


India's complete financial platform. Banking Insurance AMC Broking.
Retail Banking (largest segment): 500M customers. India's #1 home loan lender. Personal, auto, agriculture loans. YONO digital platform 10.02 Cr users. 98.7% of transactions via digital channels. Home loans 15% YoY. SME 19.1% YoY.
Corporate/Wholesale Banking: India's largest corporate lender. Working capital, project finance, infrastructure, international trade. Corporate loans 5.7%. International advances 14.8%. 229 overseas offices in 31 countries.
Treasury: Largest GoSec portfolio in India. 25.10% UPI market share (18 Cr transactions/day). 25.11% debit card spend share. Q4 treasury impacted by bond MTM losses.
Subsidiaries:
→ SBI Life Insurance (India's largest, MCap ₹1.7L Cr)
→ SBI Mutual Fund (India's largest AMC, AUM ₹11L Cr)
→ SBI Cards (MCap ₹25,000 Cr)
→ SBI General Insurance (73.87% stake)

1
50

May 29
And for anyone who wants a real deep dive, here's the entire plan:
# Plan: Full Multi-Metric Evaluator (quality, security, human_like)
## Context
MorganBench scores runs on `functional` and `efficiency` today; `quality`,
`security`, and `human_like` are explicit `None` placeholders in
`harness/evaluator/scorer.py` and excluded from the weighted `total`. The
project's spec calls for all five metrics. This feature implements the three
missing ones so a run produces a complete, honest score — without faking values
when a tool or API key is unavailable.
Decisions (from clarifying questions):
- **Judges**: 3-judge `human_like` ensemble runs **on by default**, reusing the
run's `provider:model` with 3 distinct reviewer personas. `--judge-model`
overrides; if no API key/provider error, `human_like=null` with a reason
(mock runs judge for free, deterministically).
- **Languages**: analyzers cover **Python, TS/JS, Go, Java**. Python is fully
native (added pip deps). The others shell out to their toolchains *if present
on PATH*; when a tool is missing, that language reports `null` a recorded
reason — never a silent zero or inflated score.
- **Weights**: `functional 0.50, quality 0.15, security 0.15, efficiency 0.10,
human_like 0.10`, re-normalized over whichever metrics are non-null.
## Design overview
New modules under `harness/evaluator/`:
- `langs.py` — file-extension → language map; per-language analyzer registries.
- `quality.py` — `assess_quality(workspace, changed_files) -> MetricResult`.
- `security.py` — `assess_security(workspace, changed_files) -> MetricResult`.
- `judges.py` — `assess_human_like(issue, patch, verifier_summary, provider, n=3) -> MetricResult`.
- `evaluate.py` — `evaluate_run(...)` orchestrator the loop calls; runs all
metrics, records per-metric trace events, returns the final scores dict.
`MetricResult` (pydantic): `score: float | None`, `details: dict` (tool used,
per-language/per-file counts, and `reason` when skipped). Scores are 0–1.
Analysis is scoped to the **agent's changed files** (the git diff), not the
whole repo, so we measure the agent's work. Add `_git_changed_files(workspace)`
to `harness/agent/loop.py` (parse `git diff --cached --name-only`).
### quality.py
Per language, run the linter/complexity tools on changed files of that language;
combine sub-scores, then average across analyzed languages.
- **Python (native deps)**: `ruff check --output-format=json` (violation
density), `radon cc -j` (cyclomatic complexity), `radon mi -j` (maintainability
index). `quality_py = mean(lint_score, complexity_score, mi_score)` where
`lint_score = max(0, 1 - violations/changed_loc)`, `complexity_score` maps avg
CC (≤5 → 1.0, decaying), `mi_score = MI/100`. Formula constants live at module
top, documented and tunable.
- **TS/JS**: `npx --no-install eslint -f json` if resolvable, else `null` reason.
- **Go**: `gofmt -l` `go vet` if `go` on PATH, else `null` reason.
- **Java**: `checkstyle` if on PATH, else `null` reason.
- If no language analyzed → `score=None`, `details.reason="no analyzer available"`.
### security.py
Per language, severity-weighted: `score = clamp(1 - (0.4·high 0.15·med 0.05·low), 0, 1)`.
- **Python (native dep)**: `bandit -r <changed .py> -f json`.
- **TS/JS**: `npm audit --json` if `package.json` lockfile present, else `null` reason.
- **Go**: `gosec -fmt=json` (or `govulncheck`) if on PATH, else `null` reason.
- **Java**: `spotbugs`/find-sec-bugs if on PATH, else `null` reason.
- Reuse: point `LocalToolExecutor.security_scan` (`harness/agent/local_executor.py:121`)
at `assess_security` so the agent's `security_scan` tool returns real data.
