

Jun 12
Day 12 of #SDESheetChallenge done✅
@striver_79 @takeUforward_
Today's questions
1️⃣Check if LL is palindrome
2️⃣Find the starting point of LL
3️⃣Flattening of LL
1,2 were s & f pointer Q's
question 3 was complex question without using space shows how mergesort is important
#dsa


1
13
110

Day 12 - #SDESheetChallenge
@striver_79 @takeUforward_
Q1:- Reverese half of LL & compare node one by one
Q2:- Tortoise & Hare algorithm
Q3:- Recursion and MergeSort concept

1
3
17



Jun 10
the binary search you memorized is probably wrong
Jon Bentley published a binary search in Programming Pearls after proving it correct and testing it
the bug survived for nearly 20 years
Joshua Bloch later discovered the exact same bug in the binary search implementation he wrote for the JDK
a 1988 study found correct binary search in only 5 of 20 textbooks
the bug only triggers on arrays with 2^30 or more elements
the problem appears when computing the midpoint
mid = (low high) / 2 can overflow on very large arrays
the fix is simple: mid = low (high - low) / 2
in C the overflow gives you an array index out of bounds with unpredictable results in Java it throws ArrayIndexOutOfBoundsException
the same bug affected mergesort and countless other divide and conquer algorithms

12
60
632
32,232

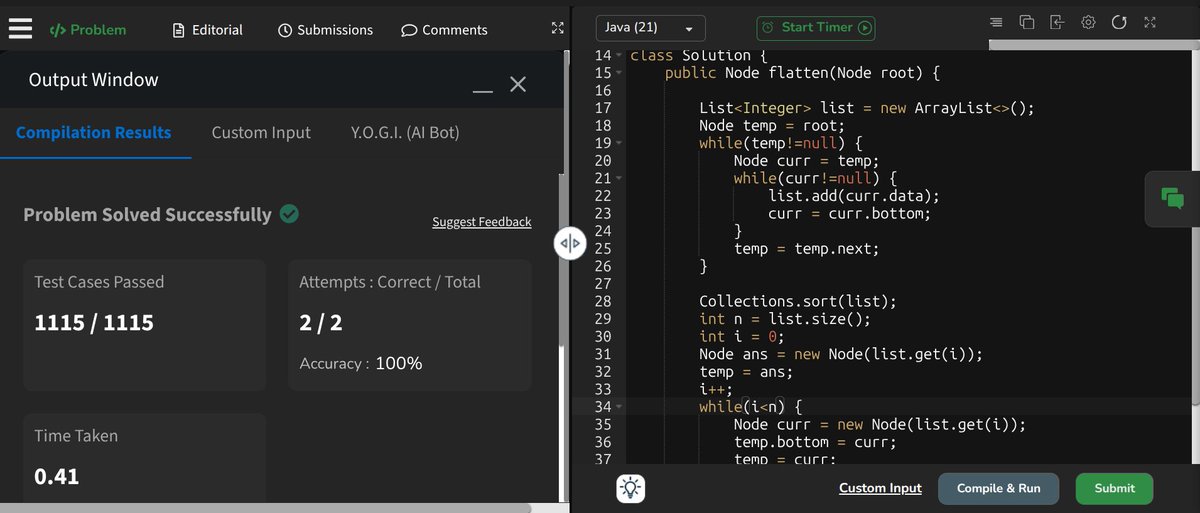
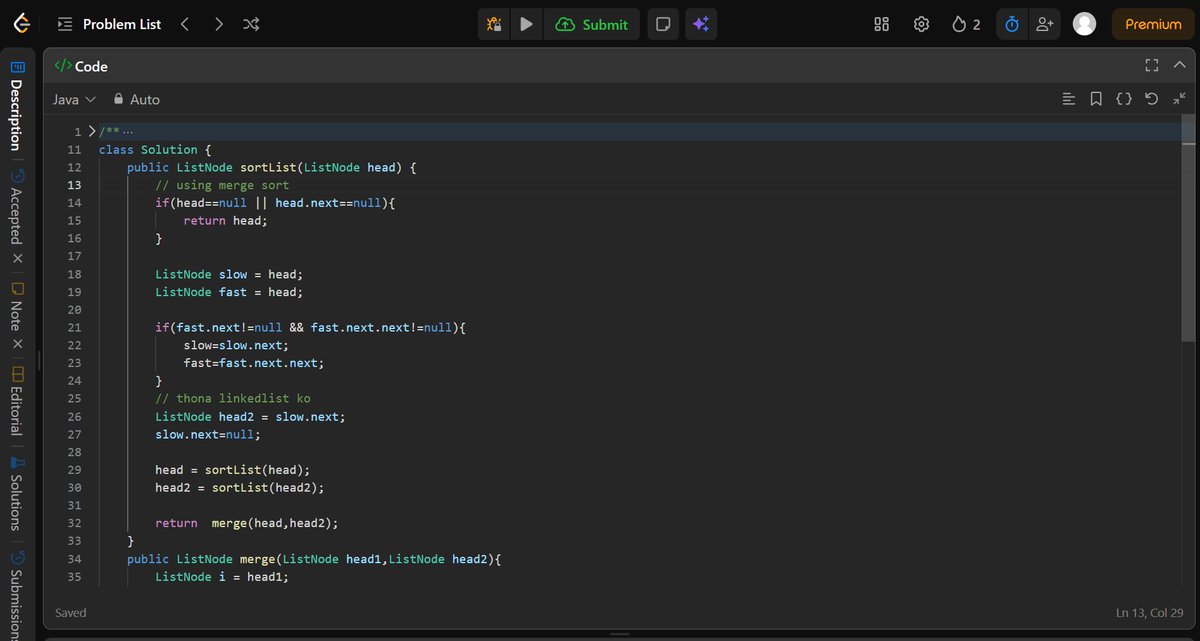
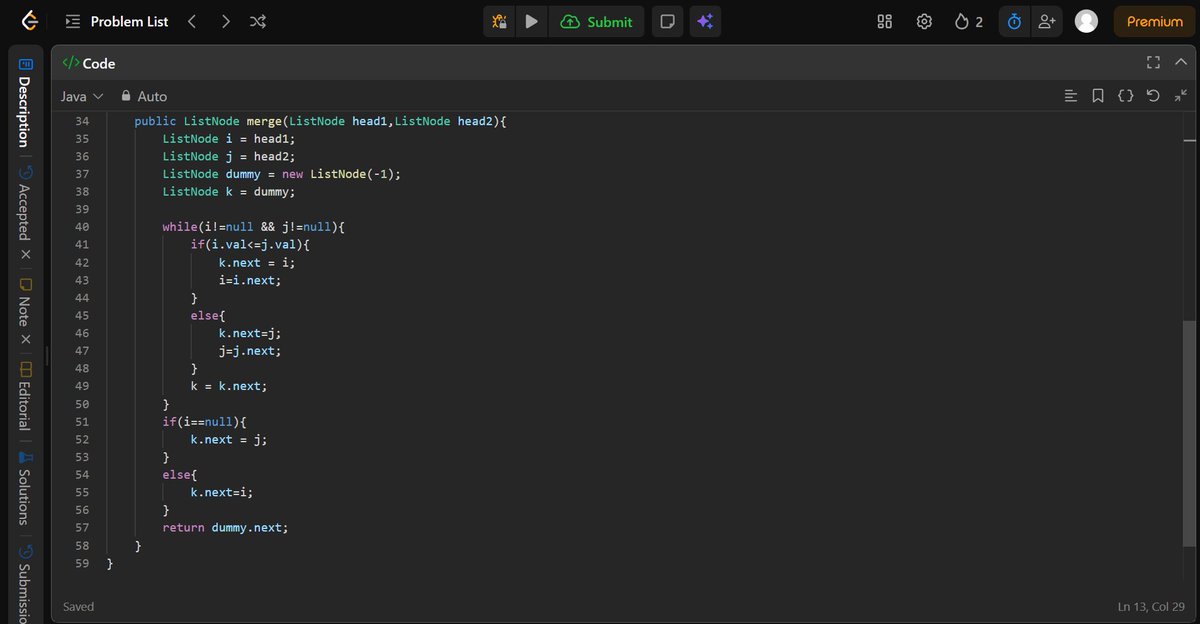
Today I solved LeetCode #148 (Sort List) using the Merge Sort approach.
While solving this problem, I gained a better understanding of recursion, linked list splitting, and merging sorted lists.
#DSA #Java #LinkedList #MergeSort #LeetCode #CodingJourney


1
14

Jun 7
例えば Quick Sort は「最良で」O(n logn)なのに対して MergeSort は「常に」O(n logn)。しかし定数項の所とかnに比例する所とかが大きいので『nが十分に大きくないと』Quick Sort の方がはやく終わるという現象を起こす。
「nが小さい間はOで比較できない」を表現しているのでは?
477

