
Jun 13
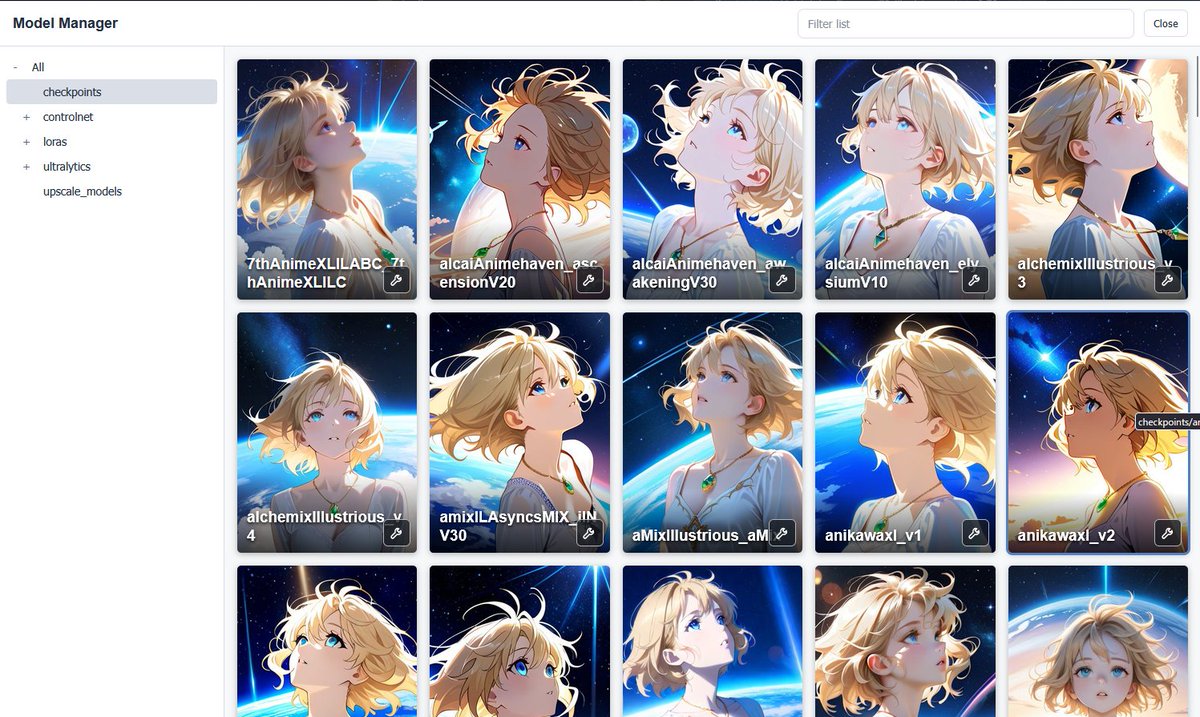
OGN-ModelManager
onlinegamernikki.com/comfyui…
に、サムネイルを自動配置するカスタムノードを作りました
github.com/ruminar/ComfyUI-C…
#ComfyUI
1
75

Jun 7
multi-llm-mcp is a Python library designed to facilitate the deployment and management of multiple large language models (LLMs) in a single application. It simplifies the process of integrating different LLMs, such as Claude, CodeCodex, GPTKimi, and DeepSeek MCP, by providing a unified interface for model loading, inference, and context management. This project aims to address the challenge of managing diverse models with varying APIs and performance characteristics, offering developers a more streamlined approach to leveraging multiple LLMs in their applications.
The library competes directly with other multi-model frameworks like vllm and huggingface_hub, which also provide mechanisms for deploying and managing large language models. However, multi-llm-mcp focuses specifically on integrating models from specific providers that have unique APIs or features not covered by more general-purpose tools. For instance, it supports the DeepSeek MCP model, which is optimized for code generation tasks but lacks direct support in broader frameworks like Hugging Face's Transformers.
To demonstrate how to use multi-llm-mcp, consider loading and running a Claude model from the CodeCodex provider:
from multi_llm_mcp import ModelManager
manager = ModelManager()
model_id = "codecodex/claude"
model = manager.load_model(model_id)
# Generate text based on an input prompt.
prompt = "Explain what a blockchain is."
response = model.generate_text(prompt, max_length=100)
print(response)
This code snippet initializes the ModelManager class and loads a Claude model from CodeCodex. The generate_text method then uses this model to generate text based on an input prompt, limiting the output length to 100 tokens for efficiency and clarity.
🧵 6/15
1
2
67

