68334 @davidjesusacu @KaiyuYang4 @hongzhou__lin @YejinChoinka @danqi_chen @prfsanjeevarora @chijinML
3
39
200
29,359
Zhouliang Yu retweeted

AIxMath is going through some extremely confused chatter at the moment. Everyone agree on the facts, yet the interpretation oscillates between "I have never seen an AI have a brilliant idea & it probably will never happen" and "math is so over, look at this algebraic geometry conjecture that got resolved!". As often in life, neither of these caricatures capture what is really going. I did my best attempt at describing the arc of progress in my recent talk. It's long form (45 minutes) but I think that's what is needed to get a grounded and contextualized view of today's SOTA.
If I'm forced to give a tl;dr it would be: 1 year ago AI could at best save me an hour of work in mathematics (at best), while today IF I ASK THE RIGHT LEVEL QUESTION it can do work that would have taken me days, sometimes (though rarely!) even weeks. And there is no reason that this progress won't continue at roughly the same rate.
youtu.be/MH3lG7V7SuU?si=Poar…
18
60
433
113,077
Zhouliang Yu retweeted

Jan 27
prompt optimization context distillation are underexplored primitives for post-training pipelines imo
13
15
287
13,611
Zhouliang Yu retweeted

Jan 27
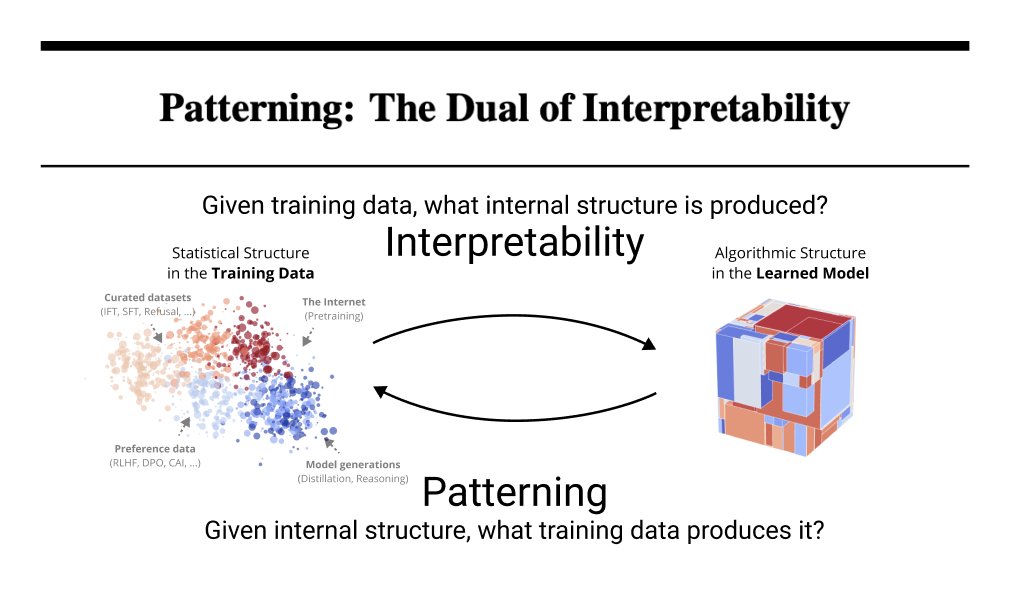
“Neural networks are grown, not programmed”
We’re changing that. Mechinterp investigates how models generalize beyond their training data by studying the resulting internal structure. We introduce patterning as the dual: given desired structure, determine what data produces it.
19
156
1,084
91,711
Zhouliang Yu retweeted

1 Oct 2025
🚀Ever wondered how to make RL work on impossible hard tasks where pass@k = 0%? 🤔
In our new work, we share the RL Grokking Recipe: a training recipe that enables LLMs to solve previously unsolvable coding problems! I will be at #CoLM2025 next week so happy to chat about it!
We also dive into the heated debate: does RL just sharpen previous learnt skills or can it unlock genuinely new reasoning? 🔥🔥
Read the full blog here: tinyurl.com/ntarc3kw
#AI #RL #NLP #reinforcementlearning #llm

