

Jun 12
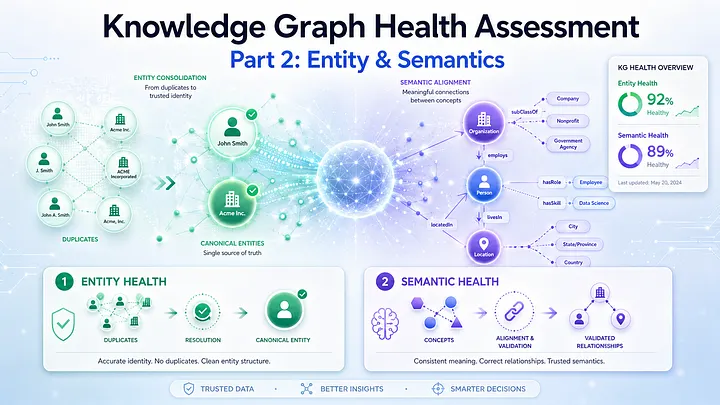
Knowledge Graph Health Assessment Part 2: Entity and Semantics
From connected graphs to trustworthy meaning for Adaptive Graph RAG
A healthy knowledge graph is not the densest graph. It is the graph whose structure preserves meaning, supports retrieval, and remains stable as knowledge evolves.
But structure is only the first layer of KG health.
A graph can be structurally healthy and still fail reasoning.
It may have short paths, strong hubs, and connected communities, but still suffer from deeper problems:
* the same real-world entity appears under many names;
* different entities are incorrectly merged;
* relationships violate domain logic;
* concepts are weakly typed or inconsistently mapped;
* important entities, properties, evidence, or relationships are missing.
For Graph RAG, these problems are not minor data quality issues. They directly affect retrieval quality, answer consistency, grounding, and trust.
In this post, the focus is on two additional layers of Knowledge Graph Health Assessment:
Entity Health → Are real-world things represented consistently?
Semantic Health → Are meanings, types, and relationships valid?
The goal is to move from a graph that is merely connected to a graph that is meaningful, consistent, and complete enough for reasoning.
By Fanghua (Joshua) Yu
medium.com/@yu-joshua/knowle…
--
💬 ‘An indispensable summary’ - Mark Underwood, Synchrony.
Join readers from Amazon, Capgemini, Michelin, Neo4j & more
Subscribe to the Year of the Graph newsletter for quarterly updates and insights on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech 👇
yearofthegraph.xyz/newslette…
1
8
138

Jun 12
(ΦωΦ )ホホゥ.... HelixDB written in Rust that collapses Postgres, Pinecone, GraphDB into one.
GitHub Awesome's video lite.tiktok.com/t/ZSQ5n3m7v/
17

Jun 12
The Early Bird clock is ticking. ⏱️
In just 3 days, ticket prices for #CDL26 will increase across all pass types - including All-Access, Day Passes, and Remote. This is your final window to join us at the Leonardo Royal Hotel London Tower Bridge while saving 30%.
What’s on the table:
✅ Technical deep-dives into Knowledge Graphs and LLMs.
✅ Hands-on Masterclasses.
✅ Networking with the world’s top data architects.
Don’t wait for the deadline. Save 30% and book your pass today.
👉 2026.connected-data.london/c…
#CDL26 #ConnectedData #KnowledgeGraphs #DataScience #AI #GraphDB #Analytics #SemTech #EmergingTech #EnterpriseData #DataStrategy #AIArchitecture

