
Saquib Aftab retweeted

Jun 12
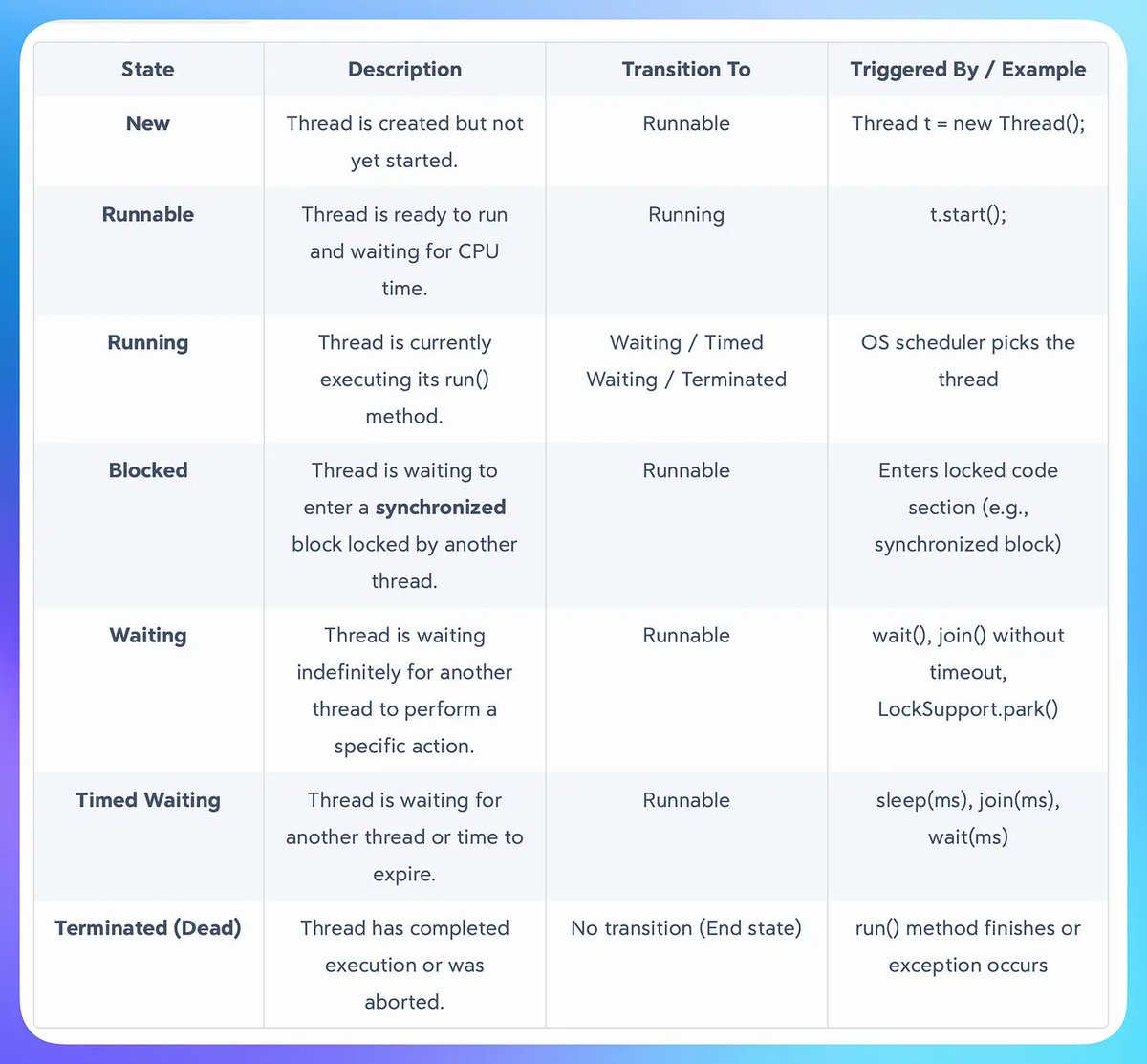
Why Is Multithreading hard?
Multithreading involves several concepts that can be challenging to grasp.
Concurrency: Multiple things are happening at the same time.
Synchronization: To ensure data integrity between threads.
Coordination: Ordering and dependency management between threads.
Visibility: This ensures that one thread sees changes made by others.
1
3
21
8,035

Multithreading
├── Thread
├── Thread Lifecycle
├── Synchronization
├── Race Condition
├── Deadlock
├── ExecutorService
├── Thread Pool
└── Concurrent Collections
10

14h
if you need multithreading write it in haskell why would you endure multithreading in rust
15

Kotlin Coroutines: Deep Dive by Marcin Moskała is the featured book 📖 on Leanpub!
Kotlin coroutines have revolutionized JVM development, especially on Android and the backend, as they let us easily implement efficient and reliable multithreading. Their cutting-edge design and features are ideally suited to modern use cases. In this book, we will explore how Kotlin coroutines work and how we can use them to improve our code.
#computer_programming #kotlin
1
62

