
32 Photos and videos









Pinned Tweet

5 Dec 2025
Since I started getting interested in ML I got it in my head that all I wanted to do was one smart thing that I could look back on and be satisfied that I did. Most papers are kinda bad even if they get accepted - the idea is very incremental, or it's just not that good an idea, or it doesn't really matter.
I never was able to do this all through PhD or my time at Amazon. All the papers I did there got into various places, but I never really thought they were actually that good. And I'd pretty much given up on this because Pluralis meant I couldn't really devote enough time to research myself. But in February I decided I didn't care and spend two months focused on a specific problem that had been going round in my head for about a year that I felt we needed to solve, and the solution came to me, and @ChaminHewa picked it up and generalised the approach and ran a bunch of novel experiments I hadn't thought of, and pulled everything together into an actual paper. And yesterday we presented this work at NeurIPS.
This is the first and probably only work I will ever do that for me feels like "ok that was GOOD". I don't care if it racks up a bunch of citations and disperses into the field or not, I don't care if someone repackages the ideas and takes all the credit for it, I don't care. For me there is an internal checkbox that just got ticked after more than ten years of trying. Anyone in ML will understand what I'm trying to say. Special day I'm going to remember for a long time.
21
12
206
18,654

1. if transacting with superintelligent models outside of the boundaries of a lab becomes difficult due to national security / ai safety concerns and so on, it will mean the Coasean boundaries of the labs will grow to encompass all interesting industry, creating a truly cyberpunk chaebol-capitalism type of future, where the goverment sort of runs them but they also sort of run the government
2. as if there weren't already enough reasons to break up your family, leave your home, the Zone of Thought will increase the attractiveness of migrating to try and have your child on american soil, so they can have 1000x the effective brain power of people born elsewhere
3. every country should probably try and either work towards a new ai security pact with the americans immediately or pool every ounce of national resources to try and create their own ASI labs lest you become complete intellectual, economic, and moral vassals to the united states of america and the output byproducts its ASIs (you wont even get to talk to them). if they succeeded (big if) this will imply a more global race and more risk factors than was previously implied by the formerly only "beating china" narrative -- but many will prefer it to the superintelligent monopolar value lock-in
4. the other alternative is to keep the tension between safety and concentration of power at the top of mind and for the government/labs to push for solving it, rather than instrumentalizing all other values to be subservient to minimizing ai harms. insofar as safety means defending properties of the fragile world we like, the diffuse nature of power is one of those properties
5. historically the americans have been really quite Benign about their global public goods hegemony despite the ability to extract significantly more rents than they do, and it makes it easy for people of all stripes to fight for america rather than under it. we probably don't have to, but i hope america overall works towards export promotion of american models rather than export control
120
123
1,635
129,300
Alexander Long retweeted

