
That's a bit presumptuous. Do you have geocoding that debunks that is a Californial homeless encampment?
15

This is about geocoding more White/Europeans. Genociding the slavs. Turn Ukraine into another multicultural hell-hole and do the same to Russia. The people doing this loathe Europeans, loather the West ("Rome").
8

Jun 13
Al the problems in the World right now Is Israel fault just because they cant stop Geocoding Civilians
1
36

Jun 13
4/ AI is also helping solve operational challenges. Meesho says its address intelligence model improved geocoding accuracy by 20 percentage points, reduced misroute-related costs by 5%, and cut failed deliveries by more than 10%. 📦
1
59

Jun 12
when you're gorgeous you're allowed to write inefficient geocoding scripts
15

let me level with you I 100% know what you are. Who you work for and just because none of you are bright or not dissociating enough to put a thought together doesn't change you are traffickers who work for geocoding cannibals
2

Jun 12
You are doing to the US what you are complaining immgrants are doing to Canada! So maybe, first go back to YOUR country before asking others to do the same!!
Also, at least the new immogrants to Canada are not geocoding the settlers like your granddaddy and grandmommy did… to the natives…
3
6
947

Jun 12
RT @inno_pastime: Maps JavaScript API Geocoding API GASでウェブアプリを作ってみました🍜
叩き台作成はGeminiにお願いし、修正・レビューを重ね汎用性も抜群。
RamenDBからスクレイピングせず、公式へ送客する安全設計…
3

The on campus internship I had with him Senior Year introduced me to AGILE Scrum concepts for a Waterfall project. He was impressed by the feature phone geocoding work I was doing for WHERE when I returned for my first Reunion.
Needless to say, he will be missed 😢 #FuckCancer
14

Jun 12
How much are you paid by IRGC to say this??
What is happening in Iran is geocoding.
After freedom I would like to see such this bullshit from you then we can get even with you.
You are worthless if you don’t have balls to say this bullshit the day after freedom
1
90

Need to geocode thousands of addresses without writing code?
This guide shows how to batch geocode large address lists for free using Geoapify's Batch Geocoding tool.
📍 Upload a file
📍 Process addresses in bulk
📍 Export results
To guide:
dev.to/geoapify-maps-api/how…
#Geocoding #GIS #GeoSpatial #Maps #Geoapify
1
53


Jun 12
So what happened in Africa France withdraws and now Russia controls all it resources and is using them to destroy Ukraine so Russia is geocoding as well be fair I understand Tehran has agreement with Moscow and Assad family many Arab states but still free to say what is right 🇺🇳
20

Yeah because the peasant torturing, child raping, Christian burning, boy castrating, dog-fucking, geocoding, Pagan, morally bankrupt Romans were so much better you braindead troglodyte
2
11
772

Jun 11
Just a false propaganda what the Indian army doing geocoding IOK Muslims.
47

Our latest case study explains how @CAL_FIRE incorporates Ecopia land cover, building footprint, & geocoding data at a statewide scale for hazard mapping, defensible space inspections, & post-fire damage assessments across 32M acres.
🔥 Check it out: hubs.ly/Q04l5YLv0
1
1
75

Jun 11
You were cheering for Israel and USA for geocoding in Gaza …
How is taste now ?
How does it feel when your loved one for doing no wrong ?
How does it feel you piece of shit
16

This week was about removing weak points and tightening the system where it actually matters.
I’m continuing to push everything toward a more controlled, production-grade architecture, less tolerance for ambiguity, fewer hidden failure paths.
What got done:
Core framework issues fixed
Tracked down and eliminated several blocking problems, missing dependencies, installer failures, and permission breakdowns. Also pushed further on separating install logic from runtime so the system behaves predictably under all conditions.
Data pipeline hardened
Focused on edge cases that break ingestion and parsing. The goal here is simple: inputs can be messy, outputs cannot be. Continued tightening normalization and fallback handling, especially around geocoding.
Caching strategy improved
Reduced unnecessary external calls and made responses more consistent. Also working through better handling of known “bad” or ambiguous queries instead of letting them fail silently.
Operational UI improvements
Continued refining dark-mode interfaces for real-world use. Prioritizing readability and speed of interpretation over anything cosmetic.
Automation moving forward
Pushed ahead on automated digest/reporting systems. Outputs are becoming more structured, more relevant, and easier to act on without manual filtering.
Current focus
Lock down install/update lifecycle so nothing partially deploys
Reinforce role/permission system (no silent failures)
Expand plugin model to support multiple controlled instances
Prepare for wider deployment without introducing instability
Bottom line
I’m not optimizing for features, I’m optimizing for systems that hold up under pressure.
If it’s not reliable, it’s not done.
33