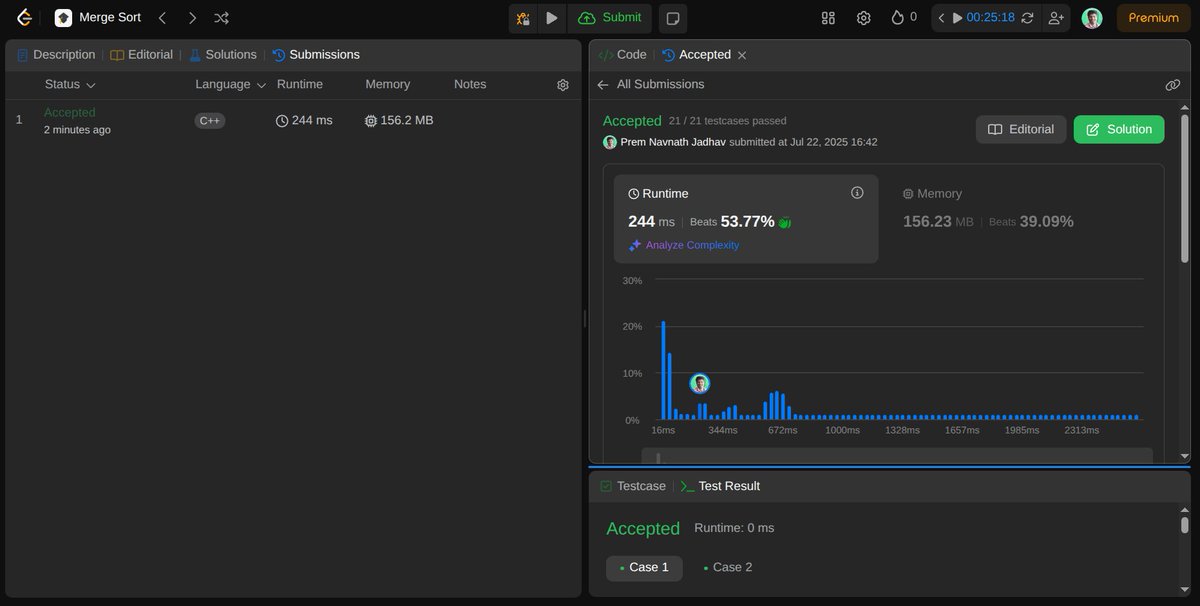
🚀 Day 219 of #100DaysOfCode
✅ Solved Merge Sort on LeetCode
🧠 Implemented recursive merge logic with dynamic memory allocation
📊 Runtime: 244 ms (Beats 53.77%)
💾 Memory: 156.2 MB (Beats 39.09%)
Keep learning, keep sorting! 🔁💡
#LeetCode #CPP #DSA #MergeSort #CodingJourney
5
50

Jun 6
Day 06 - #SDESheetChallenge
@striver_79
@takeUforward_
Q1:- on a battlefield if opposing soldiers eliminate each other; survivors more likely belong to majority
Q2:- standard DP Question
Q3:- OG MergeSort
1
8
Day 06 - #SDESheetChallenge
@striver_79 @takeUforward_
Q1:- on a battlefield if opposing soldiers eliminate each other; survivors more likely belong to majority
Q2:- standard DP Question
Q3:- OG MergeSort