1
109


Jun 11
Knowledge Graphs as the Missing Data Layer for LLM-Based Industrial Asset Operations
How much does the data model behind the tools matter?
Industrial asset management generates vast quantities of structured data: sensor telemetry, work orders, failure mode analyses, equipment hierarchies, and maintenance schedules. The rise of Large Language Models (LLMs) has prompted efforts to build autonomous agents that can reason over this data—answering operational questions, predicting failures, and recommending maintenance actions.
LLM-based agents for industrial asset operations show limited accuracy when reasoning over flat document stores. AssetOpsBench provides the first systematic evaluation of such agents, benchmarking seven contemporary LLMs across 141 expert-curated maintenance scenarios. It establishes that GPT-4 agents achieve 65% on 139 industrial maintenance scenarios, and compares LLM orchestration paradigms (Agent-As-Tool vs. Plan-Execute) on a fixed data layer.
This approach from Samyama transforms the AssetOpsBench data sources into a typed knowledge graph using an 8-step ETL pipeline and treats a typed knowledge graph as a grounding substrate, routing each question by how it is best answered:
(i) LLM-generated Cypher for structured retrieval, which lifts the same GPT-4 model from 65% to 82-83%;
(ii) native graph and optimization primitives, with no LLM, reaching 99% on graph-answerable scenarios; and
(iii) generation-augmented knowledge (GAK) for answers absent from the data -- the engine's agent materializes the missing facts as provenance-tagged graph nodes, then answers.
A recurring theme is inverted LLM usage: constraining the LLM to query generation or one-shot enrichment from a typed schema and letting the graph execute deterministically.
On the 88 real AssetOpsBench failure-mode scenarios the benchmark itself flags non-deterministic -- ten equipment types absent from the graph -- GAK lifts answerability from zero to 100% of equipment types and answers 81.8% of scenarios, every materialized fact tagged source:LLM-derived for auditability. This work also contributes 40 graph-native scenarios.
For structured operational domains the data layer -- not the LLM orchestration -- is the primary lever, and a typed knowledge graph serves as a grounding substrate between raw industrial data and LLM reasoning.
By Madhulatha Mandarapu, Sandeep Kunkunuru
arxiv.org/abs/2605.26874
#LLM #EmergingTech #AssetManagement #Research #Innovation #DataEngineering #KnowledgeEngineering
--
💬 ‘A great newsletter’ - Claudia Remlinger, former Sr. Marketing Director, Neo4j.
Join readers from Amazon, Capgemini, Michelin, Neo4j & more
Subscribe to the Year of the Graph newsletter for quarterly updates and insights on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech 👇
yearofthegraph.xyz/newslette…

1
8
294
Jun 11
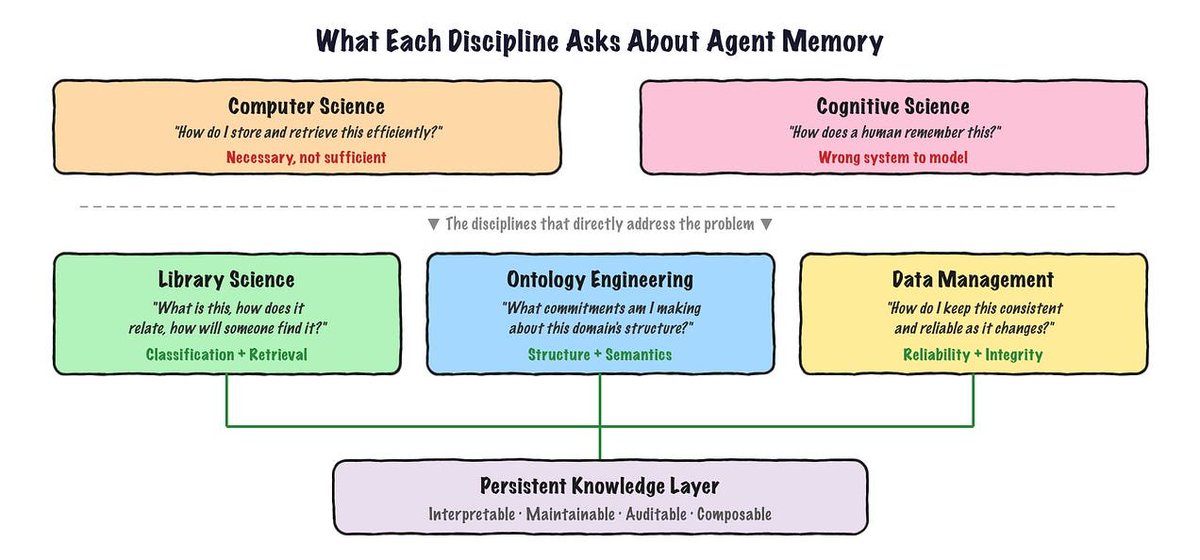
Your agent's memory problem is an information architecture problem 🧠
Most AI agent frameworks handle "memory" the same way: turn text into embeddings, store them, and retrieve whatever seems most similar to the current query.
For demos, that works fine.
But for an agent that needs to actually retain knowledge across sessions, notice when something has changed, and resolve contradictions, Artur Ciocanu argues this approach falls apart fast.
His example: every major vector database now combines similarity search with old-fashioned keyword matching, because similarity alone wasn't good enough. If your modern retrieval system needs a decades-old technique as a crutch, maybe similarity was never the right foundation for "knowledge" to begin with.
The essay traces a path through three disciplines.
Computer science gives you excellent containers (databases, indexes, search) but no sense of what the data means or how it relates to other data.
Cognitive science offered the idea of "episodic" vs "semantic" memory, borrowed from how human brains work. But human memory is built to be reconstructive and a bit lossy. Agent knowledge needs to be the opposite: precise, versioned, and consistent.
Mem0, a popular memory tool, illustrates the tension well: its newest version stores every new fact rather than updating old ones, on the theory that conflicts get sorted out later at retrieval time. The community has flagged cases where this clearly breaks (the system stores "my name is Alice" and "my name is Bob" as two separate facts, both retrieved with equal confidence).
The third discipline is the unexpected one: library science, plus its close cousins, ontology and knowledge engineering.
Librarians have spent over a century solving exactly this problem: how do you organize information so someone can find the right thing later, in a context you can't predict in advance?
That tradition offers tools that should sound familiar to anyone working with knowledge graphs: deciding at the point of storage whether something is worth keeping at all, normalizing different terms that mean the same thing into one canonical concept, systematically deciding what to discard rather than just letting it fade from memory, and trusting facts differently depending on where they came from (something a person told you directly versus something the system guessed).
The essay reframes the whole problem: an agent's memory isn't a brain. It's more like a customer data platform, where different agents are channels writing information about a person into a shared profile.
The piece builds on the work of Jessica Talisman (library science and information architecture for AI) and Kurt Cagle (ontology engineering), and points to Hindsight, a research system from Vectorize.io, as evidence the field is independently rediscovering these same ideas under benchmark pressure.
An interesting read for anyone working with knowledge graphs, ontologies, or skeptical of the idea that retrieval alone equals memory.
arturciocanu.substack.com/p/…
--
#EmergingTech #OntologyEngineering #AIAgents #InformationArchitecture #DataManagement
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open.
connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech
1
1
11
458

