Alessandro Coppelli retweeted

Jun 14
Self-hosted graph database using GraphBLAS for sparse matrix representation
github.com/FalkorDB/FalkorDB
7
29
3,024


MOST LLM APPS ARE BUILT ON FLAT DATABASES
falkordb changes that
it's a graph database built specifically for llms using graphblas and sparse matrix representation under the hood.
what that means in practice:
▫️ ultra-low latency knowledge graph queries
▫️ graphrag-ready out of the box
▫️ multi-tenant, runs on docker in one command
▫️ opencypher support python, node, rust, go clients
used for agent memory, fraud detection, cloud security & generative ai pipelines
github.com/falkordb/falkordb
6
23
98
5,334

Mar 20
SQL fails at 3 hops. GraphDBs don't.
Imagine finding all accounts within 3 hops of a suspicious transaction. Or linking fragmented customer records across systems by shared emails and phone numbers.
These are graph traversal queries. SQL can handle relationships but not depth.
Sure, you can write recursive CTEs and self-joins. That works at 1-2 hops. But go deeper and two things happen:
- The query becomes unreadable
- And the performance tanks
Each hop adds another self-join. By hop 5-6, you're looking at queries that run for minutes and fall apart under load.
The same query in Cypher:
𝗠𝗔𝗧𝗖𝗛 (𝘁:𝗧𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻 {𝗶𝗱: '𝗧𝗫𝗡-𝟬𝟬𝟭'})-[:𝗜𝗡𝗩𝗢𝗟𝗩𝗘𝗦*𝟭..𝟯]-(𝗮:𝗔𝗰𝗰𝗼𝘂𝗻𝘁)
𝗥𝗘𝗧𝗨𝗥𝗡 𝗗𝗜𝗦𝗧𝗜𝗡𝗖𝗧 𝗮.𝗻𝗮𝗺𝗲, 𝗮.𝗽𝗵𝗼𝗻𝗲
3 lines. Reads like the question you're asking. Scales to any depth.
This is what graph databases are built for.
FalkorDB is one worth knowing about. It's open-source. And it takes a different architectural approach compared to most graph DBs.
Most graph databases chase pointers from node to node during traversal. FalkorDB doesn't do that. It's built on GraphBLAS, a linear algebra framework that represents graph operations as sparse matrix computations. Each hop becomes an optimized matrix operation instead.
The result:
- Better cache behavior
- Parallel computation across hops
- Sub-millisecond latency on deep multi-hop queries
It also uses openCypher. So if you've written Cypher before (say, with Neo4j), the syntax is identical. No new query language to pick up.
Graphic below nicely illustrates how FalkorDB is superior to traditional relational DBs.
I have shared link to their GitHub repo in the next tweet.
3
10
59
6,660

Mar 2
זה דרך פתרון נפוצה לאופטימיזציה לבעיות פתרון פעולות אריתמטיות. הפתרון שלהם גם אם הוא תפור למלא מקרים אם הוא באמת משפר הרצה של מודלים פי 3 זה חסכון אדיר בזמן ואנרגיה.
גם אנחנו משתמשים בפתרון עם גישה דומה ,אופטימיזציה של מלא קרנלים לביצוע פעולות על מטריצות דלילות שנקרא GraphBLAS.
7
621

Feb 22
A super fast Graph Database uses GraphBLAS under the hood for its sparse adjacency matrix graph representation. Our goal is to provide the best Knowledge Graph for LLM (GraphRAG).
github.com/FalkorDB/FalkorDB
1
8
346



