
23h
🚨 Hugging Face published a vendor blog showing FLUX.2 [klein] can be fine-tuned with a LoRA in under 60 minutes. If that speed holds in practice, procurement can shift mo…
🔗 atlas360.news/en/news/huggin…
📩 Subscribe: atlas360.news/en/bulten
#followthelabor #orgchart #modelfinetuning
1
204

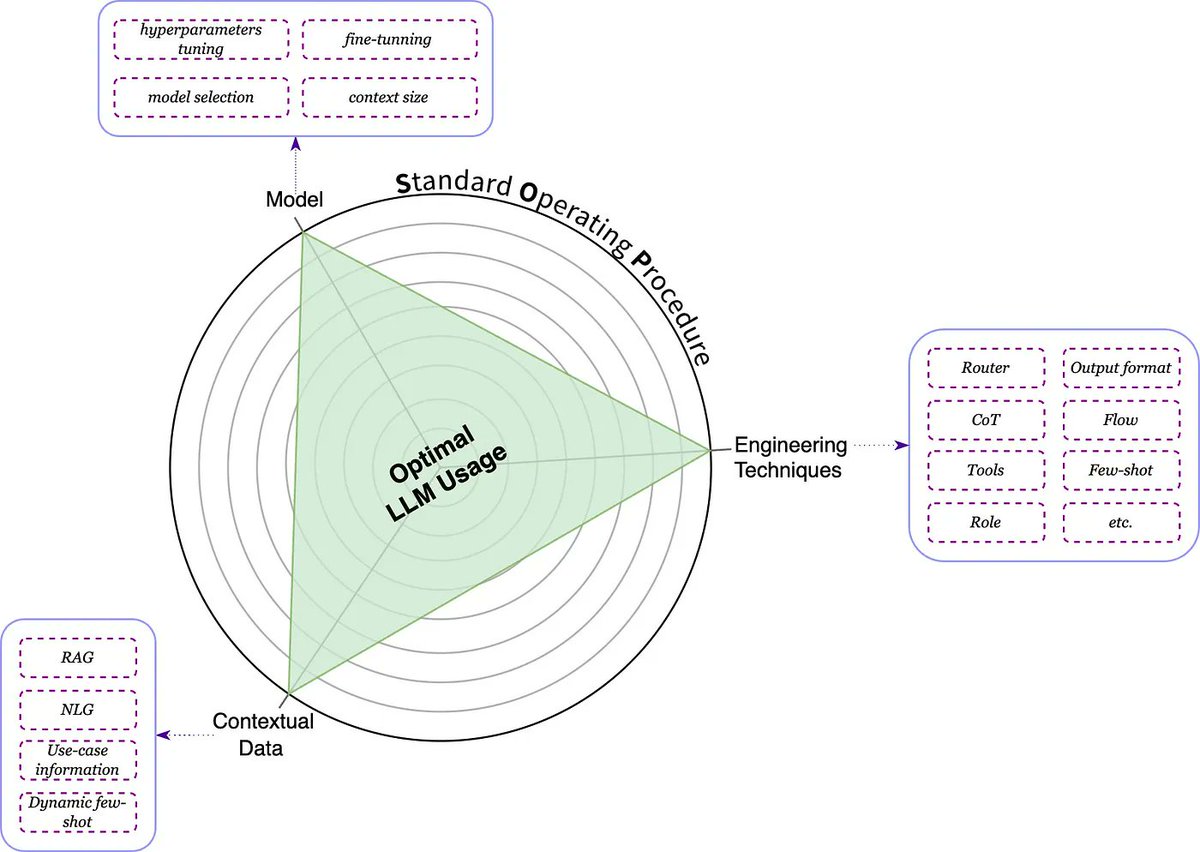
🔺✨ The LLM Triangle Principles to Architect Reliable AI Apps
📋🔧 SOP Importance: SOP guides LLM app design, transforming LLMs from simple models to expert systems for complex tasks.
⚙️🔗 Engineering Techniques: Key to implementing SOP and optimizing LLM-native app performance using workflows, chains, and agents.
📚🧠 Role of Background Data: Critical for LLM performance, providing structured information for better task understanding and execution.
🏋️💡 Model Selection Considerations: Balancing functionality and cost, tailored to task needs and application context.
🔄🔐 Challenges of Model Fine-Tuning: Enhances performance but involves privacy, compliance, and cost issues.
🔺📈 Implementing LLM Triangle Principles: Focus on SOP, engineering techniques, and background data to build reliable, high-performing LLM-native apps. From concept to production, these principles provide essential guidance.