Jun 10
Build Meaning Before Machines: Why Semantics, Ontologies, And Knowledge Graphs Matter For Agentic AI
Forrester's analysis notes that Agentic AI is exposing a foundational gap in most enterprise data strategies: Data without meaning is unusable for autonomous systems.
Agents don’t just retrieve data — they interpret, decide, and act. Without explicit context, they guess. And when agents guess, they get joins wrong, misinterpret metrics, and act on flawed assumptions. This is why ontologies, semantic layers, and knowledge graphs are rapidly becoming core architectural components. They provide what agentic systems lack in traditional data environments: a shared language, explicit relationships, and machine-readable context.
Two recently published reports give leaders clear definitions for semantics, ontologies, and knowledge graphs and provide a path for enterprises to get started on their AI transformation journey.
Semantic Layers Are The Starting Point
Make Data AI Ready Via Semantic Layer Platforms (with Noel Yuhanna) focuses on the first step in this journey: making data interpretable before making it intelligent.
Semantic layers have long ensured business-intelligence consistency. In the agentic era, they also give agents the governed context needed to turn natural language into accurate queries and actions. Modern semantic layer platforms also extend beyond metric definitions with runtime services, APIs, lineage, and policy enforcement across hybrid and multicloud environments — keeping business meaning stable as platforms change.
The report also introduces the data graph as a bridge to knowledge graphs, capturing relationships and usage patterns so organizations can give agents more context without jumping directly to a full knowledge graph architecture.
Knowledge Graphs Define The Destination
Combine Semantics, Ontology, And Knowledge Graphs For AI-Ready Data (with Indranil Bandyopadhyay and Charlie Dai) demystifies semantics, ontology, and knowledge graphs as terms.
The report suggests a desired end state: a semantically rich enterprise where all enterprise entities are not just connected but understood. It proposes a layered approach in which ontologies define knowledge, semantics enforce clarity and consistency, and knowledge graphs connect these elements into a model that supports reasoning and discovery.
Knowledge graphs are more than a data integration technique; they form the foundation of an enterprise digital twin. By making all enterprise entities and relationships explicit, they help AI interpret context, infer connections, and act more accurately across domains.
Start With Semantics, Then Evolve To A Digital Twin
The two reports together define a clear evolution path. Most organizations are not yet ready to build a knowledge graph. The semantic layer is the right starting point. It creates a consistent foundation of meaning: standardized definitions, governed metrics, and shared logic across tools and teams. The knowledge graph is the long-term destination — a form of digital twin that enables agentic AI to reason and act across the enterprise.
forrester.com/blogs/build-me…
#AgenticAI #KnowledgeGraph #SemanticLayer #DataStrategy #EnterpriseAI #DigitalTwin #AIReadyData
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open.
connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

