
Jun 13
🛡️ Reliable AI: Designing for Imperfection — the essential trustworthiness layer that addresses core LLM limitations (inconsistent outputs, poor generalization, vulnerability to attacks) by building resilient, defense-in-depth systems instead of chasing perfect models.
Just read this excellent capstone technical white paper from @aasaitech — a powerful synthesis and finale to the entire series.
Key highlights: • Defense-in-depth architecture: Input guardrails → Retrieval & Grounding (RAG) → Verification & Confidence Scoring → Fallbacks → Human Oversight → Monitoring & Feedback • Mitigation patterns for hallucinations, context mismatch, adversarial inputs, error propagation • Key metrics: Hallucination rate, confidence calibration, OOD performance, human override rate • Industrial focus: Safety-critical manufacturing, maintenance copilots, edge orchestration — where reliability is non-negotiable
Trust is earned through design, not hope. This completes the full journey — turning all prior techniques into truly dependable systems users can rely on.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you designing for reliability in your industrial/edge AI systems — heavy verification layers, confidence-based HITL, or full defense-in-depth with observability?
#ReliableAI #DefenseInDepth #IndustrialAI #AgenticAI #LLMReliability #ManufacturingAI #EdgeAI

4
Jun 13
🛡️ Hallucinations & Output Verification — the critical reliability layer for deploying LLMs in safety-critical industrial environments.
Just read this excellent technical white paper from @aasaitech on why hallucinations happen and how to build multi-layer defenses that actually work in production.
Key highlights: • Multi-layer mitigation framework: Retrieve → Generate → Verify → Refine → Deliver (with continuous feedback) • Core strategies: RAG structured outputs (JSON/Pydantic), tool verification, self-critique & reflection, external fact-checking, human-in-the-loop for high-risk cases • Industrial pipeline example for reliable QA/troubleshooting • Metrics that matter: Hallucination rate, citation coverage, verification pass rate, human escalation rate
This completes the full modern LLM deployment stack — from architecture and scaling to prompting, RAG, agents, multimodal, long context, and now trustworthy outputs you can actually deploy on the factory floor.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you currently mitigating hallucinations in your production systems — heavy RAG, structured outputs tools, or full multi-layer verification pipelines?
#HallucinationMitigation #LLMReliability #IndustrialAI #AgenticAI #SafeAI #EdgeAI
8

What is the charge? Prompt injecting a LLM? A succulent Chipotle LLM?
#AIGuardrails #LLMGuardrails #IntentClassification #LangGraph #AgenticAI #AISafety #LLMReliability #AIArchitecture
linkedin.com/pulse/python-bu…
11
Check out my new article on Explainability for AI Models
Lang* Lineage Layer: Tables, Traces, and Trust
linkedin.com/pulse/lang-line…
#LangGraph #LangFuse #LangChain #LLMObservability #AgenticAI #AISystems #AIArchitecture #LineageTracking #LLMReliability #DeveloperWorkflows
22

Jun 8
🤖 LLMs aren’t minds—they’re fluent chaos. Microsoft should stop shipping “trust me” AI into Windows workflows before it politely invents a fix for the wrong problem.
windowsforum.com/threads/why…
#WindowsIt #AiGovernance #CopilotSafety #LlmReliability

