


Jun 12
Omg shoutout to Trefethen and Bau! Math 571 at Michigan (coursicle.com/umich/courses/…) killed me. Didn't realize it was relevant to optimizers...should have looked into this before getting too deep into GEMMs and Attention kernels :(
1
2
10
1,901

Jun 11
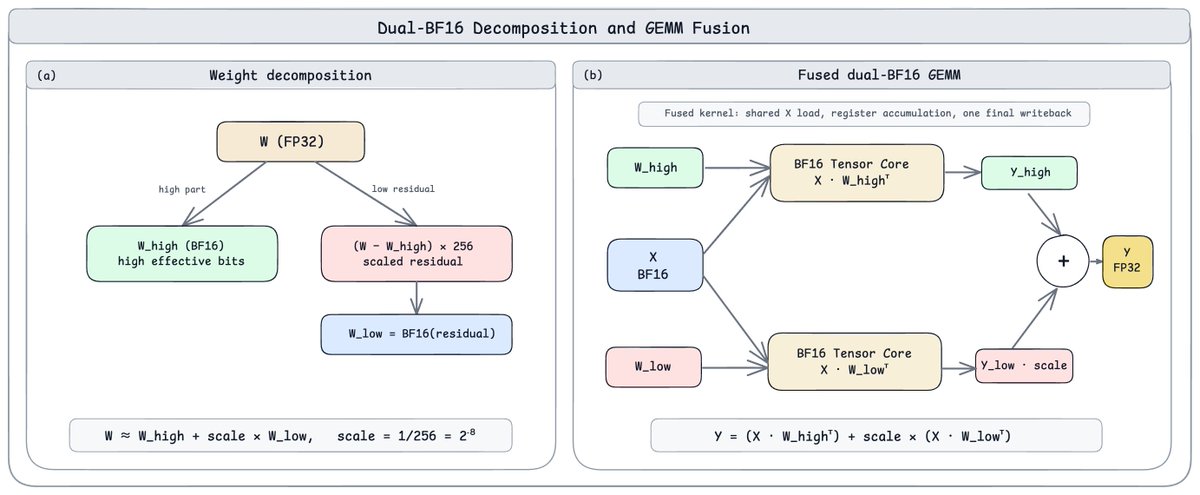
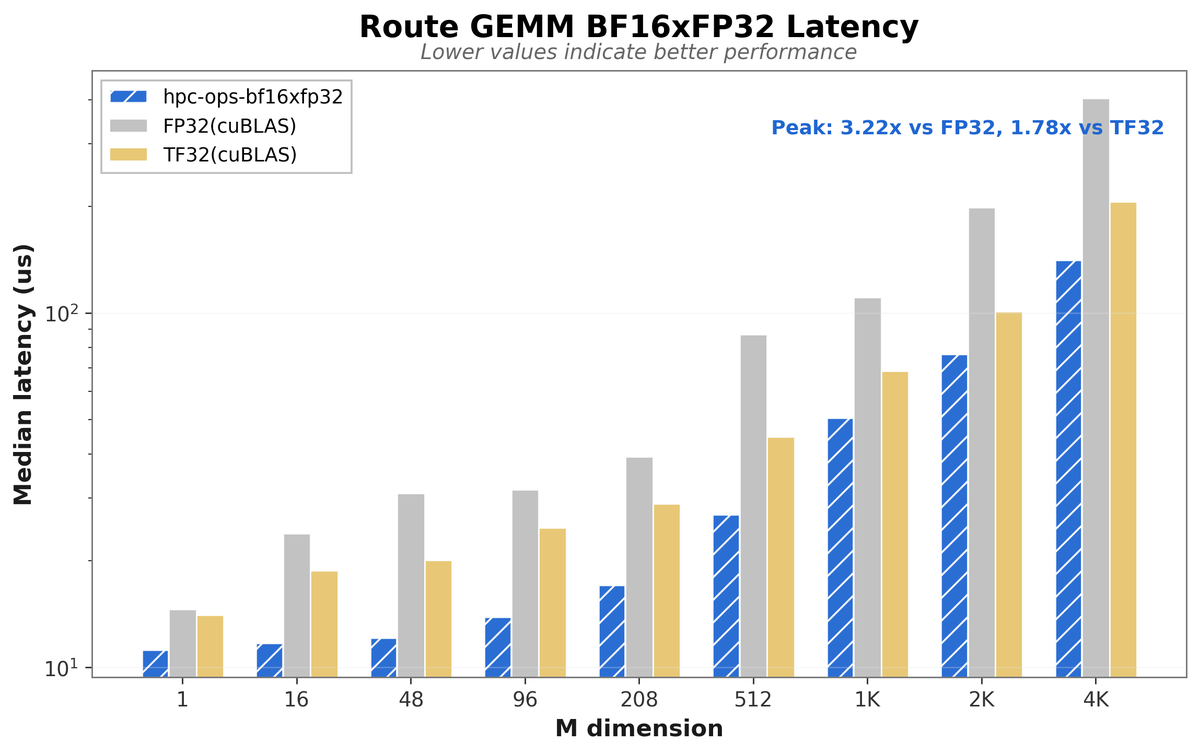
2/ Router GEMM
Combines dual BF16 GEMMs to achieve FP32-level precision while improving GPU utilization.
Up to 3.22× faster than CuBLAS FP32

1
42

Jun 10
You never heard of the GEMMs network, did you? They buy the Gilts, they have to in order to stay part of that network. So they'd be the first to know if the markets were changing & we hear nothing from them, do we? God knows where you get your nonsense from.
2
608