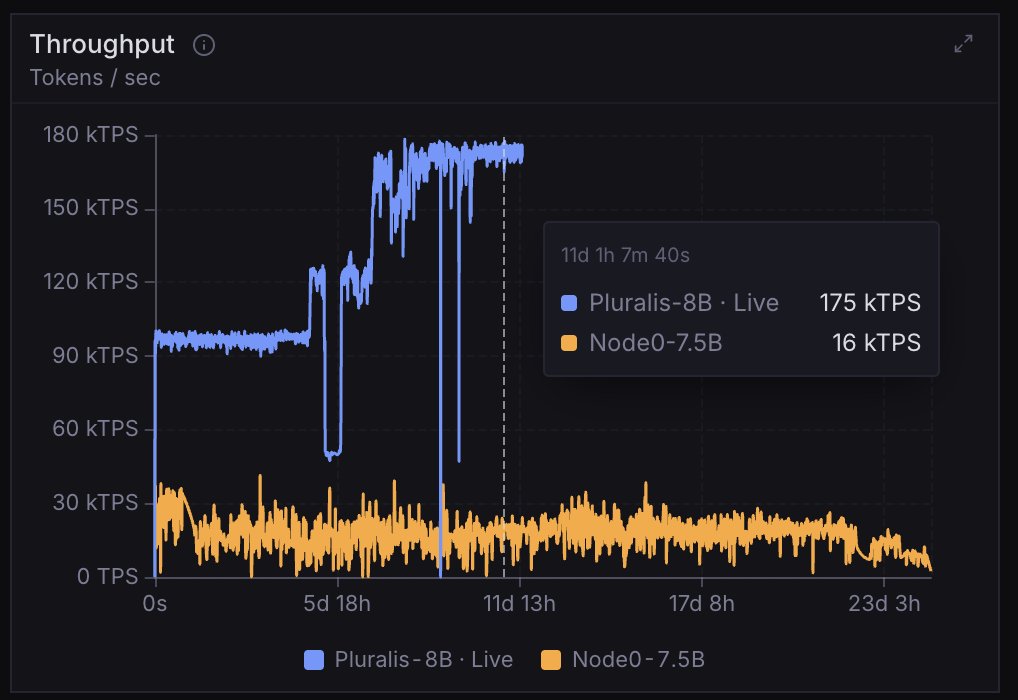
After the last 24 hours, how can you read this and not see that decentralized training is going to be the most important innovation to come out of crypto since Bitcoin?

