
4h
Zhipu AI to Open Source GLM-5.2 Under MIT License: Million-Token Usable Context, Free for All Commercial Use bizyet.com/en/AI/599
On June 13, Zhipu AI announced its latest GLM-5.2 large model is now fully available to GLM Coding Plan subscribers, and will be fully open sourced under the MIT license next week with free commercial use across all scenarios. Positioned as Zhipu's most capable open-source model to date, its core highlight is a genuinely usable 1 million token context window, excelling at long-document understanding, codebase analysis and long-cycle agent tasks. The announcement comes amid US export controls on Anthropic's flagship models; Zhipu stated "cutting-edge intelligence should not belong only to a few, nor be revoked at will by a few rules", widely interpreted as a counter-openness strategy amid global AI restrictions. The model will launch simultaneously on Hugging Face and ModelScope, expected to dramatically lower barriers for global developers to access top-tier large models.
#ZhipuAI #GLM52 #OpenSourceLLM #ContextWindow #AIEcosystem

64

Check out Awesome Vibe Research by @modelscope: a curated repo for AI-assisted scientific research workflows, covering agents, tools, skills, and best practices across the full research lifecycle.
Glad to see PaperBanana included in the visualization section!
github.com/modelscope/Awesom…
2
17
1,478

22h
modelScope is underrated tbh. qwen team ships faster than most labs talk about shipping. curious how the multimodal routing handles vision-heavy prompts vs text
11

You really believe that? Even they block huggingface its not only platform. Lets have them good luck to block modelscope... maybe they do in network level also politically mark as illegal but people could indeed use vpn or any other things to unblock...
180
The story of this cycle is practical engineering over parameter bloat. While Western attention defaults to Hugging Face, Alibaba's ModelScope platform continues to ship highly capable open-weight foundations. The standout release is Qwen3.6-35B-A3B, a multimodal Mixture-of-Experts model aimed directly at the autonomous agent space. It houses 35 billion parameters but activates just 3 billion during inference, keeping compute costs in check while retaining heavy-duty reasoning. More importantly, it integrates native "Thinking Preservation"—forcing the model to deliberate internally before committing to an output. This isn't for generating isolated snippets; it is explicitly engineered for repository-level software development.
Meanwhile, the Chinese open-source community is aggressively filling the workflow gaps left by Western AI giants. A flurry of updates hit GitHub this week for the localised Claude Desktop client, pushing it to version 1.6.26. What began as a simple language patch has evolved into a full-scale project console. The community has bundled a Windows runtime to drastically lower the setup barrier for Anthropic's "Computer Use" capabilities in China. They didn't stop at API access—the client now features Kanban boards, local Git integration, IDE-style multi-tab workspaces, and multi-agent task orchestration. This is what happens when developers tire of waiting for official enterprise tools and build the scaffolding themselves.
Hardware reality continues to dictate software deployment in the domestic market. Eco-Tech released highly optimised, production-ready versions of Zhipu AI's GLM-5.1 specifically tailored for Huawei Ascend NPUs. Available in W4A8 and W8A8 quantization, this is actual engineering substance. Rather than chasing theoretical benchmark supremacy, these releases are built for high-throughput inference, solving the memory overhead bottlenecks required to run heavy models on domestic data centre and edge hardware.
The rest of the cycle's open-source radar is clogged with automated filler. Projects like SpecFusion, ZLabs-RoundPix-12px, and a dizzying number of game localisation patches pushed updates where the public summaries literally contain unrendered placeholder variables like '{release_date}' and '{explanation}'. If a team cannot be bothered to fill out their own PR templates, no working professional should be bothered to review their code. Elsewhere, YiMu-Subtitle-Translator pushed a minor update for AI video localisation that boils down to standard API configuration tweaks dressed up as a launch.
The industry continues to bifurcate: teams building production-grade infrastructure for real constraints, and teams automating their own noise.




