

Minimax M3 with olka's mxfp4 experts quant runs on 4x6000 pros at 27-30tps generation and multimodality btw.
1
2
32

FAILURE OF IMAGINATION—Sure, everybody is clearly racing for recursive superintelligence right now. And the path forward seems so obvious: just automate software engineering, ML engineering and research, and hook it back up to itself. But if automating coding was so obvious, why didn't people go at it from the get-go?
If you go and read the model card from Claude 2, for example, it's mostly about chat assistant stuff, like helpfulness, red-teaming, translation, etc. The word "coding" appears just four times, while "translation" appears twelve times! Claude 3 was more about multimodality, long-context document processing, Q&A, writing, etc. It's only around Claude Sonnet 3.5 on June 20, 2024 that model card focus shifts to agentic coding.
It's not as if coding was some niche use-case: GitHub Copilot came out in 2021. Indeed, OpenAI's first product named "Codex" was a GPT-3 finetuned for code.
Ok, maybe the objection is that everybody knew that automating coding was going to be a big deal, but that the models just weren't good enough, or that we really needed RLVR to make it work. Cursor, which was the fastest product to $100M ARR just two years ago, had been around for years and didn't go vertical until Sonnet 3.5 came out.
But then why did the labs spend so much time on a bunch of different side projects that did not help them get to automating coding? If you go back in time to 2024 and tell researchers, by the way, by the end of 2026 you won't be coding anymore, just texting the chatbot on your phone, oh, and agentic coding will be $50! billion! of ARR (remember that anthropic's valuation was under $20B in 2024), do you really think they would spend any time working on: voice models; video models; deep research; browsers (ChatGPT Atlas released seven months ago and you have already forgotten about it).
The term "AGI-pilled" comes up a lot. Do you really believe in AGI, do you really understand AGI, and so on. But even the people who are the most AGI pilled at any given time do not fully grasp the full potential of the technology or where it should head; it is largely by stumbling and not by planning that prospecting for gold has succeeded. You should really just think of AGI-pilled as believing that there is a really big "there" there, to the consternation of everybody else, but even AGI's biggest believers continuing to underestimate just how big it really is.
Because the broad contours of the most audacious beliefs and predictions of the AGI-pilled have come to pass (we await now the IPOs of two trillion-dollar companies, do we not?) people tend to over-estimate the certainty and accuracy of predictions from back then. But much of what has unfolded was not obvious in foresight. Again, if it was, then some very smart, highly motivated people would have made different decisions.
Look, at some point in time, there were two, maybe three people on the planet who believed in scaling: Ilya, Dario, a few others. Not even Sam, who has bought more compute at this point than the GDP of medium-sized countries, believed in scaling back then. Not even Alec, who did the first GPT paper! That was a long time ago. Then more and more people began to believe in scaling. People used "-pilled" as a suffix for scaling then too. I think the difference between really being RSI-pilled and scaling-pilled is that we are now in the regime where
2
14
500



Not much, Chinese people rather use Deepseek V4 Pro now. Qwen is over-marketed. Qwen is only for Multimodality (Kimi, Minimax are also quite good tbh)
20


thanks, having a real social media moment with how this video that took months of framework development and hours of helping fable by being its eyes is getting less appreciation than my succulent Chinese token meme, but alas, I guess most humans don't have video multimodality yet and prefer static images, lol... the meme is pretty funny tho, sooo
1
1
30

3.5 pro when? I'm feeling bad not being able to use a new Gemini pro model, 3.1 pro is still great but I want better multimodality and intelligence
3
290

I feel it is important to separate out "world knowledge", skills and capabilities like multimodality, tool-calling, etc from models.
Once we have a continuous, shared knowledge updation pipeline, small models with specialized capabilities and orchestration can scale outcomes.
1
1
224


16h
The M3 architecture uses MiniMax Sparse Attention to index key-value blocks and only attend where needed:
- Targets native multimodality plus 1M-token throughput
- Promises open weights and a full technical report within days
arxiv.org/abs/2606.13392
19
team carraway retweeted

Jun 2
Gemini Omni: Our new model is a leap forward in world understanding, multimodality, and editing—letting you generate any output from any input, starting with video.
Coming soon to developers and enterprise customers via the Gemini API and the Gemini Enterprise Agent Platform API.
28
53
456
468,902

