
PostDoc @ Sapienza University of Rome | ex-Amazon
Joined March 2010
- Tweets 52
- Following 418
- Followers 223
- Likes 100
Photos and videos
Pinned Tweet

14 Apr 2022
I’m thrilled to participate in such a prestigious conference with my first paper! See you in Dublin at #ACL2022 😎 #NLProc
14 Apr 2022

#NLPaperAlert 📢 We bring together existing resources, revise them, and propose SRL4E, a unified evaluation on Semantic Role Labeling 4 Emotions!
Read our #ACL2022 preprint: researchgate.net/publication…
By @caesar_one_ @ConiaSimone @RNavigli
@ERC_Research @EuroLangTech #NLProc

6
Cesare Campagnano retweeted

20 Dec 2024
We are very excited to share that the work of @caesar_one_ , @antonio_mallia , @JackPertschuk and @fabreetseo has been accepted to #ECIR2025 as a #shortpaper. See you in #Lucca.
@ecir2025 @pinecone
#AI #Research #IR #industry

Congratulations to our very own @antonio_mallia, @caesar_one_, and @JackPertschuk – as well as their co-authors – on their accepted #ECIR2025 research papers! 🎉 They continue to push the state-of-the-art forward on information retrieval, and we as an industry are better for it! 📚
📜 Sean MacAvaney, Antonio Mallia and Nicola Tonellotto: “Efficient Constant-Space Multi-Vector Retrieval", 2025
📜 Kaili Huang, Thejas Venkatesh, Uma Dingankar, Antonio Mallia, Daniel Campos, Jian Jiao, Christopher Potts, Matei Zaharia, Kwabena Boahen, Omar Khattab, Saarthak Sarup and Keshav Santhanam: “ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring”, 2025
📜 Cesare Campagnano, Antonio Mallia, Jack Pertschuk and Fabrizio Silvestri: “E2Rank: Efficient and Effective Layer-wise Reranking”, 2025

4
10
604

Congratulations to our very own @antonio_mallia, @caesar_one_, and @JackPertschuk – as well as their co-authors – on their accepted #ECIR2025 research papers! 🎉 They continue to push the state-of-the-art forward on information retrieval, and we as an industry are better for it! 📚
📜 Sean MacAvaney, Antonio Mallia and Nicola Tonellotto: “Efficient Constant-Space Multi-Vector Retrieval", 2025
📜 Kaili Huang, Thejas Venkatesh, Uma Dingankar, Antonio Mallia, Daniel Campos, Jian Jiao, Christopher Potts, Matei Zaharia, Kwabena Boahen, Omar Khattab, Saarthak Sarup and Keshav Santhanam: “ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring”, 2025
📜 Cesare Campagnano, Antonio Mallia, Jack Pertschuk and Fabrizio Silvestri: “E2Rank: Efficient and Effective Layer-wise Reranking”, 2025
2
11
1,637
31 May 2024
RT @RSTLessGroup: Congratulations to @caesar_one_ who defended his #PhD #thesis entitled "Foundational Advancements of Large Language Mode…
4
23 May 2024
RT @RSTLessGroup: Today @Andrea_Bacciu has presented the paper "DanteLLM: Let’s Push Italian LLM Research Forward!” @LrecColing , coautho…
6
21 May 2024
RT @RSTLessGroup: Don't miss @Andrea_Bacciu and @caesar_one_ ’s presentation on Thursday at @LrecColing .They’ll be sharing their paper "Da…
5


Cesare Campagnano retweeted

23 Mar 2024
This is actually huge:
- No SFT stage (e.g., Zephyr used 200k examples)
- Preference tuning with 7K examples only (other models trained with at least 60k samples)
I've put a lot of care & love building the DPO version of the amazing Capybara dataset from @ldjconfirmed so I'm really pleased to see these results.
Let's double down on useful open data for OSS AI developers and researchers
23 Mar 2024