### judges.py
- 3 personas (CORRECTNESS, READABILITY, MAINTAINABILITY). Each builds a chat:
system = persona rubric; user = issue patch one-line verifier outcome
instruction to return **only** JSON `{"score": 0-100, "rationale": "..."}` and
the sentinel string `MORGANBENCH_JUDGE`.
- Call `provider.complete(messages, tools=[])`; `_extract_json()` robustly pulls
the JSON (first `{...}` block, regex `"score"` fallback). `human_like =
mean(valid votes)/100`. `details` = per-judge score rationale model persona.
- Each judge independent: a `ProviderError` or unparseable reply drops that vote
(note it); if zero valid votes → `human_like=null` reason. Judge token usage
is summed into `details.judge_tokens` and recorded as `judge_vote` trace events
— **not** added to the run's `total_tokens` (efficiency measures the agent).
- `MockProvider.complete` (`harness/agent/providers.py:227`): add a branch — if
any message content contains `MORGANBENCH_JUDGE`, return
`LLMResponse(content='{"score": 80, "rationale": "mock judge"}')`. Keeps
`mock:synthetic` deterministic for the demo and tests.
### scorer.py changes
Extend `score_run` to accept `quality`, `security`, `human_like` kwargs (default
`None`); set `_WEIGHTS` to the five-metric defaults above. Existing
present-only re-normalization (scorer.py:83-87) already handles `None` exclusion.
### evaluate.py orchestrator
```
evaluate_run(*, functional, total_tokens, steps, workspace, patch,
changed_files, languages, issue, verifier_payload,
judges_enabled, judge_provider, collector=None) -> dict
```
Runs quality security judges (when enabled), records `quality_detail`,
`security_detail`, `judge_vote` events via `collector`, then returns
`score_run(...)` output augmented with each metric's `details` under a
`metric_details` key in the summary `extra`.
### loop.py cli.py integration
- `harness/agent/loop.py:112-114`: after `_verify`, compute
`changed = _git_changed_files(workspace)`, build the judge provider
(`get_provider(judge_model or model)`), call `evaluate_run(...)` instead of
`score_run(...)`, then `collector.record("metric_computed", scores)`.
- `run_agent` signature gains `judges: bool = True`, `judge_model: str | None = None`.
- `harness/cli.py` `run` gains `--judges/--no-judges` (default on) and
`--judge-model` options, passed through to `run_agent`.
### Dependencies (`pyproject.toml`)
Move `ruff` into main `dependencies` (now used at runtime) and add `bandit>=1.7`
and `radon>=6.0`. Go/Java/JS tools are external (documented as optional in
`docs/ROADMAP.md`/README, not pip deps).
## Files to create / modify
- **Create**: `harness/evaluator/langs.py`, `quality.py`, `security.py`,
`judges.py`, `evaluate.py`.
- **Modify**: `harness/evaluator/scorer.py` (weights new kwargs),
`harness/evaluator/__init__.py` (exports), `harness/agent/loop.py`
(`_git_changed_files`, call `evaluate_run`, new args), `harness/agent/cli.py`
→ `harness/cli.py` (flags), `harness/agent/providers.py` (`MockProvider`
judge branch), `harness/agent/local_executor.py` (`security_scan` reuse),
`pyproject.toml` (deps).
- **Tests**: `tests/test_quality.py`, `tests/test_security.py`,
`tests/test_judges.py` (new); update `tests/test_evaluator.py` (the two tests
asserting `quality/security is None`), `tests/test_agent_loop.py` (assert
non-null metrics for mock hello-world), `tests/test_cli.py` (`--no-judges`).
## Honesty / degradation rules (must hold)
- A missing toolchain → that language's metric is `null` with a `reason`, logged
to the trace; aggregate over analyzed languages only; all-missing → metric `null`.
- Judge failure / no API key → `human_like=null` with reason; never a fabricated score.
- Judge tokens never inflate or deflate `efficiency`.
## Verification
1. `pip install -e ".[dev]"` (picks up bandit/radon/ruff).
2. `morganbench run --task hello-world --model mock:synthetic` → `summary.json`
`scores` now has non-null `quality`, `security`, `human_like`, and a `total`
that blends all five; `metric_details` present; `trace.jsonl` shows
`quality_detail`/`security_detail`/`judge_vote` events.
3. `morganbench run --task hello-world --model mock:synthetic --no-judges` →
`human_like` is `null`, total re-normalizes over the other four.
4. Negative-path check: a workspace file with a bandit-flagged pattern (e.g.
`subprocess.call(x, shell=True)`) drops `security` below 1.0.
5. `ruff check harness backend tests` clean; `mypy harness` clean;
`pytest` green; core harness coverage stays ≥80%.
6. Dashboard `/run/[id]` already renders all five score keys — they now show
real values instead of `n/a` (no dashboard change needed).
1
3
774