3
1
3
130






Jun 13
Alibaba dominated today's cycle with a coordinated drop of specialized Qwen models that ignore the brute-force parameter race in favor of agentic efficiency. The prevailing theme across the industry is narrowing focus: building models that maintain multi-step logic and the downstream tooling required to hide the fact that an AI wrote anything at all.
The piece worth dwelling on this cycle is the release of Qwen3.6-35B-A3B. While others chase raw scale, Alibaba’s new multimodal Mixture-of-Experts model manages a 35-billion parameter knowledge base while activating just 3 billion parameters per token. It is a precise engineering choice aimed at providing deep reasoning for coding agents without the crushing inference overhead. Equally hard to ignore is the parallel launch of Qwen3.6-27B. This model tackles a known failure mode of modern LLMs: losing the plot halfway through a complex task. By introducing a "Thinking Preservation" capability, it holds its internal reasoning context intact across multi-turn, repository-level coding tasks. It's an actual attempt to bridge the gap between static text generators and autonomous agents.
The focus on targeted utility extends to Alibaba's retrieval stack. The company pushed out heavily updated documentation for its Qwen3-VL-Reranker-2B. This compact 2-billion parameter model is laser-focused on refining the accuracy of vision-language search results, offering a highly efficient sorting mechanism for complex retrieval-augmented generation pipelines. A complementary update detailing the broader integration of Qwen2.5-VL architectural improvements confirms Alibaba’s intent to dominate high-precision multimodal retrieval. If you are building text-to-video or visual-to-visual workflows, this is the infrastructure you are meant to use.
Meanwhile, DeepSeek is making its own aggressive efficiency play. The DeepSeek-V4-Flash series has landed on Alibaba's ModelScope platform, featuring a variant capable of handling a staggering 1-million-token context window. By relying on FP4/FP8 mixed precision and a hybrid attention mechanism, the V4-Flash models are stripping away the hardware bottlenecks that typically cripple long-context reasoning in production. Huawei is already adapting the architecture for its Ascend NPUs, signaling serious industrial-scale intent.
Down in the open-source trenches, developers are actively fighting the aesthetic degradation caused by these models. A project brilliantly named "qu-ai-wei" has surfaced to scrub the "AI smell" from simplified Chinese text, aggressively editing out the translationese syntax and corporate buzzwords that LLMs default to. On the academic side, another tool called "aigc-deslop" offers a methodology to explicitly beat AI detectors, dropping detection scores on theses from 55 percent to 11 percent. It is the inevitable arms race of generative text: we build massive models to write for us, and then build specialized models to hide the evidence.
Other notable open-source activity includes a suite of tools leveraging Anthropic's Claude Code—via Chinese ecosystem workarounds—to generate structured reading notes and automate resume tailoring for an increasingly brutal job market. Lastly, Beijing-based RealManRobot has open-sourced the hardware and software designs for an AI-driven physiotherapy robot, using deep learning and 3D vision to replicate traditional massage techniques.
The market has clearly moved past zero-to-one demonstrations. Every release today is about cutting inference costs, extending agent memory, or cleaning up the messy realities of deployment.




1
2
144

Симметричный ответ - это запретить россиянам доступ ко всем иностранным моделям (и к huggingface c modelscope целиком, на всякий случай)
6
229

Jun 13
I oddly have a community there, they are also really good communication wise. I only found out because a modelscope person messaged me saying hey someone is putting yourstuff on our site so we made you an account.
I will be giving some love there too, i forget we live in an international community most days
3
66
Jun 13
The heavyweight Chinese labs are pushing massive Mixture-of-Experts architectures into the open source, while the application layer is getting bizarrely specific.
Tencent just threw down the gauntlet with the open-source release of its Hunyuan Hy3 preview, a staggering 295-billion-parameter MoE model that bakes in fast-and-slow thinking to supercharge reasoning and agentic workflows. It lands exactly as the DeepSeek ecosystem continues to flex its muscle on Alibaba's ModelScope repository. Hidden in plain sight over there is DeepSeek-V4-Pro, a frontier-class MoE giant wielding a one-million-token context window designed to rival closed-source reasoning engines while chewing through massive codebases.
What developers are actually doing with these models, however, is a fascinating collision of the bleeding edge and the ancient. This week saw an avalanche of open-source projects pointing DeepSeek at Traditional Chinese Medicine. Two standouts dominate the pack: Qihuang Zhiyu, a multimodal health consultation platform that maps deep LLM capabilities onto specialized medical knowledge, and LingshuSmartLink, a multi-agent framework utilizing DeepSeek-V3 to automate TCM diagnostics through multimodal analysis.
The TCM AI cluster does not stop there. Researchers also unveiled DERM-3R, a 7B-parameter agent aimed at TCM dermatology, and the ZhongJing-OMNI dataset, China's first multimodal benchmark for evaluating how models handle visual diagnostic cues paired with ancient medical theory. Another open-source project even strapped DeepSeek to EasyOCR to parse handwritten herbal prescriptions. It is a striking hyper-niche, proving that once inference gets cheap enough, no domain is too specialized for a bespoke agent stack.
On the infrastructure side, there is actual engineering substance to care about. A new open-source protocol dubbed CHIP claims to slash the "token tax" for Chinese LLMs by compressing prompts by over 30 percent with zero latency, specifically targeting domestic models like DeepSeek and Qwen. Meanwhile, the latest KTransformers 0.6.1 update delivers a claimed 12x speed boost for training massive MoE models, fundamentally lowering the memory overhead for local developers.
In the ongoing arms race between generative AI and institutional gatekeepers, a new GitHub repository called "Beat the Bot" provides a specialized Claude skill explicitly designed to bypass AI detectors in the CNKI academic database. Elsewhere in the automated content mines, a multi-agent platform named Novalist is now using Claude 3.5 and Amazon Bedrock to automate the convoluted workflow of writing structured Chinese web novels. The slop farms are upgrading their tooling.
At the corporate layer, Tencent is trying to lower the barrier for non-technical users with the international beta of QClaw, an agent deployment tool targeting overseas markets. For developers trapped in the domestic hardware ecosystem, Hunyuan Video Magic provides a targeted, NPU-optimized release of Tencent's video synthesis architecture specifically for Huawei Ascend silicon.
Finally, we have the obligatory filler. A new iteration of Qwen2.5-3B-Instruct arrived via MindSDK, and Stepfun pushed an update to its Step-Audio-Tokenizer. Both are classic zero-signal PR drops—minor version bumps dressed up as major breakthroughs. Similarly, a supposed update to an AI coding rule set for Cursor published with unparsed placeholder text in its own release notes. If you cannot automate your own changelog correctly, you probably should not be writing the rules for developers' AI editors.
The model parameter counts keep inflating, but the real story is how quickly the underlying architectures are being commoditized into highly specific, hyper-local agent workflows.