26
184
1,233
153,979
Zhouliang Yu retweeted

Jan 7
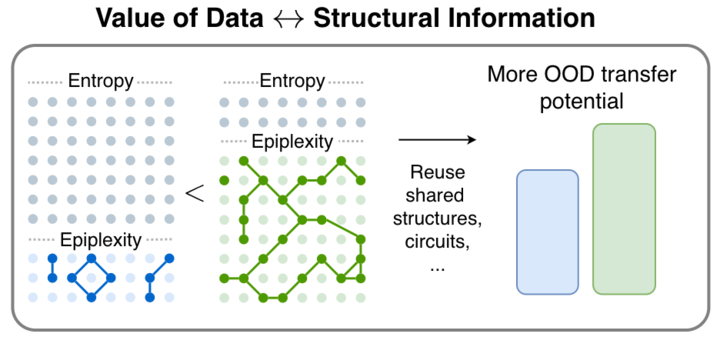
1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
arxiv.org/abs/2601.03220
with amazing team @ShikaiQiu @yidingjiang @Pavel_Izmailov @zicokolter @andrewgwils
56
393
2,345
1,068,230
Zhouliang Yu retweeted

30 Dec 2025
I’m launching Tutorial II for Physics of Language Models.
Many people focus on large-scale results.
This tutorial is about why those results are often artifacts of noise — and how to eliminate that noise at the design level.
The first video (Part 4.1a, 1 hour) is the most important one.
It focuses on methodology, not benchmarks:
– how real-life pretraining can be “cheated”,
– why academic-scale experiments are noisy,
– and most importantly, how to design a versatile, skill-pure synthetic pretraining playground.
I explain why our five synthetic tasks are designed the way they are, and how GPT2-small-scale (100M) models can reveal architectural truths that 8B models trained on 1T tokens often fail to expose reliably.
This methodology is the backbone of the entire Physics series.
▶️ First video: Part 4.1a — methodology & playground design
🔜 Second video: Part 4.1b — architectural principles from the playground
🔜 Third video: Part 4.2 — when the playground reshapes real-life pretraining
(You can find it via my profile.)

14
166
1,263
128,836
Zhouliang Yu retweeted

17 Oct 2025
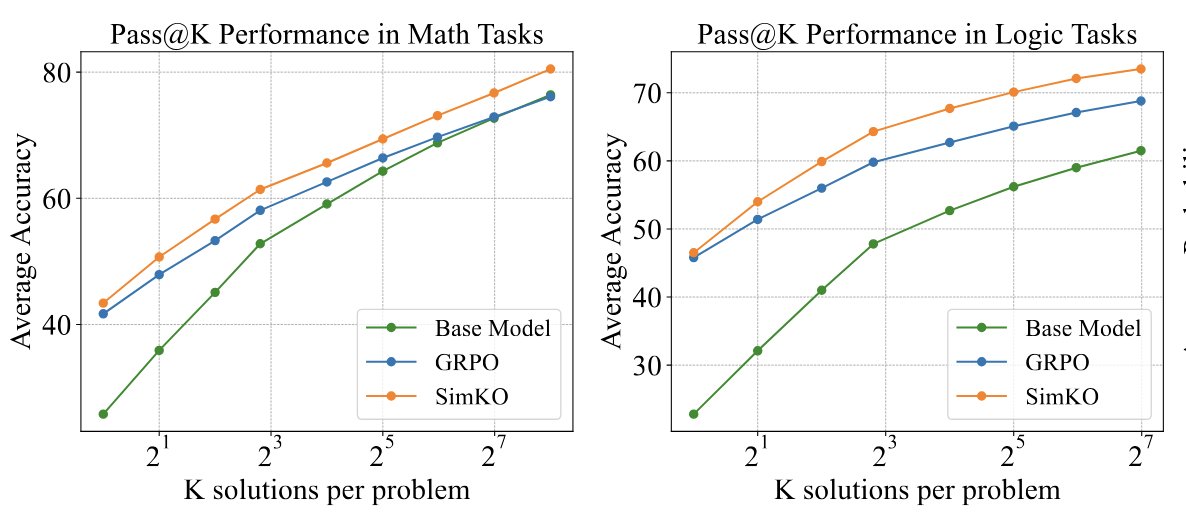
🚀 Excited to share our new paper: "SimKO: Simple Pass@K Policy Optimization"!
SimKO is a new algorithm for effectively boosts pass@K performance on math & logic tasks without sacrificing pass@1.
spherelab.ai/simko
(1/n)
6
5
10
797
Zhouliang Yu retweeted

