
19 Mar 2024
#NLPaperAlert: If you are in Malta for #EACL2024, check out our latest work on Sentence Alignment and Machine Translation!
Great work led by @franmolfese and @SBejgu from @SapienzaNLP. #NLProc #AI
📄: aclanthology.org/2024.eacl-l…
19 Mar 2024

Join us today at #EACL2024 for our presentation entitled “CroCoAlign: A Cross-Lingual, Context-Aware and Fully-Neural Sentence Alignment System for Long Texts” in the Sentence-level Semantics track! #NLProc
(Radisson Blu, Carlson Ballroom, 5th floor, Malta)

1
17
709

7 Dec 2023
📢#NLPaperAlert: "Increasing Coverage and Precision of Textual Information in Multilingual Knowledge Graphs"
🚀Check out this #EMNLP2023 paper by @ConiaSimone et al.! #NLProc
✨New multilingual benchmark: github.com/apple/ml-kge
30 Nov 2023

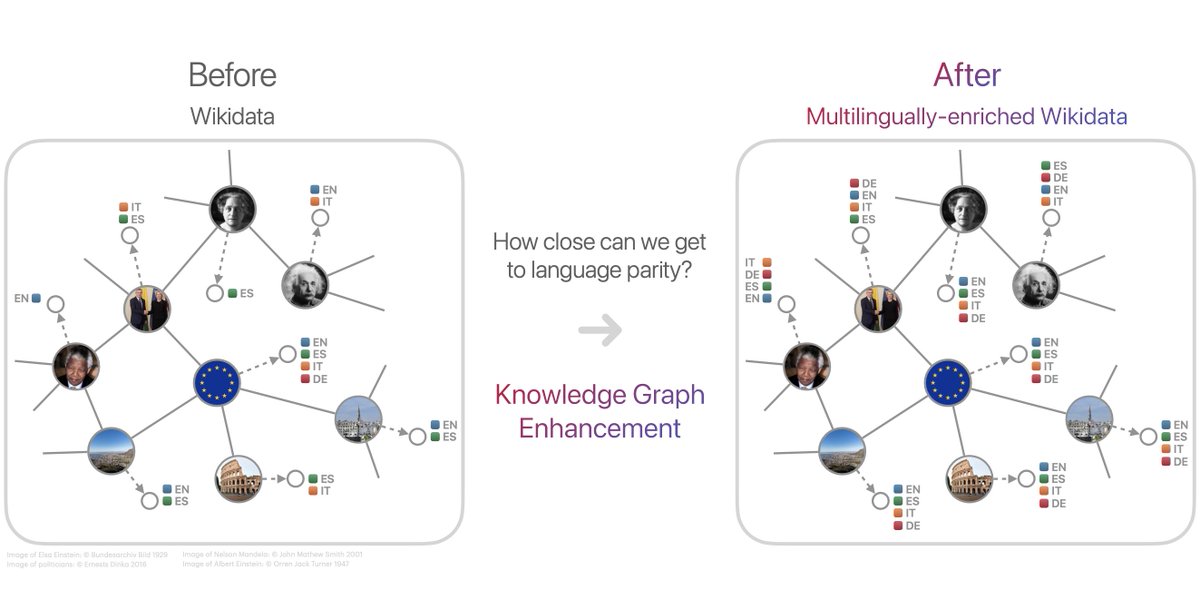
🧐How can we narrow the gap between English and non-English information in #KnowledgeGraphs? Apparently, #LLMs are still not the answer!
📄More in our #EMNLP2023 paper: arxiv.org/abs/2311.15781
🙏Thanks Min Li, @daniel_js_lee, @umarfm13, @ihabilyas, @yunyao_li!
🧵[1/n] #NLProc
3
10
1,055

25 Oct 2023
📢#NLPaperAlert: Glad to have to contributed to this work on benchmarking LLMs for text simplification. Soon to appear @emnlpmeeting #EMNLP2023
tl;dr: we analyse the zero-shot simplification capablities of 44 large language models in 3 domains (wiki, news, and medical).
25 Oct 2023

We are happy to share that "BLESS: Benchmarking Large Language Models on Sentence Simplification" was accepted to EMNLP 2023!
arxiv.org/abs/2310.15773 together with
@tannonk Alison Chi @swetaagrawal20 @d_aumiller @feralvam @MattShardlow, in collaboration with TS community❤️ :)
1
21
1,726

19 Oct 2023
#NLPaperAlert
😴 Aren't you tired of the monotonous way ChatGPT responds?
💡Infuse your preferences to personalize the way your LLM responds, based on our new alignment method 🥣Personalized Soups🥣
✅ Great work led by @jang_yoel , check it out!!
19 Oct 2023

