
Jun 13
• Works in all modern browsers and Node.js with jsdom
• Supports HTML, SVG and MathML sanitization
• Configurable with secure defaults and hooks
• Inspired the HTML Sanitizer API shipping in browsers
1
15
Jun 13
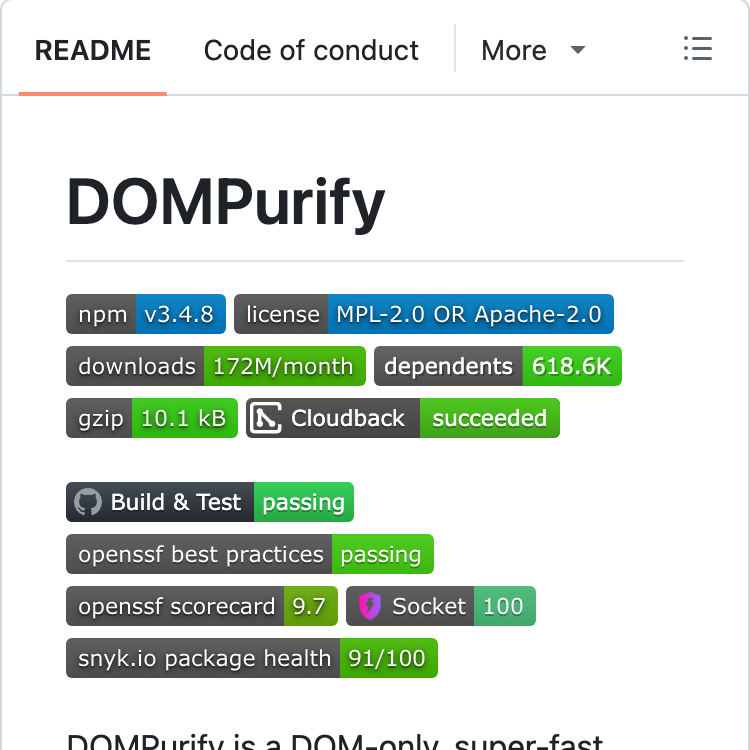
DOMPurify is a DOM-only, super-fast XSS sanitizer for HTML, MathML and SVG that prevents cross-site scripting attacks.
1
20

