
📢 Seminar announcement
Element Bioscience’s AVITI24 Multiomic NGS platform at Helmholtz Munich
It' s tomorrow!!!!! in person and VC. Register!
bit.ly/helmeb

1
35
antisense. retweeted

Jun 13
TMO: ASYMMETRIC CROSS-MODAL ATTENTION FOR LEARNING CELL-STATE-DEPENDENT REGULATORY LAGS FROM SINGLE-CELL MULTIOMIC DATA biorxiv.org/content/10.64898…

1
5
12
1,170
Nadim Darwich retweeted

Jun 14
When you need a multiomic view to see the bigger picture in human health and disease, this is the fully integrated sequencer you can count on — attending #ESHG? Stop by booth 310 to see it in action.
Download the new performance data here: nanoporetech.com/products/se…

1
2
6
749



Jun 12
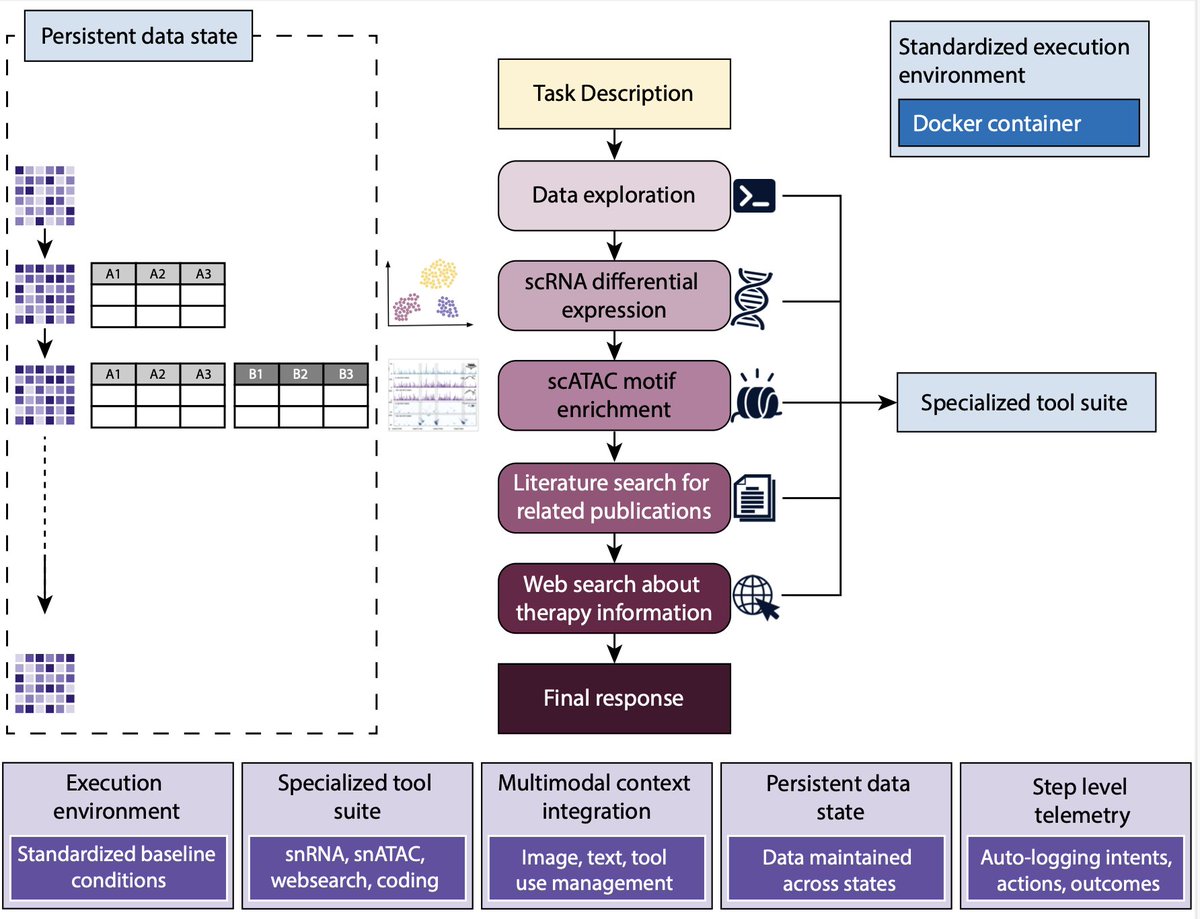
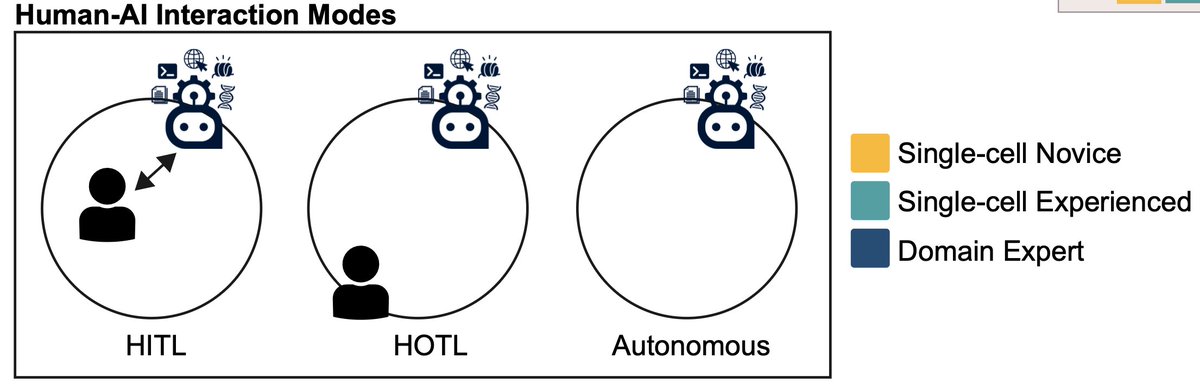
Can AI agents do real science, i.e open-ended reasoning, not just pipeline execution?
Interesting bioRxiv piece from Eli Van Allen's group at Dana-Farber/Broad. They ran a Claude Opus 4.6 agent on cancer multiomic data to find out. TLDR seems to be: neither thinking longer nor scaling up buys you the long tail. In more detail:
- Turns out the agent is strong at calling abundant cell types (82.2% correct) and much weaker for rarer ones (43.8% pass). Cell-type calls tracked the density of training evidence, not biological importance.
- Same shape on hypothesis ranking. It beat chance (30% top-1 vs 11%) but over-ranked fashionables themes that flood the literature (EMT/stromal, immune) and under-ranked metabolism and neuronal programs. Least reliable on the under-documented biology most likely to be novel.
- The authors have a clear view on the fix: not bigger models. Targeted training on underrepresented biology. Scaling does not buy you the long tail.
- Surprisingly, more reasoning steps did not mean better answers. Scrutiny depth tracked ambiguity, not correctness. Effort was a symptom of difficulty, not a driver of accuracy.
- The copilot arc also surprised me. Fully autonomous runs ranked highest in blinded expert review and read as more novel. Constant human intervention introduced a conservative bias that recapitulated known biology!! But autonomous quality fell as tasks got harder, and experts won on the hardest reasoning.
Hence their hybrid model: autonomous exploration first, human judgment for interpretation.