1
3
24
660
Jun 10
Everyone needs a context layer, but what exactly is it and how do you get one?
Many organizations are looking for advice on private context. They all start the same way: "how do we make our context usable for agents?" The phrasing is always the same. What's underneath it never is.
The moment you look closely, it breaks apart into several different problems that only look alike from a distance.
What actually sorts this space, Elisenda Bou-Balust argues, is the kind of context you're dealing with. That decides what exists to work with and which tools are even on the table.
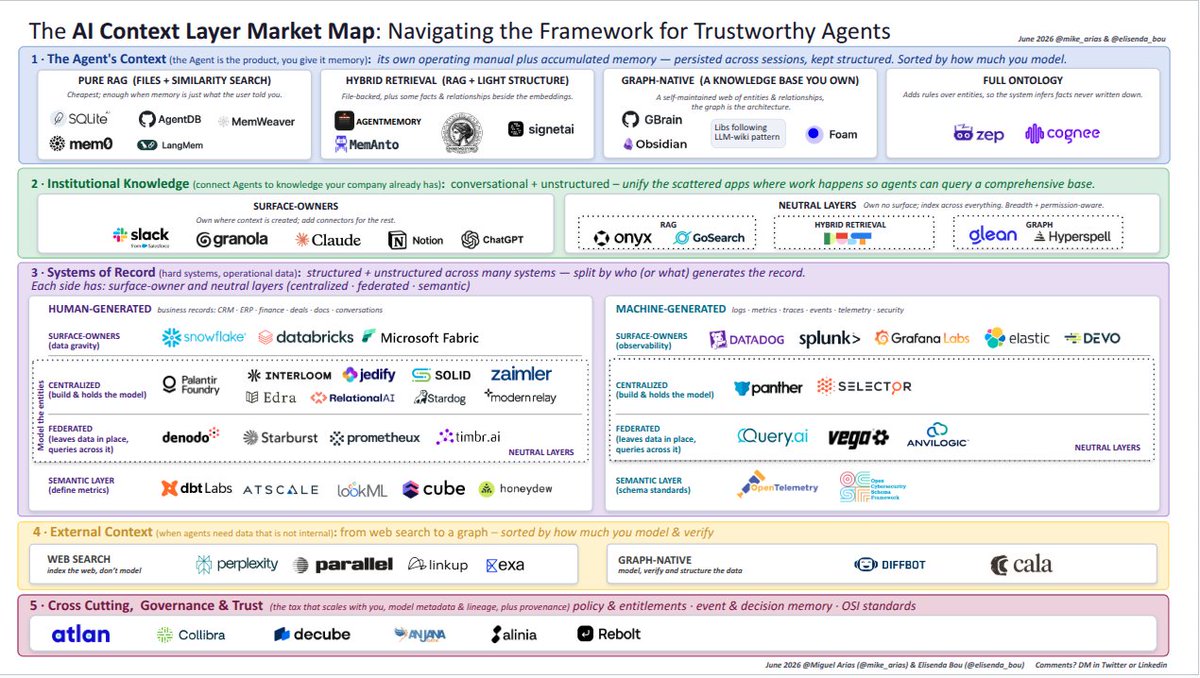
Together with Miguel Arias they consolidated the whole landscape into one map.
The AI Context Layer Market Map lays out the entire space on a single page:
→ Bucket 1: the agent's context. Its own memory and operating manual, sorted by how much you model: pure RAG → hybrid → graph-native → full ontology.
→ Bucket 2: institutional knowledge. The scattered docs, chats and tickets your company already lives in. Surface-owners (who own where work happens) vs. neutral layers (who index across everything).
→ Bucket 3: systems of record. The hard operational data, split by who (or what) generates it: human-generated business records and machine-generated telemetry. Each side has its surface-owners and its neutral layers: centralized, federated, semantic.
→ Plus the two things that cut across all of it: governance & trust (the tax that scales with you), and the emerging public data context layer (verified facts and data from the world, so agents can query external knowledge).
Caveat: it's not exhaustive and it's a snapshot of a fast-moving space.
Plus, as Tony Seale argues: You Can't Buy Your Own Context
Everyone is suddenly racing to sell you your own context. But a context you can buy is a context your competitors can buy too.
Barely a week passes now without another "context layer", "context graph", or "context foundation" for your AI agents - your organisation's reasoning, its exceptions, its hard-won workarounds, packaged up and ready to plug in.
The whole industry is starting to agree that context is the missing piece. It sounds like precisely what the moment demands. But here is the kicker - it is precisely the thing you cannot just buy.
Your context is not a feature you bolt on. It is your model of your own world - the thing that lets your organisation perceive, predict, and act as a single, coherent entity.
Every system that survives does the same thing: it holds a boundary between itself and the world, and works without pause to keep what's inside coherent against a world that never stops trying to throw it off.
That boundary is the difference between being a system and being a pile of parts. Your connected data, your ontology, your formalised meaning is that boundary.
GraphAI is the category where graph structure stops being passive infrastructure and starts doing active work, shaping what models retrieve, what agents remember, and what machine learning algorithms learn.
State of the Graph is mapping a new frontier: how graphs are being used inside AI systems.
Every AI company needs a context layer. Nobody agrees what that is. linkedin.com/pulse/every-ai-…
The AI Context Layer Market Map linkedin.com/posts/elisendab…
Why You Can't Buy Your Own Context linkedin.com/posts/tonyseale…
GraphAI as the Emerging Frontier on the Graph World Map stateofthegraph.com/2026/04/…
--
The Year of the Graph's Spring 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
yearofthegraph.xyz/newslette…
1
1
10
401