Jun 9
The initial buyer is not the BOE in gilt issuance. The UK DMO
DEBT!
Management
Office
sells gilts by auction to the market, mainly GEMMs/primary dealers.
I honestly do not understand why there is so much disinformation floating around.
dmo.gov.uk/responsibilities/…
2
21

Jun 8
46/100 of GPU Grind
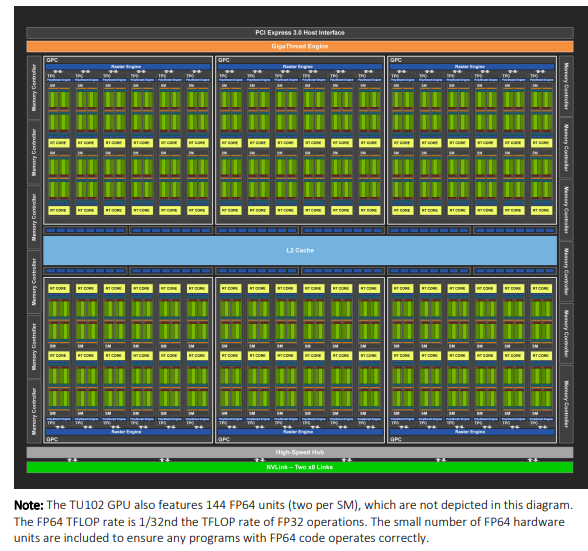
starting to work on a fp16 gemm kernel, playing with the __half api for now, all intrinsics it feels like i'm writing avx512 but in a cuda program. i'm setting up all the reference computations etc, and i was surprised to see the difference between fp64 flops and fp16 flops (i run it on a 2060 for now, going to run it on ampere ultimately to be able to use more features).
like the fp64 to fp16 ratio for cuBLAS gemms is 1/36, which is not even that much considering the hardware peak of fp64 is 1/32 of fp32 which is 1/2 of fp16, it's just that i forgot the chip had that few fp64 cores. the way they say it in the whitepaper is literally "we just included bare minimum fp64 cores so that fp64 program can run correctly". i knew that at some point but i forgot and was still surprised 😅

Jun 7

45/100 of GPU Grind
reading more about quantization today, different datatypes etc, the idea of going from fp32 to fp16 then to fp8 or even fp4 is quite simple, it’s gonna be interesting to see how its implemented though; since these are not datatypes that are necessarily natively supported in c/c
i didnt know fp8 was only supported since hopper, i think i’m going to work on a fp16 ampere hgemm first to play with the fp16 api, and then maybe a fp8 one on hopper which would also allow me to explore all the new hopper features

2
1,037

Jun 8
that’s true it does have a higher affinity for gemms
Jun 8

Muon gives off feminine vibes like it's eve to adam.
13
741
Ajitesh Shukla retweeted

Jun 7
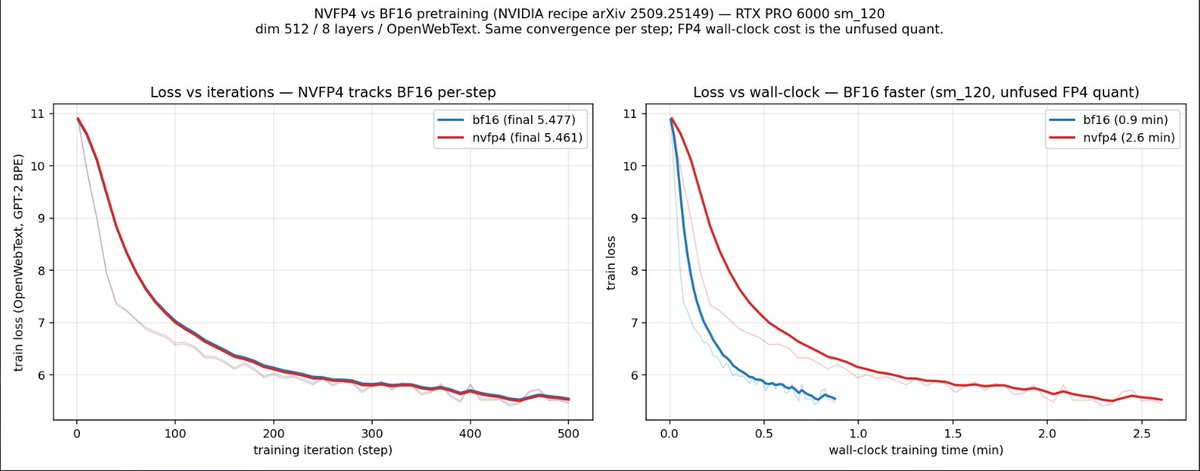
its too bad there arent any go-to high perf nvfp4 gemms for sm120 yet. thats why nvfp4 training wall clock is terrible. also not taking advantage of fusion yet
5
2
46
7,897

Jun 7
3/ note, the gradient GEMMs use stochastic rounding, but the output-layer gradient reduction stayed in fp32 since bf16 caused training instability, as amazingly detailed in the report (as divergence 1).
I think delta(w_fp4) would become zero close to 15T tokens and that could explain the weird behavior.

2
4
173


Jun 3
Slower than attention for sure. Parallax has two more GEMMs in the forward pass and the training kernel is compute-bound. There's no free lunch, which is exactly why we include the compute-matched experiment in the paper.
I didn't run the above experiment myself, perhaps @Haoxiang__Wang have the stats. But I've been running NanoChat lately, and our Triton kernel is about 25% slower than FA3 (960,000 vs 700,000 tok/sec). Hope that helps, and thanks for raising it, we'll add more efficiency discussion to the paper.
1
1
12
598