#AI #LLM #MachineLearning #SoftwareDesign #Engineering #DataScience #AIDevelopment #SOP #ContextData #ModelFineTuning
1
4
184
通过原始文本数据微调 Instruct 模型 用最少的对话数据微调现代聊天机器人,只需不到 10 美元
总结:通过对 The Guardian 的 manage-frontend 仓库进行微调 Mistral 的 7B Instruct v0.2 模型(数据集为 160 万 tokens),探索一种成本效益高、易于使用的模型微调方法。这种方法特别适用于没有深度学习工程经验的软件开发人员。
1. 实验目的与方法
1.1 实验目的 本实验旨在探索使用较小数据集微调现代聊天机器人的方法,目标是在128K上下文窗口和数十亿令牌的模型微调复杂性之间找到平衡。
通过这种方式,我们希望在保持模型性能的同时,实现经济高效的领域适应。特别是对于没有深度学习工程经验的软件开发人员来说,我们强调了一种既成本效益高又易于使用的模型微调方法,这对于希望提升其聊天机器人性能但资源有限的开发者来说非常有价值。
1.2 实验方法 我们选择了Mistral的7B Instruct v0.2模型作为基础模型,并在The Guardian的manage-frontend仓库(约160万token)上进行微调。此外,我们强调了使用易于获取的硬件进行成本效益高的模型微调的可重复性指导方针,旨在最小化试错并最大化使用原始文本数据而非标记的对话数据的效率。
2. 训练资源与库
2.1 训练资源 实验中使用了Nvidia A100 40GB和H100 80GB进行训练,以确保训练过程的高效性和可靠性。
2.2 训练库 为了提高训练速度和内存效率,我们采用了Unsloth库。同时,使用了trl库中的SFTtrainer作为HuggingFace训练器的包装器,以准备数据集进行自监督训练。
3. 数据集创建
3.1 数据集组成 原始数据集包括仓库的wiki、主分支的快照以及最后100个拉取请求的评论和代码更改,以确保数据的多样性和丰富性。与依赖大量标记会话数据的现有微调方法不同,本文采用的方法更加注重原始文本数据的使用,减少了对标记会话数据的依赖。这种方法为如何在数据受限的情况下进行有效微调提供了新的视角。 ### 3.2 数据抓取 通过复制粘贴每个wiki页面到文本文件中来抓取wiki数据,并编写了Python脚本本地运行,抓取代码库并将所有文件写入文本文件。
3.3 合成对话数据 使用GPT-4 Turbo API和特定指令生成了标记的对话数据,虽然这些数据是合成的,但可以帮助缓解灾难性遗忘和性能下降。这为如何增强模型的记忆和性能提供了一种可行的策略。
4. 模型训练与超参数
4.1 超参数选择 通过手动搜索确定了影响模型性能的最佳超参数,包括LoRA等级、批量大小和学习率。发现2e-5的学习率是最优的,这似乎是微调Mistral的标准。
4.2 优化过程 在找到最优超参数后,重新运行训练以包含所有数据,这是常见做法。
5. 实验结果与分析
5.1 性能提升 实验结果优于预期,微调后的模型能够准确回答与代码库相关的复杂问题,并在回答涉及JavaScript和Typescript的问题时,能够将`manage-frontend`代码库中的模式融入回应中。通过Gradio应用展示的微调模型实际效果超出预期,这不仅验证了微调方法的有效性,也为其他开发者提供了一种可视化和实验验证微调效果的途径。
5.2 灾难性遗忘 对于非代码相关问题,微调模型的性能有所下降,例如速度单位的错误。灾难性遗忘现象比预期的要轻,但在微调模型和基础模型之间仍然存在明显差异。
6. 文本生成策略
6.1 确定性方法 在文本生成中采用了确定性方法,使用贪婪搜索选择最可能的下一个词或词序列。这种策略在保证生成文本质量的同时,也减少了生成过程的不确定性。采用确定性的方法进行文本生成,通过贪婪搜索选择最可能的词或词序列,这种策略在保证生成文本质量的同时,也减少了生成过程的不确定性。
7. 为何这些超参数表现最佳
7.1 批量大小与变异性 使用较低的批量大小引入更多的变异性和噪声到梯度估计中,允许优化器更动态地响应数据点的特定特征。
7.2 LoRA等级与学习能力 较高的LoRA等级增加了模型学习任务特定细节的能力,而较低的等级导致更多的遗忘。较高的LoRA等级提供了更多的可训练参数,使模型能够更“智能”地学习新数据的细节,而2048的等级则允许模型过多地偏离其宝贵的预训练知识。 通过整合这些核心点,实验报告更加全面地展示了成本效益高且易于使用的微调方法,以及使用有限的原始文本数据和合成生成的对话数据在提升聊天机器人性能方面的潜力。此外,实验结果与实际应用部分强调了微调方法的有效性,而文本生成策略部分则突出了采用确定性方法的优势。 #TheGuardian #Chatbot #ModelFineTuning #DeepLearning #SoftwareDevelopment

Fine-tuning Instruct Models with Raw Text Data
Economically Efficient Chatbot Training with Minimal Dialogue Data for Under $10
Summary: This experiment explores a cost-effective and user-friendly approach to fine-tuning Mistral's 7B Instruct v0.2 model on a dataset of 1.6 million tokens from The Guardian's manage-frontend repository. The method is particularly suitable for software developers without deep learning engineering experience.
