
🔗 dx.doi.org/10.21511/ppm.24(2…
📝 A work-applied framework of dynamic resource management in the industrial value chain: Evidence from #Thailand
👥 Kanyarat Sukhawatthanakun, Chatchai Poungsuwan
#dynamicresources #employeeengagement #knowledgeintegration #resourcemanagement
1
23

May 22
🚨 LLMs are frozen after pretraining, but the world keeps changing. How do you give an LLM new knowledge without retraining it, bloating its context, or breaking what it already knows?
Existing methods hit a wall:
🔸 RAG is brittle to retrieval noise and struggles with cross-document reasoning;
🔸 Fine-tuning is expensive and causes catastrophic forgetting;
🔸 Latent memory is tightly coupled to the model that produced it.
👉 Key question: Can we encode knowledge into a small, dedicated memory model that any LLM can query without accessing the LLM itself?
🚀 Introducing MeMo (Memory as a Model) 🚀
We train a dedicated MEMORY model on a reflection Question-Answer dataset synthesized from the target corpus. At inference, a frozen EXECUTIVE model (any LLM, including closed-source models) queries the MEMORY model through a structured 3-stage protocol that decomposes complex queries into targeted sub-queries to retrieve precise, noise-robust knowledge and reasons over the responses.
🔥 Key Highlights
🧠 5-step data synthesis pipeline captures explicit facts, implicit relationships, and cross-document connections as reflections;
🛡️ Robust to retrieval noise: where RAG drops up to 6.22% with added distractors, MeMo holds steady;
🔌 Plug-and-play with any LLM, no weights, gradients, or logits required;
📦 Fixed inference cost, independent of corpus size;
🔄 Continual integration via model merging: 33% compute savings over full retraining and scaling benefits grow with the number of corpora.
📊 Strong results across BrowseComp-Plus, NarrativeQA, and MuSiQue, matching or outperforming retrieval baselines (BM25, NV-Embed-V2, HippoRAG2) with gains of up to 27% on NarrativeQA when paired with Gemini-3-Flash.
💡 Why this matters
MeMo decouples knowledge from reasoning: Train memory once with a small open model, then plug it into the frontier LLM of your choice. No retraining as new corpora arrive, no fragile retrieval pipelines, and full compatibility with proprietary APIs, paving the way for scalable knowledge-aware AI systems.
🤝 Joint work with @workryanq_nus, @961014dltkdg, @alfredleongwl, Alok Prakash, Nancy F. Chen, @arun_v3rma, Daniela Rus, and Armando Solar-Lezama
📄 Paper: arxiv.org/abs/2605.15156
💻 Code: github.com/arunv3rma/MeMo
🌐 Project page: arunv3rma.github.io/blogs/me…
🤗 Huggingface: huggingface.co/collections/G…
#LLMs #KnowledgeIntegration #MemoryAugmentedLLMs #RAG #ModelMerging


// Memory as a Model //
The paper augments any LLM with a separate trained memory model that stores, retrieves, and integrates facts on its behalf.
It decouples memory updates from base-model weight updates. It achieves continual-learning robustness without catastrophic forgetting, which is a property that RAG fails to deliver.
A vector store is a database with a learned encoder bolted on. MeMo is a learned subsystem with explicit interfaces. That distinction matters, as agents need to be able to ingest fresh knowledge weekly without retraining or vector-DB churn.
At its core, the position here is that memory in agents should be modular, learned, and gated, not a context-window hack.
Paper: arxiv.org/abs/2605.15156
Learn to build effective AI agents in our academy: academy.dair.ai/