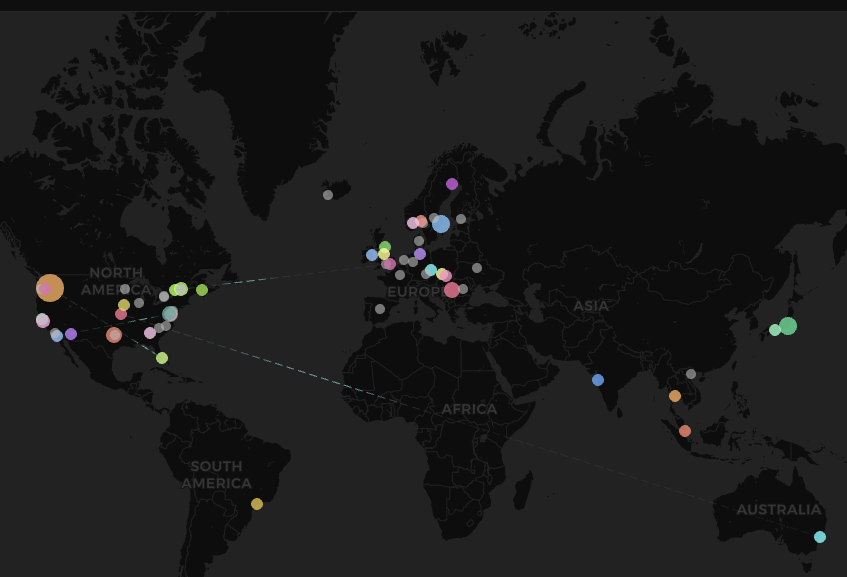
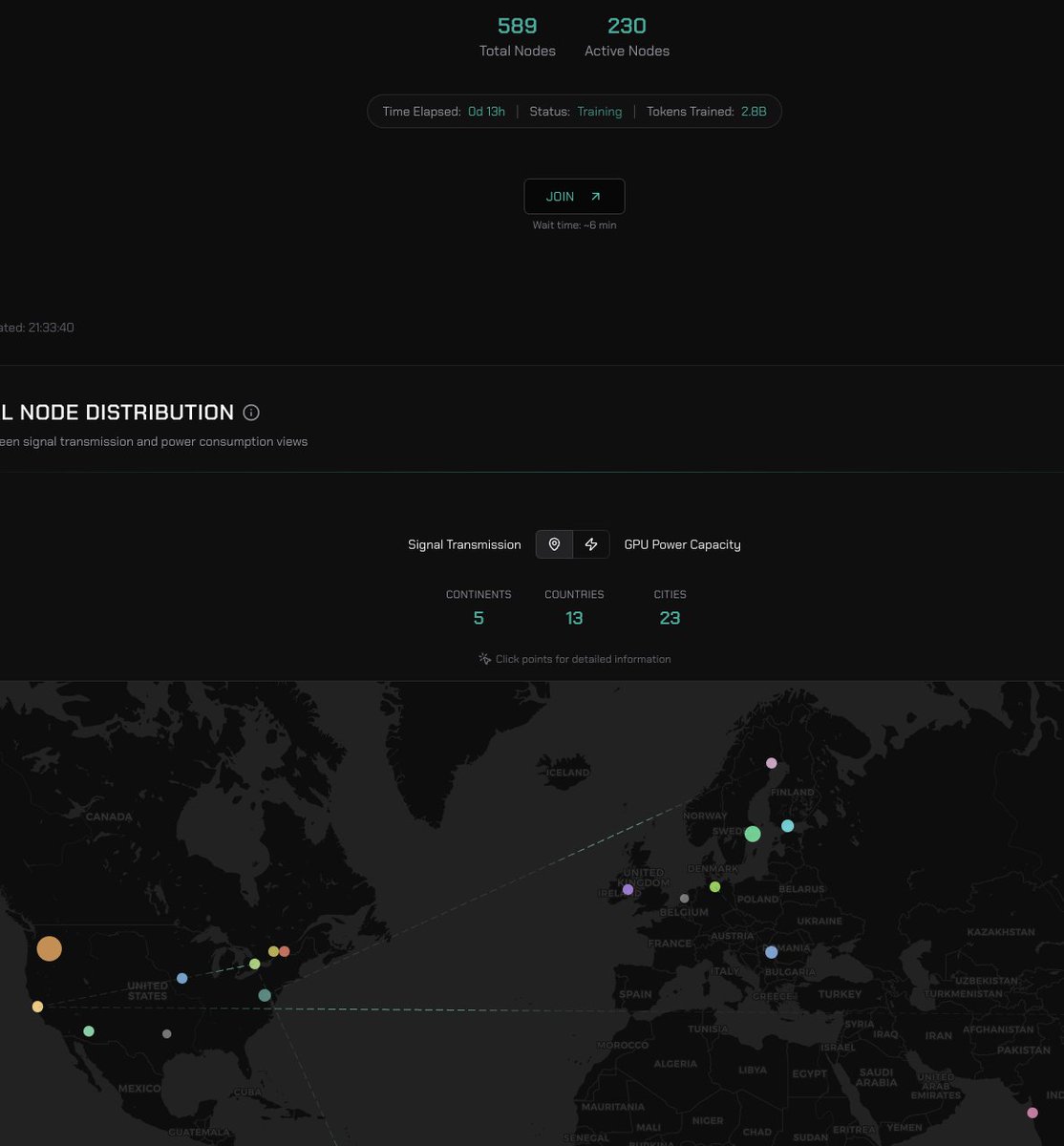
The 8B model currently training on Agora is 350B tokens in and continuing to converge. The top level metrics and evals look almost exactly like a centralised run. But;
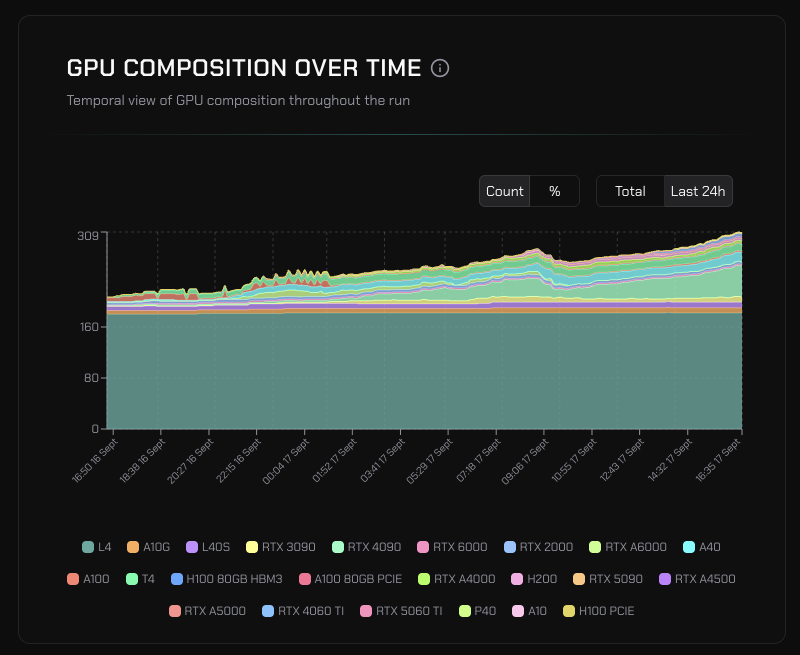
- 133 external contributors total bringing 4090's, 5090's, L40S/RTX 6000 and RTX 6000 Pros. These are cards that people actually own - there are no H100, B200's etc.
- The max number of nodes the system can support (104) was filled almost immediately. The authorization layer is receiving approximately 100 requests/minute to join.
- The total tokens/per second processed moves directly with amount of compute in the swarm, with Agora constantly optimising to make most efficient use of what hardware is present.
- MFU is approximately 20%, TPS is 170k tok/s. There are near constant communication failures which Agora is completely absorbing without slowdown.
- The system is effectively on auto-pilot, requiring very little intervention from us. Bad nodes are purged immediately before training is affected and new nodes take their place.