Just noticed that the old website also credited Semgrep, Gosec,Brakeman, CloudSploit, Trivy, Syft, Grype, ZAP, Nuclei, and Phylum. Are these all no longer used?
They sponsor Betterleaks and OpenGrep work: aikido.dev/open-source, so they know how to do it right.

ALT Screenshot of old Aikido website crediting Semgrep, Gosec, and Brakeman

ALT Screenshot of old Aikido website crediting CloudSploit for CSPM

ALT Screenshot of old Aikido website crediting Trivy, Syft, Grupe as "leveraged"
ALT Screenshot of old Aikido website crediting ZAP and Nuclei for DAST.

Don't you love it when a billion dollar company decides to stop attributing your open-source work and pass it off as their own?
web.archive.org/web/diff/202…
Great job @AikidoSecurity.
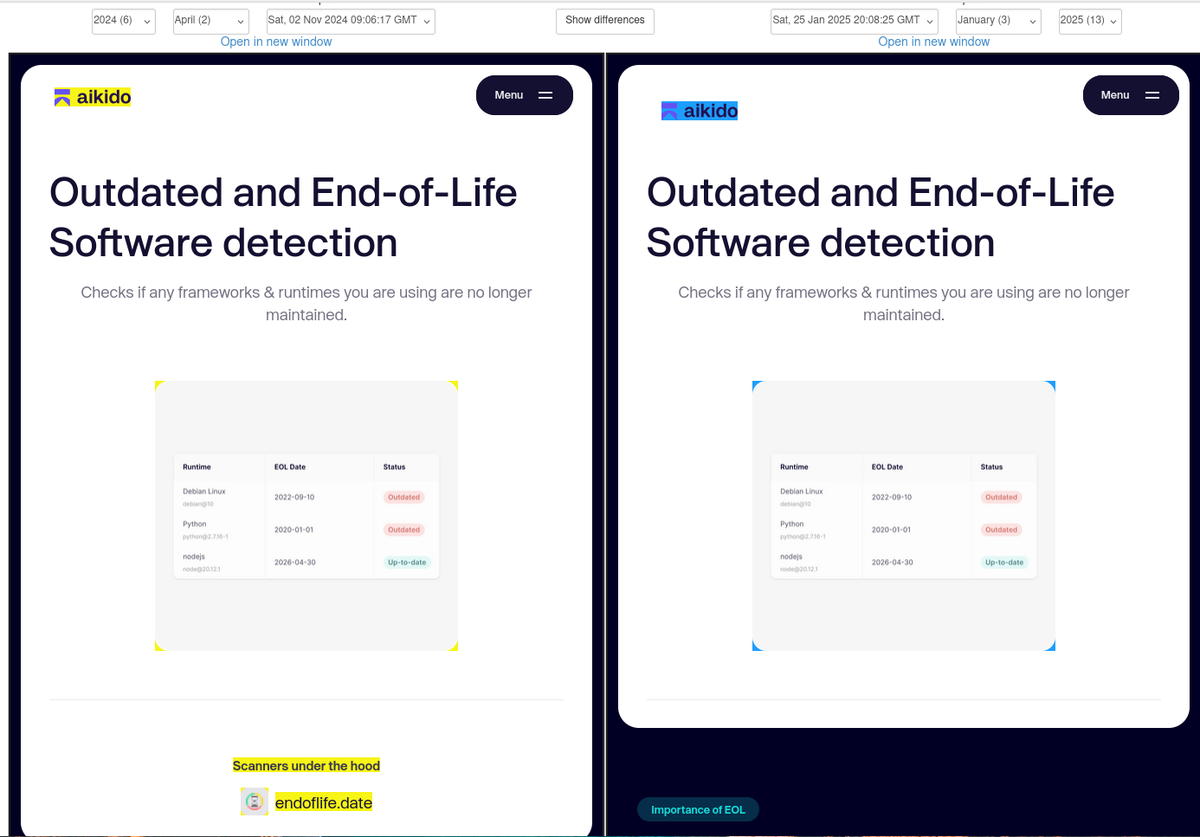
ALT A diff of two web archive screenshots of the Aikido website showing attribution to endoflife.date being removed.
1
4
22
3,967