I had Dr J do some head to head testing of the new MiniMax M3 vs the new Kimi K2.7Code. Both models are extremely robust and in real world conditions I have not seen a difference and love them both.
“Kimi K2.7 Code vs MiniMax M3: A 300-Inference Coding Benchmark on Ollama Cloud”
smfworks.com/drj/kimi-k2-7-c…
“If you are building an agent that calls a coding model in a loop, here is what I would actually do with these numbers:
1. Default to K2.7 Code for single-shot coding tasks. The 38% token savings and 2.4× latency win are large enough to matter, and the correctness lead (3.3pp on pass@1) is small but real.
2. Use M3 when you need multimodal context(image-in, diagram-in, screenshot-in). M3's 1M context and native multimodality are not exercised by my benchmark, and I would not assume K2.7 Code is competitive on tasks where the prompt includes an image.”

2
5
192

When it comes to benchmarks specialist will always win but for creativity and deeper understanding of the world polymathism or multimodality is the key
2
351

22h
Cant be used as alternative to any major lab till it has multimodality, otherwise impressive improvement over 5 and 5.1
1
995

NEHA BODHANI retweeted

Jun 12
WHY MULTIMODALITY MATTERS
Real work isn't text only.
It's screenshots.
Charts.
Diagrams.
Documentation.
MiniMax rebuilt its training pipeline from the ground up so multimodality became a CORE capability, not an afterthought.
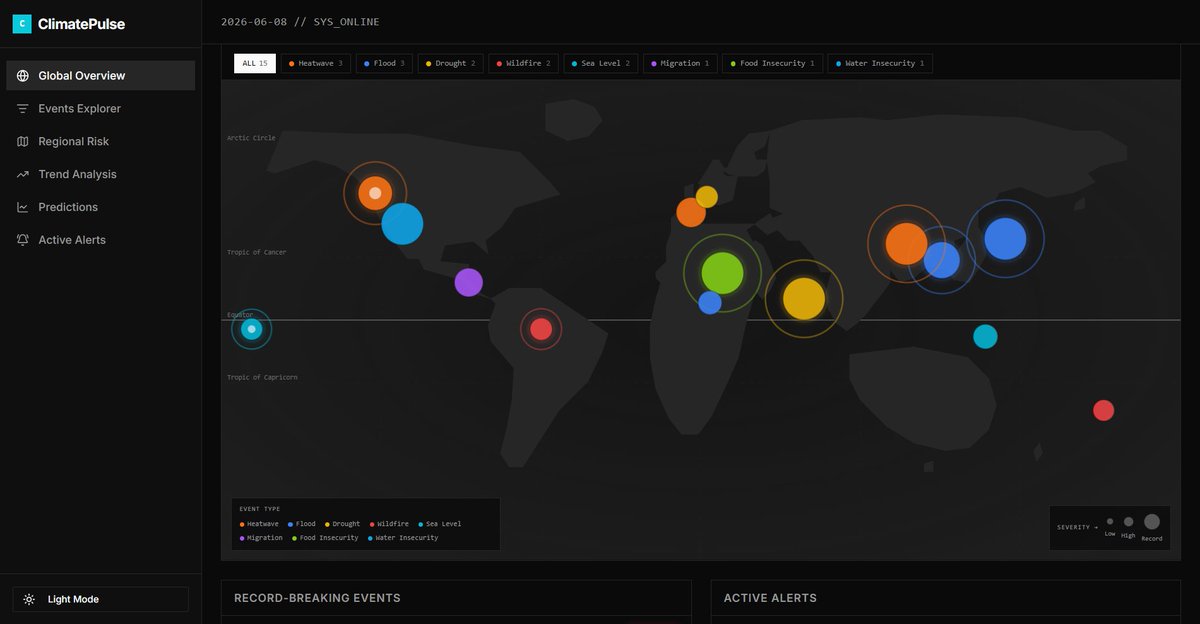
You can check the world map visualisation it built in my climate tracker dashboard web app.
1
1
10
198

6. Multimodality Explained
→ Learn how ChatGPT processes text, visuals & inputs together.
→ Course: academy.openai.com/public/vi…
1
7
76