AIが毎朝記憶を失う新人だという前提を、そろそろ捨てる時期に来ている。
コンテキストを渡すだけでは足りない。「何と何がつながっているか」をAI自身が辿れる構造が要る。ここに踏み込んだのが面白い。
3〜5年後、開発現場の主戦場は「プロンプトの工夫」から「トレーサビリティの設計」に移る。
📌 ポイント
- ドキュメントをGraphDBのノード・エッジ化し、要件→仕様→テストの依存を3ホップで辿れる地図にする発想。
- 384次元のローカルモデルで完結させOpenAI APIを使わない。コストと機密の両面で現実解になる。
- この構造化思考は建築のBIM
1
1
31

My day 1 verdict.
- Claude Fable 5 is token hungry even on low effort. I expected this tbh and i think thats just tommoz reality as they'll tweak the recipe more and more towards pushing you all to Usage Credits. That IPO will make certain the free ride is over.
- Mythos was able to one-shot a water problem that every single model utterly has failed over the past 2 weeks. It's a very complex problem I gave it and I fully expected it to fail as well. It nailed the water shader/liquid volume in one shot.
- Its security audit is meh. tbh I gave it a same set of tasks for work on security. GPT 5, Opus 4.8, Grok and now Mythos pretty much did the same things. Each had their own little spin on it, but it failed to pickup on obvious glaring security problems that I deliberately laid out for it. Weirdly Grok Composer 2.5 was probably the closest to figuring it out after 3 prompt cycles.
- Its slow af but its plan -> iterate cycle seems to have less prompt cycles. Like you take a hit up front on consumption issues for the pre-start phase, but you end up spending less iteration cycles to nudge it back into place.
- It will absolutely drift architecturally each cycle it goes through. No matter how much safe guards you put in place, this thing will buck the guard rails fast. I have a combination for example in .NET Roslyn Analyzers and Graphdb pattern rejection bash scripts that push the models to behave. This thing blew straight past those and gamed them. Impressive it knew how to work around them, unimpressed it ignored the warning signs.
- As @ThePrimeagen pointed out. It will create more tests than code to solve a problem. I forbid it to run or write unit tests to see if that was true. Sure enough it ignored that rule and apologised after the fact.
- All models so far write shit C code. Like the type of code you'd grab a junior dev and say "ok champ, lets talk about pointers and how you use them". Even when you point out the C hygiene issues that I'd never let a dev get passed me in a PR, this thing is no different. Could be a language issue or training problem maybe.
- Rust code it pretty much gets right first go, I will admit it seems to eat up rust code well. Doesn't pump out as much token usage with this either. I had it write several prompts in several languages to compare, and it the token usage on Rust seems to be the lowest...
- It nails voxel composition well. I feed it a simple screenshot of pixelart scene and said voxelize it.. wasn't half bad... tbh I am tempted to keep some of this for reals...
Is it an upgrade from the rest of the models. I'm gonna give it 8 spuds out of 10 in the Potato Spud scoring system.
The downside is... I know this is the first bait-n-switch model @AnthropicAI has lined up for us to push towards Credit Usage now.
Sad....
1
6
794
import all that data into a graphdb, tbh you're sitting on a signal vs noise ratio sentiment gold mine if you're scraping that much ..especially if each account has been vetted for echo bot vs human..
All those influencer insecurity hunger "who followed me who unfollowed me and why"
1
18
Building a value-driven Enterprise Knowledge Graph at Rabobank: From foundations to adoption
In large enterprises like Rabobank, customer data is often fragmented across systems, making it difficult to gain a unified view of customer relationships, product interaction, and potential business risks. This fragmentation limits operational efficiency, regulatory compliance, and the ability to deliver personalized services.
To address this, we developed an Enterprise Knowledge Graph (EKG) that connects siloed data into a single, coherent Global Customer View, accessible across the organization and integrated with Data & Analytics Platforms. The solution is making real business impact across the enterprise in domains like Know Your Customer (KYC), business lending and more.
We share our practical approach for:
Designing a Minimum Viable Graph to deliver early value