1
2
63

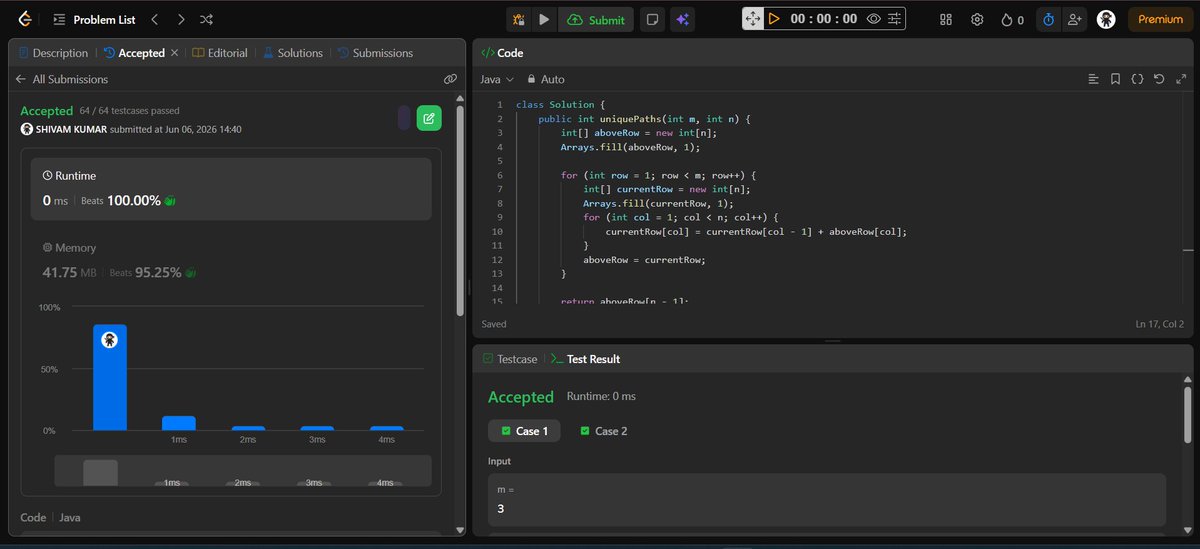
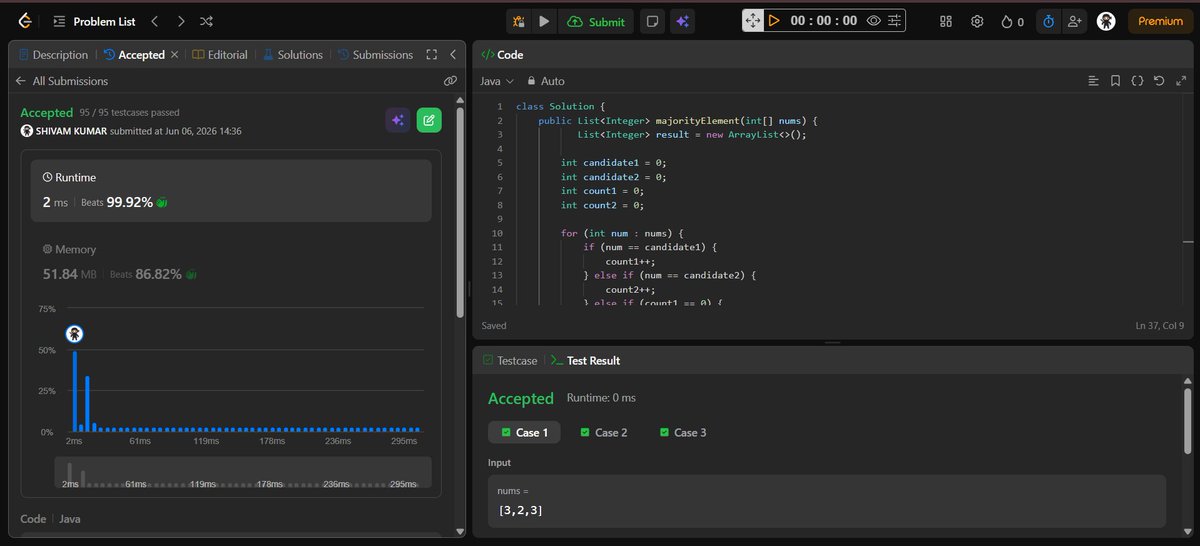
🚀 Day 6 of #SDESheetChallenge @takeUforward_ @striver_79
Solved:
✅ Majority Element-II
✅ Grid Unique Paths
✅ Reverse Pairs
Key learnings:
🔹 Boyer-Moore
🔹 Combinatorics
🔹 Modified MergeSort
#SDESheetChallenge


22
365

Jun 4
Day 4 of #SDESheetChallenge
Solved 3 array problems today:
✅ Count Inversions (Merge Sort)
✅ Find the Duplicate Number
✅ Find the Repeating and Missing Number
GitHub: github.com/batman-rises/POTD…
#DSA #LeetCode
@striver_79 @takeUforward_
#MergeSort
4
34