1
19
2,860

Apr 7
The @ResearchBrc is pleased to share that its recent MoU with @iitbbs has received extensive media coverage across leading newspapers and major digital platforms. The development has also been highlighted through IIT Bhubaneswar’s official communication channels.
This response underscores the increasing academic relevance of interdisciplinary collaborations that integrate Indian Knowledge Systems within contemporary research frameworks. Such initiatives open new avenues for meaningful engagement between traditional śāstric wisdom and modern scholarship.
We remain grateful for the continued guidance of our mentors and well-wishers as we strive to advance the mission of śāstra-sevā in academic contexts.
🔗 For more activities of BRC, visit:
brcglobal.org/
#BhaktivedantaResearchCenter #IITBhubaneswar #AcademicCollaboration #ResearchImpact #IndianKnowledgeSystems #SastraSeva #VedicStudies #HigherEducation #KnowledgeIntegration


2
12
501

4 Dec 2025
The next wave of AI apps won’t be single-model prompts they’ll be full pipelines: knowledge retrieval, tool calls, autonomous actions, streaming output, multi-agent flows.
And @miranetwork is giving developers the toolbox to build all of that with just a few lines of Python.
From simple chatbots to complex orchestration layers, the future of AI engineering is composable.
#MiraNetwork #FlowsSDK #AIEngineers #MultiModel #AIOrchestration #PythonDevelopers #AITools #KnowledgeIntegration #FutureOfAI @wallchain

1
2
50

20 Nov 2025
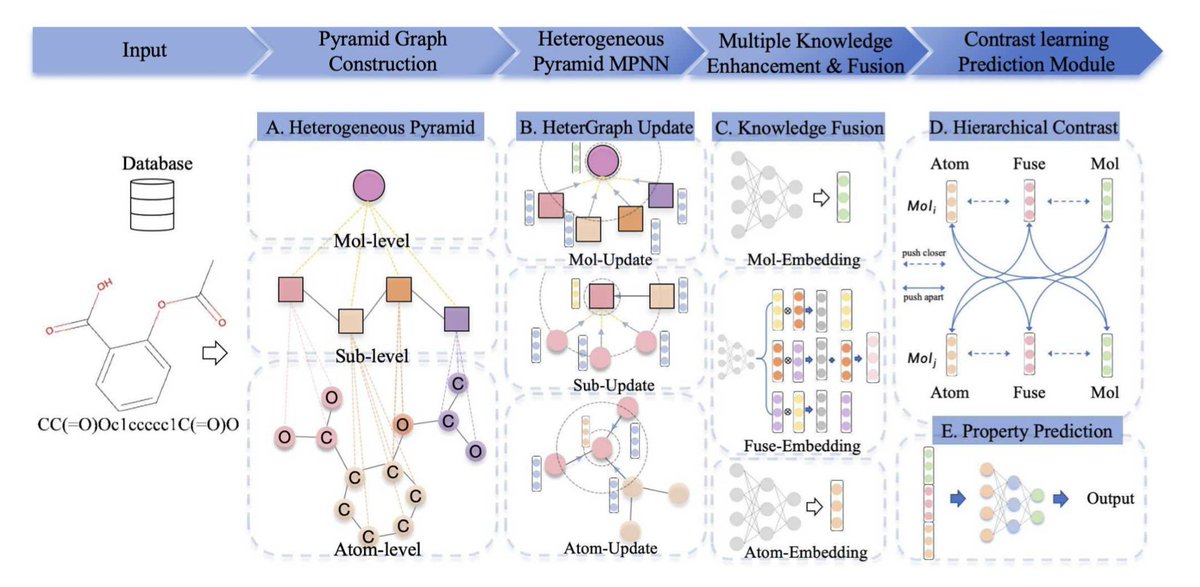
PyrMol: A Knowledge-Structured Pyramid Graph Framework for Generalizable Molecular Property Prediction
1. PyrMol introduces a novel pyramid graph framework that integrates multiple chemical expertise into graph neural networks (GNNs) to enhance molecular property prediction. This approach constructs heterogeneous pyramid molecular graphs across atomic, subgraph, and molecular levels, guided by functional groups, pharmacophores, and reaction-derived fragments.
2. The framework features a multi-source knowledge fusion module that adaptively aggregates heterogeneous subgraph signals. This module balances redundancy and complementarity of knowledge, significantly improving model generalization across diverse biochemical tasks.
3. PyrMol employs a hierarchical contrastive learning strategy to align representations across scales, enhancing discrimination and consistency. This method consistently outperforms 12 state-of-the-art baselines across 10 public benchmarks, including advanced subgraph-enhanced architectures and leading pretraining models.
4. The pyramid graph structure in PyrMol enables hierarchical message passing, capturing multi-scale topological information. This structured approach not only boosts performance but also demonstrates plug-and-play versatility when integrated into existing GNNs, yielding universal performance gains.
5. The study highlights the importance of incorporating structured domain knowledge into molecular AI. PyrMol's ability to focus on key substructures and atoms within molecules provides valuable insights for molecular optimization and drug discovery.
📜Paper: biorxiv.org/content/10.1101/…
#MolecularPropertyPrediction #GraphNeuralNetworks #KnowledgeIntegration #DrugDiscovery #AIinChemistry
3
669