How I made my Python script 4X FASTER with Multithreading 🪡
Today I learn Multi threading ...
I have made a script using multi threading to scrape the books title and compare the time taking by the process
so as you can see
normal sequential takes: 6.23 sec
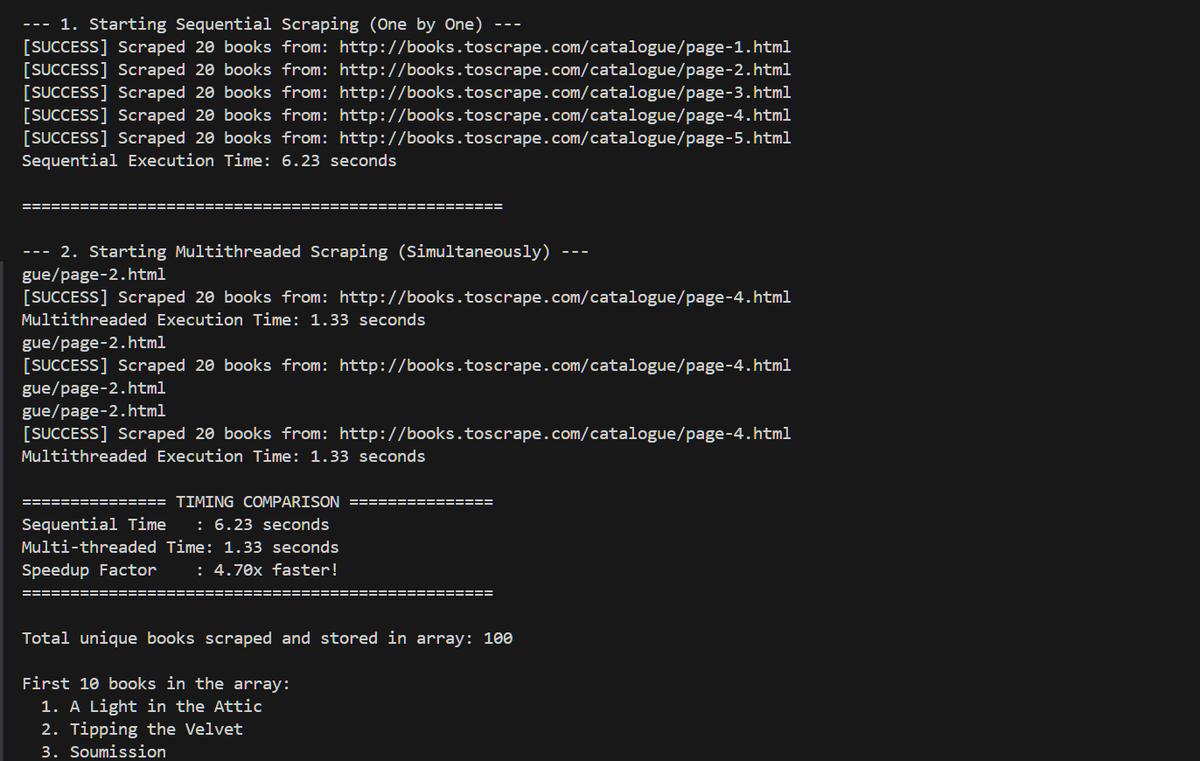