Jun 12
I've moved all my local Obsidian content to the web on @cloudflare Workers, using the GitHub API, @tan_stack start, and Fumadocs
Here's a rant about the problems I've faced:
> tried fumadocs-ui with TanStack Start, DocsLayout expects Next.js router context, had to use undocumented fumadocs-ui/provider/tanstack wrapper
> used import.meta.glob for vault .md files, Vite refuses to resolve symlinks, set preserveSymlinks AND server.fs.allow for parent dir
> remark-math parses Full Loss: $$ as inline math start, $$Classification Loss: as closing delimiter, entire document between = one KaTeX block = red error cascade
> wrote preprocessor to split $$ onto own lines, now indented list items break because $$ with 4 spaces = code block not math fence per CommonMark
> closing $$ at 4-space indent doesn't close math block in micromark, requires ≤3 spaces, everything after becomes red KaTeX error
> rehype-katex omits throwOnError from Options type via Omit<>, can't disable red error rendering, only strict: 'ignore' available
> KaTeX chokes on unicode inside accidental math blocks: zero-width spaces (8203), smart quotes (8217), emojis ✅❌ all throw "No character metrics" warnings
> renderMarkdown runs twice (SSR hydration), both execute full remark rehype KaTeX pipeline, client re-parses already-rendered HTML causing duplicate warnings
> switched to pre-rendering KaTeX before remark, used <span> wrapper, remark parses span contents as markdown, closes at first inner </span> not outer
> KaTeX outputs MathML <annotation> with raw LaTeX source, remark leaks annotation text into output showing {DETR} = \lambda{cls} as plain text
> set output: 'html' to strip MathML, switched to <div> wrapper, remark treats as opaque HTML block — now <div> at column 0 breaks nested list context
> deeply indented list items after <div> become code blocks, 4-tab indent (16 spaces) no longer recognized as list continuation after block element
> tried <span style="display:block"> to keep inline context, KaTeX's nested spans still get fragmented by remark's inline HTML parser
> tried custom <math-display> element with rehype plugin to replace post-parse, custom elements aren't in CommonMark type-6 block list but still break lists
> TanStack Start splat routes need params._splat, not documented, found by reading api.trpc.$.tsx scaffold code
> fumadocs-core PageTree.Item url field doesn't auto-encode spaces, manual `encodeURIComponent` needed for "Knowledge Index" → " " paths
> wikilink resolution: Obsidian uses filename lookup not path, built filename→key index, then realized anchors need separate slugify matching heading ID generation
> `[[Page#Section|Alias]]` wikilinks stripped to plain text initially, then added resolver but cross-vault links need vault context not available in renderer
> Shiki highlighting in Workers: had to use JS regex engine not WASM, async codeToHtml inside sync processSync = Promise wrapper hell, moved to loader
> `#Q question #A answer` flashcard syntax: regex eats newlines between tokens, had to use `[^\S\n] ` (horizontal whitespace only) to preserve structure
> same-line `#Q text #A text` works, multi-line breaks, had to split first then group consecutive `#Q`/`#A` lines into `<div class="obsidian-qa">` blocks
> hydration mismatch: fumadocs-ui RootProvider sets `className="dark"` on server, client detects different theme, added `suppressHydrationWarning` to `<html>` and `<body>`
> Grammarly extension injects `data-gr-ext-installed` on body during hydration, triggers mismatch warnings, same `suppressHydrationWarning` fix
> `flattenTree` from fumadocs-core expects `Node[]` not `PageTree.Root`, had to pass `tree.children` not `tree`
> Obsidian image embeds image.png need conversion to standard markdown, built imageByFilename Map with both encoded and decoded keys for lookup
> mermaid code blocks need client-side rendering, marked with .vault-mermaid class, lazy-loaded mermaid.js in useEffect after HTML set
> scroll-to-anchor breaks on SPA navigation, hash exists before element rendered, added retry loop with 5 attempts × 100ms delay
> anchor click handling: href="#section" needs preventDefault smooth scroll history.pushState, same-page vs cross-page detection via pathname comparison
> Obsidian callouts > !note not standard markdown, need custom remark plugin or regex preprocessing, skipped for now
> nested lists with mixed tabs/spaces: Obsidian uses 4-space equiv tabs, CommonMark interprets 4 spaces as code block in certain contexts
> math inside list items: $$` must be ≤3 spaces from list item content column, Obsidian allows 0-indent which breaks list continuation
> `processSync` can't handle async Shiki highlighting, had to make renderMarkdown async, moved call to route loader for SSR
> KaTeX CSS `?url` import generates hashed asset path, works in dev but needed verification for Worker ASSETS binding in prod
> search API uses `createSearchAPI("advanced")` with structuredData, had to strip markdown syntax for indexable text, regex soup for fenced blocks/links/math
> slugifyAnchor normalization: Obsidian "IOU (Heading)" and "IOU(Heading)" both need same slug, added `\s \(` → `(` replacement before kebab-case
> blank lines inside `$$ math blocks: Obsidian allows, standard CommonMark terminates block, wrote pass to normalize delimiter placement
> \` at end of lines in LaTeX cases environment: \ (backslash space) vs \\ (line break), inconsistent source files cause KaTeX errors
> styling broken via proxy: assets at `/fumadocs/assets/*` correctly proxied but Worker can't find files because path mismatch with actual build output location
> pnpm v10 `ERR_PNPM_IGNORED_BUILDS` hard error: esbuild/sharp/workerd scripts blocked, moved `onlyBuiltDependencies` from `package.json#pnpm` to `pnpm-workspace.yaml`
> fumadocs-ui `.shiki:not(.not-fumadocs-codeblock *)` CSS matches ALL `.shiki` elements, applies padding/position to `.line` spans creating horizontal separator lines between code rows
> Shiki `bundledThemes` not obvious, had to enumerate keys to find available dark themes
> code span colors overridden: fumadocs-ui `code span { color: var(--shiki-light) }` rule wipes all inline token colors from Shiki output
> RootProvider `search` prop API undocumented for TanStack, dug through `.d.ts` files to find `DefaultSearchDialogProps` interface
> DocsLayout `tree` prop needs `PageTree.Root`, had to read bundled `definitions-Cob-Q8-8.d.ts` to understand Item/Folder/Separator structure
> fumadocs-core loader accepts `VirtualFile` objects, could construct manually but easier to build PageTree directly from file paths
> `createMarkdownRenderer` from fumadocs-core uses remark rehype internally, but outputs React component not HTML string, needed different approach
> gray-matter and marked not needed: fumadocs-core has `content/md/frontmatter` and remark pipeline built-in, but as transitive deps not directly importable in pnpm
> `fumadocs-core/mdx-plugins/remark-gfm` re-exports remarkGfm, can use without adding direct dependency
> Cloudflare Worker can't use filesystem at runtime, all content must be bundled at build time via import.meta.glob eager loading
> glob pattern `'../../content/**/*.md'` from src/lib needed symlink in place AND Vite fs.allow config for parent directory
> `$vault.tsx` acts as layout needing `<Outlet />`, `$vault.index.tsx` is vault index, `$vault.$.tsx` is catch-all, file naming convention undocumented
> TanStack Router basepath `/fumadocs` handles routing but Vite base affects asset URLs differently, needed both configured correctly
> mermaid.initialize() must be called before mermaid.run(), but DOM not ready on hydration, race condition with useEffect timing
> structuredData from search index includes raw markdown, needed regex to strip fenced blocks, wikilinks, math delimiters for clean search text
2
1
7
647
eclesio retweeted