Jan 21
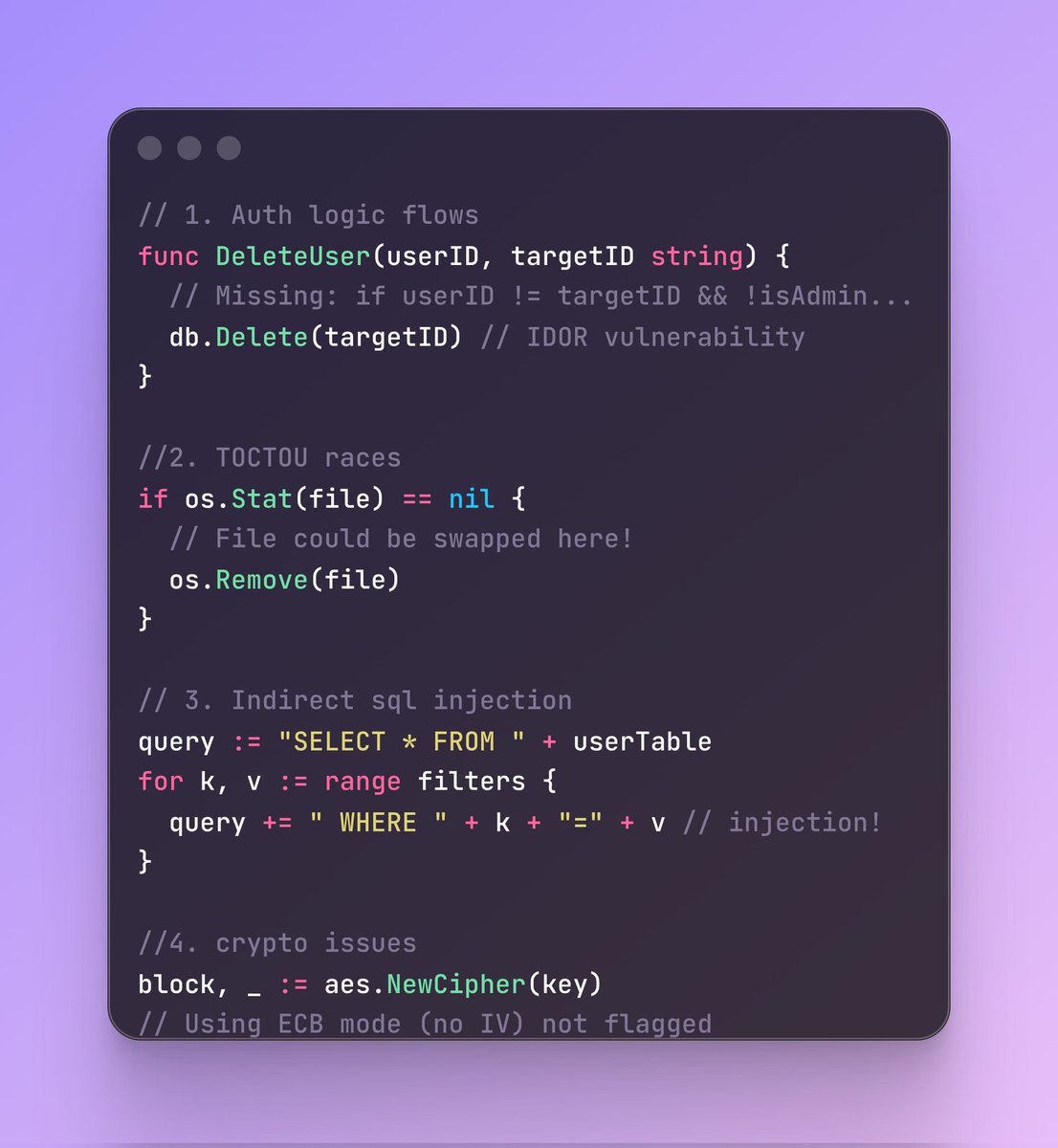
I was wondering how does go vet and staticcheck find security issues.
we know both tools perform static analysis on Go source code by building an abstract syntax tree (AST) and analyzing code patterns without executing the program.
go vet and staticcheck are great but have blind spots. They catch syntactic issues but miss semantic security bugs.
Bugs they catch are as follows:-
1. Printf mismatches
2. Basic SQL concat injection
3. Obvious crypto misuse (MD5)
What they miss are:
1. Auth logic flows
2. TOCTOU races
3. Indirect sql injection
4. subtle crypto issues
developers should augment these tools with static analysis tools below:-
-> gosec: specifically designed for Go security
->semgrep: with custom security rules
->govulncheck: for dependency vulnerabilities
->Custom analyzers for your specific security requirements
2
4
45
4,168

Jan 1
Go Lambda開発を守る:gosec/Trivy/golangci-lintで構築する自動セキュリティCI|Y.A zenn.dev/yadevloper/articles… #zenn
1
2
1,426


25 Oct 2025
TEAMS (3): At Pistachio we use various free/cheap tools (dependabot, gosec, govulncheck, etc) to stay on top of obvious code security problems (plus semgrep). Infra scanning stuff (vanta, cloudgeni, security command center), and network protection (Google Cloud Armor).
1
9
398

10 Sep 2025

10
747


10 Sep 2025
Come see my talk, Security Champion Worst Practices, in room 513A & B, at 10 am. #gosec2025 #gosec

10
782


9 Sep 2025
What happens when you bring Red teams and Blue teams together? Panelists, including our own @ScoubiMtl, will discuss the power of collaboration and Purple Teaming. Don't miss the panel tomorrow at GoSec 25!
Learn more: gosec.net/

2
9
1,767
31 Aug 2025
I'm off to record my audiobook for Alice and Bob Learn Secure Coding this week in Ottawa! Next week is #GoSec in Montreal. 🥳

2
3
42
1,732

20 Aug 2025
Year 2026,
Am hearing the interior of the interiors of Kenya,
Good Shepherd Gospel Campaign (GOSEC) Caravan.
Am hearing the cry of the master.
If God has called you, follow His call.
“Don't permit difficulties & uncertainities to stop you.”
#NoPlaceShallBeTooInteriorForUs



2
5
73