
loretta lynn 最終予選
🗺️ Hangtown MX
woman's
moto1:1位 moto2:1位 総合1位
250C
moto1:14位 moto2:13位 総合14位
woman's クラスは決勝への切符GETできました!🎫
#LLMX



3
16
175
5,872


Jun 9
将来アプリというものが無くなるのか無くならないのか。アプリを開発すること自体はどんどん安価していくが人と物事のインターフェースがどうなるか。プロンプト(会話でのコミュニケーション)は残りそうだけど、他のコミュニケーションはどうなるのか?
#LLMx哲学 #LLMxPhilosophy
3
55

What a weekend at High Point Raceway 🏁
Thank you to everyone, the racers, the families and the staff for letting us be a part of your #RoadToLorettas
Were excited to see the whole process 💪
📸 @_hyperfocusimages @lorettalynnmx #LLMX #HighPointMX




5
82

Happy Memorial Day from all of us at @lorettalynnmx 🫡🇺🇸
Here’s to all the men and women that gave their lives for us #HappyMemorialDay #LLMX

3
7
452
Motocross at its core 🔥
The racing has only just begun at the @lorettalynnmx Northeast Area Qualifier here at High Point MX ➡️ Who’s ready for more racing⁉️
📸 @_hyperfocusimages @racerxonline #LLMX #HighPointRaceway




1
11
268
Checking in from High Point Raceway 🏁
Weather is part of it and that’s not stopping the battles on track 💪
📲 @mitchy_the_kiddd @racerxonline @lorettalynnmx #LLMX #HighPointMX




1
11
575
It’s time to go racing‼️
Are you ready for @lorettalynnmx ➡️ Follow along this weekend with our Northeast Area Qualifier here at High Point Raceway 🏁
📸 @_hyperfocusimages @lorettalynnmx #LLMX #HighPointMX




1
7
97
Attention Racers 🚨 Registration will remain open until Tuesday at 12pm EST Southwest Amatuer/Youth Regional Championship at @foxraceway The extension is to better accommodate riders that attended the area qualifier this past weekend in New Mexico.
Link in the bio 🔗 #LLMX

11
521
Happy Mothers Day 💕 We can’t do this without you‼️ We’re wishing you all a very happy Mother’s Day to all the mom and all that you do 🏆
#LLMX




8
476
We couldn’t be more proud of @kenroczen94 💪
Congratulations Ken Roczen your 2026 Monster Energy Supercross Champion 🏆
📸 @align.with.us @supercrosslive #LLMX




1
25
314
5,012
Get ready for the 2026 Loretta Lynn’s Northeast Area Qualifier ➡️ Mark your calendars May 21-24 2026 and join us at High Point Raceway 🏁
@lorettalynnmx
For more information please visit the link in our bio 🔗 #LLMX #HighPointMX

1
4
441
The 2026 Loretta Lynn’s Area Qualifiers are rolling right along 💪
Make sure you visit the link in our bio and get registered for Regional Championships 🔗 #LLMX




8
476
Rupert MX to Host ONE DAY Northwest Area Qualifier on May 3 🏁
Check the link in our bio for more information and updates to the Area Qualifiers and Regional Championships schedule 🏆 #LLMX
🔗 mxsports.com/2026/04/21/comp…

13
551
Congratulations to your 2x 250 West @supercrosslive Champion Haiden Deegan 🏆 @dangerboydeegan
Champions are made here 💪
📸 @align.with.us @supercrosslive #LLMX




1
49
1,750

Apr 2
名前を出していただきありがとうございます‼️
LLMx機械設計の話、6月に設計工学会で講演することになったので、ちょうどいま急ピッチで色々試してる所でした🤯
また何か面白いネタあれば、共有してください🤣笑
1
5
383
We love to see your journey 🏁 The #RoadToLorettas is in full swing with Area Qualifiers happening all over the country 🤘
Tag @lorettalynnmx and use hashtags #LLMX and #RoadToLorettas this season and we’ll this summer at the ranch 🏆