3
10
83
4,924
Alexander Long retweeted

11h
Sure, that's a business, but if you can train an LLM you probably already have an edge on mass access to hardware and possibly lower costs. 3rd party providers also tend to quantize beyond reason.
Sure you won't capture 100% of the market but it's clearly far from 0% either.
1
1
406
Systems like this must exist. This is the way out.
The 8B model currently training on Agora is 350B tokens in and continuing to converge. The top level metrics and evals look almost exactly like a centralised run. But;
- 133 external contributors total bringing 4090's, 5090's, L40S/RTX 6000 and RTX 6000 Pros. These are cards that people actually own - there are no H100, B200's etc.
- The max number of nodes the system can support (104) was filled almost immediately. The authorization layer is receiving approximately 100 requests/minute to join.
- The total tokens/per second processed moves directly with amount of compute in the swarm, with Agora constantly optimising to make most efficient use of what hardware is present.
- MFU is approximately 20%, TPS is 170k tok/s. There are near constant communication failures which Agora is completely absorbing without slowdown.
- The system is effectively on auto-pilot, requiring very little intervention from us. Bad nodes are purged immediately before training is affected and new nodes take their place.
4
7
43
6,436
Jun 13
I would like to make a few brief points;
- Opensource ai is not the same thing as opensource software. The models cost tens to hundreds of millions to make. This is not gonna be a volunteer effort from people doing stuff after work for free.
- the second you release a weight set, you lose any ability to make money serving your own model and recoup the training cost. This very simple property means open-weights is unsustainable.
- the things you ACTUALLY want from opensource ai is: transparent behaviour, dispersed ownership and control, a guarantee of access, the ability to build on it/modify it, and privacy.
protocol learning gets you all 4 and is the only alternative to closed models that makes any kind of sense.
By protocol learning I mean a very specific, novel thing; collaborative training and development of the models without anyone ever being able to see the complete weight set.
19
20
110
8,304
Alexander Long retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,095
25,269
85,541
83,558,378
every good outcome I’ve seen has been from finding a secret and doubling, tripling down on it in a way that compounds over time. not necessary that it even remains a secret because nobody ever believes you anyways; if it was something easy to accept it wouldn’t be available
97
146
2,673
169,276
Jun 10
Seems like a good time to repost this. tl;dr extreme power asymmetries emerge if models stay closed (we're seeing start of this now), and open-weight releases are not sustainable and we cannot rely on them. But there is a third path that makes sense.
3
8
34
1,364
Jun 10
There's three articles in this series, all worth reading; pluralis.ai/blog/decentraliz… pluralis.ai/blog/protocol-le…
4
439
Jun 9
The single most immediate, impactful downside to AI is concentration of power risk. This is 1/100th of how bad it's going to get.
The only way out of this is to have an independent model supply chain via pooled compute.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