2
2
54
Ajitesh Shukla retweeted

Jun 12
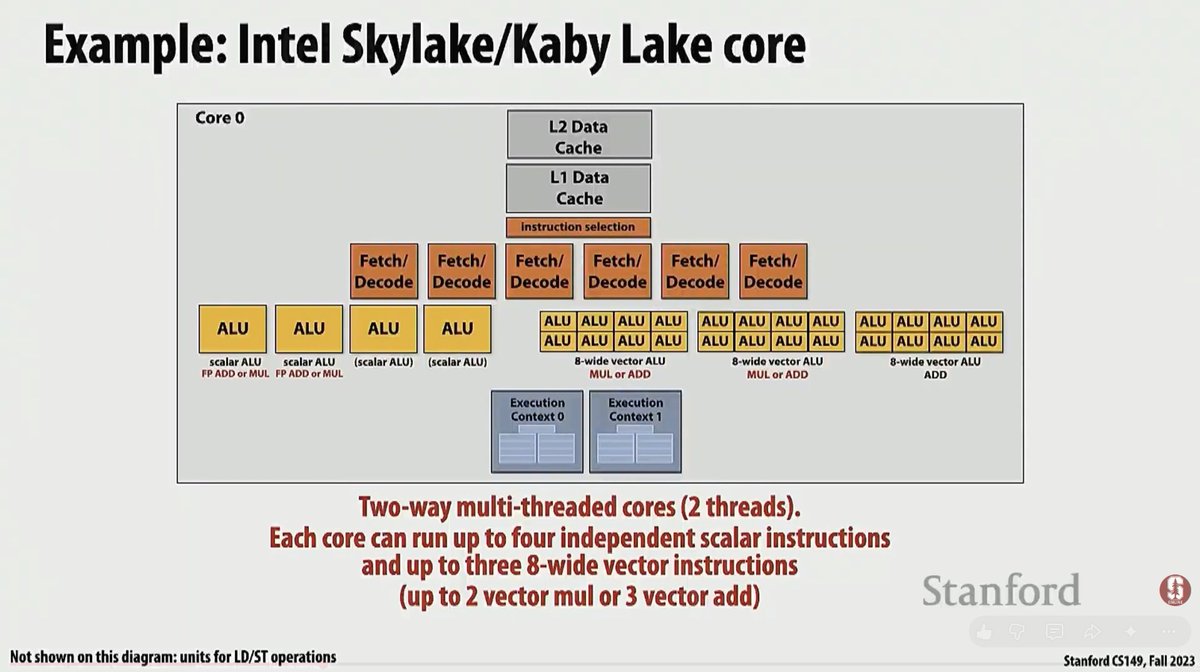
47/100 of GPU Grind
following stanford cs149 with lecture 3, covering cpu multithreading to hide stalls and maximise core utilization, the example of Intel Kaby-Lake cpu with superscalar core in which multiple instructions can run per clock cycle. Also covering heterogeneous superscalar cores (with scalar and SIMD ALUs) that can run in the same clock cycle
also covering GPU SIMT with a simplified explanation of warps and warp divergence
i love re-watching a course about "beginner" concepts of HPC and see how it is explained by different professors, the laundry pipelining analogy was funny 😆


Jun 8

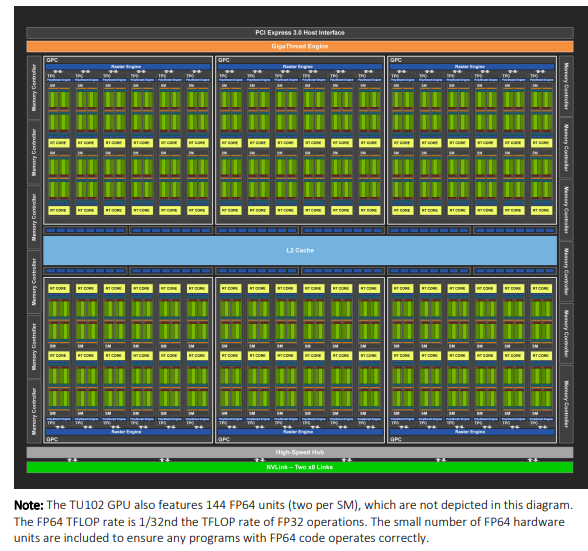
46/100 of GPU Grind
starting to work on a fp16 gemm kernel, playing with the __half api for now, all intrinsics it feels like i'm writing avx512 but in a cuda program. i'm setting up all the reference computations etc, and i was surprised to see the difference between fp64 flops and fp16 flops (i run it on a 2060 for now, going to run it on ampere ultimately to be able to use more features).
like the fp64 to fp16 ratio for cuBLAS gemms is 1/36, which is not even that much considering the hardware peak of fp64 is 1/32 of fp32 which is 1/2 of fp16, it's just that i forgot the chip had that few fp64 cores. the way they say it in the whitepaper is literally "we just included bare minimum fp64 cores so that fp64 program can run correctly". i knew that at some point but i forgot and was still surprised 😅

1
22
925
Immaraju Giridhar retweeted

Jun 12
HOW JAVA HANDLES MULTITHREADING AND CONCURRENCY
You write Java code that defines tasks capable of running simultaneously using threads.
Java provides built-in multithreading support through the Thread class and the Runnable or Callable interfaces.
The Java Virtual Machine (JVM) is responsible for managing thread creation, scheduling, and execution across CPU cores.
AT RUNTIME:
→ The JVM creates multiple threads that execute independently within the same process, enabling concurrent task execution.
→ Each thread maintains its own stack memory while sharing heap memory with other threads in the application.
→ Java provides synchronization mechanisms such as synchronized methods, blocks, locks, and monitors to coordinate access to shared resources and prevent race conditions.
→ The Java Concurrency API (java.util.concurrent) offers powerful utilities such as thread pools, executors, futures, semaphores, countdown latches, and concurrent collections.
→ The JVM collaborates with the operating system scheduler to distribute threads efficiently across available CPU cores.
→ Modern Java versions introduce advanced concurrency features such as virtual threads, making it easier to build highly scalable applications with minimal resource overhead.
→ Developers can design responsive applications by separating long-running tasks from the main execution flow.
THE RESULT:
Java applications can perform multiple operations simultaneously, improving responsiveness, throughput, resource utilization, and scalability on modern multi-core systems.
→ Want to go deeper? Check out this ebook:
Java: The Complete Handbook:
codewithdhanian.gumroad.com/…