17 Oct 2025
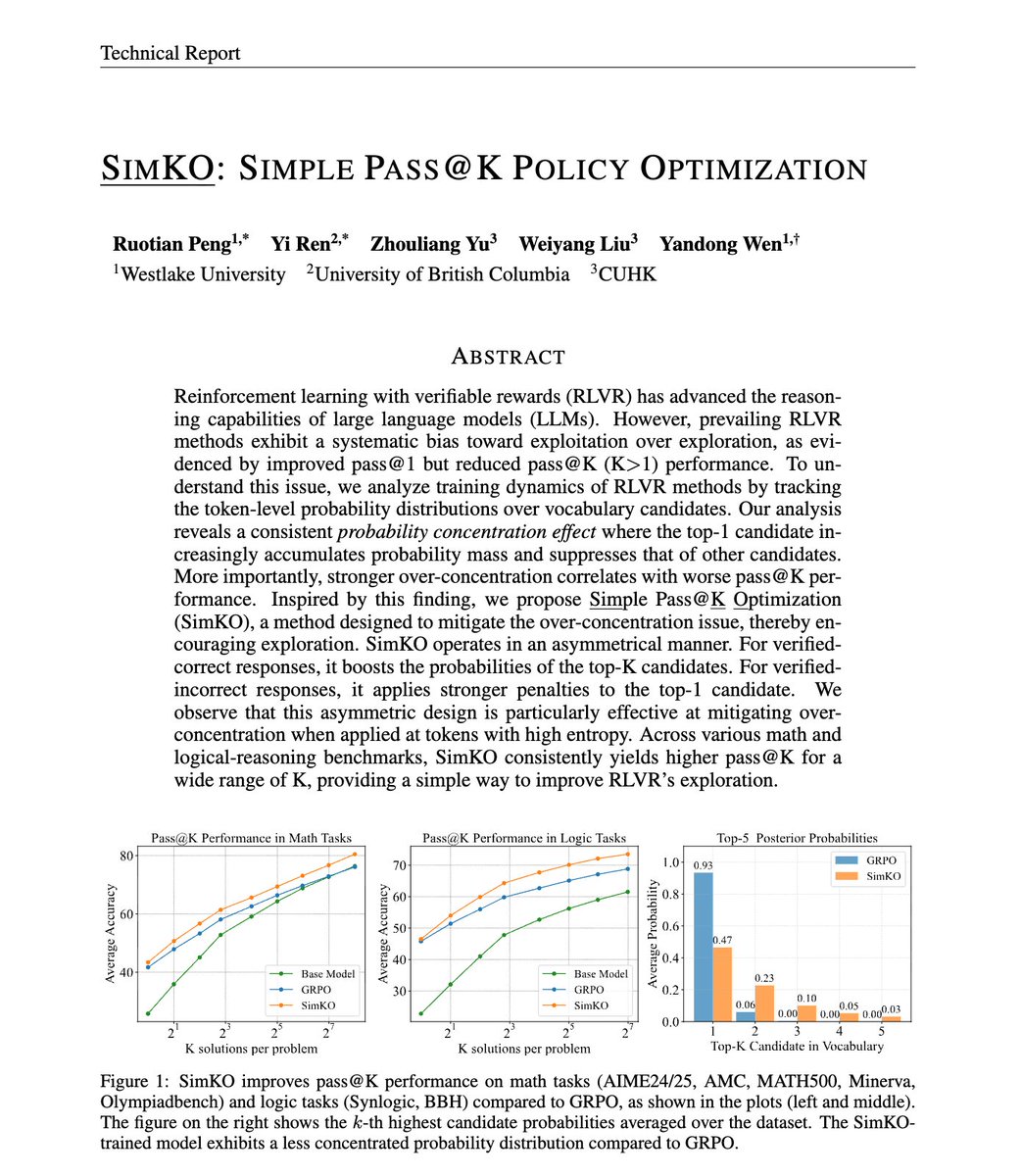
🚀 Glad to introduce SimKO (Simple Pass@K Optimization)
Current GRPO-based methods overfit to safe responses -- great Pass@1, poor Pass@K.
🔍 We find this stems from probability over-concentration: the model collapses onto its top-1 token, losing exploration. This appears to be a more accurate observation metric than commonly used entropy.
✨ SimKO fixes this with probability redistribution:
✅ Encoruage top-K candidates for high-entropy tokens in correct responses
❌ Penalize over-confident top-1s for incorrect responses
🧮 Improves Pass@K across math & logic benchmarks -- simple, stable, effective.
📄 Paper: arxiv.org/abs/2510.14807v1
🌐 Project: spherelab.ai/simko
#LLM #ReinforcementLearning #Reasoning #RLVR #AI
5
21
158
10,515
Zhouliang Yu retweeted