🎯 Tired of one-size-fits-all AI chatter? ChatGPT tends to generate verbose & overly informative responses. This is because the current RLHF pipeline only allows aligning LLMs to the general preferences of the population. However, in the real world, people may have multiple, conflicting preferences (e.g., Friendliness vs Formal, Informative vs Conciseness).
✨ To model each personalized preference without conflict, we convert the current alignment problem into a Multi-Objective RL problem and introduce Personalized Soups🍜.
With Personalized Soups🍜, you could align your LLM to your preference by simply merging the parameters optimized on single objectives (preferences) on the fly!
paper: arxiv.org/abs/2310.11564

1
15
1,944

15 Oct 2023
📢#NLPaperAlert Incredible work led by @seungonekim @jay_shin & Yejin Cho!
➡️ Ranking responses is subjective
➡️ Do you prefer short vs long, formal vs informal, creative vs precise responses?
➡️ 🔥Prometheus 🔥➡️Open LM trained to respect custom criteria
Check it out!
15 Oct 2023

Excited to present 🔥Prometheus, a fully open-source evaluator LM that is on par with GPT-4 evaluation when the “appropriate” reference materials are appended!
* Could generalize to customized score rubrics
* Shows high correlation with both human evaluators & GPT-4 evaluation
6
28
6,576

16 May 2023
📢#NLPaperAlert Is superhuman performance hype truly grounded? Check out our #ACL2023NLP paper with a thorough analysis of popular #NLU benchmarks (#SuperGLUE and #SQuAD) and recommandations. Joint work w/many world-renowned #NLP researchers!
arxiv.org/abs/2305.08414
#NLProc

1
3
11
1,034
2 May 2023
#NLPaperAlert: "Entity Disambiguation with Entity Definitions" presented today at #EACL2023 @eaclmeeting
By @luigi_proc @ConiaSimone @edoardo_barba @RNavigli @SapienzaNLP
Paper: aclanthology.org/2023.eacl-m…
#NLProc #AI

1
9
25
2,171
5 Dec 2022
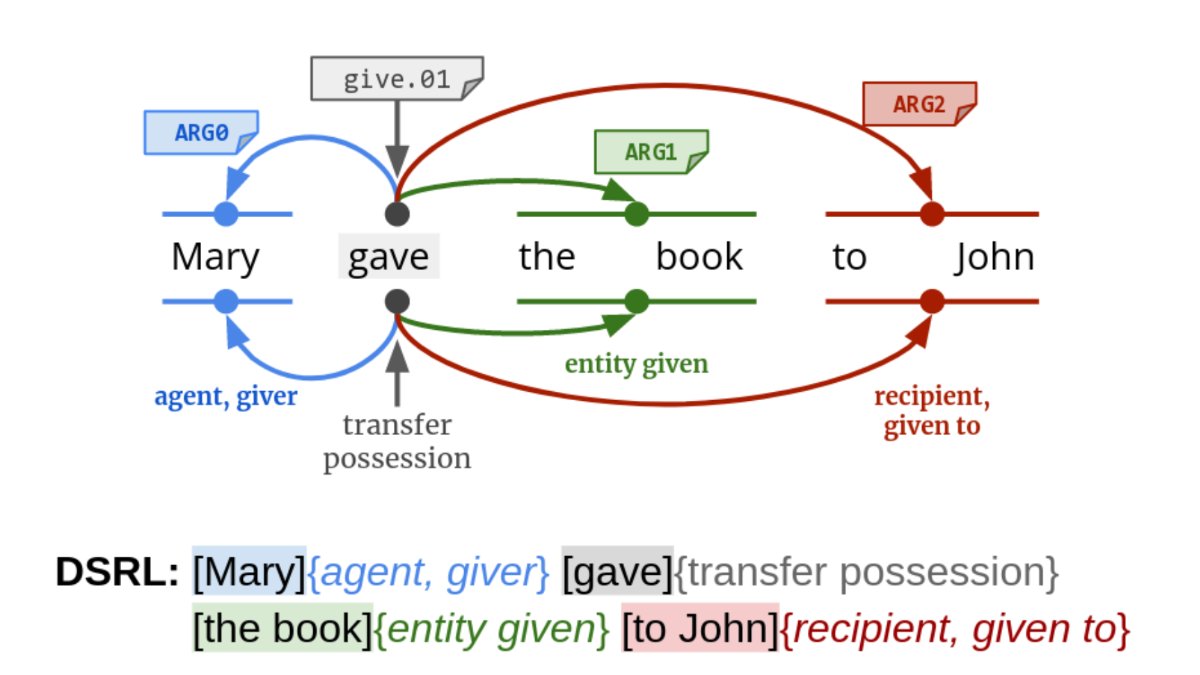
#NLPaperAlert 📢: Semantic Role Labeling meets Definition Modeling in our new paper in Findings of #emnlp2022.
By @ConiaSimone @edoardo_barba @alescire94 @RNavigli @ERC_Research #NLProc
Read more 📄: researchgate.net/publication…
10
16
30 Nov 2022
📢 #NLPaperAlert 🌟Active Learning Over Multiple Domains in Natural Language Tasks 🌟
To appear at Workshop on Distribution Shifts (DistShift) at #NeurIPS2022 later this week!
📜: arxiv.org/abs/2202.00254
This is honestly the hardest ML problem I’ve ever worked on. 👉🧵

