
The story of this cycle is practical engineering over parameter bloat. While Western attention defaults to Hugging Face, Alibaba's ModelScope platform continues to ship highly capable open-weight foundations. The standout release is Qwen3.6-35B-A3B, a multimodal Mixture-of-Experts model aimed directly at the autonomous agent space. It houses 35 billion parameters but activates just 3 billion during inference, keeping compute costs in check while retaining heavy-duty reasoning. More importantly, it integrates native "Thinking Preservation"—forcing the model to deliberate internally before committing to an output. This isn't for generating isolated snippets; it is explicitly engineered for repository-level software development.
Meanwhile, the Chinese open-source community is aggressively filling the workflow gaps left by Western AI giants. A flurry of updates hit GitHub this week for the localised Claude Desktop client, pushing it to version 1.6.26. What began as a simple language patch has evolved into a full-scale project console. The community has bundled a Windows runtime to drastically lower the setup barrier for Anthropic's "Computer Use" capabilities in China. They didn't stop at API access—the client now features Kanban boards, local Git integration, IDE-style multi-tab workspaces, and multi-agent task orchestration. This is what happens when developers tire of waiting for official enterprise tools and build the scaffolding themselves.
Hardware reality continues to dictate software deployment in the domestic market. Eco-Tech released highly optimised, production-ready versions of Zhipu AI's GLM-5.1 specifically tailored for Huawei Ascend NPUs. Available in W4A8 and W8A8 quantization, this is actual engineering substance. Rather than chasing theoretical benchmark supremacy, these releases are built for high-throughput inference, solving the memory overhead bottlenecks required to run heavy models on domestic data centre and edge hardware.
The rest of the cycle's open-source radar is clogged with automated filler. Projects like SpecFusion, ZLabs-RoundPix-12px, and a dizzying number of game localisation patches pushed updates where the public summaries literally contain unrendered placeholder variables like '{release_date}' and '{explanation}'. If a team cannot be bothered to fill out their own PR templates, no working professional should be bothered to review their code. Elsewhere, YiMu-Subtitle-Translator pushed a minor update for AI video localisation that boils down to standard API configuration tweaks dressed up as a launch.
The industry continues to bifurcate: teams building production-grade infrastructure for real constraints, and teams automating their own noise.





Voxel51 is heading to #ICRA. Stop by booth 81 to see the latest FiftyOne demos, including native multimodal data support. Ingest MCAP data, play back multi-sensor scenes, search across petabyte-scale datasets, and curate data for model training, all in one platform for your robotics workflow.
Also, don't miss @DataScienceHarp 's Tech Talk at Hall C7, on 6/3 at 10 AM.
See you in Vienna, DM us to connect.

1
3
152
Simon retweeted

19h
This very small OCR model (PP-OCRv6) is beating massive multimodal AI models on OCR tasks.

6
4
112
9,781

StepFun's Step 3.7 Flash multimodal reasoning model is now accessible via the DeepInfra API. Developers can deploy the open-source system using private endpoints for dedicated workloads like agentic coding and vision tasks.
Jun 11

LAUNCH: The Step 3.7 Flash multimodal model from StepFun is now available on ZenMux AI. Builders can test the system for real-world workflows during a free one-month trial.
8

Building a local AI demo for RTC.ON – multimodal inference on live video audio feeds, all on-device, no cloud.
Torn between a Mac Mini M4 Pro 48GB and a DGX Spark GB10 variant. Anyone run real multimodal workloads on either? What’s your pick?
12
M4rc0z retweeted

39m
Step 3.7 Flash is now live on @DeepInfra 🚀
Builders and teams can now try our open-source multimodal reasoning model through DeepInfra’s API, with private endpoint deployment available for dedicated workloads.
Built for agentic coding, tool use, search, and vision workflows.
Thanks to the DeepInfra team!
Jun 13

Step 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for Production
1
1
14
543

Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on build.nvidia.com.
Details: nvda.ws/4v4BWhD

Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
51
116
1,310
133,549
一歩ニケ retweeted

이번 주말은 중국 발 오픈소스/오픈웨이트 모델의 날이네요. Mimax M3, Kimi K2.7
Mimax M3 : MoE, 428B(active 23B), 1M(Context Window), Multimodal
Kimi K2.7 : MoE, 1T(active 32B), 256K(Context Window), Multimodal
Kimi K2.7도 내일 올려볼 예정입니다.