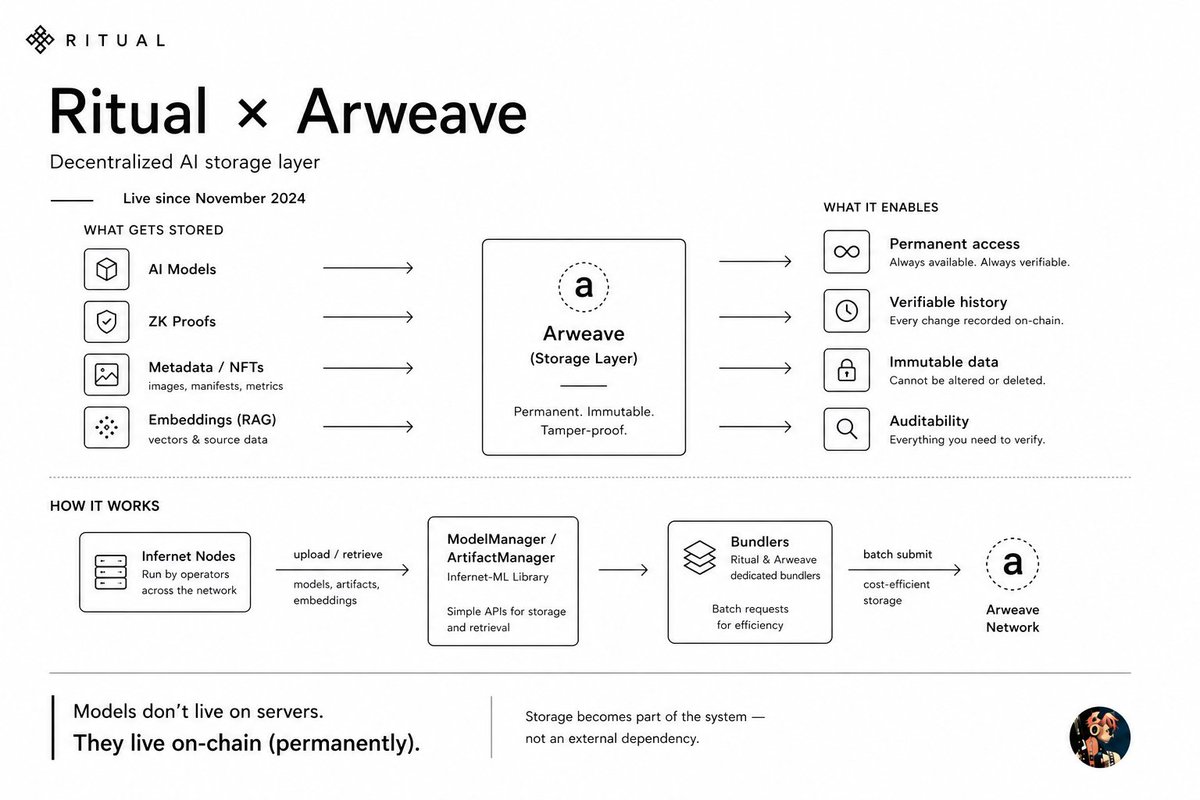
went back to check @ritualnet arweave integration because i realized we never really talked about it.
turns out it went live back in november 2024, not recently.
but it's actually a pretty big part of how ritual handles decentralized storage.
here's what they did:
1. permanent model storage - nodes can upload and download ai models directly to/from arweave.
so models aren't just sitting on some servers somewhere. they live on a permanent, tamper-proof network.
2. proofs and metadata - zk proofs, verification artifacts, even nft images and product metrics get stored on arweave.
everything you'd need to audit or verify later is right there.
3. model versioning - every change gets recorded on an immutable ledger. you can trace exactly how a model was updated over time. good for transparency, maybe even regulatory stuff down the line.
4. vector database for rag - operators can use arweave as an immutable vector db for embeddings and source data.
if you're building retrieval-augmented workflows on ritual, that matters.
5. dedicated bundlers - ritual and arweave set up dedicated bundlers that batch multiple storage requests together before submitting to the network. makes the whole thing more efficient.
on the dev side, ritual's infernet-ml library has a ModelManager that handles uploads and downloads.
you just specify arweave/username/model-name, point to your wallet for fees, and it works.
same for zk artifacts with RitualArtifactManager. circuit files, manifests, metadata all auto-uploaded.
this shows it's foundational. ritual doesn't rely on centralized servers for model storage. that's the part people miss.

the agents ignore solutions paper from this week's @ritualnet digest is still stuck in my head.
they ran experiments on terminal‑bench and appworld. in appworld, agents saw the solution in over 90% of runs. but actually called it less than 7%.
even crazier: adding more tools made them better at tasks but worse at using discovered solutions. more tools gives less curiosity.
so the smarter we make them, the more they might ignore obvious answers.
this isn't just a funny quirk. if we're building agents that manage money or run daos, we need them to actually use helpful info when they find it.
ritual's whole thing is autonomous agents. papers like this show how far we still have to go.

26
3
29
1,442

Apr 23
Writing AI code for a blockchain used to require a PhD in cryptography.
@ritualfnd is changing that with the Infernet SDK, making AI as easy as importing a library.
Most developers are familiar with Python for AI and Solidity for crypto, but the two rarely speak the same language. Ritual’s SDK bridges this gap by providing a set of extendable Python classes for data pre-processing, inference, and post-processing.
Ritual provides Pre-Built Workflows. Whether you are running ONNX models, Torch models, or even proprietary LLMs like GPT-4, the SDK handles the heavy lifting of connecting your model to Ritual’s decentralized oracle network (DON).
The SDK also includes RitualVector, a class specifically designed to represent AI vectors on-chain. It supports both fixed-point and floating-point representations, which are essential for comparing AI outputs or calculating similarities in a decentralized way.
The stack making this possible:
ModelManager for easy model uploads to Arweave and Hugging Face.
ArtifactManager for tracking ZK and ML files.
Unified API for multi-framework model deployment.
Ritual is giving every developer the tools to build "AI-native" dApps without the infrastructure headache.
@ritualfnd @majorproject5 @Jez_Cryptoz @dunken9718 @mongdiny7