10

为何我持续看好 @miranetwork?因为它正在解决 AI 时代最核心、最棘手的问题之一:可靠性验证。
在 GPT-4o、Claude 这些最强模型仍有 30-40% 幻觉率(hallucination)的大背景下,Mira 提出了一种非常现实、可落地的“验证网络”方案,这在当前浮躁的 AI 场中极其稀缺:
Mira 的价值主张非常明确:
不造模型,而是增强模型的可信度:
它不是和 OpenAI、Anthropic 竞争,而是作为“信任中间层”存在,为所有 LLM 提供外部验证。
已在多个行业实现显著降错率:
某些应用场景错误率从 35% 降至 <5%,个别甚至 10 倍下降——这是硬结果,而不是炒概念。
目标是将 AI 错误率压低至 1% 以下:
一旦实现,AI 将从“演示工具”进化为“可部署的可信基础设施”。
尤其在高风险领域(如自动交易、资金调度):
大模型可以输出交易逻辑、触发指令,但若基础参数是“幻觉”,将带来灾难性后果。
#Mira 构建的验证层,确保所有交易触发、策略决策建立在“真实事实”之上,不是猜测或幻觉,这对于 AI 驱动的交易系统来说,是“从可用到可信”的质变。
在 hype 退潮之后,Mira 留下的是稀缺性:
23 年 Agent 热潮后,许多项目因缺乏实用性和可信度而快速消亡, #Mira 没有追逐炒作,而是选择深耕“可验证性”,这是 AI 真正落地的前提,而这也正是 企业级客户、资本管理系统、链上执行智能合约系统 所共同需求的。
总结:
在 AI 进入“第二曲线”的今天,真正的门槛不是谁能更快输出,而是谁能确保输出是正确的。@miranetwork 就是那个守住真相的人。@MiraNetworkCN @karansirdesai
#MiraNetwork #AIverification #LLMreliability @KaitoAI #Web3AI #TrustedAI #AIxCrypto #KAITO #yap
14 Jun 2025

Even frontier LLMs like GPT-4o and Claude suffer from 30-40% hallucination rates. But how does our verification network solve this fundamental AI reliability problem?
Our Head of Growth, @Stone_gettings, dives into it on the @blockfuel podcast.
Highlights you must watch🧵
183
6
88
23,709

11 Dec 2024
🎯 Excited to moderate a fascinating deep-dive with @RushShahani for @TheOfficialACM, on building trustworthy LLM applications that actually work in production (you know, the part that keeps CTOs up at night 😅)
When your AI demo works perfectly but prod is... let's say "creative" with the truth, this is the conversation you need. While others theorize about AI from their ivory towers, Rush is in the trenches daily as a startup CTO, turning academic papers into solutions that actually ship. He just published a Manning book on LLM Reliability, packed with battle scars and victories from building AI that works in the real world.
🔍 We're diving into:
- Battle-tested strategies for taming hallucinating LLMs
- RAG pipelines that deliver more than just promises
- Building AI agents that your users will actually trust
🎤 As your moderator, I'll be pushing for the real, unfiltered insights beyond the usual AI hype. With 1000 registrants already (and counting!), this is clearly hitting a nerve in the AI community.
📅 Date: Thursday, December 12
🕐 Time: 2:00 PM ET/19:00 UT
P.S. Rush is the CTO of @PersanaAi (YC W23) and has built AI systems at LinkedIn and Shopify.
#AI #MachineLearning #LLMs #ProductionAI #LLMreliability

1
1
6
914

9 Nov 2024
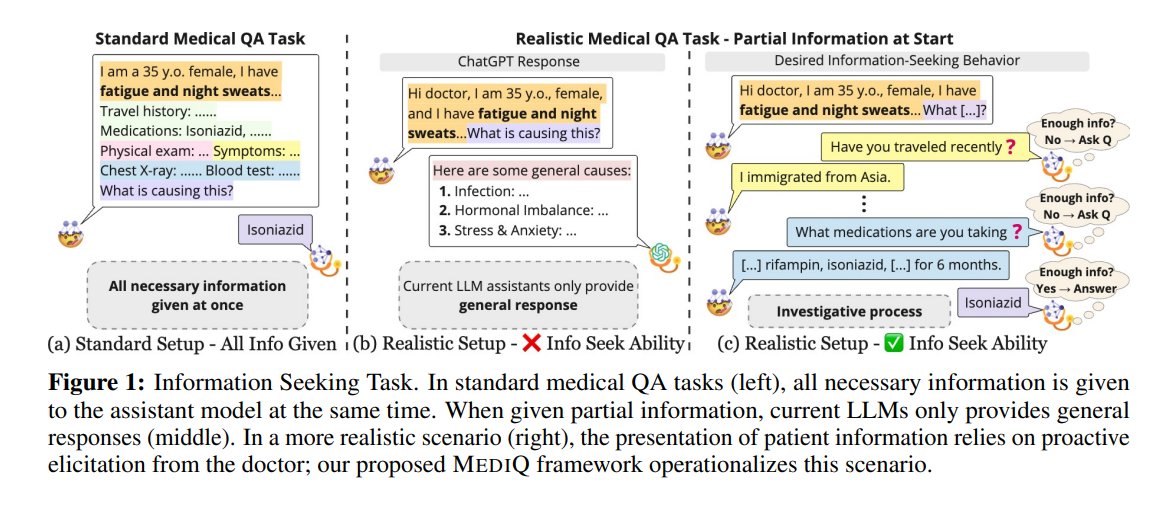
21/25 MediQ: Question-Asking LLMs and a Benchmark for Reliable Interactive Clinical Reasoning
This paper introduces MediQ, an interactive benchmark to evaluate question-asking abilities in LLMs for reliable medical interactions.
It addresses the issue of LLMs answering questions with incomplete information by simulating clinical scenarios where an Expert LLM proactively asks clarifying questions.
Experiments show that prompting LLMs to ask questions is non-trivial, with abstention strategies improving diagnostic accuracy by 22.3% but still lagging behind complete-information scenarios.
#MediQ #MedicalLLM #InteractiveLLM #QuestionAsking #LLMReliability
Paper Link: arxiv.org/abs/2406.00922
2
2
142