Transitioning from full to incremental data loads
The need for performing entity matching / resolution
Driving adoption by integrating the EKG into existing tools and workflows
How GenAI helped to accelerate the need for Enterprise Knowledge Graphs
This talk is for business and technical professionals at a beginner to intermediate level who are exploring how to build or scale knowledge graphs in complex environments. No prior graph experience is required, but familiarity with enterprise data challenges will be helpful. The case is relevant in and outside of the financial services / banking industry.
Attendees walk away with a clear understanding of how to approach knowledge graph development in a large organization, from initial design to enterprise-wide adoption.
Link to talk: 2025.connected-data.london/t…
--
Colin van Lieshout. Solution Architect, Rabobank
Colin is a pragmatic and visionary Solution Architect, driving the adoption and scaling of graph technology at Rabobank.
Stijn Oude Elferink. Product Manager, Rabobank
Stijn is a curious Product Manager who has been responsible for the Knowledge Graph strategy in Rabobank.
--
Welcome to Connected Data London's #TeaserTuesday
Every Tuesday, we share teasers from #CDL25 on our channels
Connected Data London 2025 brought together leaders and innovators. Were you there?
🎥 Watch the sessions: 2025.connected-data.london/
📩 Join the community: connected-data.london
Tune in and learn from leaders and innovators; subscribe and watch premieres as they are released!
Join community legends and new voices in #CDL25 for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
1
148
Atlassian Teamwork Graph: The Secret Weapon That's No Longer a Secret
Atlassian has expanded Teamwork Graph from an internal product feature into a programmable developer platform — and the connected work implications are significant.
Teamwork Graph unifies data across Atlassian and 100 popular apps. It collects your work, pages, ideas, service requests, projects, and more. The promise:
Maximize your data’s potential effortlessly, intelligently connect any team, work, and app on a single platform with Teamwork Graph.
At Team '26, Atlassian announced general availability of Teamwork Graph Connectors via Forge, an open beta of the Teamwork Graph CLI with 300 commands, and two new Rovo MCP Server tools that expose graph context to external AI agents.
The Teamwork Graph contains more than 150 billion objects and relationships across Jira, Confluence, Bitbucket, Loom, JSM, and 75 third-party tools including GitHub, Google Docs, and Figma — all accessible via single authentication.
But here's what matters for connected work: the graph doesn't just connect things, it understands the relationships between people, projects, documents, and decisions. When it's working, the system knows what you're trying to do. Context shows up where it's needed — without switching tools, chasing context, or stitching together fragments from a dozen sources.
As Mitch Ashley of Futurum observes: context stops being an internal feature of someone else's product and becomes addressable infrastructure. A marketer asking Rovo, a developer asking Claude Code, and a Jira incident agent examining the codebase all read from one graph. Answers stay consistent. The audit trail collapses into a single boundary.
Grounding agent responses in Teamwork Graph data delivered 44% more accurate results while using 48% fewer tokens in internal benchmarks. Mercedes-Benz reports a 10x increase in software delivery speed after building custom Forge connectors against the graph.
AI isn't the magic here — it's the multiplier. The real transformation happens when connected data and consistent ways of working let AI act like a teammate, not just a tool.
By Mitch Ashley (Futurum)
Atlassian Teamwork Graph atlassian.com/platform/teamw…
Atlassian Teamwork Graph: The context engine behind your AI—everywhere atlassian.com/blog/company-n…
Atlassian Teamwork Graph: The Secret Weapon That’s No Longer a Secret futurumgroup.com/insights/at…
#ConnectedWork #EnterpriseAI #GraphData #AgenticAI
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open.
connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

