
9 Nov 2024
21/25 MediQ: Question-Asking LLMs and a Benchmark for Reliable Interactive Clinical Reasoning
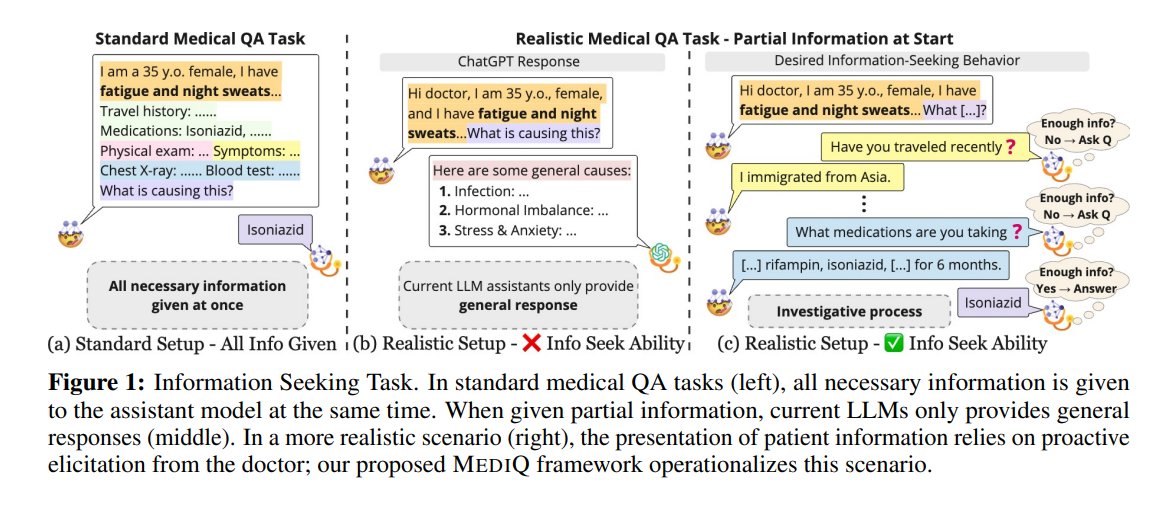
This paper introduces MediQ, an interactive benchmark to evaluate question-asking abilities in LLMs for reliable medical interactions.
It addresses the issue of LLMs answering questions with incomplete information by simulating clinical scenarios where an Expert LLM proactively asks clarifying questions.
Experiments show that prompting LLMs to ask questions is non-trivial, with abstention strategies improving diagnostic accuracy by 22.3% but still lagging behind complete-information scenarios.
#MediQ #MedicalLLM #InteractiveLLM #QuestionAsking #LLMReliability
Paper Link: arxiv.org/abs/2406.00922
2
2
142

9 Feb 2023
We evaluate ChatGPT, a multi-task, multilingual, multi-modal, and multi-turn interactiveLLM for NLP
📄 arxiv.org/abs/2302.04023v1

1
2
189