Jan 8
This new graph DB is 496x faster than Neo4j!
(open-source)
Let me break down why:
A traditional graph DB stores two things: nodes (entities) and edges (relationships between them).
When you query a traditional graph DB, it traverses by "pointer chasing":
→ Start at a node
→ Follow a pointer to the connected node
→ Follow another pointer
→ Repeat
This is inherently sequential. One hop at a time. And as your graph grows, this gets painfully slow.
FalkorDB asks a different question:
What if we represent the entire graph as a matrix?
Here's how it works:
Imagine a simple grid. Rows are source nodes, columns are destination nodes.
If Mary follows Bob, you set position [Mary, Bob] = 1.
That's it. Your entire graph is now a matrix of 1s and 0s.
Let's call this the Follows matrix (F).
Here's where it gets interesting:
Finding who Mary’s friends follow? In a traditional graph DB, you hop twice: Mary → friends → friends’ friends.
But with matrices, you multiply the Follows matrix by itself: F × F = F².
This takes just one operation, and you’re done!
Similarly, a complex pattern like “A follows B, B likes C” becomes: Follows × Likes.
This means you can represent traversal as math operations.
Why this matters:
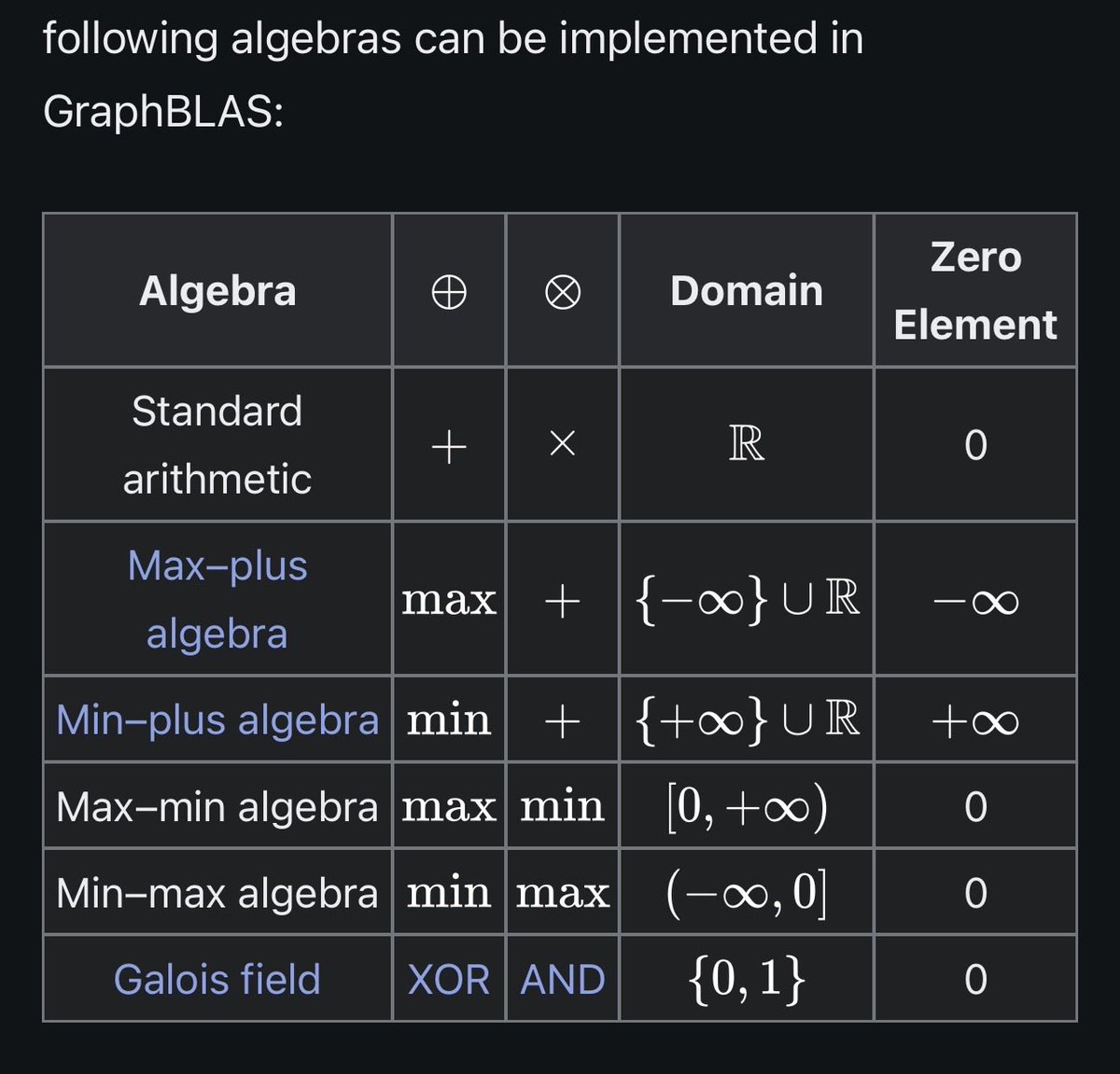
- Matrix operations have been optimized for 50 years
- Modern hardware (CPUs/GPUs) is built to crunch matrices
- Operations run in parallel (pointer-chasing simply cannot)
While there are a few more optimizations involved (like using sparse matrices, written in C, etc.), this approach makes FalkorDB 496x faster than Neo4j.
The graphic below shows this difference clearly.
Traditional graph DBs go through Cypher QL → Pointer-Based Traversal, while FalkorDB uses a Matrix-Aware Planner that converts queries into matrix operations.
FalkorDB is built entirely on this principle:
- Native Redis module (in-memory, ultra-fast)
- Powered by GraphBLAS for sparse matrix operations
- Auto-translates Cypher queries into matrix algebra
This is hugely important for AI applications because…
Modern AI agents and RAG systems need to traverse complex relationships in real-time. When an agent reasons through a knowledge graph, connecting users to actions to outcomes, every millisecond of latency compounds.
Vector DBs capture semantic similarity. But they miss explicit relationships.
Knowledge graphs fill that gap.
And when your agent needs to perform multi-hop reasoning across thousands of connected entities, matrix-based traversal makes it easier to scale your AI application without running into latency bottlenecks.
FalkorDB is 100% open-source, and you can see the full implementation on GitHub and try it yourself.
I've shared a link to their GitHub repo in the replies.
15
63
407
26,404