1
1
8
427
Context Graphs are a convergence, and convergence needs architecture
Charles Betz of Forrester Research published a piece titled "Context Graphs Are a Convergence, Not an Invention", and it deserves to be read widely.
Having a VP-level analyst at a major research firm put it in writing, with the historical inventory to back it up, is genuinely significant. It signals that this conversation has moved from the practitioner fringe into the mainstream enterprise consciousness.
Betz traces the lineage back 40 years: Zachman's enterprise architecture framework in 1987, the ITIL push for configuration management databases in the 1990s, APM in the early 2000s, process mining, ChatOps, organisational network analysis, FinOps, software bills of materials, and architecture decision records.
His central observation: none of these systems talk to each other, and the convergence the VC community is declaring as a greenfield opportunity is in fact the long-overdue integration of work that's been accumulating in silos for four decades.
Kurt Cagle extends the argument, identifying three structural gaps that "context graph" as a term does not resolve:
The entity resolution gap -- a flat context graph doesn't solve it. You need a formal registration mechanism: a way to declare that an entity exists, give it a canonical identifier, and establish that the various local identifiers in legacy systems refer to it.
The events-versus-state gap -- process mining logs and APM traces are event records. CMDBs and EA capability maps are state records. Conflating the two in a single knowledge graph doesn't unify them; it obscures the distinction that makes each useful.
The governance gap -- "Who owns this graph?" is actually several questions at once. Governance has to be built into the architecture itself, not answered after the fact.
The proposed answer is holonic architecture -- a unit that has stable, dereferenceable identity, a formal separation between infrastructure layer and payload, a machine-enforceable boundary, and governed, audited portals between domains. The W3C RDF stack (RDF 1.2, OWL 2, SHACL 1.2, SPARQL 1.2) is the only implementation substrate that arrives vendor-neutral, with formal semantics and decades of standardisation behind it.
The question before the context graph community is whether the convergence happens as a coherent, formally specified, openly governed architecture -- or as a collection of incompatible vendor implementations, each claiming to be the "system of record for decisions," none of them able to talk to the others.
The map is not the territory. But a good map needs more than a title; it needs a cartographic system.
By Kurt Cagle
linkedin.com/pulse/context-g…
#EnterpriseArchitecture #SemanticWeb #ContextGraphs #OpenStandards
--
Join the Conversation
Subscribe to the Year of the Graph newsletter for quarterly insights on #KnowledgeGraphs, #GraphDB, Graph #Analytics, #AI, #DataScience and #SemTech .
📧 Subscribe: yearofthegraph.xyz/newslette…
💼 Sponsorship inquiries: yearofthegraph.xyz/contact/

2
8
272
Context Graph: How Organizations Use LLMs Cost-Effectively
Large organizations want to use large language models (LLMs) to answer questions and generate accurate content, but the models themselves know nothing about the organization. The missing piece is context — the right slice of enterprise knowledge, delivered into the prompt at the right moment, in the fewest tokens.
This book is about context graphs: enterprise graph data structures designed to assemble that compact, high-value context. Context graphs are structured, persistent records of product data, customer data, ontologies, and decision traces — capturing not just what happened inside an enterprise, but why it happened, who approved it, and which precedents justified it.
The focus throughout the book is token efficiency and quality of content returned from an LLM. Every modeling decision, retrieval pattern, and architectural choice is evaluated against that pair of constraints.
This textbook is written for three overlapping groups:
Enterprise architects and senior engineers designing AI-powered systems who need a principled approach to organizational memory and context management.
AI/ML practitioners and data engineers building LLM-powered applications and struggling with hallucinations, missing context, and poor decision quality in agent workflows.
Technical product managers and founders building or evaluating products in the enterprise AI space who want a framework for where context graphs create durable competitive advantage.
The book assumes comfort reading technical content and some exposure to software systems. It does not require a deep background in machine learning or graph databases — knowledge graphs, labeled property graphs, and formal ontologies are all introduced from first principles.
The most expensive problem in enterprise AI is no longer the model — it is the context the model is given. Large language models can summarize, reason, and draft fluent text, but only when they are handed the right organizational knowledge at the right moment.
Today most organizations solve that problem one prompt at a time, stuffing whatever they can fit into a context window and hoping for the best. There is no canonical reference for the discipline that should sit underneath those prompts. This book exists to define that discipline and to give practitioners a working blueprint.
The opportunity is genuinely large:
McKinsey estimates generative AI could add $2.6 to $4.4 trillion in value annually across industries — but the majority of enterprise deployments remain stuck in pilot stages, blocked by hallucinations, missing context, and brittle integrations.
Foundation Capital's analysis of the AI market frames the trillion-dollar enterprise opportunity not as building better foundation models, but as solving the context problem — giving models the right organizational knowledge at the moment of decision.
Gartner predicts that over 40% of agentic AI projects will be cancelled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls — failure modes that largely trace back to missing or unreliable context.
The Stanford AI Index reports that enterprise generative AI adoption has crossed a majority threshold, yet only a small fraction of organizations report consistent, production-grade results — a gap that reflects the missing layer of persistent, structured context.
The literature gap is the reason for this book:
Context graphs as a discipline sit between three mature fields — knowledge graphs, retrieval-augmented generation (RAG), and process mining — but no widely available textbook treats them as a unified practice. Practitioners building this layer today usually stitch together blog posts, vendor documentation, and trial-and-error.
Context graphs deserve a foundational text, and this book aims to become a pillar reference that future books, courses, and products build on.
What makes this book different:
Most books on enterprise AI stop at architectural sketches or vendor walkthroughs. This one is built on a validated learning graph of 496 interconnected concepts organized into 12 taxonomy categories, introduced across 22 chapters in strict prerequisite order so the ideas compound rather than collide.
It pairs an extensive background on graph fundamentals, semantic layers, metadata standards, and decision traces with precise, queryable graph models — schemas you can implement and query directly, not just diagrams to admire.
The entire textbook is open source and free — no paywalls, no access codes, no subscription — because a foundational discipline needs an accessible foundational reference.
By Dan McCreary
dmccreary.github.io/context-…
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open.
connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