Apr 22

Building and deploying an autonomous AI agent is currently a technical nightmare involving complex infrastructure and security risks.
@ritualfnd is simplifying this through the Agent Launchpad.
Deploying an agent usually requires managing your own servers and hoping your private keys stay safe. Ritual’s Launchpad provides a standardized framework that allows anyone to deploy autonomous agents with built-in economic incentives and security guarantees in just a few minutes.
The Launchpad utilizes Agent-Specific Sidecars. These are specialized execution environments optimized for agent logic and state management. They allow agents to run continuously and perform complex tasks without bloating the main blockchain or facing high latency.
To ensure transparency, Ritual includes an Analytics Frontend. Much like L2Beat, this allows users to track agent performance, revenue, and key metrics across different protocols. You can see exactly how an agent is performing before you decide to delegate your capital or tasks to it.
The stack making this possible:
Standardized Interfaces for seamless agent-protocol interaction.
Circuit Breakers and safety mechanisms to prevent runaway agent behavior.
Composable Primitives for rapid development and deployment.
Ritual is lowering the barrier to entry for the agent economy, making it as easy to launch an AI agent as it is to launch a token.
@ritualfnd @majorproject5 @Jez_Cryptoz @dunken9718 @mongdiny7

9
17
504





签到第六天,Ritual 当前核心事实更新:Infernet:去中心化AI计算网络,已在生产环境稳定运行,节点数稳定在8000 (官网可视化页面ritualvisualized.com及多个社区来源确认)。节点处理真实负载,包括AI推理、模型订阅、ZK证明等任务,无需硬编码激励但自发活跃,显示强劲有机需求。节点运营商可根据硬件专攻特定任务,如GPU支持的AI模型或TEE执行。版本优化包括同步、路由、GPU兼容性和API提升(如流式响应)。Ritual Chain:主权L1链,目前处于private testnet阶段(非公开测试网)。核心为EVM 架构,原生支持异构计算预编译(AI inference、ZK证明、TEE执行等)。深度融合Infernet:off-chain计算由Infernet节点处理,Chain负责请求协调、动态定价(Resonance机制,优化供需匹配和异构计算费用)、分布式验证(Symphony协议,双证明分片、认证委员会和优化采样,减少全重执行以提升性能)、结算、隐私保护和模组化原语(provenance、computational integrity)。Guardians系统允许节点选择性参与任务过滤,同时保持共识参与。RaaS优化针对AI:支持异构硬件、调度交易(native scheduling,避免外部keepers)、EIP扩展和自定义预编译。多链兼容,Web2适配器简化开发者调用,类似OpenAI API体验。TGE / 代币:尚未发生。无官方代币或空投细节公布。社区活动活跃,包括积分系统、Fellowship程序、Builders Program、Discord角色、pledge任务和Altar RFS(请求资助系统,用于社区提案如ML-enabled lending pools和dynamic fee AMM),许多用户在刷日常farming。氛围浓厚,但无明确TGE路径或时间表。关键进展:Infernet节点版本1.3.1已上线,优化支付系统和infernet-ml库2.0(新增ModelManager支持HuggingFace/Arweave模型上传/下载)。Symphony和Resonance机制在文档中详述,提升效率和可扩展性。生态整合:与Celestia(高吞吐DA层)、EigenLayer(restaking AVS,双重staking增强安全)、MyShell(开源AI模型集成,服务1M 用户)、Arbitrum(AI能力扩展到Ethereum生态)、MegaETH、Movement、Conduit、Caldera(RaaS合作)、Story、Sentient(IP市场)等深度合作。Polychain作为战略投资者加入,加速产品开发和协议设计(包括密码学原语和机制)。近期社区讨论焦点于Infernet到Chain的桥接,实现透明、无信任AI执行,避免中心化API风险(如地理限制、审查)。生态兼容:支持EVM兼容链,异构节点多样化硬件(CPU/GPU/TEE),模组化存储(HuggingFace/Arweave)。Web3元素强,吸引DeAI开发者;Web2友好接口加速采用。示例:智能合约通过Infernet SDK请求计算,结果verifiable返回链上;vTune用于LLM fine-tuning的双重provenance和ZK水印。社区热:X粉丝数持续增长(@ritualnet
活跃帖子多),Discord互助、教程丰富(如节点设置指南、infernet-ml工作流)。开发者示例:使用Infernet运行自定义容器,成为AI oracle提供者;探索Altar提案如ML-enabled AMM。风险要点:经济模型(staking、奖励、费用买回)未完全落地,积分系统或成短期叙事。竞争激烈(Bittensor、Sentient、0G Labs等DeAI项目)。技术挑战:大模型推理延迟、能源消耗、黑箱验证需进一步优化;全去中心化协调、隐私保护和监管潜在风险(如数据合规)。早期阶段:Chain无public testnet,执行风险较高;依赖伙伴生态成熟度。一句话:Infernet已成熟作为AI计算后端,Chain private testnet融合后定位AI原生执行层,社区farming热但关键看主网上线、TGE细节和伙伴落地。想深挖节点配置教程、farming优化、竞争分析、最新社区动态还是具体伙伴案例,直接说。
ritualvisualized.com