6 Oct 2025
Code World Model is necessary but not sufficient to do grounded planning. Simple take: pretrain like you'll posttrain (agentic coding). Bright future (research) take: neural concrete interpretation will converge to neural abstract interpretation.
1
2
20
1,693

Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for full-parameter fine-tuning using Evolution Strategies (ES).
By skipping gradients and optimizing directly in parameter space, ES achieves more accurate, efficient, and stable fine-tuning.
Paper: arxiv.org/pdf/2509.24372
Code: github.com/VsonicV/es-fine-t…
90
383
2,607
414,913
Zhouliang Yu retweeted

1 Oct 2025
Finally had a chance to listen through this pod with Sutton, which was interesting and amusing.
As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea is sufficiently "bitter lesson pilled" (meaning arranged so that it benefits from added computation for free) as a proxy for whether it's going to work or worth even pursuing. The underlying assumption being that LLMs are of course highly "bitter lesson pilled" indeed, just look at LLM scaling laws where if you put compute on the x-axis, number go up and to the right. So it's amusing to see that Sutton, the author of the post, is not so sure that LLMs are "bitter lesson pilled" at all. They are trained on giant datasets of fundamentally human data, which is both 1) human generated and 2) finite. What do you do when you run out? How do you prevent a human bias? So there you have it, bitter lesson pilled LLM researchers taken down by the author of the bitter lesson - rough!
In some sense, Dwarkesh (who represents the LLM researchers viewpoint in the pod) and Sutton are slightly speaking past each other because Sutton has a very different architecture in mind and LLMs break a lot of its principles. He calls himself a "classicist" and evokes the original concept of Alan Turing of building a "child machine" - a system capable of learning through experience by dynamically interacting with the world. There's no giant pretraining stage of imitating internet webpages. There's also no supervised finetuning, which he points out is absent in the animal kingdom (it's a subtle point but Sutton is right in the strong sense: animals may of course observe demonstrations, but their actions are not directly forced/"teleoperated" by other animals). Another important note he makes is that even if you just treat pretraining as an initialization of a prior before you finetune with reinforcement learning, Sutton sees the approach as tainted with human bias and fundamentally off course, a bit like when AlphaZero (which has never seen human games of Go) beats AlphaGo (which initializes from them). In Sutton's world view, all there is is an interaction with a world via reinforcement learning, where the reward functions are partially environment specific, but also intrinsically motivated, e.g. "fun", "curiosity", and related to the quality of the prediction in your world model. And the agent is always learning at test time by default, it's not trained once and then deployed thereafter. Overall, Sutton is a lot more interested in what we have common with the animal kingdom instead of what differentiates us. "If we understood a squirrel, we'd be almost done".
As for my take...
First, I should say that I think Sutton was a great guest for the pod and I like that the AI field maintains entropy of thought and that not everyone is exploiting the next local iteration LLMs. AI has gone through too many discrete transitions of the dominant approach to lose that. And I also think that his criticism of LLMs as not bitter lesson pilled is not inadequate. Frontier LLMs are now highly complex artifacts with a lot of humanness involved at all the stages - the foundation (the pretraining data) is all human text, the finetuning data is human and curated, the reinforcement learning environment mixture is tuned by human engineers. We do not in fact have an actual, single, clean, actually bitter lesson pilled, "turn the crank" algorithm that you could unleash upon the world and see it learn automatically from experience alone.