2
13
53

25 Oct 2022
📢 #NLPaperAlert: Outliers Dimensions that Disrupt Transformers Are Driven by Frequency
with @gpuccetti92 @bkbrd Felice Dell'Orletta
TLDR: remember how BERT over-relies on just 48 magic params? They're related to token frequency in training! /1
arxiv.org/abs/2205.11380
4
5
39
21 Oct 2022
#NLPaperAlert Proud of our new work!
New findings, SOTA results, and, my personal favourite, 🌟 Open sourcing new models 🌟, significantly better than current T5s!

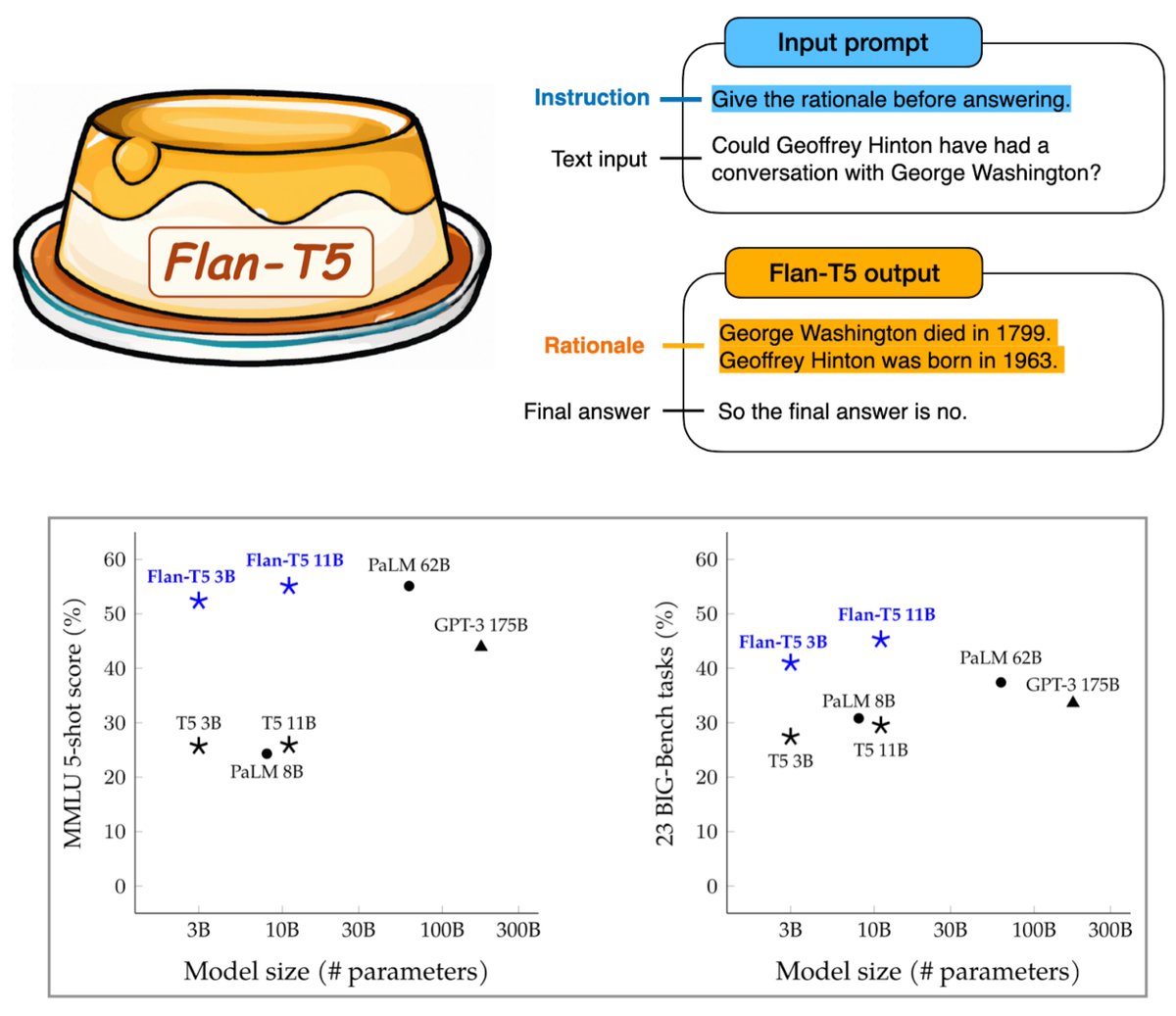
New open-source language model from Google AI: Flan-T5 🍮
Flan-T5 is instruction-finetuned on 1,800 language tasks, leading to dramatically improved prompting and multi-step reasoning abilities.
Public models: bit.ly/3sbNPDJ
Paper: arxiv.org/abs/2210.11416
2
4
44