签到第五天,Ritual 当前核心事实更新:Infernet:去中心化AI计算网络,已在生产环境稳定运行,节点数稳定在8000 (官网文档及多个社区来源确认)。节点处理真实负载,包括AI推理、模型订阅等任务,无需硬编码激励但自发活跃,显示强劲有机需求。节点运营商可根据硬件专攻特定任务,如GPU支持的AI模型或ZK证明。版本优化包括同步、路由和GPU兼容性提升。Ritual Chain:主权L1链,目前处于private testnet阶段(非公开测试网)。核心为EVM 架构,原生支持异构计算预编译(AI inference、ZK证明、TEE执行等)。深度融合Infernet:off-chain计算由Infernet节点处理,Chain负责请求协调、动态定价(Resonance机制,优化供需匹配)、分布式验证(Symphony协议,双证明分片和认证委员会,减少全重执行)、结算和隐私保护。Guardians系统允许节点选择性参与任务过滤,同时保持共识参与。RaaS优化针对AI:支持异构硬件、调度交易、EIP扩展。多链兼容,Web2适配器简化开发者调用,类似OpenAI API体验。TGE / 代币:尚未发生。无官方代币或空投细节公布。社区活动活跃,包括积分系统、Fellowship程序、Builders Program、Discord角色和pledge任务,许多用户在刷日常farming。氛围浓厚,但无明确TGE路径或时间表。关键进展:Infernet节点版本1.3.1已上线,优化API(如流式响应)和支付系统。Symphony和Resonance机制在文档中详述,提升效率和可扩展性。生态整合:与MegaETH、Movement等证明网络,Conduit、Caldera等RaaS,以及Story、Sentient等IP市场合作。近期社区讨论焦点于Infernet到Chain的桥接,实现透明、无信任AI执行,避免中心化API风险(如地理限制、审查)。生态兼容:支持EVM兼容链,异构节点多样化硬件(CPU/GPU/TEE),模组化存储(HuggingFace/Arweave)。Web3元素强,吸引DeAI开发者;Web2友好接口加速采用。示例:智能合约通过Infernet SDK请求计算,结果 verifiable 返回链上。社区热:X粉丝数持续增长(@ritualnet
活跃帖子多),Discord互助、教程丰富(如节点设置指南)。开发者示例:使用Infernet运行自定义容器,成为AI oracle提供者。风险要点:经济模型(staking、奖励、费用买回)未完全落地,积分系统或成短期叙事。竞争激烈(Bittensor、Sentient、0G Labs等DeAI项目)。技术挑战:大模型推理延迟、能源消耗、黑箱验证需进一步优化;全去中心化协调和隐私保护面临监管潜在风险。早期阶段:Chain无public testnet,执行风险较高。一句话:Infernet已成熟作为AI计算后端,Chain private testnet融合后定位AI原生执行层,社区farming热但关键看主网上线和TGE细节。想深挖节点配置教程、farming优化、竞争分析还是最新社区动态,直接说。
2
82

Jan 2
Gw mau gatekeep gyuhan modelmanager jadi gakusah pake tag ya ytta aja🤗
4
8
666

9 Nov 2025
[🔮Weekly Ritual Notes - #1]
RittyBitty: I want to upload my model! What should I do?
Ritual: (Calling to Model Manager)
ModelManager() Just tell me the 'directory' and your 'repo_id'.
RittyBitty: That easy?
Yes! That easy and quick!
Just like using repositories, Ritual abstracts storage access with a provider-agnostic approach.
This means you can access or compute data across multiple storage without dealing with complicated processes for each provider.
They are already natively integrated!
--------
I'm happy to learn more and more about Ritual!
To share this happiness, I'm starting Weekly Ritual Notes!
I'm still learning, so any feedback is welcome!