Jun 4
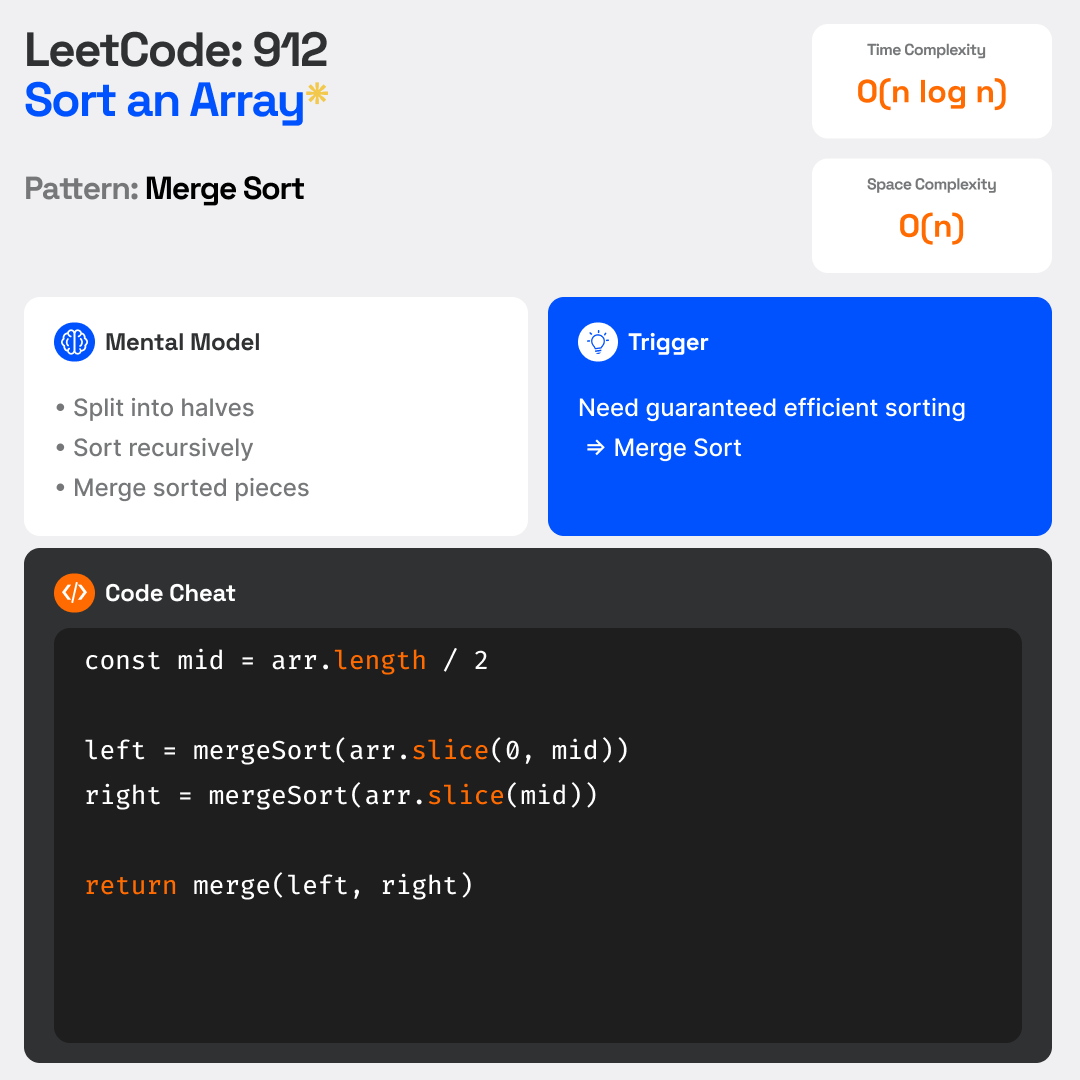
Merge Sort finally made recursion click for me ⚡
Break problem into smaller sorted pieces,
then merge everything back.
#DSA #LeetCode #Algorithms #MergeSort #CodingInterview
1
97

Jun 4
Done with Day4 Challenge! would have never thought the mergesort approach for inversion! rest two were solved using unordered-map.
#SDESheetChallenge

6
12
123


May 30
JavaにはJDK7から2種類のソートアルゴリズムが実装されている。安定性が不要なプリミティブ向けにDual-Pivot QuickSort、安定性が必要なオブジェクト向けにTimSort。今やレガシーなQuickSortやMergeSortは使われていない
1
5
13
1,377

May 27
Yes. Cache misses increase a lot if I increase the range of the input numbers.
-10k to 10k:
mergesort 21s
fenwick 14s, 65M cache misses
-100M to 100M:
mergesort 26s
fenwick 47s, 16G cache misses
1
33
May 27
I had Grok code me a simple brute force solution in cuda and it's faster at 100k, about even at 1M and slower at 10M than a singlethreaded C solution using Fenwick trees or mergesort. Even with very good optimization I don't see billions being realistic with brute force.
1
1
37

