
In another life, I should've been hard launching her ka Sweetest Taboo ya Sade🥺

Please go subscribe to GrownFolks!
🎥 YouTube Channel:
youtube.com/@GrownFolksBrand
We're launching a huge raffle during UFC 250! If we reach 100 subscribers, I'm giving away the entire raffle pot. My goal is to grow the channel, build a great community, and give back to the people who support us.
If you'd like to help grow the channel, you can donate here:
cash.app/$GrownFolksShow
A portion of all donations will also help support SAVE (Suicide Awareness Voices of Education):
save.org
Every subscriber, like, comment, share, and donation helps us grow. Thank you for supporting GrownFolks and helping us make a difference.
Subscribe today:
youtube.com/@GrownFolksBrand
#GrownFolks #UFC250 #Giveaway #Raffle #YouTube #MentalHealthAwareness #SAVE #Community
1

It fails because there is nothing so dumb leftists.will.not endorse it
For crying out loud, they even insist that this:👌🏼means "white power" when we have the 4chan discussion launching it as a troll!
DeeJ retweeted

May 20
WELCOME TO MONSTERS NFT 👹
Monsters is an upcoming Rat Fink inspired collection launching on ETH full of insane creatures made to pull out your inner madness, created by @SDecays
4,444 Monsters 🔥
We’re so excited to share this artwork with you🔥
Follow us along our journey for updates, and hop into the discord to vibe with us.
discord.gg/UF2eGVBnt

43
294
1,510
9,157

Working on launching a website, but getting the back end to talk to the front-end has been tough. That and getting the backend to function correctly.
1

Launching a petition to the NFL & Santa Clara City. The 49ers say EMF levels are "400x below the safe zone." How is "safe" defined?
The report should not be secret. @sfchronicle @karaswisher @abc7newsbayarea @mercnews @WallStreetApes youtube.com/shorts/7_rzcUQIl…
Please go subscribe to GrownFolks!
🎥 YouTube Channel:
youtube.com/@GrownFolksBrand
We're launching a huge raffle during UFC 250! If we reach 100 subscribers, I'm giving away the entire raffle pot. My goal is to grow the channel, build a great community, and give back to the people who support us.
If you'd like to help grow the channel, you can donate here:
cash.app/$GrownFolksShow
A portion of all donations will also help support SAVE (Suicide Awareness Voices of Education):
save.org
Every subscriber, like, comment, share, and donation helps us grow. Thank you for supporting GrownFolks and helping us make a difference.
Subscribe today:
youtube.com/@GrownFolksBrand
#GrownFolks #UFC250 #Giveaway #Raffle #YouTube #MentalHealthAwareness #SAVE #Community
4
Agent 11 retweeted

Jun 13
🚨 HOLY SMOKES! UFO FILES JUST DROPPED — AND THEY’RE GETTING WEIRDER BY THE DAY 👽🛸
MASSIVE “MOTHER ORB” LAUNCHING SMALLER ORBS… ONE AFTER THE OTHER 🛸
FBI agents reported mysterious lights “DANCING” near a tree line before VANISHING into the night 👽
799
2,027
11,519
793,775

CBDC: Bank Of Uganda is launching money withdrawal limits in 6 months in line with the Prophecy.
Prophecy Exposes Alarming Globalists Digital Currency Plot!
youtu.be/BVio7feMW2E?si=7Anj…
#ProphetElvisMbonye
Matt retweeted

Last week, after Israel targeted Hezbollah in Beirut, Iran responded by launching 30 ballistic missiles.
2
2
17
1,900

A sleek new blue Freelander SUV is launching soon in the Middle East — and Abu Dhabi has been chosen as the starting point! 🚙
This revived British icon is a collaboration between Jaguar Land Rover and Chinese Chery.
Looks sharp, modern, and perfect for Gulf roads. Excited to see it hit the streets?