Jun 12
I open-sourced an HTML MathML render of the JAM Gray Paper: real rendered math in any browser, stable per-§/equation anchors for deep-link citations, and a v0.8.0⇄v0.7.2 version toggle. Built from the LaTeX source via LaTeXML.
Check it out at timwu20.github.io/graypaper-…
Code: github.com/timwu20/graypaper…
1
1
29

Me trying to get this PDF to read MathML properly.

ALT A man is surrounded by 4 martial artists in the movie The Furious.
2
56

Jun 11
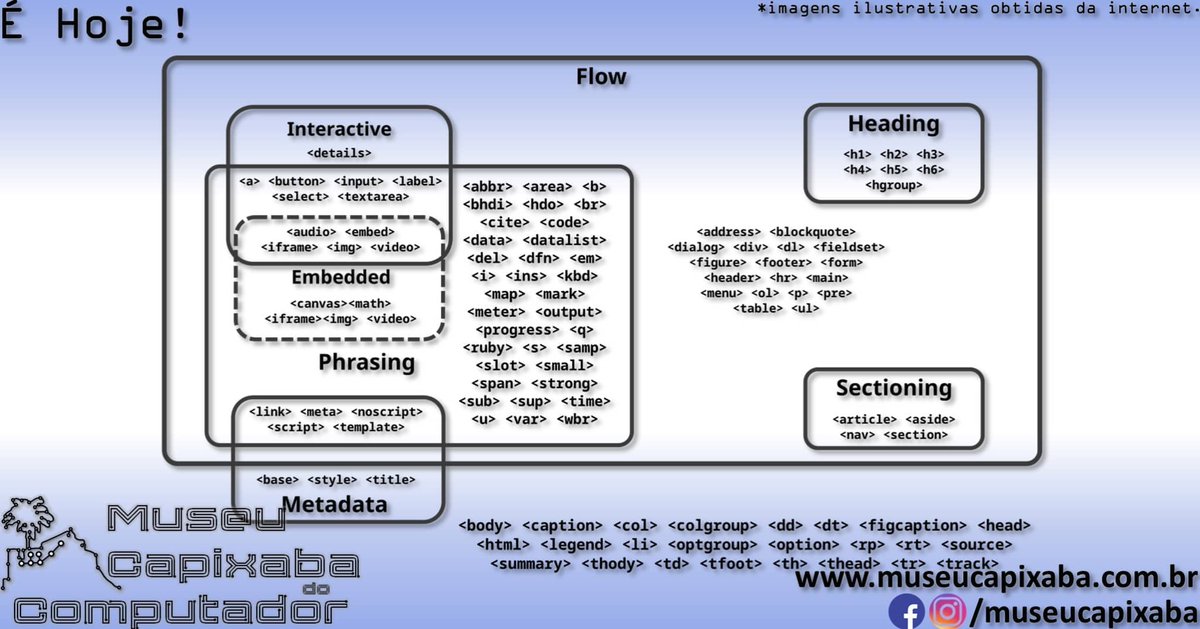
É hoje! A HyperText Markup Language HTML de 1993.
em museucapixaba.com.br/hoje/hy…
#MuseuCapixaba #mcc #éhoje #museu #Geek #HTML #HyperText #TimBernersLee #DanConnolly #IETF #W3C #RFC1866 #CERN #HTML2 #HTML3 #HTML4 #HTML401 #HTML5 #CSS #CanvasAPI #MathML #Netscape #XHTML1 #Hyperlink