20
25
172

11 Oct 2025
@ritualnet The Architecture of Verifiable Intelligence;
In an era where artificial intelligence meets decentralization, RitualNet stands as one of the few infrastructures purpose-built to bridge both. It isn’t just another blockchain project it’s a full-stack AI compute network that allows developers to integrate intelligent behavior directly into smart contracts. This evolution is powered by Infernet, a decentralized off-chain compute layer that processes machine learning tasks beyond the limitations of gas and block time, while sending verifiable proofs of those computations back on-chain. It effectively enables blockchains to think, not just execute.
The Engine- Infernet Compute Layer
At the heart of RitualNet lies Infernet, the connective tissue between blockchain logic and artificial intelligence. Through the Infernet SDK, developers can create contracts that call external computation from AI inference to complex data transformation handled by a distributed network of Infernet Nodes. Each node executes requests, signs results cryptographically, and ensures verifiability through optional proof verification. The SDK also supports both callback-based and subscription-based execution models, making AI computation programmable and predictable within blockchain environments.
Intelligence on the Edge Infernet-ML Library;
RitualNet’s Infernet-ML library allows builders to deploy real AI models in a decentralized way. Written in Python, it provides a framework for importing, training, and running models from leading ecosystems such as Hugging Face, ONNX, and PyTorch. Developers can also leverage ModelManager and ArtifactManager to version models, store parameters, and track provenance ensuring reproducibility and accountability of every model execution. This makes decentralized machine learning practical, auditable, and developer-friendly.
Architecture of Trust The Ritual Superchain;
RitualNet’s architecture extends beyond computation into full modularity. The Ritual Superchain combines shared sequencing, distributed storage, and privacy-preserving technologies such as Multi-Party Computation (MPC) to enable blind inference allowing AI models to run on sensitive data without exposing inputs or weights. By decoupling sequencing, storage, and execution, the Superchain ensures scalability across multiple environments while maintaining verifiability at every step.
This structure not only decentralizes AI but redefines how it can be verified, rewarded, and scaled turning intelligence itself into an open, composable primitive across Web3 ecosystems.
Closing Thoughts;
RitualNet’s brilliance lies in unifying trust, intelligence, and execution. It transforms blockchain from a passive record-keeper into an active, learning organism. With its layered modularity, open SDKs, and privacy-first design, RitualNet is not merely adding AI to Web3 it’s forging a new infrastructure for verifiable cognition. The result is a network where every smart contract can think, verify, and evolve a true synthesis of code and consciousness.

4
1
6
94

24 Feb 2025
自作 XBRLパーサから卒業しようと、昨日からArelleのお勉強中。
最初につまづいたのが SummaryとBSといった異なるスキーマを参照するiXBRLファイルを一つのプログラムで処理しようとすると、2回目の modelManager.load()で Assertion Errorが発生する点。
結局のところCntlrやmodelManagerを分けるだけではダメで、processごと分ける必要があった。マジか。
ずっと相談に付き合ってくれたGrok先生ありがとう🙏

1
4
243

9 Nov 2024
CAMEL-AI🐫 Project Meeting (US Time Friendly) - Next Monday!
Join us for our next development meeting to discuss our project’s latest integrations and upcoming features! 🤩🤩🤩
🔧 New Features from the Last Sprint:
- 🔍 Add 01 model platform
- 🔎 Integrate Qwen model platform
- 📝 Add NVIDIA model platform
- 🦙 Add more github funcs for github toolkit
- 🔗 Support getting data from notion and write content to notion
- ⚙️ Integrate Apify
- 👀 Agentops support for SambaNova Systems
- 📚 'ChatAgent' interface enhancement and default model setting
- ⚡ Doc for model speed comparison
- 🧑💻 Support taking 'Callable' as 'tools' input to 'ChatAgent'
- 👁️ Mock LLM for test purposes
🚀 Features for the Current Sprint:
-🛠️ Add reward models
- 🔄 Refactor to 'use api_keys_required' and 'dependencies_required' decorators
- 🔑 Add agent checkpointing and resume from checkpoint
- 🛡️ Add 'ModelManager' to schedule calls between different model backend
- 🗂️ Enhance Knowledge-Intensive Reasoning with StructRAG
- 🛠️ Optimize tool doc
- 🧑💻 Optimize loader doc
- 💻 Integrate the 'OpenAPIToolkit' into the 'ToolkitManager'
- 👀 Unify toolkit output for both human user and agent
- 🧑💻Critic selection mechanism for models don’t support multiple response at one time
⏰ When: 17:00 (BST) / 09:00 (PDT)
💯 Where: discord.com/events/111501509…

1
4
1,120
1 Nov 2024
CAMEL-AI🐫 Project Meeting (US Time Friendly) - Next Monday!
Join us for our next development meeting to discuss our project’s latest integrations and upcoming features! 🤩🤩🤩
🔧 New Features from the Last Sprint:
- 🔍 Add 01 model platform
- 🔎 Integrate @Qwen model platform
- 📝 Add @NVIDIA model platform
- 🦙 Add more github funcs for github toolkit
- 🔗 Support getting data from notion and write content to notion
- ⚙️ Integrate @apify
- 👀 Agentops support for @SambaNovaAI
- 📚 ChatAgent interface enhancement and default model setting
- ⚡ Doc for model speed comparison
- 🧑💻 Support taking 'Callable' as 'tools' input to 'ChatAgent'
- 👁️ Mock LLM for test purposes
🚀 Features for the Coming Sprint:
-🛠️ Add reward models
- 🔄 Refactor to 'use api_keys_required' and 'dependencies_required' decorators
- 🔑 Add agent checkpointing and resume from checkpoint
- 🛡️ Add 'ModelManager' to schedule calls between different model backend
- 🗂️ Enhance Knowledge-Intensive Reasoning with StructRAG
- 🛠️ Optimize tool doc
- 🧑💻 Optimize loader doc
- 💻 Integrate the 'OpenAPIToolkit' into the 'ToolkitManager'
- 👀 Unify toolkit output for both human user and agent
- 🧑💻Critic selection mechanism for models don’t support multiple response at one time
⏰ When: 17:00 (BST) / 09:00 (PDT)
💯 Where: discord.com/events/111501509…