11 Jul 2025
Hello everyone, I'm making this post, to get your help!
Governments and Third parties are trying hard to steal from my Thesis, and from my hard working job. My thesis is a deep dive into the cosmos, into information theory, the electron and cybersecurity...
Help my voice get heard. before my hard worked thesis disappears... help me! I beg everyone of you to download my thesis from ZENODO! help! @CastellaniMatte
#UnifiedTheory #InterdisciplinaryResearch #FundamentalScience #CosmicConnections #TheoreticalFrameworks #ScientificSynthesis #AppliedPhilosophy #KnowledgeIntegration #BeyondDisciplines #InnovationInThought
zenodo.org/records/15854629
4
276

21 Sep 2024
🔴Live #WOHC2024 🌠Fantastic discussion on the wider complexities of #OneHealth #Ethics #Gender #Indigenous #KnowledgeIntegration & collaboration across disciplines between @FAO @UNEP @ILRI @CGIAR @uwsomwwami @UPTuks @SwissTPH

1
3
205

24 Aug 2024
6/8 The results highlight the need for more effective integration of external knowledge and reasoning mechanisms in LLMs to enhance their performance in real-world biomedical applications. #AIinHealthcare #KnowledgeIntegration
1
1
184

22 Aug 2024
📢Присоединяйтесь к бесплатному онлайн вебинару от к.ю.н. Яхина Филюса о современной Исламской психологии и ее ответах на сегодняшние вызовы.
⏰ 25.08.2024, 18.00 GMT 3, Стамбул
📌Регистр.: forms.gle/HEv9pgTzL7bwAmz26
#islam #islamicstudies #knowledgeintegration #ikiacademy

2
19

11 Dec 2023
i2Insights brings together work that might not otherwise meet, such as conceptual & methodological tools for #knowledgeintegration (from #interdisciplinarity & #transdisciplinarity) & for #knowledgesynthesis (from education). Read more at i2insights.org/2023/12/12/ei….
#I2Sresources
1
7
510

3 Nov 2023
Excited to hear @UWaterloo BKI alum @SamuelPetrie talking about the need for more knowledge integrators to help address Canada’s health care crisis. #KnowledgeIntegration

ALT PowerPoint slide with presentation title, “Health System Impact: Being a Generalist in a Specialized World” by Sam Petrie, PhD
2
1
6
294

19 May 2023
COSBI's #ScientificAdvisoryBoard: Day 2: #knowledgeintegration, multiscale #modeling, #PBPK and #QSP modeling - the avant-garde of research
@CIBIO_UniTrento @UniTrento @HIT_trentino @Unipisa
#Axcella @Roche

2
4
204

11 Jan 2023
At a two-day @NSF funded #TeamScience workshop organized by @vaseagrant on #resilience in coastal communities of Hampton, Virginia. Excellent opportunity for #knowledgeintegration and #transdisciplinary #capacitybuilding, while developing my ideas on #publichealth in this area.