43

Accessible reading matters. It’s about making sure everyone can read in a way that works for them.
Whether that’s print, audio, braille or flexible digital formats, access to reading opens up learning, work and reading for pleasure. For people with vision impairments and other print disabilities, it’s what makes reading possible.
That’s why industry collaboration is so important. Our work with the @DAISYConsortium , along with standards like EPUB 3 and eBraille, is all part of moving accessible reading forward in a practical way.
This week’s DAISY Technical Meeting 2026 at the National Library of Norway, brings that work together.
Great to see Mattias Karlsson from Dolphin speaking in the “Reading and Authoring Mathematics” session. His presentation looks at how EasyReader supports accessible maths content, including practical use of MathML with MathCAT library and new AI-powered features.
It’s exactly the kind of progress that shows how much accessible reading continues to evolve.

ALT The National Library Building in Oslo with logos from National Library of Norway and DAISY Consortium and the words 'Daisy Technical Meeting 2026'
19


Jun 9
Detrás de la evolución real de la Web hubo otros nombres decisivos. Uno de ellos fue 𝐃𝐚𝐯𝐞 𝐑𝐚𝐠𝐠𝐞𝐭𝐭, un pionero británico de la computación que ayudó a convertir la Web primitiva en una plataforma mucho más rica, visual y funcional, nacido por cierto en la misma fecha que Berners-Lee (08/Jun/55).
𝐑𝐚𝐠𝐠𝐞𝐭𝐭 comenzó a involucrarse con la Web en 1992. Desde Hewlett-Packard Labs trabajó en navegadores y servidores experimentales, participó en la evolución de HTML, impulsó propuestas como HTML y HTML 3.0, y desarrolló Arena, un navegador experimental que servía para probar nuevas capacidades del lenguaje.
Su visión era clara: la Web no debía ser solo texto enlazado. Debía permitir documentos más expresivos, con imágenes, tablas, formularios y estructuras capaces de parecerse más a una publicación digital moderna.
También fue clave en el trabajo temprano alrededor de 𝗛𝗧𝗧𝗣: ayudó a lanzar y presidió el grupo de trabajo HTTP en la IETF. Más adelante participó en estándares como 𝖧𝖳𝖬𝖫 4, 𝖷𝖧𝖳𝖬𝖫, 𝖬𝖺𝗍𝗁𝖬𝖫, 𝖷𝖥𝗈𝗋𝗆𝗌 y otros proyectos del W3C.
Mientras Berners-Lee imaginó la Web, 𝐑𝐚𝐠𝐠𝐞𝐭𝐭 ayudó a darle forma técnica, estructura y posibilidades reales de publicación.
La historia de Internet no fue obra de una sola mente brillante, sino de una comunidad de ingenieros que construyeron, probaron, corrigieron y estandarizaron cada pieza.
𝐑𝐚𝐠𝐠𝐞𝐭𝐭 merece estar en esa conversación.
#daveraggett #worldwideweb #html #http #XHTML #W3C #INTERNET #retrocomputingmx #InternetHistory

17

📐 Microsoft 365 is making it easier to create, share, and collaborate with math. New improvements bring stronger LaTeX support, MathML Core compatibility, and more accessible PDFs. Learn more: msft.it/6017v55qL
#Microsoft365 #Accessibility
2
2
9
915

「Microsoft 365」(Office)アプリの数式対応が改善 ~LaTeX、MathML Core、PDF 2.0 - 窓の杜 forest.watch.impress.co.jp/d…
今度試してみるか
1
2
410