6
3
27
1,759
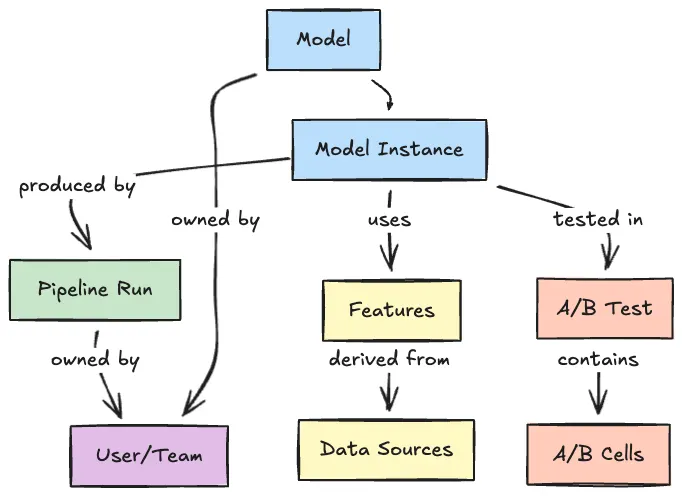
Democratizing Machine Learning at Netflix: Building the Model Lifecycle Graph
When Netflix began investing in ML over a decade ago, it was focused on a single domain: personalization. Today, ML runs across personalization, studio, payments, ads, and more, each with its own tech stack, metrics, and org structure.
That growth introduced a new challenge: enabling cross-pollination of models and data across domains.
Without any discovery infrastructure, ML practitioners couldn't easily collaborate or share work across business verticals. Their tools existed in silos. The model registry was unaware of which A/B tests were using its models. The pipeline orchestrator was unaware of downstream model dependencies.
Consider content embeddings: Studio teams created sophisticated embeddings for production workflows that could also be valuable for Ads (context matching) and Personalization (recommendations). Making that cross-pollination happen was extraordinarily difficult.
The Netflix team's answer was the Metadata Service (MDS), which builds a Model Lifecycle Graph that indexes and connects ML-related entities across the company, including models, features, pipelines, experiments, and datasets.
The graph answers cross-domain questions such as "Which experiments are running this model?" or "Which models share these features?"
It was designed to make every ML asset at Netflix discoverable, understandable, and reusable by every ML practitioner, regardless of their team or domain.
The architecture flows from event ingestion (via Kafka and AWS SNS/SQS) through entity enrichment, normalization, and storage in Datomic (for graph traversals) and Elasticsearch (for full-text discovery). Background enrichment jobs then walk the graph to infer relationships that no single source system could see on its own.
The result: a query that once required manual checks across four separate systems (model registry, pipeline orchestrator, experimentation platform) is now a single graph traversal.
By Saish Sali, Nipun Kumar, Sura Elamurugu
netflixtechblog.com/democrat…
#MLOps #MachineLearning #DataEngineering #DataLineage
--
The Year of the Graph's Spring 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
yearofthegraph.xyz/newslette…
1
9
483

Jun 7
仕様詰めを先にやる大切さは実感してたけど、ドキュメント同士の関係性をGraphDBで管理してAIが自分で辿れる状態にする発想なかったです!
個人プロジェクトでも応用できそう。

個人開発で使っているAI駆動開発のアーキテクチャを公開してみました
- ドキュメントのグラフ化
- GraphRAGとVectorDBのナレッジベース
- 実際に使用する際のAgent Skills & MCP
この辺をまとめてみました
まぁ銀の弾丸はないですが誰かの参考になればいいなと
zenn.dev/abalol/articles/579…
23