
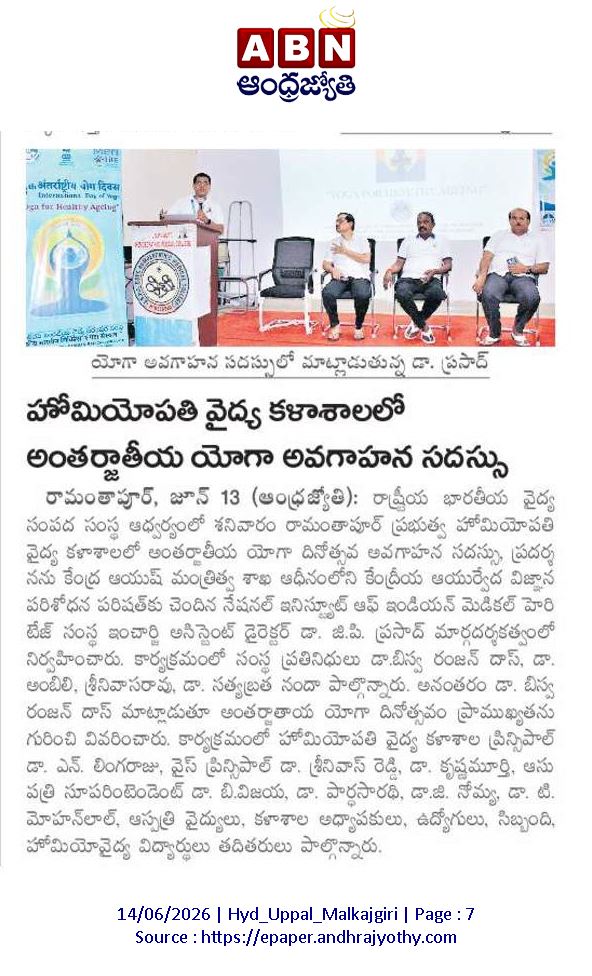
Media coverage of CCRAS-NIIMH Hyderabad: Yoga Awareness Lecture & Common Yoga Protocol (#CYP) demonstration at JSPS Government Homoeopathic Medical College, on 13-6-2026, led by Dr G.P. Prasad, A.D. In-charge, distributed IEC materials & medicinal saplings to faculty & staff.



21

なるほど、恐らくJST/JSPS系と他省庁系の研究開発資金で座組や資財の所在、アクセス基準が異なるのだと思います。例えば科研費で雇用する、企業と連携するなどのケースでは仰る通りです。
2
238

JSPS DC1の2倍払っていて偉すぎるな…

おじさんな、女性比率を上げるためにも、ピチピチの女子大学院生を、500万円で囲おうと思うんだ😘
239
Ministry of Ayush retweeted
🧘♂️ On #IDY2026, CCRAS-NIIMH Hyderabad organized a Yoga Awareness Lecture & Common Yoga Protocol (#CYP) demo at JSPS Govt. Homoeopathic Medical College on 13-6-2026, led by Dr G.P. Prasad, the team distributed IEC materials & medicinal saplings to faculty & staff . @moayush #Yoga




1
1
476

Jun 13
【創価大学】シンガポール経済史に関するワークショップ soka.ac.jp/fila/news_fila/20…
日本学術振興会(JSPS)科学研究費補助金(24K04984)、および創価大学マレーシア研究センター(CMS)の共催。シンガポールおよび東南アジアの経済発展を歴史的視点から再検討。
元MASの創価大学客員教授Choy Keen Meng博士
243
Marie Seki/対馬民俗生態学者 retweeted

Jun 12
【JSPS Monthly(学振便り)】日本学術振興会(JSPS)が月1回配信しているメルマガでは、最新の公募案内やイベント情報等をお届けしています。ぜひご登録ください!
🔗jsps.go.jp/j-mailmagazine/in…
#JSPS

1
9
1,492


2544 TÜBİTAK–JSPS (Japonya) İkili İş Birliği Çağrısı Açıldı tubitak.gov.tr/tr/duyuru/254…
6
2544 TÜBİTAK-JSPS (Japonya) İkili İş Birliği Çağrısı Açıldı tubitak.gov.tr/tr/duyuru/254…
4

自分が知る限り、基本的には雇用関係がないとe-radの研究者番号は貰えない。JSPSも「研究機関に所属する研究者」が科研費の申請資格を有するとしてる。この「所属」をどう解釈するかだですけど、「客員」はふつう所属してないからこそ「客員」と呼ばれているので、科研費申請資格は持てないですね。
Jun 11

【拡散希望】科研費番号を頂ける研究機関に客員研究員として採用して貰えないでしょうか?科研費を獲得して間接経費で所属機関に貢献します。
院生の時点で、サントリー若手、松下、村田、笹川など、民間研究助成を1000万円以上獲得した実績があり、日本語で研究費を獲る腕には自信があります。
1
243
大隅典子 retweeted

Jun 12
6月2日ボン大学にて開催された留学フェアにJSPSのブースを出展しました。
日本での研究滞在に関心の高い学生が多く訪れ、JSPSの学術国際交流事業について直接説明を行いました。
#JSPS #JapanandGermany

Jun 12

On 2nd June, we participated in the International Study and Internship Fair at Universität Bonn.
Many students interested in conducting research in Japan visited our booth, where we provided information about our international exchange programs.