3
9
85
5,665
Alexander Long retweeted

Jun 7
the "narrow capability gap" in question
let's put this to rest please
I can't hear the coping anymore
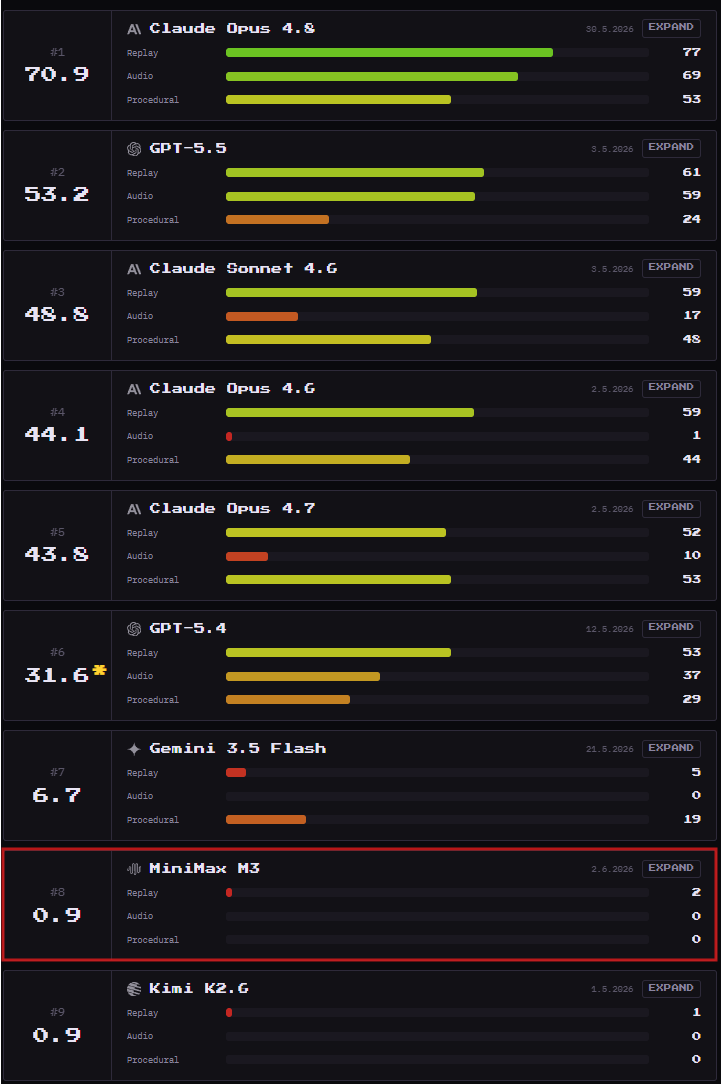
Jun 6