Jun 5
「Microsoft 365」(Office)アプリの数式対応が改善 ~LaTeX、MathML Core、PDF 2.0/入力・編集からWebとの相互運用、アクセシビリティまでを強化 forest.watch.impress.co.jp/d…
1
12
31
6,538
📐 Microsoft 365 is making it easier to create, share, and collaborate with math. New improvements bring stronger LaTeX support, MathML Core compatibility, and more accessible PDFs. Learn more: msft.it/6016vdkxK
#Microsoft365 #Accessibility
1
1
16
1,110
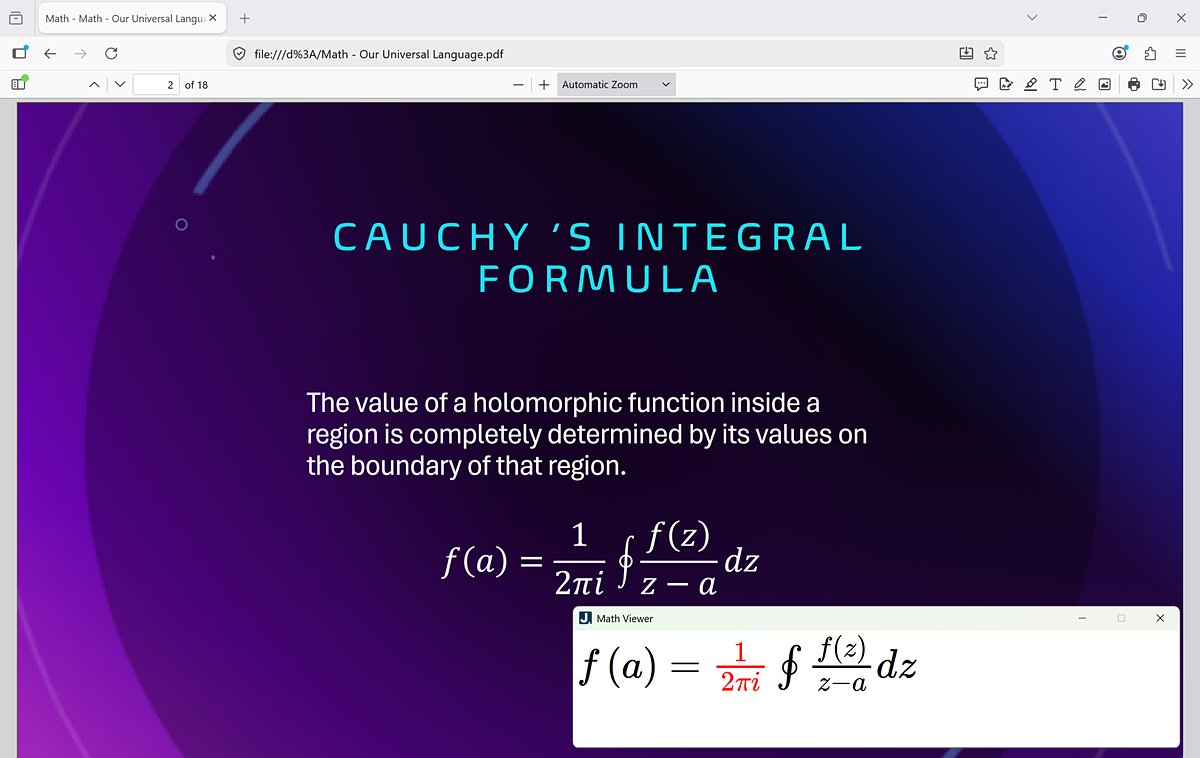
⚙️ New math improvements in Microsoft 365 Beta Channel:
✍️ Improved LaTeX support
🔗 MathML Core compatibility
📄 Accessible PDF exports
Take a look: msft.it/6015vjofb
#Microsoft365 #Accessibility
ALT A screenshot of an online LaTeX editor interface showing two panels. The left panel displays code with mathematical notation and functions, while the right panel features typeset equations and headers.
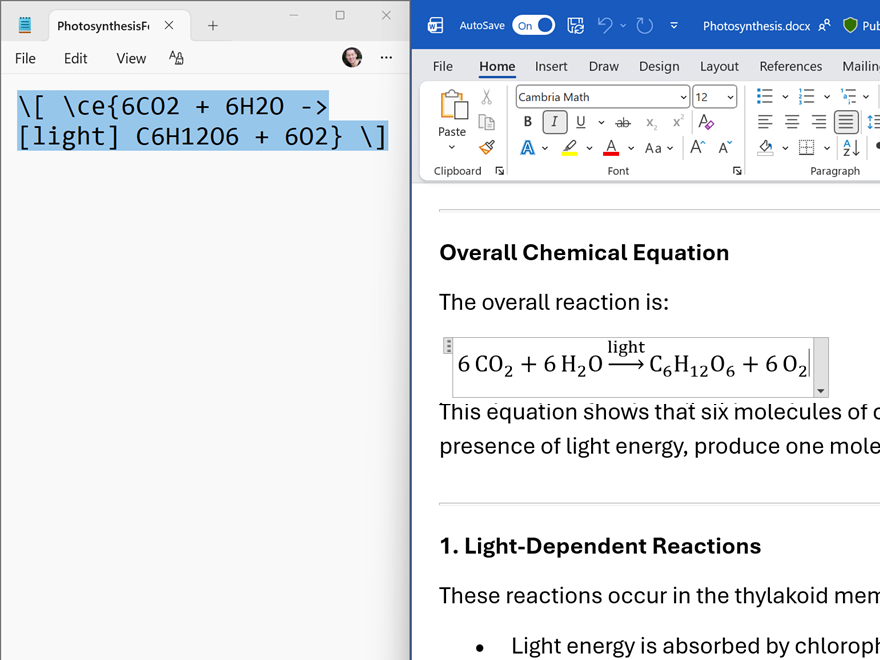
ALT A screenshot showing a text document discussing photosynthesis. The text outlines the overall chemical equation, highlighting the reaction: 6CO2 6H2O → C6H12O6 6O2. Key sections include 'Light-Dependent Reactions' and details about energy absorption by chlorophyll.
6
24
1,745