Does such an algorithm even exist? Finding it would of course be a huge AI breakthrough. Two "example proofs" are commonly offered to argue that such a thing is possible. The first example is the success of AlphaZero learning to play Go completely from scratch with no human supervision whatsoever. But the game of Go is clearly such a simple, closed, environment that it's difficult to see the analogous formulation in the messiness of reality. I love Go, but algorithmically and categorically, it is essentially a harder version of tic tac toe. The second example is that of animals, like squirrels. And here, personally, I am also quite hesitant whether it's appropriate because animals arise by a very different computational process and via different constraints than what we have practically available to us in the industry. Animal brains are nowhere near the blank slate they appear to be at birth. First, a lot of what is commonly attributed to "learning" is imo a lot more "maturation". And second, even that which clearly is "learning" and not maturation is a lot more "finetuning" on top of something clearly powerful and preexisting. Example. A baby zebra is born and within a few dozen minutes it can run around the savannah and follow its mother. This is a highly complex sensory-motor task and there is no way in my mind that this is achieved from scratch, tabula rasa. The brains of animals and the billions of parameters within have a powerful initialization encoded in the ATCGs of their DNA, trained via the "outer loop" optimization in the course of evolution. If the baby zebra spasmed its muscles around at random as a reinforcement learning policy would have you do at initialization, it wouldn't get very far at all. Similarly, our AIs now also have neural networks with billions of parameters. These parameters need their own rich, high information density supervision signal. We are not going to re-run evolution. But we do have mountains of internet documents. Yes it is basically supervised learning that is ~absent in the animal kingdom. But it is a way to practically gather enough soft constraints over billions of parameters, to try to get to a point where you're not starting from scratch. TLDR: Pretraining is our crappy evolution. It is one candidate solution to the cold start problem, to be followed later by finetuning on tasks that look more correct, e.g. within the reinforcement learning framework, as state of the art frontier LLM labs now do pervasively.
I still think it is worth to be inspired by animals. I think there are multiple powerful ideas that LLM agents are algorithmically missing that can still be adapted from animal intelligence. And I still think the bitter lesson is correct, but I see it more as something platonic to pursue, not necessarily to reach, in our real world and practically speaking. And I say both of these with double digit percent uncertainty and cheer the work of those who disagree, especially those a lot more ambitious bitter lesson wise.
So that brings us to where we are. Stated plainly, today's frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity's documents with some sprinkle on top. They are not platonically bitter lesson pilled, but they are perhaps "practically" bitter lesson pilled, at least compared to a lot of what came before. It seems possibly to me that over time, we can further finetune our ghosts more and more in the direction of animals; That it's not so much a fundamental incompatibility but a matter of initialization in the intelligence space. But it's also quite possible that they diverge even further and end up permanently different, un-animal-like, but still incredibly helpful and properly world-altering. It's possible that ghosts:animals :: planes:birds.
Anyway, in summary, overall and actionably, I think this pod is solid "real talk" from Sutton to the frontier LLM researchers, who might be gear shifted a little too much in the exploit mode. Probably we are still not sufficiently bitter lesson pilled and there is a very good chance of more powerful ideas and paradigms, other than exhaustive benchbuilding and benchmaxxing. And animals might be a good source of inspiration. Intrinsic motivation, fun, curiosity, empowerment, multi-agent self-play, culture. Use your imagination.
26 Sep 2025