面向LLM的超高速图数据库:FalkorDB,为LLM提供长期记忆、上下文理解和事实性知识,帮助LLM进行复杂推理
其通过GraphBLAS、稀疏矩阵和线性代数查询,来解决LLM在事实性、上下文理解和实时响应上的痛点
用稀疏矩阵和线性代数替代传统遍历,将整个图结构转化为数学矩阵,稀疏矩阵只存储存在的连接,这极大节省空间和计算资源,查询变成矩阵运算,速度远超遍历
比仅靠向量搜索,图数据库能保留实体间的细腻关系和上下文,提升智能体返回信息的准确性和相关性
做为GraphRAG的“知识缓存”,LLM回答前先要“秒级”拿到相关子图,FalkorDB负责毫秒级把实体-关系子图抽出来塞Prompt
做为智能体/聊天机器人记忆,对话过程中实时写入“用户-意图-实体”三元组,下轮对话立刻可查
#AI记忆 #FalkorDB
4
45
160
16,105

25 Nov 2025
Why FalkorDB matters:
🔹Sub-10ms graph lookups
🔹Perfect for agentic workflows
🔹Uses the same math as GPUs (GraphBLAS)
🔹Ideal for GraphRAG long-term memory
🔹Lightweight open source
It basically fixes the core bottleneck in autonomous AI systems.
#FutureTech #GraphDB
2
1
5
37

19 Dec 2024
Is Math the Language of Knowledge? 🎙️
Is it possible to retrieve information in a RAG system with matrix multiplication? The CTO and Cofounder of @falkordb , @roilipman, explains how using GraphBLAS techniques, yes, you can!
youtu.be/eRbVfXbWEsw
4
7
241
6 Dec 2024
For a couple of reasons but the main one is FalkorDB is using GraphBLAS to represent its Graph topology.
Meaning its the only Graph Database to use Adjacency Matrix vs Adjacency List
1
2
41