6
11
92
2,234
Frank Alcantara retweeted

Jun 11
one of the weirdest things about multithreading is that two threads can be working on completely different variables and still slow each other down
because those variables happen to live on the same cache line.
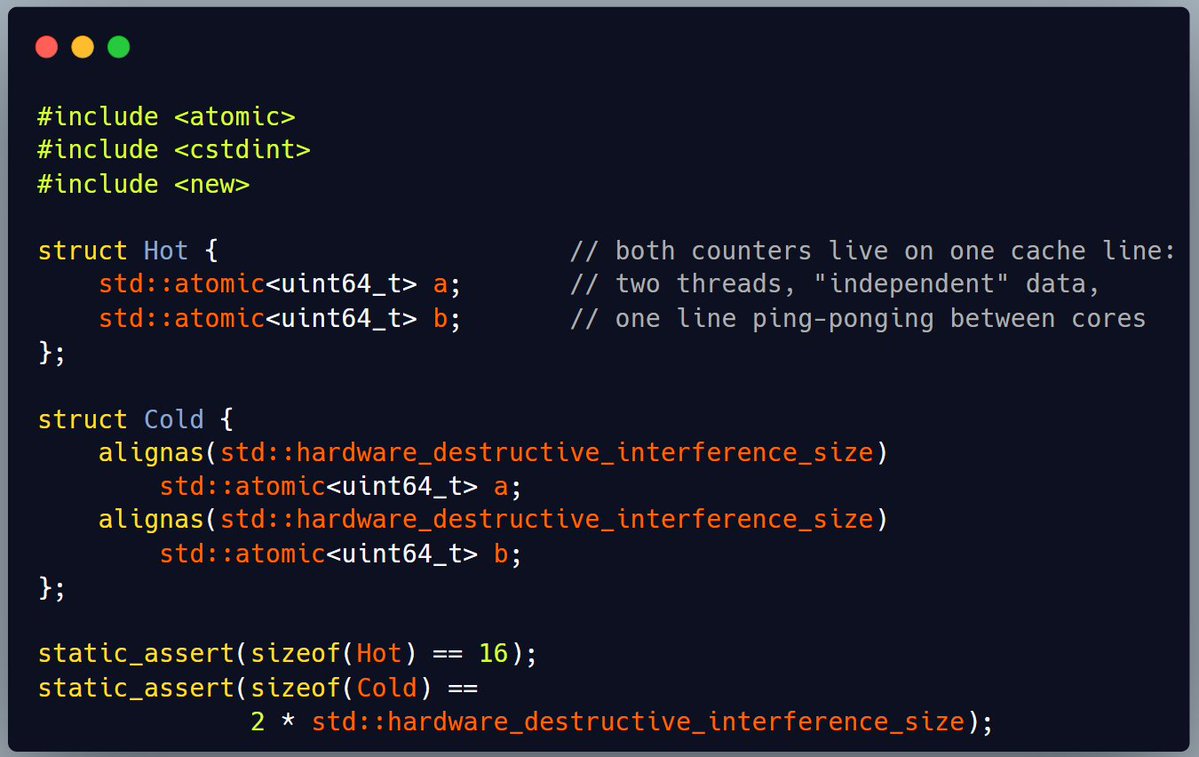
5
5
172
7,815



Jun 12
multithreading
Jun 12

Codex is how @ndrewpignanelli at @intelligenceco updates multiple parts of a website in parallel, turning a week of work into three days.
27

After 2 months of job searching following a layoff, I’m still looking for my next opportunity.
Java Backend Developer • 1 YOE in FinTech
• 50 Spring Boot REST APIs shipped
• 25% API latency reduction via SQL optimization
• Batch processing, multithreading.
A thread 🧵
1
2
61
Ali Shan retweeted

Jun 9
Just aced my first Java multithreading quiz! Spent 2 days reviewing thread pools and synchronization, practice makes perfect. #StudyUpdate #CodingJourney,

2
7

Jun 12
Day 7 of #BuildUntilHired
Today I revised:
✅ Exception Handling
✅ Multithreading
✅ Java 8 Features (Streams, Lambda Expressions, Functional Interfaces)
Also solved practice problems
#BuildUntilHired #Java #SpringBoot #DSA #DeveloperJourney #TechLearning #AI #OpenToWork
1
23


Day 12/60 #60DaysOfLearning2026
Started learning Java fundamentals, covering Java architecture, core OOP concepts, exception handling, multithreading, and file handling.
@lftechnology
#LSPPDay12 #LearningWithLeapfrog

4
59