
My full opinion in a longpost, which I accept could be entirely wrong. We’ll see.
I don’t think they *have* to be responsive, but this will probably be the centerpiece of staying the injunction against them as a supply chain risk.
If this was intentional by the administration, it’s possibly a brilliant legal move (I doubt this).
Then, for the precautionary principle I’m just applying Ant’s own safety logic.
False positives are almost costless, Fable doesn’t run critical infrastructure or anything and just launched. That may change in the future, but as a dry run Ant’s own safety policies were shown to be very weak.
False negatives on the other hand can be bad, and doesn’t depend on scifi scenarios. Time isn’t on your side during an active hack. The principle was demonstrated here.
Ant should have somebody with their finger on the emergency stop button, unless they didn’t really believe any of what they were saying about capabilities as a cyber weapon…
At some point it won’t be a free or easy decision to press that button, but it is now.
On a more practical level, simply complying would have earned them some much needed political capital. And they knew they risked being shut down anyway, which is what happened.
They are an NSA contractor and invented the most powerful hacking tool known to man. The public doesn’t particularly like AI companies.
The WH said the NSA reviewed the details, Ant can’t assume they’re in the NatSec loop anytime a concern is raised in real-time by government.
1
1
26

Maga Troon retweeted

Jun 14
the zoomies are popping the fuck off longpost style

2
3
146
2,141

It's interesting how Denmark hired Croat light cavalry as mercenaries in late 17th century.
I mentioned this in the "longpost" bellow.
These troops were hardened by Habsburg-Ottoman frontier warfare, with a reputation for being especially ferocious.

3 Dec 2024

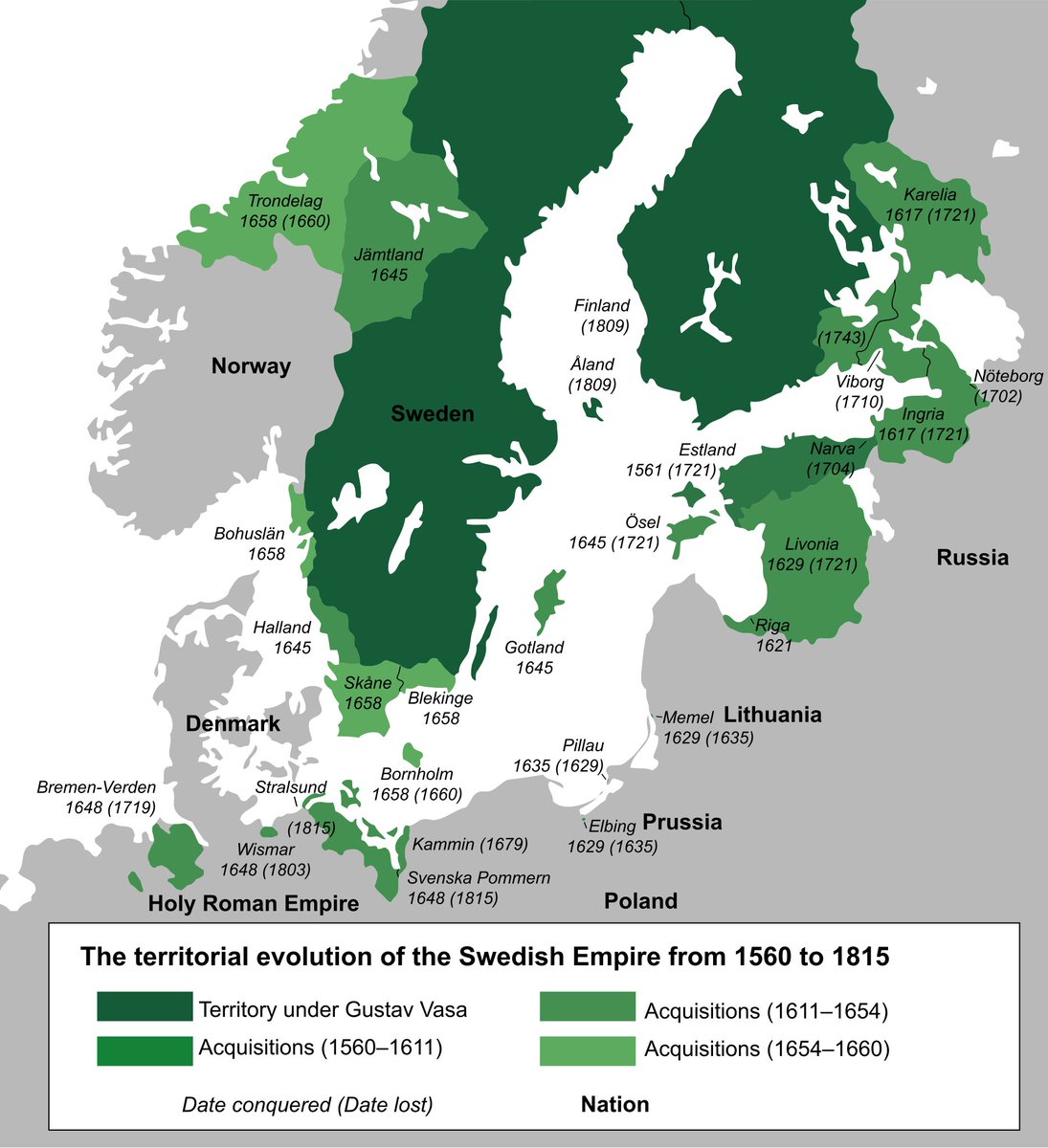
During the Scanian War of 1675-79 irregular troops known as the snapphanar appeared!
These soldiers were pro-Danish and harassed the Swedes in the region of Scania which had passed under Swedish control in 1658, attacking the supply lines and participating in organized ambushes.
The snapphanar was used as a general term describing different types of soldiers who were harassing the Swedes in this troubled region.
Some of them were Danish soldiers specifically send to Scania and other territories recently obtained by the Swedes in what is now southern Sweden (you can observe this on the map I attached) to wreak havoc.
Others were locals, motivated be either resentment towards the new Swedish rule or simply by promises of loot and plunder they could obtain living this sort of lifestyle, effectively becoming bandits.