.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled.
My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning.
And if we have continual learning, we don't need a special training phase - the agent just learns on-the-fly - like all humans, and indeed, like all animals.
This new paradigm will render our current approach with LLMs obsolete.
I did my best to represent the view that LLMs will function as the foundation on which this experiential learning can happen. Some sparks flew.
0:00:00 – Are LLMs a dead-end?
0:13:51 – Do humans do imitation learning?
0:23:57 – The Era of Experience
0:34:25 – Current architectures generalize poorly out of distribution
0:42:17 – Surprises in the AI field
0:47:28 – Will The Bitter Lesson still apply after AGI?
0:54:35 – Succession to AI
416
1,237
9,500
1,963,376
Zhouliang Yu retweeted

4 Oct 2025
From Reasoning to Learning: A Survey on Hypothesis Discovery and Rule Learning with Large Languag...
Kaiyu He, Zhiyu Chen.
Action editor: Quanshi Zhang.
openreview.net/forum?id=d7W3…
#knowledge #deductive #reasoning
2
1
402
Zhouliang Yu retweeted

29 Sep 2025
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
thinkingmachines.ai/blog/lor…
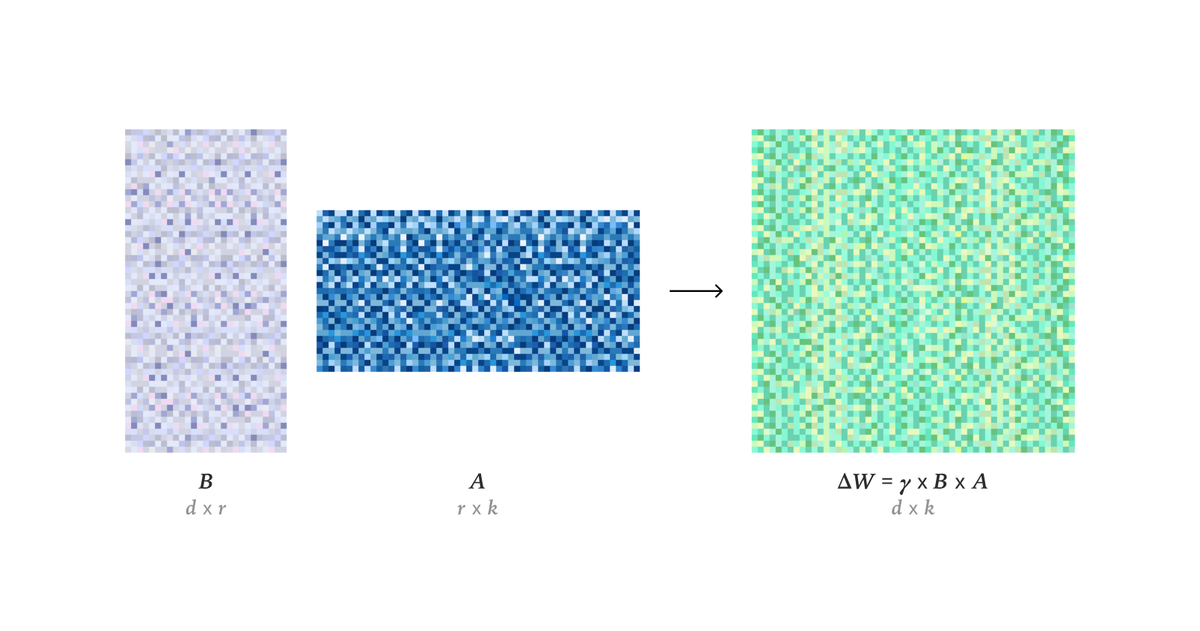
82
556
3,485
1,449,384
Zhouliang Yu retweeted

12 Sep 2025
This is a big deal. It is the first large-scale demonstration of the advantage of real-time reinforcement learning. The recipe is scalable and requires no intervention in principle; the model can adapt forever as long as it is being used.
There is no way to achieve similar results with sim-to-real learning because that would require simulating thousands of human users.
The feedback loop of 1.5 hours is still too long. It might be good enough for this use cases but many use cases would benefit from instant learning which requires new algorithms.
11 Sep 2025

We've trained a new Tab model that is now the default in Cursor.
This model makes 21% fewer suggestions than the previous model while having a 28% higher accept rate for the suggestions it makes.
Learn more about how we improved Tab with online RL.
7
18
307
56,529
Zhouliang Yu retweeted
10 Sep 2025
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
thinkingmachines.ai/blog/def…
230
1,244
7,610
3,489,784
Zhouliang Yu retweeted
8 Sep 2025
Agreed. I said in ICML'24 tutorial that hallucination probably doesn't deserve its name. To me, it's nothing but the fact that LLMs learn "format" much faster than other things; so it is encouraged (via pretrain data) to be English-correct even if it wasn't sure of the answer.
6 Sep 2025

The new OpenAI paper “Why Language Models Hallucinate” is more like PR than research.
The claim that hallucinations arise because training/evaluation reward guessing over abstaining is decades-old (reject option classifiers, selective prediction).
5
26
398
47,387
Zhouliang Yu retweeted
9 Sep 2025
We have been working on enabling LLMs to generate symbolic graphics programs since IG-LLM (ig-llm.is.tue.mpg.de/) and SGP-Bench (sgp-bench.github.io/), but SFT didn't really work at the time. We now find that, with a properly designed cross-modal reward (eg, CLIP), RLVR can work surprisingly well for generating symbolic graphics programs.
This direction excites us not only because symbolic graphics programs serve as an elegant, unified representation for LLMs to perform visual synthesis, but also because they offer a natural way to distill visual knowledge from a cross-modal reward model into LLMs.


7
16
1,860
Zhouliang Yu retweeted

3 Sep 2025
Dwarkesh Patel is 100% right on this: AI's utility is very strongly dependent on continual learning.
youtu.be/nyvmYnz6EAg?si=D2v2…
49
128
1,486
434,836