May 29
これから数学のカンを鈍らせない為のちょっとした過去問題集を作りたいと思うのですが誰が欲しい人いますか
もし渡すとしたら大学名年度大問数のみ書いた写真かデータを送るので東進の過去問データベースなりmathMLなり他個人サイトまで行ってもらうことになりますが
ただ選んでリスト化するだけです
1
4
253

May 26
Thanks! You're right that it's the hard part, and that's exactly why I didn't try to win it. I drew a line between what a literature review actually needs and what parses badly, and the two sets barely overlap. To decide which papers matter and what each one argues, you need the running prose, the abstract and the metadata. The table cells and the equation glyphs are both the parts that parse worst and the parts you least need for that job. So /tyler optimises hard for clean text and deliberately gives up the rest.
Concretely, it's pymupdf4llm doing the extraction. Prose and abstracts come out clean, and I then strip the boilerplate: repeated headers and footers, page numbers, JSTOR notices. Tables: pymupdf4llm detects many and renders them as markdown, but quality varies, so I pass them through as-is rather than pretend they're reliable. Figures are dropped entirely, since a figure bitmap carries no text value for navigation. Equations come through as linearised text, often degraded; I don't reconstruct LaTeX or MathML.
What makes that safe is that every paper keeps its source PDF path in the frontmatter, so /tyler is never the system of record on a single number – the moment you need the exact table or the precise equation, you open that one original. The one genuine failure mode is scanned PDFs with no text layer: those come out empty, and the fix is to OCR them first. But for the real task – navigating 100 papers cheaply and knowing which three to read properly – chasing perfect table parsing is the highest-effort, lowest-payoff thing you could do.
2
3
619