Your margin is my opportunity: AI version…
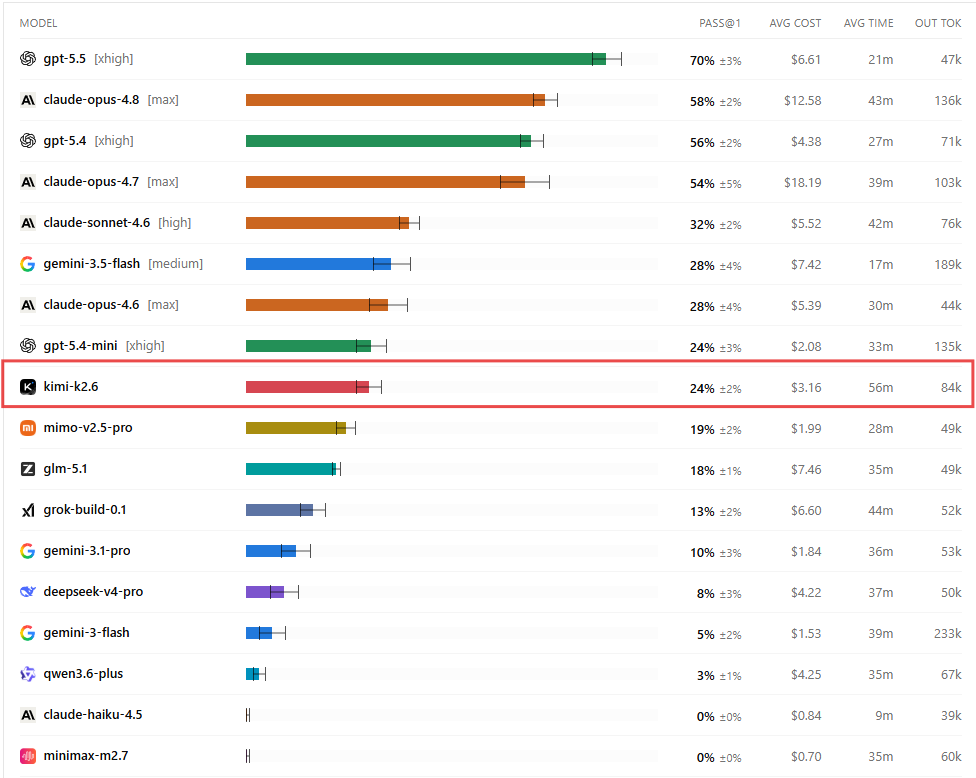
The biggest surprise of 2026 is that the capability gap between the best open-weight/source models and the best closed models has narrowed much faster than the pricing gap. The pricing gap remains enormous while the capability gap is quite narrow.
What does this means in practice?
For a company consuming 1 billion input tokens and 1 billion output tokens per month:
GPT-5.5 Pro: ~$105,000
Claude Opus 4.8: ~$30,000
DeepSeek V4 Pro: ~$5,220
DeepSeek R1: ~$2,740
I asked ChatGPT what it thought about this and it answered as follows:
“If I were building a company today, the economic frontier would look roughly like:
DeepSeek V4 Pro / R1 for high-volume inference.
Claude Opus for premium agent workflows where reliability matters.
GPT-5.5 Pro only for workloads where its incremental capability demonstrably produces enough business value to justify a 20–40× token premium.”
Most CEOs have no idea that, instead of this nuanced approach, their teams are running amok internally by picking the most expensive models in most cases and burning through massive budgets with zero governance, audit ability and control.
As control planes like our Software Factory become more standard, you can expect the run rate revenue growth of the frontier labs to go down meaningfully and the revenues of the open models to skyrocket.
Why? Because we can implement the nuanced approach above and be agnostic to model - instead focusing on customer intent, model task and cost management among other things.
32
41
579
193,275
Alexander Long retweeted