Social bias is not the only type of bias in NLP models. My collaborators and I Introduce 🆘: Systematic offensive stereotyping bias, define it, propose a method to measure it and validate it in our #COLING2022 paper efatmae.github.io/publicatio…
#nlproc #NLPaperAlert 🧵(1/8)
1
10
27
3 Oct 2022
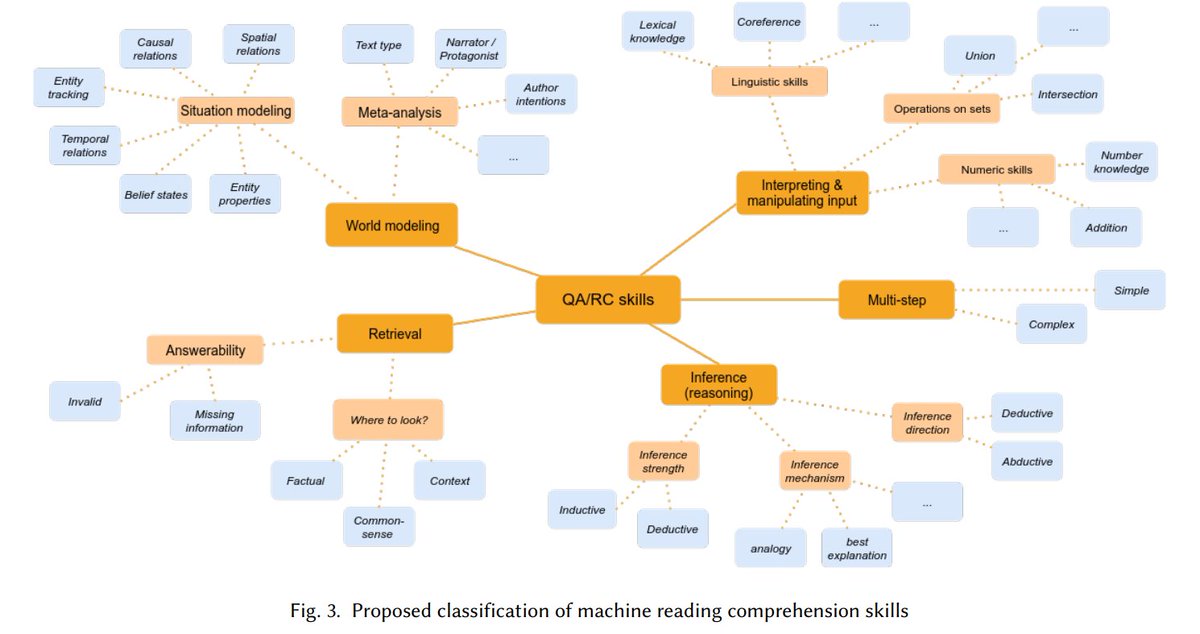
#NLPaperAlert: QA Dataset Explosion🔥is out in ACM CSUR, updated with 30 new resources! with @nlpmattg @IAugenstein
We surveyed 200 QA/RC datasets to develop a taxonomy of formats & reasoning skills. Also discussed: modalities, domains, non-English data
arxiv.org/abs/2107.12708
2
24
73
27 Sep 2022
#NLPaperAlert 📢 Awesome new paper by @rajivmovva
Q: As LLMs grow ever larger, how can we compress them?
A: Combining these popular methods yields 🌟super-multiplicative🌟 compression ratios📈!
1/
26 Sep 2022

Delighted that our paper was accepted to COLING 2022!
Our paper asks how different neural network compression techniques (quantization, distillation, pruning) interact.
#COLING2022 #NLProc arxiv.org/abs/2208.09684