JavaScriptテンプレートエンジン「art-template」のnpmパッケージが、メンテナの交代後に商用iOSエクスプロイトキット配布の起点に転用されたとの報告です。このパッケージを組み込んだWebサイトをiPhoneのSafariで開くだけで、閲覧者のブラウザ上でiOS向けの攻撃コードが自動実行されうる状態だったとされています。
iOS 17.3で修正済みのWebKit脆弱性を突く攻撃コードの配信に使われたとみられ、Googleの脅威分析チームGTIGが詳細な分析を公開している商用iOSエクスプロイトキット「Coruna」の配信実装と同一または近縁の実装と高確度で分析。
ChromeやAndroidは初期のUA(User-Agent)判定で停止するため、実質的な主標的はiPhone/iOS Safariとされている形(コード上はmacOS Safariなどへの分岐も存在)。
対策としては、C2ドメイン `l1ewsu3yjkqeroy[.]xyz` の遮断と、ビーコン通信の特徴(IP取得サービス `icanhazip[.]com` への問い合わせ直後に未知APIへPOSTする挙動)による検知が示されています。
【要点の整理】
・「メンテナンスを引き継ぐ」名目で譲渡した先で直ちに武器化されたと元著者(aui)が説明。不審な挙動を報告するIssueは攻撃者側で削除されていたとのこと
・v4.13.3は文字コード難読化(String.fromCharCode)で外部呼び出しを隠蔽していたが、v4.13.5/4.13.6では難読化を外して `loadScript()` が v3[.]jiathis[.]com 配下のJSを直接読込み、最終的に utaq[.]cfww[.]shop 配下のiOS向け本体スクリプト(49554fde7424c31c[.]js)へ到達する構成
・本体側では、多層アンチボット(自動化検出・WebRTC WebGL・MathML描画・IndexedDB Blob書込み・タイムアウト(待機上限))に加え、WebAssemblyのメモリ領域からApple実行形式(Mach-O)の識別値を走査してCPU種別を分岐する処理や、JIT(実行時コンパイル)後の機械語を想定ハッシュと照合する検証チャレンジまで組み込まれており、ブラウザ向けエクスプロイト配信の選別機構と説明されているとのこと
・Coruna内でiOS 16.6〜17.2を対象とするエクスプロイトチェーン「cassowary」はCVE-2024-23222(WebKitの型の取り違え=type confusion)を悪用するもので、今回のサンプルがiOS 17.3で動作を停止する境界はこのパッチ境界と一致。URL導出方式やXOR難読化パターン、`.xyz`系C2の文字数パターンなども構造的にCorunaと一致しており、GTIGがCoruna第3キャンペーンに紐付けた中国系の金銭目的の脅威アクターUNC6691とも整合する手掛かりが複数指摘
詳細は以下を参照:
socket.dev/blog/coruna-respa…
1
7
1,216

May 15
Knowledge graphs as the backbone of digital twins for chemical processes
Building a digital twin of a chemical reactor sounds simple in principle: connect a virtual model to the plant, feed it data, let it predict. In practice, every unit operation needs its own bespoke model, and the equations, parameters and process descriptions live scattered across papers, software and lab notebooks. Scaling this to hundreds of processes is the kind of problem where ontologies and graphs shine.
Shuyuan Zhang and coauthors propose a knowledge graph that organizes process model building blocks (variables, laws, formulas, phenomena, context) into two ontologies, OntoModel and OntoProcess. Formulas are stored in MathML and parse automatically into code for SciPy, Pyomo or Julia. Autonomous agents handle assembly, calibration, SPARQL rule inference, database queries, AI property prediction, and chemistry queries via an LLM.
Two workflows emerge. A bottom-up agent assembles models when phenomena are explicit, tested on an annular microreactor where Villermaux–Dushman calibration reveals tunable mixing times down to 0.1 ms. A top-down agent screens candidates when phenomena are ambiguous, applied to a ribbed Taylor–Couette reactor where the best dispersion law shifts with rotation speed and solvent. It then drives multi-objective optimization of a flow amidation, finding Pareto-optimal trade-offs between space-time yield and E-factor, and beating Bayesian optimization on a benchmark.
What I find compelling is the philosophy. Rather than training one black-box model per process, the authors treat models as structured, reusable knowledge objects, with LLMs and AI predictors as supporting agents. A clean answer to a familiar frustration: predictive science gets stuck not on math, but on the lack of shared semantics across teams and tools.
For groups in pharma, specialty chemicals or battery electrolytes, this points to digital twins that actually scale. Process knowledge becomes queryable infrastructure rather than tribal memory, and new reactors can be onboarded by adding instances to the graph rather than rebuilding from scratch.
Paper: Zhang et al., Nature Chemical Engineering (2026) — CC BY 4.0 | doi.org/10.1038/s44286-026-0…

13
40
1,877

May 7
これによると数式はMathMLでPDFに埋め込むべきらしいけれど、MathMLは長ったらしくて読みにくくてLLMのトークン喰うし、LaTeX記法の方が人間もLLMも得意だし、何か良い工夫はないものか

The LaTeX LWG at the PDF association has published a Best Practice Guide for accessible math:
pdfa.org/resource/best-pract…
See also
latex-project.org/news/2026/…
#TeXLaTeX
5
27
5,778