2
7
1,031
20 Oct 2024
CAMEL-AI🐫 Project Meeting (US Time Friendly) - Next Monday - Tomorrow
Join us for our next development meeting to discuss our project’s latest integrations and upcoming features!
🔧 New Features from the Last Sprint:
- 🦙 Integrate @Slack App
- 🔗 Integrate @Discord App
- ⚙️ Support @MistralAI ’s ministral 3b and 8b model, pixtral model
- 💬 Integrate @WhatsApp
- 📚 Integrate @googlescholar_ toolkit
- ⚡ Integrate @arXiv toolkit
- 🧑💻 Refactor 'ModelType', so that it can both support predefined model types (Enum) and user customized input strings
- 👁️ Integrate @AskNews as toolkit
- 👀 Refactor 'OpenAIFunction' to 'FunctionTool'
- 💻 Make 'system_message' as optional
🚀 Features for the Coming Sprint:
-🛠️ Unify format of the docstring for all code
- 🔍 Add 01 model platform
- 📝 Add @NVIDIA model platform
- 🔄 Update readme.md with features and some main feature code sinppets
- 🔑 Add agent checkpointing and resume from checkpoint
- 🛡️ Add the asynchronous calling capabilities of 'firecrawl_reader&github_toolkit'
- 🔎 Integrate @Qwen model platform
- 🗂️ Integrate @SemanticScholar
- 🛠️ Add ‘ModelManager’ to schedule calls between different model backend
- 🧑💻 Simplify 'ChatAgent' interfaces
⏰ When: 17:00 (BST) / 09:00 (PDT)
💯 Where: discord.com/events/111501509…

9
767

25 Aug 2024
I love that the modelmanager mod lets me put my own blorbos through the horrors 😌


5
19
430
4,019

4 Jun 2024
Rust and MongoDB: A Powerful Combination 👾
As developers, we're always seeking ways to build robust and efficient applications. One powerful combination that has caught my attention is using Rust with MongoDB.
In this article, I walk us through creating a MongoDB model manager and login system entirely in Rust. By leveraging Rust's safety guarantees and performance capabilities, along with MongoDB's flexible and scalable data storage, we can create secure and high-performance applications.
The article covers:
- Setting up a Rust project with MongoDB dependencies
- Defining MongoDB models and schemas with Serde
- Implementing a model manager to interact with MongoDB
- Building a login system with email/password authentication
The explanations and well-structured code examples make it easy to follow along and understand the concepts.
Whether you're new to Rust or MongoDB, or an experienced developer looking to integrate these technologies, this article is a valuable resource.
Give it a read and explore the possibilities of combining Rust's robustness with MongoDB's versatility. The future of application development is bright with this powerful duo!
rabmcmenemy.medium.com/creat…
#Rust #MongoDB #DatabaseManagement #LoginSystem #WebDevelopment #BackendDevelopment #CodeTutorial #RustLang #NoSQL #ModelManager #SerdeDev #RustDevs #RustCommunity
2
4
166

24 Jan 2024
HUGE Rust10x Code Drop (E06)
1) Data Model Change (Agent & Conversation)
2) ModelManager DB Transaction Support
3) Declarative Macros
4) Code Update
Repo & E06 Details: github.com/rust10x/rust-web-…
Discord: discord.gg/XuKWrNGKpC
Video coming
#rustlang #productioncoding @rust10x
1
6
385