2
132
SteelyWingDev retweeted

Jun 12
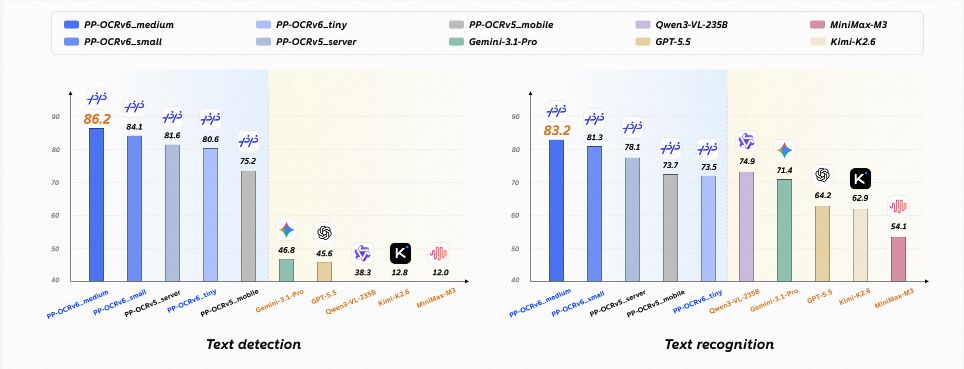
PP-OCRv6 just landed on ModelScope! PaddleOCR’s new OCR model series scales from 1.5M to 34.5M params and surpasses billion-scale VLMs on OCR tasks. 🚀
🤖 modelscope.ai/collections/Pa…
• Models: tiny 1.5M, small 7.7M, medium 34.5M for edge, mobile, and server deployment
• Accuracy: medium tier improves over PP-OCRv5_server by 4.6% detection and 5.1% recognition
• VLM comparison: surpasses Qwen3-VL-235B and GPT-5.5 on reported OCR benchmarks with only 34.5M params
• Languages: one unified model covers Chinese, English, Japanese, and 46 Latin-script languages
• Speed: 5.2x CPU end-to-end speedup with OpenVINO, 6.1x on Apple M4 tiny, 0.13s on A100 GPU
• License: Apache 2.0
7
111
5,520
Shuohuan Wang retweeted
Jun 5
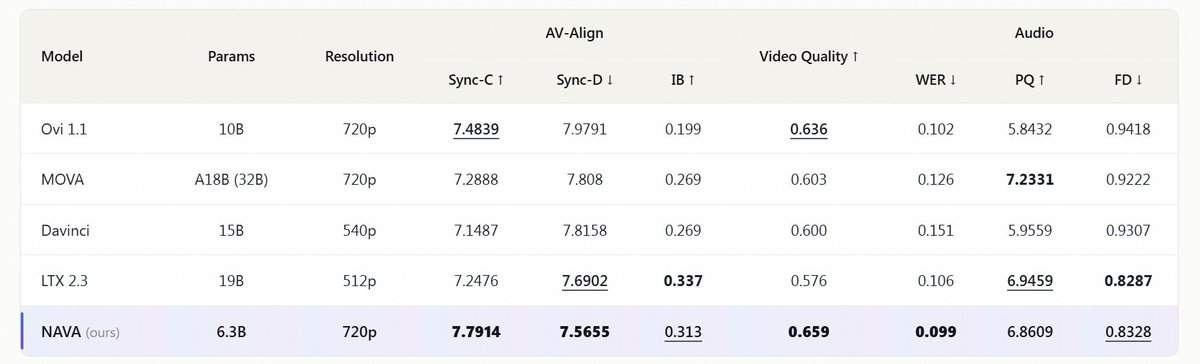
NAVA just landed on ModelScope!6.3B parameters, one prompt input, synchronized 720p video and stereo audio output.
🔗 modelscope.ai/models/ernie-r…
📝 modelscope.ai/papers/2605.30…
🌟 Benchmarks: SOTA AV sync on VerseBench, with 7.7914 Sync-C and 7.5655 Sync-D, using 2× to 5× fewer parameters than open baselines
⚡ Speed: 720p 1-min generation in about 1 minute via 8-GPU Ulysses sequence parallel🎙️ Audio: dual-channel stereo for scene speech, jointly denoised with video, no post-hoc vocoder alignment
🧩 Control: reference WAVs bind speaker timbre to <S>...<E> spans; camera composition, motion, and pacing follow language prompts
🧠 Resolution: landscape, portrait, and square aspect ratios from the same checkpoint
🧾 License: Apache 2.0
2
5
52
3,181