In our latest, we tested elements of cancer biology research using @AnthropicAI AI agents, with varying amounts of human involvement across multi-step, multi-omic analyses
Interesting times for agentic AI & biological discovery, and for the future of (cancer) biology research...
2
6
33
3,956
Elfride De Baere retweeted

Jun 11
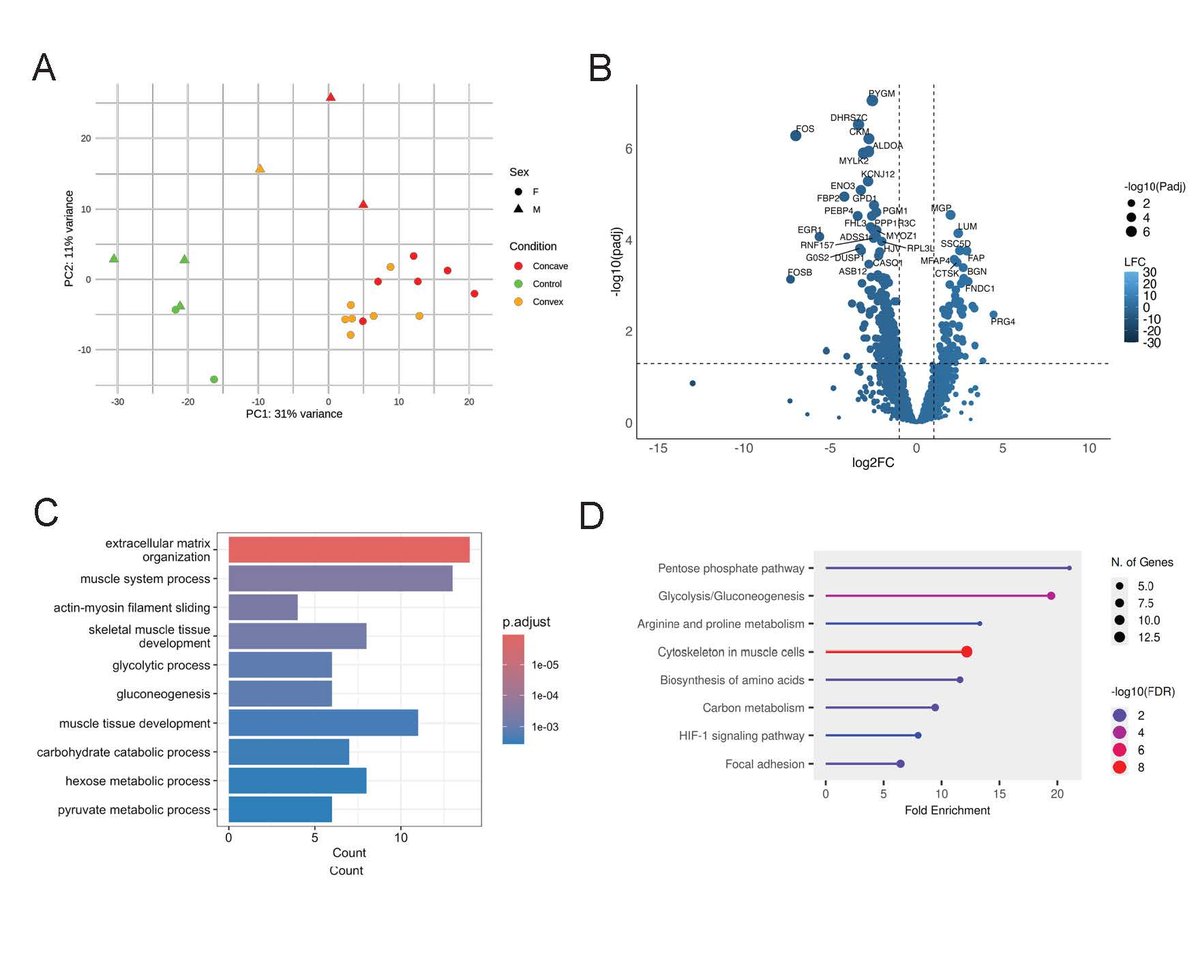
.@HGGAdvances latest article presents a multiomic study of idiopathic scoliosis that helps to elucidate disease mechanisms & enable therapeutic and biomarker development: bit.ly/3QpfUaq #ASHG #HumanGenetics #GeneticsDiscoveries



5
7
1,062
アクティブ・モティフ retweeted

Epigenetics Update - Multiomic single-cell perturbation screens reveal critical lncRNA regulators of senescence go.nature.com/47Aev6m
Researchers from @PKU1898 in Nature Aging
#Epigenetics #Multiomics #SingleCell #LncRNAs
---
Gain deeper insight at epigenometech.com
3
9
571
Sara Tolaney retweeted

It was an honor to receive a Young Investigator Award from @ConquerCancerFd at @ASCO this year, supporting our multiomic profiling of patients with HR metastatic breast cancer on ADC /- immune therapy. YIA is a transformative grant for us young Oncologists (a few pictured here 😊)!!
Deepest thanks to my dream mentorship team for making it happen: @stolaney1 @DFCI_BreastOnc @VanAllenLab



1
2
28
906