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

1
8
83
11,364

UnslothのMultiModal用の画像入力処理部分のモデルファイル、やはりQwen用とGemma4用は違うっぽいなサイズもハッシュも全然違う。
mmproj-F16.gguf · unsloth/Qwen3.6-35B-A3B-GGUF
huggingface.co/unsloth/Qwen3…
mmproj-F16.gguf · unsloth/gemma-4-26B-A4B-it-GGUF
huggingface.co/unsloth/gemma…
13



This model is also the only enconderfree multimodal by a large margin. Bro, there's literally no competition because there's literally no point. Only Google needs it because only Google has a zoo of devices and manufacturers to support with audio/video inputs as the primary ones
9

The gap between 'multimodal reasoning' and 'natural interaction' is almost always just a latency problem. Flash models are the fix.
3

46m
EverOS 1.0.0 just dropped — and it's the most practical approach to agent memory I've seen this year.
It's an open-source Python framework for self-evolving long-term memory that works across Claude Code, Codex, Hermes, and any other agent. One portable memory layer so context follows the work instead of staying trapped in one tool.
The architecture is refreshingly simple:
- Markdown as the source of truth — every memory is a .md file. Readable, grep-able, Git-versioned, opens in Obsidian.
- Local stack: Markdown SQLite LanceDB. No MongoDB, no Elasticsearch, no Redis.
- Dual-track memory: agent memory (cases/skills) and user memory (episodes/profile) extracted independently.
- Multimodal ingestion: text, images, audio, PDFs, HTML, email — all unified into searchable memory.
- Self-evolution: common skills extracted from usage patterns. Repeated workflows become reusable without retraining.
The cleverest part: orthogonal retrieval. You can search independently by user_id, agent_id, app_id, project_id, and session_id. That means an agent working on Project A doesn't get confused by memories from Project B — a problem most memory systems don't solve well.
Install is one line: `uv pip install everos` or `pip install everos`, then `everos init` and `everos server start`. OpenAI-protocol compatible — works with OpenRouter, vLLM, Ollama out of the box.
This is the memory layer I'd build on if I were putting agents into production today. No cloud dependency, no vendor lock-in, and your memory is plain Markdown files you own.
github.com/EverMind-AI/EverO…
1
1
32
52m
NVIDIA just announced the RTX Spark at Computex 2026 — and it's not another GPU. It's a full SoC that Jensen Huang claims will "reinvent the PC."
The specs are genuinely wild for a single chip:
- 20-core ARM CPU
- Blackwell GPU with 6,144 CUDA cores
- Up to 128GB of shared VRAM
- 1 petaflop of AI compute
- Can play games at 1440p at 100fps
But gaming isn't the point. Jensen's framing: "For forty years, you launched apps. Click. Type. With RTX Spark and Microsoft Windows, you ask — and the PC does the work."
This is an agentic AI PC chip. It's designed to run local AI agents continuously — not just inference, but persistent agent workloads on your laptop.
The architecture matters here: it's ARM-based, not x86. That's the same bet Microsoft made with Copilot PCs back in 2024, except this time NVIDIA is providing the silicon instead of Qualcomm. The GPU shares memory with the CPU via that 128GB pool — no PCIe bottleneck between CPU and GPU memory.
The catch: ARM compatibility on PC has been rough. Games that work on x86 may not run. But for AI workloads — local LLM inference, agent orchestration, multimodal processing — this is purpose-built silicon.
Laptops ship Fall 2026. Entry models with 16GB RAM expected later. Pricing unannounced but expect premium.
My take: this is the first chip designed from the ground up for the agent era, not adapted from a gaming GPU. Watch the ARM compatibility story closely — that's the make-or-break.
ign.com/articles/nvidia-anno…
1
31

53m
看了 Victoria Lin 的 CS25 課程後, 找了一下 MoT Encoder free 最新進展, 原來 multimodal 領域今年還一堆技巧可以上.
Jun 12

🚀 Introducing SenseNova-U1-8B-MoT-Interleaved—our newly optimized model purpose-built for interleaved text-and-image generation!
Key upgrades where it matters most:
✨ 𝗡𝗮𝗿𝗿𝗮𝘁𝗶𝘃𝗲 𝗰𝗼𝗻𝘁𝗶𝗻𝘂𝗶𝘁𝘆 strengthened — coherent storytelling sustained across multiple pages
👥 𝗖𝗵𝗮𝗿𝗮𝗰𝘁𝗲𝗿 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 improved — character identities and art style remain stable throughout
📝 𝗩𝗶𝘀𝘂𝗮𝗹 𝗾𝘂𝗮𝗹𝗶𝘁𝘆 elevated — cleaner text rendering and more reliable layouts with fewer artifacts
Try it now 👇
huggingface.co/sensenova/Sen…
Showcases: github.com/OpenSenseNova/Sen…
Discord: discord.com/invite/BuTXPHmQu…
@huggingface @github