9
426
遅くなってごめんなさい💦🙏
episode7 ロレッタ決勝アップしました!✨✨
youtu.be/MTe3gOUDV6c?si=jhbr…
一週間行われたロレッタのレース😢😢
パドック設営から受付、練習そしてレース。長かったような短かったような1週間!
#本田七海 #llmx

1
8
69
9,097
The Area Qualifiers are only hitting up 🔥 Spring is getting closer and more chances to qualify for Regionals 🎟️
Make sure you plan and register online at MXSports.com 📲 #LLMX #RoadToLorettas



3
334

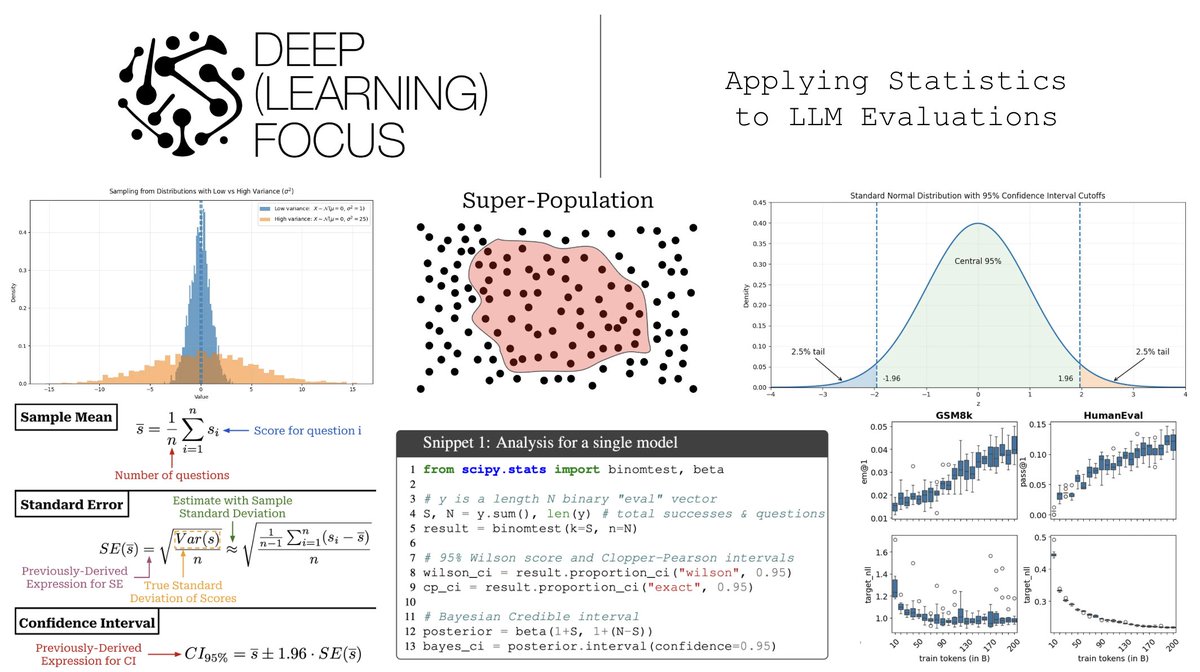
I've recently been struggling with the level of noise in LLM evaluations. Inspired by this, I did a deep dive into practical / applied statistics for LLM evals. Tomorrow morning, I'll publish my learnings so far in a long-form writeup on my blog.
Statistics is a huge field, but a lot of the most important concepts for approaching evals in a rigorous manner are relatively easy to learn and apply. With a grasp of applied statistics for LLMx, you can:
1. better interpret results (i.e., understand if they are meaningful or caused by noise).
2. design evals in a way that is conducive to drawing more confident conclusions.
Both of these points help us to run faster and more efficient experiments, rather than wasting time and compute chasing noise.
Some of my favorite papers so far:
- A statistical approach to LLM evaluations: arxiv.org/abs/2411.00640
- Don't use CLT in LLM evals with fewer than 100 data points: arxiv.org/abs/2503.01747
- Quantifying variance in evaluation benchmarks: arxiv.org/abs/2406.10229
- A framework for reducing uncertainty in LLM evaluation: arxiv.org/abs/2508.13144
18
32
309
19,267