
Feb 20
Updates:
Excited to share that Agent Data Protocol (ADP) is accepted to ICLR 2026 Oral! 🎉
We also added support for 3 new datasets: SWE-Play, MiniCoder, and Toucan, bringing us to 3M trajectories supported.
If you're training agentic LMs, try ADP tell us what dataset/agent format you want next. PRs & requests welcome. Let's make this the open standard for agent training data 🔥
🚀Original post: x.com/yueqi_song/status/1983…
📄Read our paper: arxiv.org/abs/2510.24702
🌐Check our project website: agentdataprotocol.com
29 Oct 2025

We just built and released the largest dataset for supervised fine-tuning of agentic LMs, 1.27M trajectories (~36B tokens)!
Up until now, large-scale SFT for agents is rare - not for lack of data, but because of fragmentation across heterogeneous formats, tools, and interfaces.
To solve this, we introduce the Agent Data Protocol, a new “interlingua” between a broad variety of heterogeneous agent datasets - coding, browsing, API/tool use - and unified agent training pipelines downstream.
We unified 13 datasets into ADP, converted them to be compatible with multiple agent frameworks, and observed ~20% average gains, reaching SOTA/near-SOTA without domain-specific tuning.
📄 Read our paper: arxiv.org/abs/2510.24702
🌐 Check our project website: agentdataprotocol.com/
And this is just getting started, we can add more datasets, further expand the resources, and make training agent LMs easy for all. We’d love to have you join the shared effort and help to make ADP the open standard for the community 🚀
5
19
130
116,762



1 Aug 2025

2
5
198

7 Jul 2025
Kid casually writing C like it’s his personal diary 😂
Not coding storytelling in machine language!
#TechProdigy #MiniCoder #FutureDeveloper #CodeLife #CppHumor #YoungGenius #ProgrammerKid #NextGenCoder #DevHumor #GeekMode #Tesla
#AI
#ElonMusk
#OpenAI
#Crypto
#Bitcoin
#SpaceX
11
173

29 Apr 2022
Ojo @guinxu aquí "minicoder" analizando minuciosamente @FlatworldGame y la noche es joven 😄
pd. le encanta👍

1
33

15 Nov 2021
Check out our beginner level Coding for Kids Course and sign up your mini coder today! 💻👇
buff.ly/3CihE8x
#minicoder #codingforkids #choosecollege #dundeeandanguscollege


4
4

26 Feb 2020
#HBD25thAlan
@soyalannavarro #minicoder te manda un gran abrazo, gracias por ser siempre tan lindo. Te amamos

3
2
8

11 Aug 2019
ENCUESTA HOOOOOOOOOOOOYYYYY ES SÁBADOOOOOOO COOOOODEEEEERRRRRRRR #CD9Fails ESTABA EN LA CALLE Y VEO A UNA MINICODER CON UNA PLAYERA DÉ CD9
0%
NEEEEEETAAAAAA MICH
50%
MINICODER ASDFGGHHJKL
0%
PLAYERA DÉ CD9 AWWW
50%
TÉ EMOCIÓNASTEEEEE
4 votes • Final results
1
1
3

7 Jun 2019
#My #MiniCoder @GirlsWhoCode @codeorg #Thanks #CodeOrg for such an #interactive #learning #experience

2

Our minicoder project counts 480 children that take part - do you like our new logo designed by :m team player Francesca? #mondora #BCorp #BCorporation #BTheChange #MinicoderProject #Innovation

3


14 Dec 2018
Proud mom moment. Telling your littlest daughter she can leave the hint minecraft code in and start from there and her responding “yeah, but I like erasing it and doing it all myself” studio.code.org/s/aquatic/st… #minicoder #girlsrule
7

20 Oct 2018
And the winner of the weekend goes to this little man - who found the bug in his dads, @the_culture_guy code - enjoy 😉 .
.
#kcbuild18 #minicoder #dev #developer #webdev #buildtheweb #hackathon #hackathon2018 ift.tt/2pYI8sS

1
7

22 Jun 2018
How's about that? UK Government has launched new #InstituteofCoding - bit.ly/2tnRlw2. We at #IvyKids say, start them off early w/ a copy of #Coder Academy🤖👾 by Sean McManus @musicandwords 👍! #Coding #coders #minicoder #codingforkids #childrensbooks

1
2

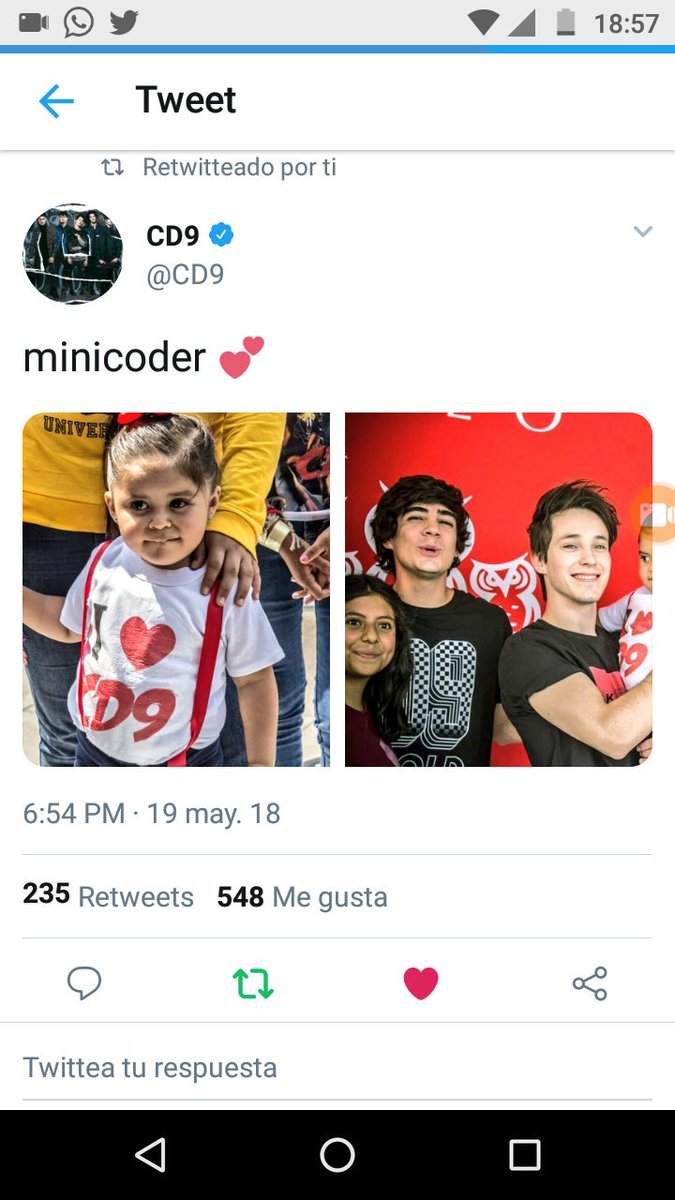
20 May 2018
En mi casita hay una minicoder que espera verlos pronto
P.D:A pesar de su corta edad le gusta Freddy & Jos 🙊😍😏
1






30 Jan 2018
Check it out! minicoder will develop your shopify store for $5 on #Fiverr fiverr.com/s2/9d90970a5c
#microjobs
#gigbucks
#fourerr
#Seoclerks
#CodeClerks
#oDesk
1
2
22 Dec 2017
Check it out! minicoder will create, customize, fix your joomla website for $5 on #Fiverr fiverr.com/s2/179ad31879
2