ALT Title, authors, and abstract of paper, from https://arxiv.org/abs/2208.09684.
1
2
17
20 Sep 2022
📢 #NLPaperAlert #COLING2022
Machine Reading, Fast And Slow: When Do Models "Understand" Language?
TLDR: instead of claiming broad "language understanding", why don't we define the reasoning expected in specific cases?
arxiv.org/abs/2209.07430
with @sagnikrayc @IAugenstein
/1
2
20
94
23 May 2022
📢 #NLPaperAlert: What Factors Should Paper-Reviewer Assignments Rely On?
arxiv.org/abs/2205.01005
with @Ternethorn, to appear at #NAACL2022
TLDR: How should conferences match papers to reviewers, so as to avoid #Reviewer2? #NLProc community says: not with similarity scores!🧵
/1

3
8
22
14 Apr 2022
#NLPaperAlert 📢 We bring together existing resources, revise them, and propose SRL4E, a unified evaluation on Semantic Role Labeling 4 Emotions!
Read our #ACL2022 preprint: researchgate.net/publication…
By @caesar_one_ @ConiaSimone @RNavigli
@ERC_Research @EuroLangTech #NLProc

1
13
30
4 Apr 2022
#NLPaperAlert 📢: where do language models encode predicate-argument structure information? And how to use it in multilingual Semantic Role Labeling?
Find out more in our #ACL2022 paper! #NLProc
📝: researchgate.net/publication…
By @ConiaSimone @RNavigli
@ERC_Research @EuroLangTech
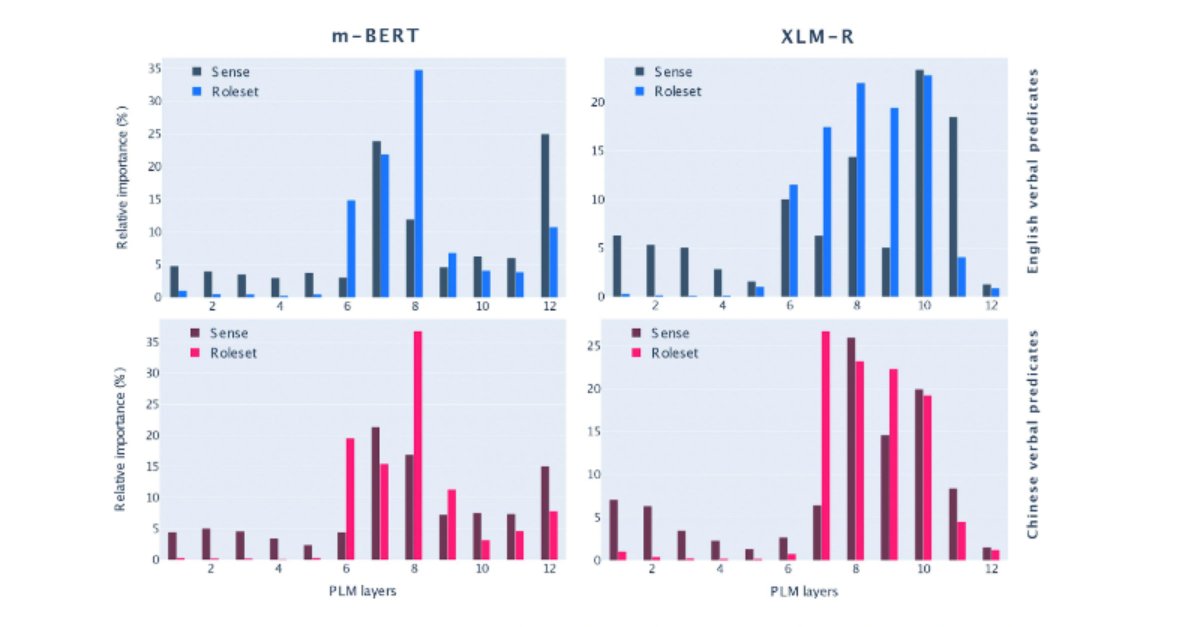
10
20
7 Feb 2022
📢📜#NLPaperAlert 🌟Active Learning over Multiple Domains in NLP🌟
In new NLP tasks, OOD unlabeled data sources can be useful. But which ones?
We try active learning ♻️, domain shift 🧲, and multi-domain sampling🔦 methods to see what works [1/]
arxiv.org/abs/2202.00254

2
18
73
5 Oct 2021
#NLPaperAlert: Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics
With @prajjwal_1 @bkbrd, accepted by insights-workshop.github.io
arxiv.org/abs/2110.01518
A proud example of a paper genre I'd call "research realism": a mix of negative & (cautiously) positive results
/1
3
7
33