1
11
886

Due to its centrality to global environments, economy, & society, should a platform for the #ocean like @IPCC_CH & @IPBES be set up? Gaill et al. propose the International Panel for Ocean Sustainability re #KnowledgeIntegration for #OceanScience policy doi.org/10.1038/s44183-022-0…

ALT Title, authors’ names, and abstract of an article proposing an international panel for ocean sustainability. Text: An evolution towards scientific consensus for a sustainable ocean future.
1
2
253
29 Jul 2022
Community engagement in international research needs: 3) processes to support #knowledgeintegration as integration is an explicit task that doesn’t just happen if you put people together i2insights.org/2022/07/26/co…
@RachelKelly___ @hengenlang @Fostino21
3
6

2 Jul 2022
Here our newest work. Unveiling the transformative capabilities of Mexico #SDG #RESPOL #KnowledgeIntegration @MatiasRamirez50 @OscarYRomeroG1 @Johan_Schot reader.elsevier.com/reader/s…
1
8



20 Jan 2022
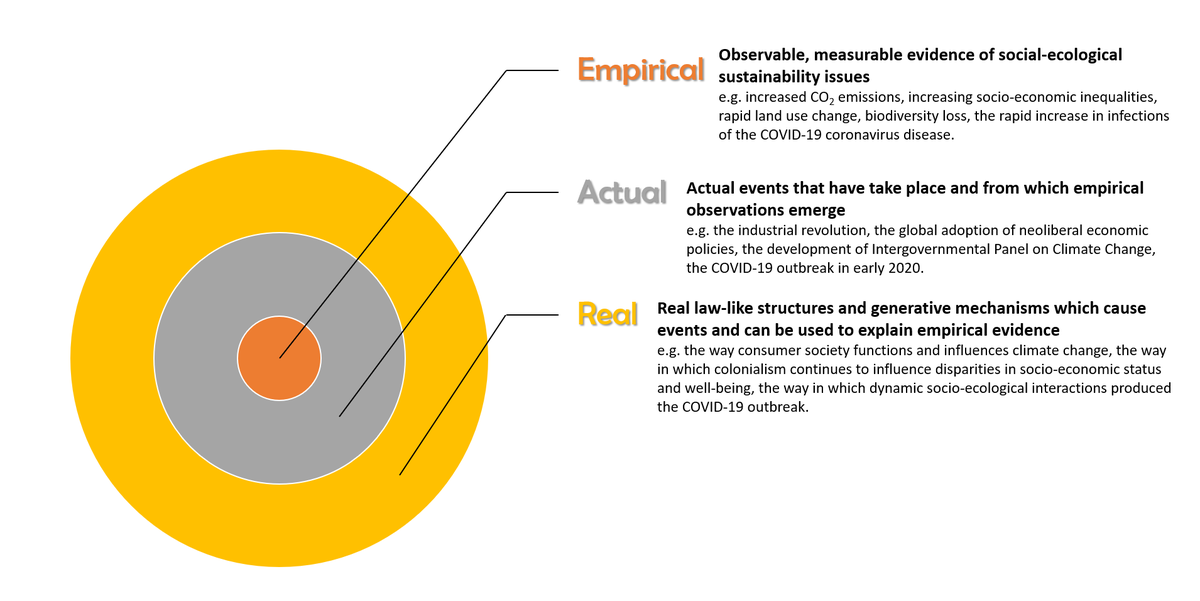
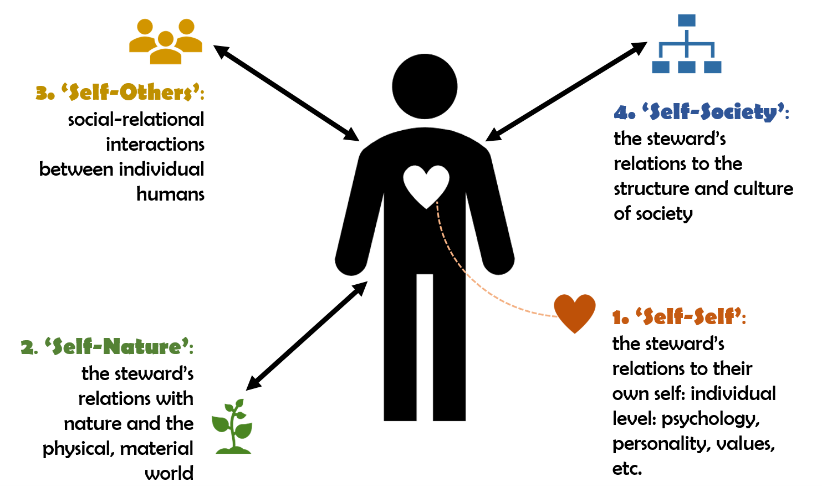
So what does #criticalrealism have to do with #sustainabilitysciene or #transdisciplinarity? Here I explore some of the methodological and conceptual tools from CR that can help with the long-standing challenge of #knowledgeintegration in TD research onlinelibrary.wiley.com/doi/…
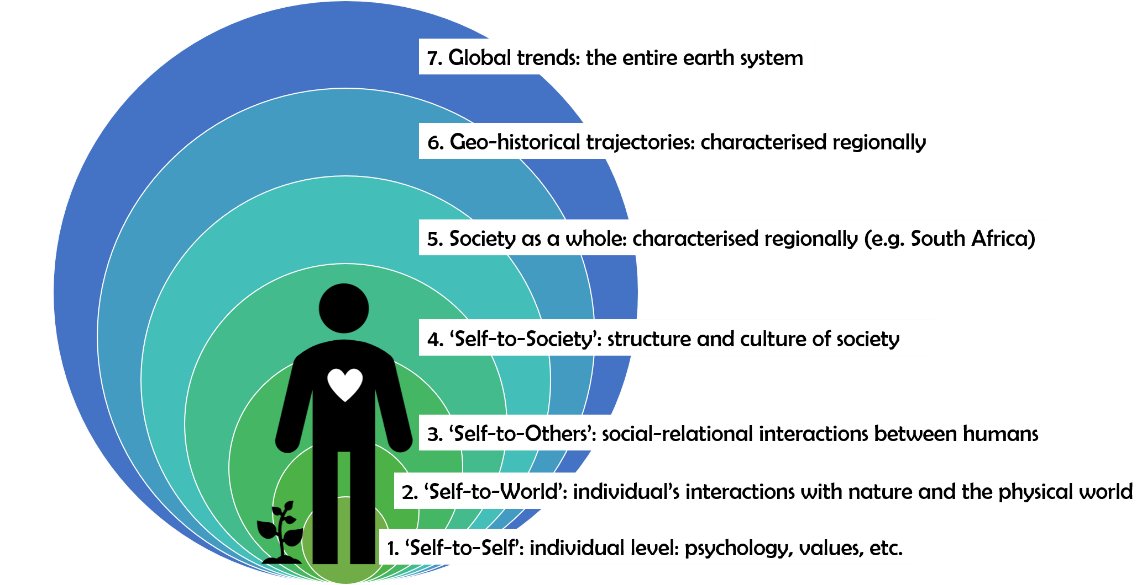
2
18
38

18 Jan 2022
Wir unterstützen @Transfair_AT im Stakeholder Prozess (#knowledgeintegration) und mit unserer Expertise in der #Modellierung. Aktuelle Publikationen beschäftigten sich mit #Klimaschutz & #Energiewende: doi.org/10.3390/en12081584 & epub.oeaw.ac.at/?arp=0x003b2… (2/2)
1
3

24 Nov 2021
A big thank you to all the participants who contributed to our Forum yesterday and a special thanks to Sabine Hoffmann @EawagResearch who shared her experience and perspective as integration expert
#sustainabilityscience #transdisciplinarity #knowledgeintegration #webinar
1
1