The Danish called these troops friskytter, while the Swedish term snapphanar had negative connotations, associated with banditry.
One of the main objectives of the snapphanar was to prevent the Swedish tax collection and undermine the authority and legitimacy of Swedish state in the disputed regions, preparing the way for Danish invasion, as part of the Danish plan to regain full control of what they lost. This invasion would ultimately happen in the aforementioned Scanian War.
Most of these friskytter/snapphanar were infantrymen, but there were also light cavalry units, some of them very professional and experienced. It's very interesting how the Danes also used Croat mercenaries as part of the friskytter, the famed Croat light cavalry which had distinguished itself in the Thirty Years' War, coming out of tradition of similar borderland raiding in the Croatian frontier against the Ottomans.
This is also an example of how in early modern warfare these conflicts regularly devolved in a "petty war" or "little war" in the problematic borderland regions, where both sides began relying on irregular light infantry and cavalry, and these units would start operating independently, often turning to simple banditry.
The snapphanar were initially very successful in undermining the Swedish control of Scania. However as the tide of the war turned against Denmark, Sweden eventually gained and opportunity to deal with these troublesome snapphanar, and they did this in a very brutal manner. No mercy was shown to these men, who were considered as nothing more than criminal bandits!
When they were captured, the Swedes executed the snapphanar and had their impaled bodies displayed as a warning to the population not to side with them. They also used the brutal breaking wheel method of execution, which also served to intimidate the local population.
The Swedes also pushed the Scanian peasants to swear allegiance to the King of Sweden, which many did. This would begin to create a wedge between the local population and the snapphanar "guerrilla" troops. While previously the locals were sympathetic to the Danish groups, the terror of the snapphanar caused many to change sympathies. Many were also simply demoralized by Swedish victory, as King Charles XI of Sweden launched a successful counteroffensive and regained full control of Scania.
The Swedes were determined to crush the snapphanar movement for good, and continued to do so even decades after the Scanian War ended in 1679. The last suspected snapphane, Nils Tuasen‚ was executed in 1700 for killing a Swedish soldier all the way back in 1677.