1. Objective and Method
1.1 Objective:
The experiment aims to find a balance between the complexity of fine-tuning models with billions of tokens and a 128K context window. The goal is to achieve domain adaptation economically while maintaining model performance.
This method is highlighted for its cost-effectiveness and ease of use, especially valuable for developers with limited resources who want to enhance their chatbot's performance without deep learning engineering experience.
1.2 Method:
We fine-tuned Mistral's 7B Instruct v0.2 model on The Guardian's manage-frontend repository, approximately 1.6 million tokens.
We emphasized repeatable guidelines for cost-effective model fine-tuning using readily available hardware, aiming to minimize trial and error and maximize efficiency using raw text data instead of labeled dialogue data.
2. Training Resources and Libraries
2.1 Resources:
Nvidia A100 40GB and H100 80GB were used for training to ensure efficiency and reliability.
2.2 Libraries:
The Unsloth library was used for speed and memory efficiency during training. The SFTtrainer from the trl library served as a wrapper for the HuggingFace trainer to prepare the dataset for self-supervised training.
3. Dataset Creation
3.1 Composition:
The original dataset included the repository's wiki, a snapshot of the main branch, and the last 100 pull request comments and code changes to ensure diversity and richness.
Unlike existing fine-tuning methods that rely on a large amount of labeled dialogue data, our approach focuses more on the use of raw text data, reducing reliance on labeled dialogue data. This provides a new perspective on how to fine-tune effectively with limited data.
3.2 Data Scraping:
Wiki data was scraped by copying and pasting each wiki page into text files, and Python scripts were written to run locally, scraping the code repository and writing all files into text files.
3.3 Synthetic Dialogue Data:
Labeled dialogue data was generated using the GPT-4 Turbo API and specific instructions, which, although synthetic, helped mitigate catastrophic forgetting and performance degradation. This offers a viable strategy for enhancing model memory and performance.
4. Model Training and Hyperparameters
4.1 Hyperparameter Selection:
Optimal hyperparameters affecting model performance, such as LoRA levels, batch size, and learning rate, were determined through manual search. A learning rate of 2e-5 was found to be optimal, which seems to be the standard for fine-tuning Mistral.
4.2 Optimization Process:
After finding the optimal hyperparameters, training was rerun to include all data, a common practice.
5. Results and Analysis
5.1 Performance Improvement:
The results exceeded expectations, with the fine-tuned model accurately answering complex questions related to the codebase and incorporating patterns from the `manage-frontend` repository into responses to questions involving JavaScript and Typescript. The actual performance of the fine-tuned model, demonstrated through a Gradio app, surpassed expectations, validating the effectiveness of the fine-tuning method and providing other developers with a way to visualize and experimentally verify the fine-tuning effects.
5.2 Catastrophic Forgetting:
Performance on non-code-related questions, such as incorrect speed units, declined for the fine-tuned model. Catastrophic forgetting was lighter than expected, but a clear difference still existed between the fine-tuned model and the base model.
6. Text Generation Strategy
6.1 Deterministic Approach:
A deterministic approach was used in text generation, selecting the most likely next word or sequence of words using greedy search. This strategy ensured the quality of generated text while reducing uncertainty in the generation process.
7. Why These Hyperparameters Performed Best
7.1 Batch Size and Variability:
A lower batch size introduced more variability and noise into the gradient estimates, allowing the optimizer to respond more dynamically to specific features of data points.
7.2 LoRA Levels and Learning Capacity:
Higher LoRA levels increased the model's ability to learn task-specific details, while lower levels led to more forgetting. Higher LoRA levels provided more trainable parameters, allowing the model to learn details of new data more "intelligently," while a level of 2048 allowed the model to deviate too much from its valuable pre-trained knowledge.
Integrating these core points, the experimental report comprehensively presents a cost-effective and user-friendly fine-tuning method and the potential of using limited raw text data and synthetically generated dialogue data to enhance the performance of chatbots. Additionally, the results and practical application sections underscore the effectiveness of the fine-tuning method, while the text generation strategy section highlights the advantages of using a deterministic approach.