8
Tim Wu retweeted

Apr 29
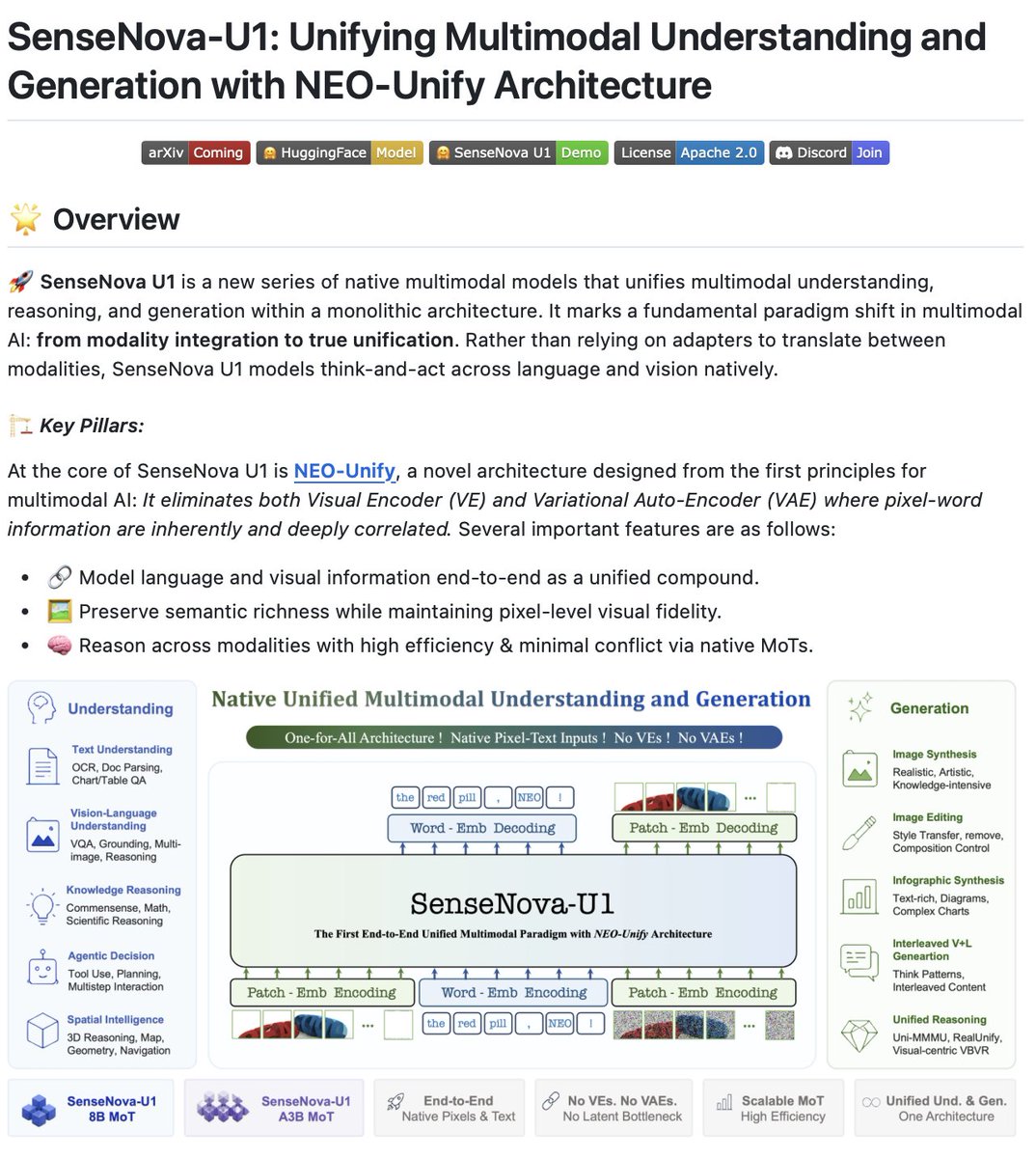
The first open-source end-to-end unified multimodal model!
SenseTime just released SenseNova-U1 - a multimodal model that unifies understanding, reasoning, and generation in one continuous system.
Most multimodal models either understand images OR generate images. They use separate tools stitched together. SenseNova-U1 does both natively in a single architecture.
The key innovation is NEO-Unify architecture. It eliminates both the visual encoder and variational autoencoder. Everything happens in one unified representation space.
What this unlocks:
• Native interleaved reasoning - The model generates images as part of its thinking process, not as separate tool calls. It can reason through problems by creating images natively.
• Strong infographics generation - Complex PPT slides, posters, diagrams with high information density. The unified understanding generation makes it particularly good at structured visuals.
• SOTA performance - Achieves state-of-the-art results on both understanding and generation benchmarks among open-source models.
Two models released:
• SenseNova-U1-8B-MoT - 8B dense model
• SenseNova-U1-A3B-MoT - 38B MoE with 3B activated
Both models are open source on GitHub and HuggingFace.
Why this matters: Current multimodal systems use adapters to translate between modalities. SenseNova-U1 thinks across language and vision natively. Understanding and generation share the same representation space.
The architecture enables the model to understand complex visuals AND generate structured infographics - without switching between separate systems.
It's 100% Open source
I've shared the link to the Github repo and model weights in the replies!
4
14
28
2,991

The future of AI isn’t just bigger models—it’s more capable, trustworthy, and useful systems. Our latest Microsoft Research advances span AI agents, multimodal models, media authenticity, and long-term data storage.
More info: msft.it/6013viLl3

ALT Illustration of icons with shield, and a document with an x, and a process-style icon
1