8
17
180
8,820
myy retweeted

Jun 7
Longpost about the biggest misconception I see people having by FAR on LLMs right now.
Know the difference between the harness, the model, and serving inference.
Vast majority of problems I see people having right now are due to the harness. Each provider has it's own unique thing that's wrong with it. Claude is unique like the state of California in that it taxes/is bad at everything.
Harness: This is the traditional software that calls the model api from the provider. This is what you install on your computer or the website you visit to access the LLM.
Common harnesses:
- Claude Code
- Codex
- Droid
- Pi
- OpenCode
- OMP ❤️
- Antigravity
- Copilot
- chat.com, claude.ai, or google.com in a web browser could technically be considered a harness
Harnesses are most people's bottleneck because things like tool calls, system prompts, mcp servers, skills, subagents, change the way the api is called and its actually used for gathering information and your day to day work dramatically. Claude code or codex can use 8x the tokens in certain contexts when programming compared to pi or omp purely due to hashline editing and tool calls in the system prompt. Planning and subagent management also makes work significantly faster for larger tasks. Compaction in codex is so good the model needs 1/4 the context that claude or gemini does to achieve better results which allows them to serve more users simultaneously with available vram.
Model: This is the actual LLM. The weight values which were trained and deployed somewhere which you access from the harness on your machine via an api. This is what people are benchmarking and typically talking about when they post evals.
Common Models:
- Claude Opus 4.8
- GPT 5.5
- Gemini 3.5 Flash
- Deepseek V4 Pro
- Qwen 3.7 Max
- Kimi K2.6
- Composer 2.5
People run evals to determine model quality for different tasks. Most engineers are using them for agentic coding, where terminalbench is king, and swebench to a lesser extent currently. For academic research and "white collar work" (i've written about this gimmick previously) there are other evals people target.
Serving and Inference: This is the actual computer and infrastructure network the model is running and being served on remotely. This can vary wildly depending on the provider.
- Google and XAI are the only ones that own their full stack vertically right now. Google has vertically integrated all of their models to use in house TPUs rather than GPUs to run on their cloud network (GCP, which they also own) extremely reliably and quickly.
- OpenAI has secured deals with Microsoft and now AWS and others to have guaranteed compute capacity until 2030 or so and preplanned most of their capacity already. They have deals with nvidia and cerebras directly now for datacenter buildouts.
- Anthropic didn't buy nearly enough compute the last few years. Now they are desperately selling off equity and turning into corporate frankenstein to meet demand. They are currently splitting the inference they give you between: GPUs, TPUs, AWS, GCP, SpaceX, bunch of other random crap. This is completely unmanageable in any reasonable period of time given the current growth of the space.
Chinese models are open source. Most of the chinese infrastructure is completely jank and slow, but great news! There's places hosting it for you like firworks, GMI, and others on the latest blackwell gpus to run it at 5x the speed you get through the official chinese apis. Or you can host them yourself! The chinese models are also a fraction of the price because power and the older hardware they have is so cheap. DSV4 flash performs the same as sonnet for actual pennies, or you can pay the same prices as the western providers on fireworks or gmi to get something that absolutely flies like gemini does. Kimi charges PER TURN rather than per token so you get 14x the tokens weekly on their chinese sub that you would get on gpt pro for something at gpt 5.4 xhigh's intelligence level.
There are different techniques people use to serve the models more effectively as well to more customers:
- Quantization truncates the weight values in memory to use less vram at the expense of the model getting "dumber" which claude does during peak hours in some locations and local hosters often use to take advantage of weaker gpus for personal use
- Smaller models can perform better than larger ones on actual task evals in some cases or be trained or fine tuned to be more token efficient to use less compute while performing similarly from a user's perspective
- Things like MOE allow models like deepseek or qwen to get split across lots of smaller/cheaper gpus at once and split off smaller more specialized models for research and specialized use cases
- Specialized silicon like Google's TPUs, Trainium, Cerebras, Groq, allow the models to be hosted at much much higher speeds at higher cost due to the specialized silicon and software stack
- Newer generation gpus or gpus with higher memory bandwidth or blackwell hardware are the single largest determinant in how fast a model will run that you are hosting followed by custom kernels, serving configuration, parallelism etc. However everything revolves around the silicon. Nvidia is still king because of Cuda and blackwell gpus have minimum 2x the memory bandwidth of any other gpus on the market. TPUS are faster still but far more specialized and difficult to get/set up. AMD/Apple chips are significantly slower albeit cheaper in some cases.
Why all of this is important:
Many of the issues people experience with claude for example, or reasons you see wildly different experiences from two people using the same model are ACTUALLY because of issues with the harness or serving. Some examples
- Opus 4.8 works okay on bedrock in opencode at 2am BUT Opus 4.8 on a $20/mo sub during peak business hours served at fp8 quant god knows where on medium thinking in claude code Is completely useless.
- Gemini 3.5 Flash or 3.1 Pro feels completely useless in gemini cli and gets stuck in loops constantly BUT in OMP it's as good as 5.5 is at 10 times the speed
- Qwen 3.6 27b locally feels awful in opencode on a macbook or dgx but absolutely flies at 10x the speed with no tool calls or thinking in pi with nvfp4 and MTP on a 5090 using raw bash and web search.
Why gpt is so uniquely good at the above:
Even if it's slow during the day from the massive userbase, it's the only one that just fucking works 24/7. It's not the fastest or the prettiest, but it's the most reliable and consistent out of the box with the least setup by far.
Why claude is so uniquely bad at the above:
The default harness is bad, the user experience is flashy, but it's the most expensive by far, you get wildly different quantizations, speeds, and answer quality depending where it's being hosted, and they have one nine of uptime status.claude.com/. This is largely due to organizational issues at the company which will *never* be resolved due to the cap table being so split now and internal politics.
Be extremely wary when someone says "I'm using claude" "I'm using deepseek" "I'm using gemini" two different people could be having wildly different results depending on what harness they're using, what model, thinking, and where it's being served at what time of day.
To summarize:
GPT - Slow Harness - Great model - Great Infra
Google - Shit Harness - Great model - UNMATCHED infra
Anthropic - Shit Harness - Okay model - Shit Infra - Great marketing and sales team
(hence California Income/Property/Sales tax analogy)
Chinese models - It's like linux, here's the parts, build it yourself! or use the hosts in china for dirt cheap or expensive western hosts for extremely fast infra
You can use ANY harness you want with ANY provider if you're willing to set it up
39
26
333
58,885
Spaceman retweeted

The most reconstructed group lion the American right is posting rebels flags lmao.
Wasn’t Von Longpost doing the respect me for being a veteran in da Union army during the AHP tantrum?
Absolutely reconstructed
3
2
85
3,470


Jun 12
19 days without a cfang longpost I miss him so much 😔

Jun 11

19 days without a cfang longpost I miss him so much 😔
1
1
42
506