
Jun 11
```
cat /etc/openproject/conf.d/other
export OPENPROJECT_INSTALLATION__TYPE="packager"
export SERVER_PATH_PREFIX_PREVIOUS="/"
export SYS_API_KEY="cG"
export SVN_REPOSITORIES=""
export GIT_REPOSITORIES="/var/db/openproject/git"
export OPENPROJECT_SEED_ADMIN_USER_MAIL="openproject@ADb.Net"
export EXECJS_RUNTIME="Node"
export OPENPROJECT_RAILS__CACHE__STORE="memcache"
export OPENPROJECT_ATTACHMENTS__STORAGE__PATH="/var/db/openproject/files"
export HOST="127.0.0.1"
export WEB_TIMEOUT="300"
export SECRET_KEY_BASE="15e"
export SECRET_TOKEN="15e"
export RECOMPILE_RAILS_ASSETS=""""
export OPENPROJECT_HOST__NAME="192.168.101.16"
export OPENPROJECT_HTTPS="false"
export OPENPROJECT_HSTS="false"
```
1
23
Nalin retweeted

Jun 9
🐧 Linux Kernel is C
🌐 Nginx is C
🚀 Redis is C
🗄️ PostgreSQL core is C
🧠 SQLite is C
🔒 OpenSSL is C
📦 Git is C
⚡ Memcached is C
🧵 libuv is C
📡 TCP/IP stack is C
🖥️ X11 Window System is C
🧰 GNU Coreutils are C
🛠️ GCC is C
🧬 CPython runtime is C
📁 ext4 / NTFS file systems are C
🎮 Game engine foundations are C
🚗 Embedded firmware is C
📟 Networking drivers are C
🛰️ Aerospace & real-time systems are C
💳 Payment terminals run C
The foundation of operating systems, databases, networking, crypto, and embedded systems is written in C.
Trends come and go.
C stays.
10
7
82
2,965




我最後一次用memcache 是2009年了
大凡有點非key value lookup需求的場景 memcache就差不多是廢了


4
560


May 30
The question of the day… What is faster…
- Using memcache like KV storage to store dns query results and have higher cache hit rate
- Use in memory cache to store the DNS query but have a lower cache hit rate
4
1,699

May 29
Top tech skills to have in your CV in 2026
1. Distributed Caching : Redis, Memcache
2. Monitoring : Splunk, Dynatrace, Grafana, ELK
3. Messaging : Kafka, JMS, RabbitMQ
4. Testing : TDD, Mockito, JUnit
5. CI/CD & Containers : Jenkins, GitHub Actions, Docker, Kubernetes
6. Frameworks : Spring Boot, Spring MVC, Apache Camel
7. Microservices : Config Server, API Gateway, Service Discovery, Resilience4j
8. Multithreading & Concurrency : Executors, ForkJoin, CompletableFuture
9. Security : Spring Security, OAuth2, JWT
10. Persistence : Hibernate, JPA, MyBatis
11. API Development : REST, Swagger, OpenAPI
12. Reactive Programming : WebFlux, RxJava, Reactor
13. Build Tools : Maven, Gradle
14. Code Quality : SonarQube, PMD, Checkstyle
15. Cloud : AWS, GCP, Azure
16. Java Versions : Java 8:25 features
17. Design Principles : SOLID, Design Patterns, Clean Architecture
34
20
192
7,874

May 28
Roundcube Webmailで複数の深刻な脆弱性が修正され、特に認証不要で悪用できるSQLインジェクションの危険性が注目されている。攻撃者はログイン不要でデータベースへ不正クエリを実行でき、情報窃取や権限昇格につながる恐れがある。
問題は2026年5月24日に公開されたRoundcube 1.6.16と1.7.1で修正された。最も重大なのはvirtuser_queryプラグインに存在した事前認証SQLインジェクションで、preg_replaceのバックスラッシュ処理不備を悪用して任意SQLを注入できる。
さらにLDAP autovalues機能の安全でないコード評価によるリモートコード実行、RedisやMemcacheのセッション汚染を利用した事前認証ファイル削除、SVG animate要素を使うCSSインジェクション回避、下書き復元画面でのStored XSSなども修正された。
SSRF回避やリモート画像ブロック回避も含まれ、複数の欠陥を連鎖利用される危険があった。Orange Cyberdefenseなどの研究者が報告しており、Roundcube利用組織には不要プラグイン停止とログ監視強化も推奨されている。
gbhackers.com/roundcube-webm…
2
8
1,816


May 13
memcache v1.7.0 released with maxKeySize, maxValueSize, and hashLargeKey which will do a hash on the key if it is too large. Keyv (keyv.org) will start to use this with v6.
npmjs.com/package/memcache
#javascript #typescript #nodejs #memcache