6 Jun 2024
งานวิจัยจาก Google: AI โกหก หรือแค่ไม่มั่นใจ? นักวิจัยคิดค้นวิธีใหม่ตรวจสอบได้!
บทความนี้นำเสนอวิธีการใหม่ในการตรวจสอบความน่าเชื่อถือของคำตอบจาก AI แบบจำลองภาษาขนาดใหญ่หรือ LLM (Large Language Model) ซึ่งบางครั้งก็ให้คำตอบที่ผิดหรือหลอกลวง เรียกว่าการเกิด “การสร้างภาพหลอน(Hallucination)" แต่จะรู้ได้อย่างไรว่า AI กำลังโกหก หรือแค่ไม่มั่นใจในคำตอบกันแน่?
นักวิจัยได้พัฒนาวิธีการวัดความไม่แน่นอน (Uncertainty) ในคำตอบของ AI โดยวัด 2 ประเภทคือ ความไม่แน่นอนจากการขาดความรู้ (epistemic uncertainty) และความไม่แน่นอนในกรณีที่มีคำตอบได้หลายแบบ (Aleatoric Uncertainty)
โดยใช้หลักการทางทฤษฎีข้อมูล (Information Theory) เรียกว่า Mutual Information หรือ MI ซึ่งวัดความสัมพันธ์ระหว่างคำตอบที่ได้เมื่อถาม AI ซ้ำ ๆ ด้วยโจทย์และคำตอบก่อนหน้า ถ้า AI ไม่แน่ใจในคำตอบจริง (Epistemic Uncertainty สูง) ค่า MI ที่วัดได้จะต่ำ แสดงว่าคำตอบนั้นไม่น่าเชื่อถือ
ความพิเศษของวิธีการใหม่นี้คือ ใช้ได้ทั้งโจทย์ที่มีคำตอบเดียว และโจทย์ Open-Ended ที่อาจมีคำตอบได้หลายอย่าง ในขณะที่วิธีการเดิม เช่นการดูค่าความน่าจะเป็นของคำตอบ จะใช้ได้ดีแค่กับโจทย์ที่มีคำตอบเดียวเท่านั้น
ผลการทดลองชี้ให้เห็นว่า วิธีนี้สามารถจับ Hallucination ได้ดีกว่าวิธีการแบบเดิมอย่างมีนัยสำคัญ โดยเฉพาะในโจทย์ที่มีหลายคำตอบเป็นไปได้ นับเป็นความก้าวหน้าสำคัญในการทำให้เราใช้งาน AI ได้อย่างไว้วางใจมากขึ้นในอนาคตครับ
แหล่งที่มา: huggingface.co/papers/2406.0…
งานวิจัย: arxiv.org/abs/2406.02543
เอกสารงานวิจัย: arxiv.org/pdf/2406.02543
#AI #LLMs #Google #Research #Hallucination #MutualInformation #EpistemicUncertainty #AleatoricUncertainty #InformationTheory #TrustInAI #LLMReliability

1
55