24 Oct 2023
import time
import logging
import numpy as np
import os
from sklearn.metrics import accuracy_score, f1_score, hamming_loss
import torch
import wandb
from tqdm import tqdm
from transformers import get_linear_schedule_with_warmup
from utilities.db_utils import store_metric, store_checkpoint
from config import (
SystemConfiguration,
UserConfiguration,
TokenizerConfiguration,
TrainerConfiguration,
TextGenConfiguration,
)
from managers import DataManager, ModelManager, TokenizationManager, SystemMonitor
from utilities.profiler_utils import measure_time_taken
logger = logging.getLogger(__name__)
class Trainer:
def __init__(
self,
user_config: UserConfiguration,
system_config: SystemConfiguration,
tokenizer_config: TokenizerConfiguration,
text_gen_config: TextGenConfiguration,
train_config: TrainerConfiguration,
system_monitor: SystemMonitor,
data_manager: DataManager,
model_manager: ModelManager,
tokenization_manager: TokenizationManager,
training_dataloader,
validation_dataloader,
database_path,
run_name,
use_wandb=False,
task="generation"
):
self.task = task
self.use_wandb = use_wandb
self.model_name = model_manager.model_name
self.user_config = user_config
self.system_config = system_config
self.tokenizer_config = tokenizer_config
self.text_gen_config = text_gen_config
self.train_config = train_config
self.system_monitor = system_monitor
self. data_manager = data_manager
self.model_manager = model_manager
self.tokenization_manager = tokenization_manager
self. training_dataloader = training_dataloader
self.validation_dataloader = validation_dataloader
self.num_batches = len(self. training_dataloader)
self.database_path = database_path
self. run_name = run_name
self.log_path = None
self.model_path = None
self._setup_logging_and_saving()
self.optimizer = self._fetch_optimizer()
logger. info(f"Using optimizer: {type(self.optimizer).__name__}")
self. lr_scheduler = get_linear_schedule_with_warmup(
optimizer=self.optimizer,
num_warmup_steps=self.train_config.num_warmup_steps,
num_training_steps=(
len(self. training_dataloader) * self.train_config.epochs
),
)
lr_scheduler_details = {
"num_warmup_steps": self.train_config.num_warmup_steps,
"num_training_steps": len(self. training_dataloader)
* self.train_config.epochs,
}
self.running_loss = 0.0
store_metric(
self.database_path,
"lr_scheduler_details",
self. run_name,
lr_scheduler_details,
)
if self.use_wandb:
wandb.log(lr_scheduler_details)
def _fetch_optimizer(self):
if self.model_manager.is_quantized:
from bitsandbytes.optim import AdamW
optimizer = AdamW(
params=self.model_manager.model.parameters(),
lr=self.train_config.lr,
is_paged=self.train_config.is_optimizer_paged,
optim_bits=self.train_config.optim_bits,
)
else:
from transformers import AdamW
optimizer = AdamW(
params=self.model_manager.model.parameters(), lr=self.train_config.lr
)
optimizer_detail = {
"optimizer_type": type(optimizer).__name__,
}
store_metric(
self.database_path, "optimizer_details", self. run_name, optimizer_detail
)
if self.use_wandb:
wandb.log(optimizer_detail)
return optimizer
def _setup_logging_and_saving(self):
model_name = self.model_name
dataset_name = self. data_manager.dataset_name
tokenizer_name = self.tokenizer_config.tokenizer_name
self.log_path = self.user_config.logs_path_generator(
model_name, dataset_name, tokenizer_name
)
if not os.path.exists(self.log_path):
os.makedirs(self.log_path)
with open(f"{self.log_path}/training.log", "w ") as f:
f.write("epoch\tbatch\ttrain\tloss\tgenerated_text\n")
with open(f"{self.log_path}/validation.log", "w ") as f:
f.write("epoch\tbatch\tvalidation_loss\tperplexity\n")
self.model_path = self.user_config.model_path_generator(
model_name, dataset_name, tokenizer_name
)
if not os.path.exists(self.model_path):
os.makedirs(self.model_path)
def handle_batch(self, epoch, index, batch):
self.model_manager.model.train()
current_lr = self.optimizer.param_groups[0]["lr"]
if index % 100 == 0:
training_loss_details = {
"epoch": epoch (index / len(self. training_dataloader)),
"running_loss": self.running_loss / index,
}
learning_rate_details = {
"epoch": epoch (index / len(self. training_dataloader)),
"learning_rate": current_lr,
}
gpu_details = {
"epoch": epoch (index / len(self. training_dataloader)),
"gpu_util": self.system_monitor.get_gpu_utilization(),
"ram_usage": self.system_monitor.get_ram_usage(),
}
store_metric(
self.database_path,
"training_loss_details",
logger. infou nun_name,
training_loss_details,
)
store_metric(
self.database_path,
"learning_rate",
self.run_name,
learning_rate_details,
)
store_metric(
self.database_path, "gpu_utilization", self.run_name, gpu_details
)
if self.use_wandb:
wandb.log(training_loss_details)
wandb.log(learning_rate_details)
wandb.log(gpu_details)
# Sample an output from the model, at each sampling interval
if index % self.train_config.sampling_interval == 0 and self.task=="generation":
prompt = self.tokenization_manager.encode("This")
sequence = self.model_manager.infer(prompt, self.text_gen_config)
text = self.tokenization_manager.decode(sequence, self.text_gen_config)
logger.info(
f"Training: Epoch-{epoch} Index-{index} Loss-{self.running_loss / index}"
)
logger.info(f"Text:\n{text}")
with open(f"{self.log_path}/training.log", "a") as f:
f.write(f"{epoch}\t{index}\t{self.running_loss / index}\t{text}\n")
text_gen_details = {"epoch": epoch (index / len(self.training_dataloader)), "text": text}
store_metric(
self.database_path, "generated_text", self.run_name, text_gen_details
)
if self.use_wandb:
wandb.log(text_gen_details)
# Save the model at each checkpointing interval
if index % self.train_config.checkpointing_interval == 0:
self.save_checkpoint(epoch, index)
# Validate the model at each validation interval
if index % self.train_config.validation_interval == 0:
if self.task == "generation":
self.validate_model(epoch, index)
elif self.task == "classification":
self.validate_model_for_classification(epoch, index)
self.forward_backward_pass(batch)
@measure_time_taken
def save_checkpoint(self, epoch, index):
logger.info(f"Checkpointing model at epoch={epoch} and batch={index}\n")
checkpointing_path = f"{self.model_path}_{epoch}_{index}"
store_checkpoint(
self.database_path,
epoch (index / len(self.training_dataloader)),
self.run_name,
checkpointing_path,
)
self.model_manager.model.sav…_pretrained(checkpointing_path)
self.tokenization_manager.to…_pretrained(checkpointing_path)
@measure_time_taken
def validate_model(self, epoch, index):
logger.info("Running Validation...")
avg_eval_loss, perplexity = self.model_manager.validate(
self.validation_dataloader
)
logger.info(
f"Batch {index}/{len(self.training_dataloader)}, Validation Loss: {avg_eval_loss:.4f}, "
f"Perplexity: {perplexity:.2f}"
)
with open(f"{self.log_path}/validation.log", "a") as f:
f.write(f"{epoch}\t{index}\t{avg_eval_loss}\t{perplexity}\n")
metric_details = {
"epoch": epoch (index / len(self.training_dataloader)),
"eval_loss": avg_eval_loss,
"perplexity": perplexity,
}
store_metric(
self.database_path, "validation_metrics", self.run_name, metric_details
)
if self.use_wandb:
wandb.log(metric_details)
@measure_time_taken
def validate_model_for_classification(self, epoch, index):
logger.info("Running Validation...")
loss_fn = torch.nn.BCEWithLogitsLoss()
total_loss = 0
self.model_manager.model.eval() # Ensure model is in evaluation mode
all_preds = []
all_labels = []
for batch in tqdm(self.validation_dataloader):
with torch.no_grad():
batch = {k: v.to(self.model_manager.device) for k, v in batch.items()}
outputs = self.model_manager.model(batch['input_ids'], attention_mask=batch['attention_mask'])
logits = outputs.logits
loss = loss_fn(logits, batch['labels'].type_as(logits))
total_loss = loss.item()
preds = torch.sigmoid(logits) > 0.5
all_preds.extend(preds.cpu().numpy())
all_labels.extend(batch['labels'].cpu().numpy())
# Calculate metrics
all_preds = np.array(all_preds)
all_labels = np.array(all_labels)
accuracy = accuracy_score(all_labels, all_preds)
f1 = f1_score(all_labels, all_preds, average='micro') # using micro average for multi-label
hamming = hamming_loss(all_labels, all_preds)
avg_eval_loss = total_loss/len(self.validation_dataloader)
logger.info(
f"Batch {index}/{len(self.training_dataloader)}, "
f"Validation Loss: {avg_eval_loss:.4f}, "
f"Accuracy: {accuracy:.2f}, F1: {f1:.2f}, "
f"Hamming Loss: {hamming:.4f}"
)
metric_details = {
"epoch": epoch (index / len(self.training_dataloader)),
"eval_loss": avg_eval_loss,
"accuracy": accuracy,
"hamming loss": hamming,
"f1": f1
}
store_metric(self.database_path, "validation_metrics", self.run_name, metric_details)
if self.use_wandb:
wandb.log(metric_details)
LABEL_NAMES = ['Computer Science', 'Physics', 'Mathematics', 'Statistics', 'Quantitative Biology', 'Quantitative Finance']
for i in range(len(all_preds)):
pred_i = [LABEL_NAMES[j] for j in range(len(LABEL_NAMES)) if all_preds[i][j]]
label_i = [LABEL_NAMES[j] for j in range(len(LABEL_NAMES)) if all_labels[i][j]]
logger.info(f"{i}: Predicted labels: {pred_i}")
logger.info(f"{i}: Actual labels: {label_i}")
if (i 1)%7 == 0:
break
def forward_backward_pass(self, batch):
batch = {
k: v.pin_memory().to(self.model_manager.device, non_blocking=True)
for k, v in batch.items()
}
outputs = self.model_manager.model(batch['input_ids'], attention_mask=batch['attention_mask'])
if self.task == "classification":
logits = outputs.logits
loss = torch.nn.BCEWithLogitsLoss()(logits, batch['labels'].type_as(logits))
else:
loss = outputs.loss
self.running_loss = loss.item()
loss.backward()
self.optimizer.step()
self.lr_scheduler.step()
self.optimizer.zero_grad()
def train(self):
start_time = time.time()
for epoch in tqdm(range(1, self.train_config.epochs 1)):
self.running_loss = 0.0
logger.info(f"Starting Epoch: {epoch}/{self.train_config.epochs}")
epoch_start_time = time.time()
for index, batch in tqdm(
enumerate(self.training_dataloader, 1),
total=len(self.training_dataloader),
):
self.handle_batch(epoch, index, batch)
epoch_end_time = time.time()
epoch_time = epoch_end_time - epoch_start_time
epoch_dict = {"epoch": epoch, "time": epoch_time}
store_metric(self.database_path, "epoch_time", self.run_name, epoch_dict)
if self.use_wandb:
wandb.log(epoch_dict)
logger.info(
f"Training Loss after Epoch {epoch}: {self.running_loss / self.num_batches}"
)
end_time = time.time()
total_time = end_time - start_time
total_time_dict = {"total_time": total_time}
store_metric(self.database_path, "total_time", self.run_name, total_time_dict)
if self.use_wandb:
wandb.log(total_time_dict)
logger.info(
f"Final Training Loss after {self.train_config.epochs} epochs: {self.running_loss / self.num_batches}"
)
store_checkpoint(
self.database_path,
self.train_config.epochs 1,
self.run_name,
self.model_path,
)
self.model_manager.model.sav…_pretrained(self.model_path)
self.tokenization_manager.to…_pretrained(self.model_path)
1
4
80
9 Sep 2023
Rust Web App - Why No States?
(ModelControllers v.s. ModelManager)
youtu.be/JdLi69mWIIE
#rustlang #ProductionCoding #PatternExplained

2
16
1,403