15

The question of why India hasn't produced a "DeepSeek"—a homegrown, state-of-the-art foundational model that competes with GPT-4 at a fraction of the cost—is complex. It is not due to a lack of talent or coding ability, but rather a combination of **infrastructure gaps, funding culture, and strategic focus.**
Here is a breakdown of the primary reasons:
1. The "Compute" Gap (The Hardware Bottleneck)
This is the most immediate hurdle. To train a model like DeepSeek-V3, you need thousands of high-end GPUs (like the NVIDIA H800 or H100).
* **China:** Despite US sanctions, China has been hoarding chips for years and has a massive domestic manufacturing base for servers and data centers. DeepSeek had access to a cluster of 2,000 H800s ready to go.
* **India:** India has a severe shortage of domestic GPUs. Most Indian AI startups rent compute from cloud providers (AWS, Azure, Google), which is expensive and creates data sovereignty issues. India is currently building a "IndiaAI" compute capacity of roughly 10,000 GPUs, but this is a government initiative that is just starting, whereas Chinese companies have had private infrastructure for years.
2. The "Services" vs. "Product" Mindset
India’s tech economy is built on **IT Services** (Infosys, TCS, Wipro). The model there is: "A client gives us a problem, we solve it efficiently using existing tools."
* Building a foundational LLM is a **Product R&D** play. It requires spending $50M–$100M with *zero guarantee* of revenue or a usable product for 2–3 years.
* Indian venture capitalists (VCs) have traditionally been risk-averse regarding "Deep Tech." They prefer investing in SaaS (Software as a Service) or B2B companies that generate revenue quickly. DeepSeek was funded by a hedge fund (High-Flyer) that was willing to make a massive, speculative capital expenditure (CapEx) bet.
3. The "Brain Drain"
While India produces some of the world's best AI engineers, the ecosystem to keep them there is weak.
* Many of the top AI researchers at Google, OpenAI, Meta, and Anthropic are of Indian origin.
* However, they left because the research labs, the funding, and the massive compute clusters were in the US. Until recently, India did not have an environment where a researcher could train a trillion-parameter model.
4. Data Complexity (The Language Problem)
DeepSeek focused primarily on English and Chinese.
* India is uniquely difficult because of its linguistic diversity. To build an "Indian GPT," you cannot just train on English and Hindi. You need high-quality data in Tamil, Telugu, Bengali, Marathi, Kannada, etc.
* Curating, cleaning, and tokenizing this massive amount of Indic language data is a nightmare compared to the relatively structured corpora of English and Mandarin. Indian startups like **Sarvam** and **Krutrim** are trying to solve this, but it slows down development significantly.
5. Regulatory Uncertainty
India's regulatory environment regarding AI has been cautious.
* In 2023, the Indian government briefly issued an advisory requiring government approval before launching "untested" AI models. While it was retracted, it created a chilling effect.
* DeepSeek released their model as "Open Source" (mostly). India’s IT rules and liability frameworks sometimes discourage companies from open-sourcing their weights for fear of legal backlash if the model generates something offensive.
Is India trying?
Yes, but the strategy is different.
* **Krutrim (Ola):** Launched India's first indigenous LLM, though it faced criticism for accuracy issues upon release.
* **Sarvam AI:** A well-funded startup focusing on building efficient models for Indian languages.
* **CoRover.ai:** Developed the 'Hanooman' series of models in partnership with Reliance.
China built DeepSeek because they had **excess compute, massive capital looking for a home, and a strategic fear of US AI dominance.**
7
Cessyyyy 🍀 retweeted

₱40,000 IPON CHALLENGE
We are launching our ₱40,000 Ipon Challenge in order to raise funds for Heath’s upcoming concert.
This project is created to help us raise funds through regular savings for this goal.
Any amount counts. Every amount given, whether big or small, helps us get closer to our goal.
#HEATHJORNALES #HEATH_QUARTERS_GLOBAL

1
37
48
1,023
mamacarol retweeted

May 24
Effortless elegance meets next level innovation. 💜📸
Gabbi Garcia with the all-new #Xiaomi17TSeries.
Officially launching in the Philippines this May 29, 4 PM. Stay tuned. ✨
#XiaomiPH #Xiaomi17TSeries #TheTelephotoMaster
#Xiaomi17TSeriesxGabbiGarcia