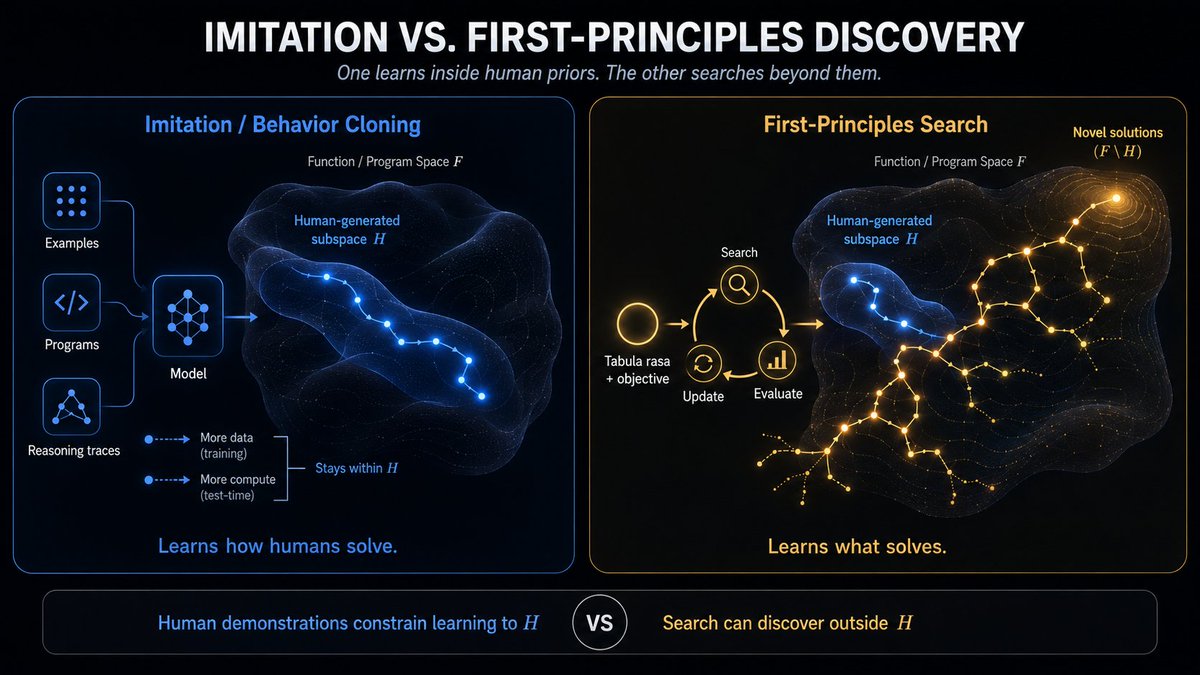
If you train on (unsorted list, bubble sort procedure, sorted list) traces, you will never test time compute (TTC) your way to mergesort.
So frontier lab ppl say "well we dont just train on 1 algo, we train on many classes of sort algo's so it should be able to explore the function space of sort".
You are still limited then.
Lets for example say we dont know about non-comparative sort (radix sort). But we train on all comparative sort algos.. same issue. it wont sample non-comparative sort algos! How? It doesnt think orthogonally? But ppl do!
OAI STILL think this is the path to AGI?!
It cant be.
Modern LLM stack today is essentially imitation learning small amount of search via TTC (test time compute) leveraging gen-verifier gap to self-distill back into the weights.
This will always confine you to the train manifold of function space to search.
This makes novel programs that are much better but far outside the human manifold almost impossible to TTC your way to find.
We need to teach the model a more general search procedure to explore the full hypothesis space without such heavy bias to human thinking (e.g. AlphaZero). People have given up on this bc at large action spaces such DQN MCTS collapses. The idea shouldnt be thrown out just because the implementation of it doesnt scale. But thats what it seems everyone has done.
If we want true AGI, we need models that can think from first principles, branching/exploring in a clever way to go the rest of the distance. Essentially mimicking the scientific method.
Asking the RIGHT question / conducting a CLEVER experiment to reduce the hypothesis space.
Why do frontier labs not get this yet? Or is this a psyops on us all?
8
4
42
9,708

May 15
Quicksort is "fastest" in average operation (O(n log n)), but can degrade to O(n²).
Heapsort is O(n log n) in worst case.
Mergesort is always O(n log n).
But their space and setup costs are different. So, quicksort is usually the best choice.
1
38