#TheGuardian #Chatbot #ModelFineTuning #DeepLearning #SoftwareDevelopment

1
6
786
Fine-tuning Instruct Models with Raw Text Data
Economically Efficient Chatbot Training with Minimal Dialogue Data for Under $10
Summary: This experiment explores a cost-effective and user-friendly approach to fine-tuning Mistral's 7B Instruct v0.2 model on a dataset of 1.6 million tokens from The Guardian's manage-frontend repository. The method is particularly suitable for software developers without deep learning engineering experience.
1. Objective and Method
1.1 Objective:
The experiment aims to find a balance between the complexity of fine-tuning models with billions of tokens and a 128K context window. The goal is to achieve domain adaptation economically while maintaining model performance.
This method is highlighted for its cost-effectiveness and ease of use, especially valuable for developers with limited resources who want to enhance their chatbot's performance without deep learning engineering experience.
1.2 Method:
We fine-tuned Mistral's 7B Instruct v0.2 model on The Guardian's manage-frontend repository, approximately 1.6 million tokens.
We emphasized repeatable guidelines for cost-effective model fine-tuning using readily available hardware, aiming to minimize trial and error and maximize efficiency using raw text data instead of labeled dialogue data.
2. Training Resources and Libraries
2.1 Resources:
Nvidia A100 40GB and H100 80GB were used for training to ensure efficiency and reliability.
2.2 Libraries:
The Unsloth library was used for speed and memory efficiency during training. The SFTtrainer from the trl library served as a wrapper for the HuggingFace trainer to prepare the dataset for self-supervised training.
3. Dataset Creation
3.1 Composition:
The original dataset included the repository's wiki, a snapshot of the main branch, and the last 100 pull request comments and code changes to ensure diversity and richness.
Unlike existing fine-tuning methods that rely on a large amount of labeled dialogue data, our approach focuses more on the use of raw text data, reducing reliance on labeled dialogue data. This provides a new perspective on how to fine-tune effectively with limited data.
3.2 Data Scraping:
Wiki data was scraped by copying and pasting each wiki page into text files, and Python scripts were written to run locally, scraping the code repository and writing all files into text files.
3.3 Synthetic Dialogue Data:
Labeled dialogue data was generated using the GPT-4 Turbo API and specific instructions, which, although synthetic, helped mitigate catastrophic forgetting and performance degradation. This offers a viable strategy for enhancing model memory and performance.
4. Model Training and Hyperparameters
4.1 Hyperparameter Selection:
Optimal hyperparameters affecting model performance, such as LoRA levels, batch size, and learning rate, were determined through manual search. A learning rate of 2e-5 was found to be optimal, which seems to be the standard for fine-tuning Mistral.
4.2 Optimization Process:
After finding the optimal hyperparameters, training was rerun to include all data, a common practice.
5. Results and Analysis
5.1 Performance Improvement:
The results exceeded expectations, with the fine-tuned model accurately answering complex questions related to the codebase and incorporating patterns from the `manage-frontend` repository into responses to questions involving JavaScript and Typescript. The actual performance of the fine-tuned model, demonstrated through a Gradio app, surpassed expectations, validating the effectiveness of the fine-tuning method and providing other developers with a way to visualize and experimentally verify the fine-tuning effects.
5.2 Catastrophic Forgetting:
Performance on non-code-related questions, such as incorrect speed units, declined for the fine-tuned model. Catastrophic forgetting was lighter than expected, but a clear difference still existed between the fine-tuned model and the base model.
6. Text Generation Strategy
6.1 Deterministic Approach:
A deterministic approach was used in text generation, selecting the most likely next word or sequence of words using greedy search. This strategy ensured the quality of generated text while reducing uncertainty in the generation process.
7. Why These Hyperparameters Performed Best
7.1 Batch Size and Variability:
A lower batch size introduced more variability and noise into the gradient estimates, allowing the optimizer to respond more dynamically to specific features of data points.
7.2 LoRA Levels and Learning Capacity:
Higher LoRA levels increased the model's ability to learn task-specific details, while lower levels led to more forgetting. Higher LoRA levels provided more trainable parameters, allowing the model to learn details of new data more "intelligently," while a level of 2048 allowed the model to deviate too much from its valuable pre-trained knowledge.
Integrating these core points, the experimental report comprehensively presents a cost-effective and user-friendly fine-tuning method and the potential of using limited raw text data and synthetically generated dialogue data to enhance the performance of chatbots. Additionally, the results and practical application sections underscore the effectiveness of the fine-tuning method, while the text generation strategy section highlights the advantages of using a deterministic approach.
#TheGuardian #Chatbot #ModelFineTuning #DeepLearning #SoftwareDevelopment
1
2
953

8 Aug 2023
Calling all Deep Learning experts! Is there a guide on how to fine-tune a seq2seq model to transition it to a decoder-only architecture? Seeking insights! 🚀 #ModelFineTuning #deeplearning
3
134