18
125
8,860

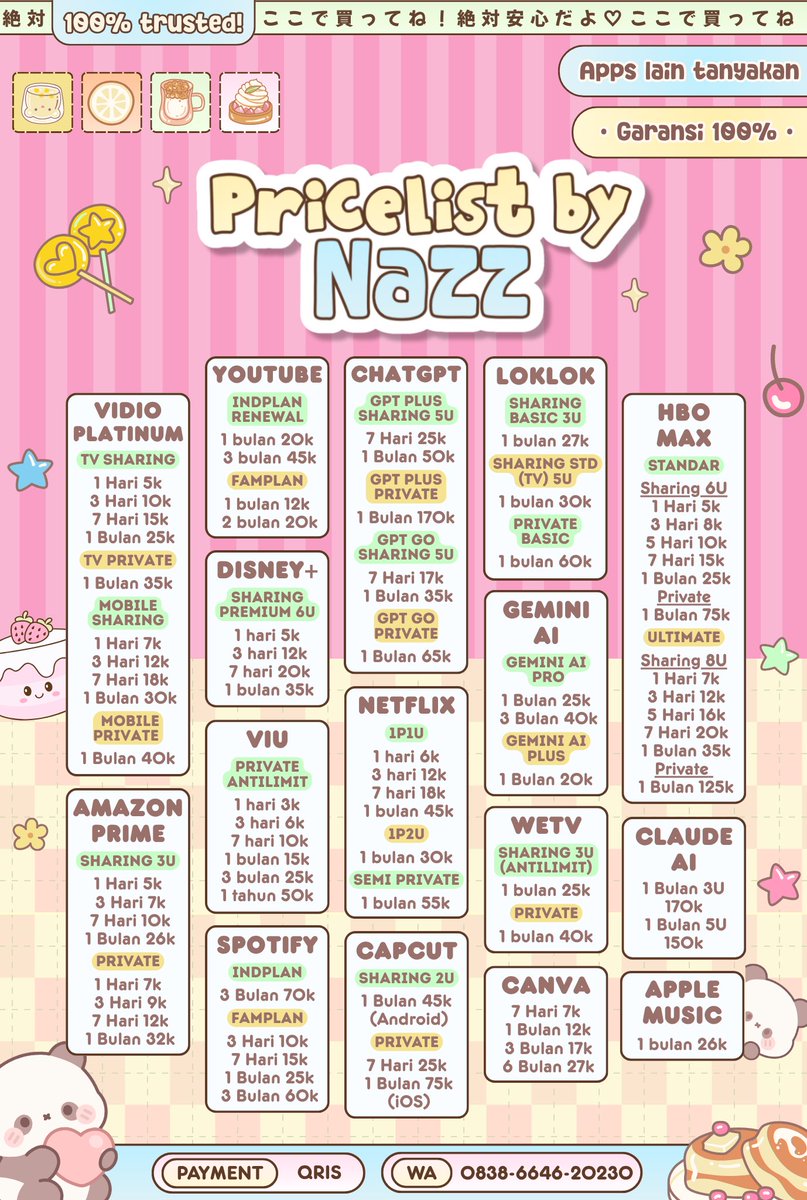
Pricelist baru sudah launching, semoga dipertemukan dengan pembeli pembeli yang amanah, sabar, dan patuh rules
Aamiin
3

With the largest successful IPO in history on the @Nasdaq ….
It won’t be long until you see @internSPC69x launching to the billions.
Load your bags 🚀🚀🚀
dexscreener.com/solana/5QPHh…
12
Latiencur retweeted

I'm not launching until I fill up the entire top bar.

1
1
4
52
Karlson Cleaning 💫 retweeted

🚨BREAKING: Didier Drogba says the Ghana government launching an official protest against the Canada government on Thomas Partey visa denial and Warning them to overturn that unfortunate decisions is the right thing to do
"I think the Ghanaian government is absolutely right to stand up for one of its citizens. Whether you agree with Thomas Partey or not, every person deserves fair treatment and due process."
"What I respect is that Ghana didn't stay silent. They reportedly made their position clear and challenged a decision they felt was unfair and damaging."
"Too often African countries are expected to simply accept decisions made elsewhere without asking questions. This time, Ghana decided to ask those questions."
"If a player has not been found guilty in a court of law, then governments and football authorities have to be very careful about the message they send."
"The World Cup is supposed to bring nations together. It should not become a competition where administrative decisions create unnecessary controversy before the football even starts."
"I understand every country has the right to enforce its own laws and immigration policies, but there also has to be consistency, transparency and respect."
"For me, the important thing is that Ghana defended one of its own and made sure its concerns were heard at the highest level. That's exactly what any government should do for its citizens."
"Whether the decision is eventually overturned or not, Ghana sending a strong protest shows that African nations are becoming more confident in defending their people on the global stage, and I think that's something many Africans will support."


44
333
1,660
46,727

Did you join a protest against the white paedophiles at all or hear of anyone launching a hate march or protest?
3