1
3
943

Jun 12
Threat Intel Brief — 2026-06-12
Today’s real signal is ShinyHunters/UNC6240 turning Oracle PeopleSoft into an extortion lane, not a generic “new CVE” story.
GTIG/Mandiant says the group exploited CVE-2026-35273 as a zero-day against Oracle PeopleSoft Environment Management / PSEMHUB infrastructure from May 27–June 9, with more than 100 exposed organizations notified and higher education heavily represented.
Oracle confirms the bug affects PeopleSoft Enterprise PeopleTools 8.61 and 8.62, specifically the Updates Environment Management component. It is remotely exploitable without authentication over HTTP and carries a CVSS 9.8 score.
The interesting wrinkle: FIRST EPSS remains very low, and the CVE does not appear to be in CISA KEV yet. Verify KEV immediately before publishing, but that is exactly why this is worth watching. The defender mistake would be ranking by EPSS alone after credible targeted exploitation has already occurred.
Operational takeaways:
• PeopleSoft shops: apply Oracle mitigation and patch guidance now.
• Disable EMHub or remove PSEMHUB where possible.
• Block external access to /PSEMHUB/* and /PSIGW/HttpListeningConnector where possible.
• Hunt WebLogic / PIA logs for external POSTs to those endpoints.
• Look for unexpected JSPs under PSEMHUB.war.
• Check for suspicious files or directories under PSEMHUB.war/envmetadata/transactions/.
• Review recently created or modified XML files under Environment Management metadata paths.
• Monitor for outbound SMB from PeopleSoft hosts.
• Hunt for MeshCentral activity and azurenetfiles[.]net artifacts.
• Treat matching activity as incident response, not routine vulnerability management.
Forecast / game theory:
• Likely near-term path: extortion pressure and leak-site leverage against already-compromised institutions.
• Plausible next path: copycat scanning once enough technical detail circulates, even if broad exploitation metrics lag.
• Watch for: KEV addition, public PoC, new victim disclosures, reuse of MeshCentral staging, or movement from higher-ed into HR/payroll-heavy enterprises.
Watch item:
ESET’s OceanLotus report is strategically interesting. Vietnam-aligned APT32 appears more domestically focused from 2024–2026, including activity around Vietnamese finance, infrastructure, transport, and politically relevant targets. That is lower immediate defender urgency unless your exposure overlaps Vietnam, regional supply chains, finance, infrastructure, transport, or political targets.
References:
• GTIG/Mandiant: cloud.google.com/blog/topics…
• Oracle advisory: oracle.com/security-alerts/a…
• NVD: nvd.nist.gov/vuln/detail/CVE…
• FIRST EPSS: api.first.org/data/v1/epss?c…
• CISA KEV catalog: cisa.gov/known-exploited-vul…
• ESET OceanLotus: welivesecurity.com/en/eset-r…
#ThreatIntel #CTI #CyberSecurity
1
1
174

Two models. Trained independently, on different data, different tasks. Average their weights, the result should be garbage. Except sometimes it isn't. Why? That's one of the questions Emanuele Rodolà has been attacking, through geometry. And model fusion is just one corner of it, his work stretches across audio, language models, and multimodal learning.
He's the next name on our 10th edition lineup.
Emanuele Rodolà is a Full Professor of Computer Science at Sapienza University of Rome, where he leads the GLADIA AI group. His work in this field has been supported by an ERC grant, a FIS grant, and a Google Research Award. In the past, he was a postdoctoral researcher at USI Lugano (2016–2017), an Alexander von Humboldt Fellow at TU Munich (2013–2016), and a JSPS Research Fellow at the University of Tokyo (2013), in addition to visiting periods at Tel Aviv University, Technion, École Polytechnique, and Stanford. He is a fellow of ELLIS and a fellow of the Young Academy of Europe. Professor Rodolà has received numerous awards for his research and plays an active role in the academic community, serving on program committees and as Area Chair for major conferences in AI and ML. His current research focuses primarily on neural model fusion, representation learning, language models, ML for audio, and multimodal learning, with around 190 publications in these areas. His work has been featured in media outlets including Fortune, Wired, Italian national broadcast and newspapers.
See you in Warsaw for the 10th edition, October 8–10 at the Copernicus Science Centre.

1
4
190
Kosuke Takeuchi retweeted

JSPS科研費「近代日本における貸本屋の所在と蔵書に関する研究」(23K12104)の成果として、『近代貸本屋総覧』を公開しました。随時追加・更新予定です。お気づきの点・情報提供など、お気軽にお知らせください。
🔗researchmap.jp/multidatabase…
53
101
9,285

🇫🇷✈️🇯🇵 L'appel à candidatures PHC SAKURA 2027 est ouvert !
Ce programme franco-japonais soutient les échanges scientifiques et technologiques d'excellence entre laboratoires des deux pays, en favorisant les nouvelles coopérations et la participation des #jeuneschercheurs & #doctorants.
Mis en œuvre par le MEAE, le MESRE et la JSPS, il finance principalement les indemnités de séjour et les voyages des équipes lauréates.
👉 Les équipes françaises peuvent déposer leur dossier sur Campus France.
➡️ campusfrance.org/fr/sakura
📅 Clôture : 3 septembre 2026

3
12
1,021
Jun 12
【学振トピックス】令和8(2026)年5月20日(水)~21日(木)、タイ・バンコクにて、第14回グローバルリサーチカウンシル年次会合が開催されました。
🔗jsps.go.jp/j-topics/2026/061…
#JSPS #JSPSTopics
1
1,118
Jun 12
The 14th Annual Meeting of the Global Research Council (GRC) was held in Bangkok, Thailand, on May 20–21, 2026.
🔗jsps.go.jp/english/e-topics/…
#JSPS #JSPSTopics
1
1,173