Jun 11
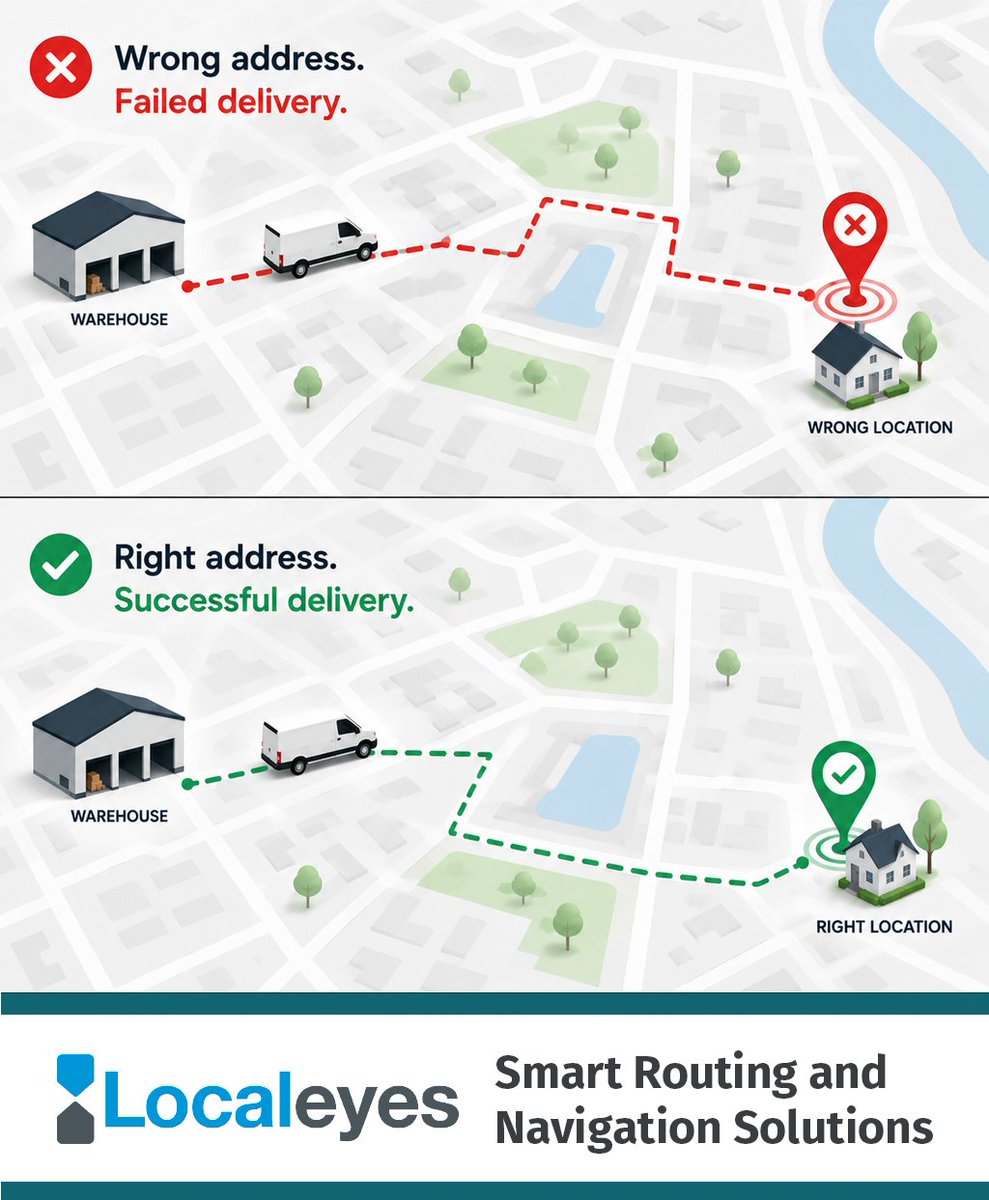
Failed deliveries often start with bad address data.
Better geocoding improves location accuracy, reduces driver confusion, and increases first-time delivery success—saving time, costs, and customer frustration.
Learn more:
local-eyes.nl/solutions/last…
#Logistics #LastMile #Geocoding
4

Jun 11
I also showed you the population of Gaza increased their population steadily up until the October 7th incident. From 1 million people in 1995 to 2.23 million in 2023. So the point is no one was geocoding them at all.
11