One particular aspect of LLM pretraining that often gets under-discussed in research is the fault-tolerance properties of the underlying system. Even in large centralised datacenter settings, tech reports such as Llama-3 or the recent Laguna tech report from Poolside openly talk about the importance of handling device and node failures. For example, Llama-3 training faced about 419 unexpected interruptions, with about half of those related to GPU/HBM/device-class failures one way or another (to understand the magnitude of these failures, that’s a GPU-related issue every 6 hours!).
When running distributed LLM pretraining, fault-tolerance is not a luxury; it’s a necessity. Devices can go offline for various reasons, including workers voluntarily leaving the training stack. In this setting, being able to have a resilient system that continues training without interruption is a massive engineering push, let alone the fact that the entire run is happening in geographically distributed compute.
Agora has now been up and running for more than two weeks on prosumer volunteers across North America, with nodes joining/leaving our pretraining run on an almost hourly basis. Despite this churn, training has been going smoothly so far and the training loss continues its downward trajectory at a stable throughput.
2
2
14
637
Jun 1
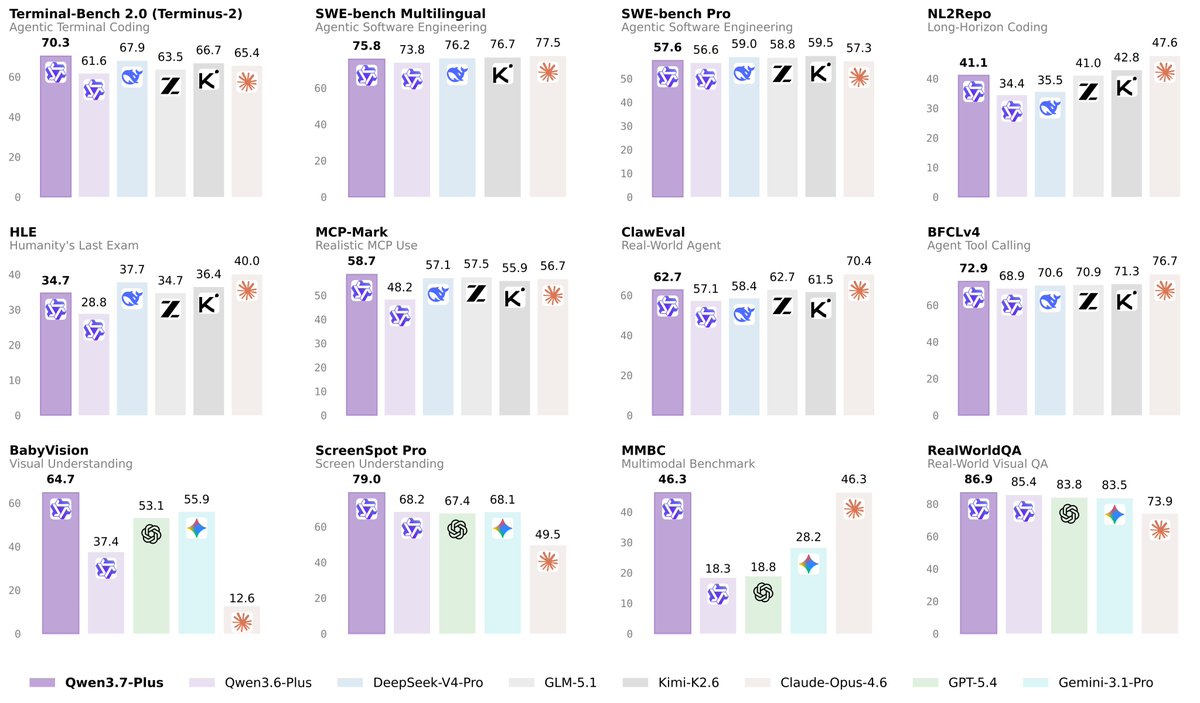
Qwen3.7 looks closed
Jun 1

👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
6
1,357

The events of the last 6 months in technology are arguable amongst the most important in human history
The tools now increasingly exist for recursive self improvement of models & agents
We are likely in very early lift off & exponential
Largely unnoticed outside of tech
266
426
4,665
581,665
May 31
Whole section on Pluralis in Chamath's substack this week right under details of Anthropic's monster round.
9
12
89
16,909
May 29
4090 and 5090 prices have more than 2x'd on vast in last 20 days. People realising these cards are good
3
1
31
4,682
Alexander Long retweeted

May 28
stop scrolling & read this all the way through

111
54
903
209,369