2
155

May 12
I only backed up db and had code and all the settings in subversion (that was before git existed). I had a replica of the db on standby, and used that replica to make backups regularly.
Semi unrelated, but given that I’m down the memory lane… eventually I had to scale up the db for a few reasons: naive view counter on the images, geospatial searches, and a lot of traffic (all of google earth and maps users). A bit of context, that was when hard drives had a latency of 10ms, memcached was a fancy new thing (that I was using), Google had not yet created the S2 library, and Redis didn’t exist. After scaling up it to multiple replicas it was still failing under load.
I tried some “simple” solutions for the counter, like storing in memcache and flushing regularly to the db, but it was still not able to sync in time. I talked with the YouTube team on the phone, they had some solution where they store exactly until 301 views and then used another system that was more complex.
At the end I did my own thing radically simplifying the problem, I wrote a demon in C with a simple embedded http server using libuv (or libevent?). Our ids were dense and we had tens of millions of images, so you can already guess the solution: the api was backed by a simple statically allocated vector of ints, and that vector was mmap’d to a file. I made a thread only to flush the file to disk every second. It worked wonderfully, with only an issue during a migration (int32 != int64…). I solved the problem with the geosearches by having another demon that implemented a quad-tree over the photo locations.
Point is, eventually things became more complex, but those 2 demons were still a single C file each. They run in separate servers, but I could have run them on the same server. And you live in a different world today, SSDs are much faster, and you have many more options to stay simple. And you probably don’t have to serve the traffic of Google Maps and Google Earth…
Some people just want a complex architecture to look like the big companies, but most of the time that’s just bureaucracy. Really listen to @levelsio, he is spot on his decisions, and you can get very very far. If it gets more complicated, it’s easier to scale up when you have something simple that you understand

do you just backup the entire vps instead of just the db and vps separately? how do you handle failover? another hot instance on standby?
4
1
37
5,437

May 2
Spent this weekend diving into research papers.
Just published my first article on caching, summarizing “Scaling Memcache at Facebook.”
x.com/020Adhish/status/20506…
Curious to know—have you explored better approaches? Let’s discuss

1
4
85

Apr 28
Developers, do you know what a thundering herd is?
If you never heard of it, read below 👇
It happens when a large group of processes is is waiting for a single resource. When that resource becomes available, they all wake up and try to use it at the same time.
This overloads the system, basically a DOS: it suddenly has to handle a ton of requests.
For example: a big chunk of Redis/Memcache keys expire a the same time. All the requests hit database, slowing everything down.
What can you do?
A couple of things:
1. Use locks. Allow one process to do the expensive work, while the others wait for cache to get populated.
2. Implement randomized TTL using jitter. Make sure the records don't expire all the same time.
3. Pre-warm the cache with the most popular keys when cache layer is reset and before traffic starts flowing through the service.
1
1
28

Apr 22
At Meta most object fetches are just a memcache read. The famous TAO paper from a decade back itself covers how the solution to everything is distributed memcache which serves 99.9% of reads 😅
2
9
3,760
Apr 22
If it were meta it would just keep all the usernames in a distributed memcache and just look it up from there 🤣
2
3
1,660

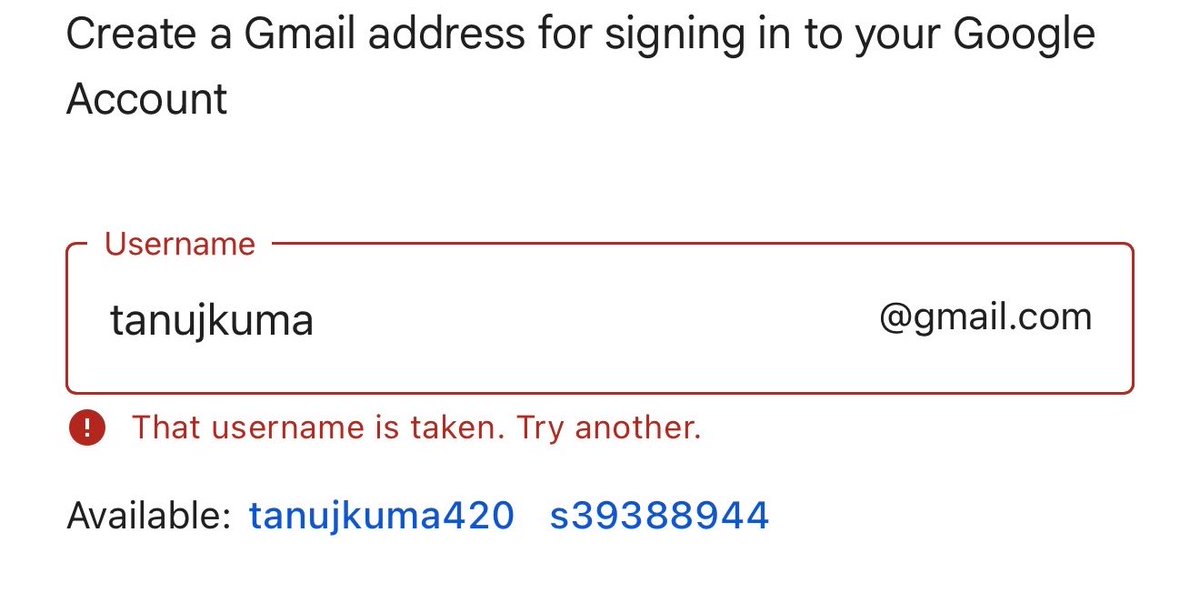
Apr 14
At scale, username availability checks are fast because of architecture, not brute force.
Typical design:
1) Normalized username key
- Convert input to canonical form (lowercase, strip rules, etc.)
2) Hash / Partition
- Route lookup to the shard responsible for that username range/hash.
3) Indexed KV / DB Lookup
- Exact match against indexed username key. This is not scanning users.
4) Caching Layer
- Frequently checked names may sit in Redis/memcache/edge cache.
5) Async Suggestions Engine
- Suggested alternatives are generated separately.
The real complexity is not lookup speed, it’s handling race conditions so two users can’t claim the same username simultaneously.
Apr 14

Interviewer:
You type a Gmail username and UI instantly shows "Username already taken"
There are millions of users globally
How does it check so fast?
1
6
1,147