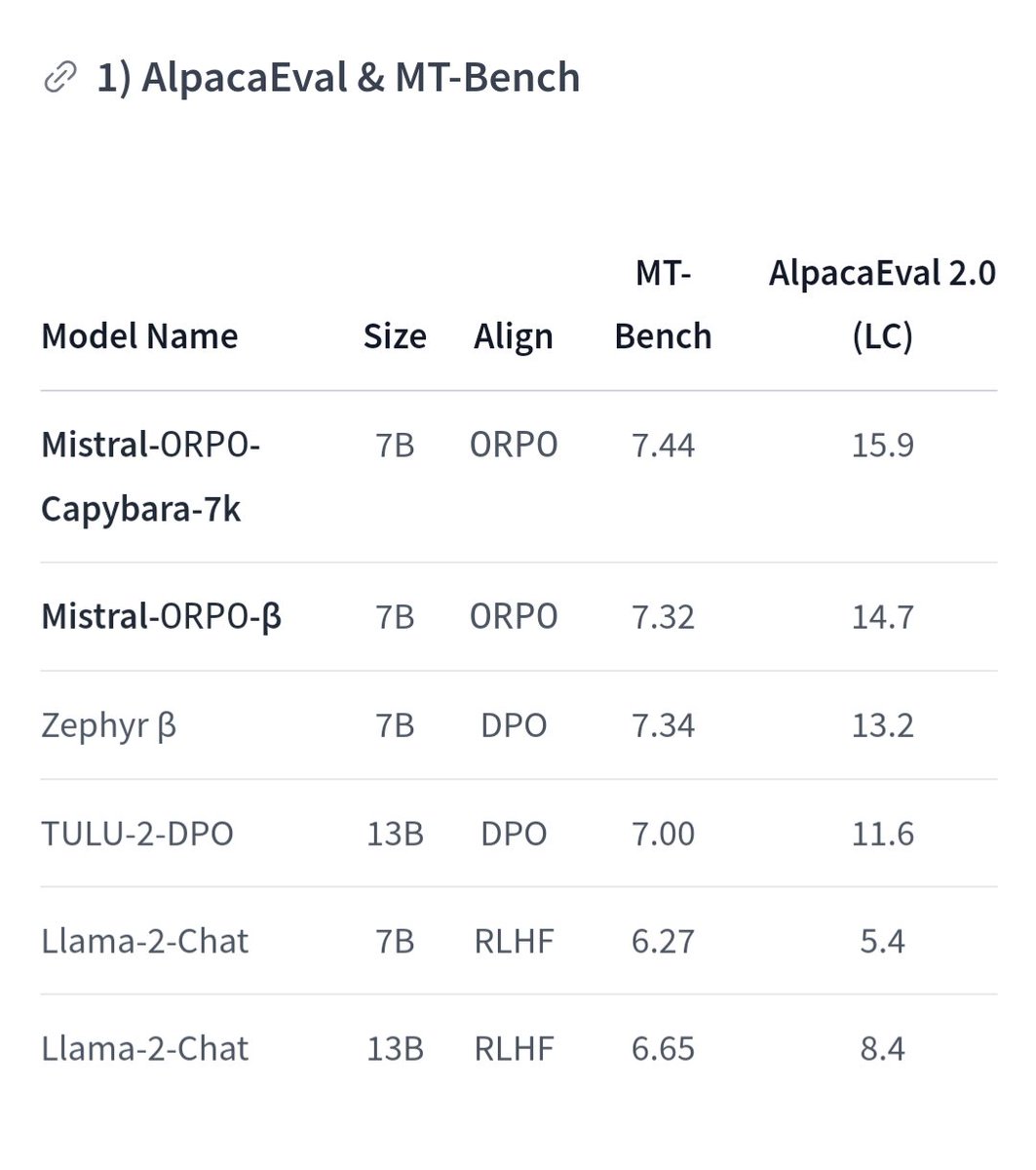
📢New model, Mistral-ORPO-Capybara-7k in ORPO collection!🧵
With 💡ORPO💡 7k Capybara preference pair by @argilla_io🔥 Mistral (7B), you can get the human-aligned chat model within 2.5 hours of fine-tuning👀
👉AlpacaEval 2.0 (LC): 15.9%
👉MT-Bench: 7.44
👉IFEval: 61.27%
2
17
72
6,519

Redefining Retrieval in RAG
A nice comprehensive study that focuses on the components needed to improve the retrieval component of a RAG system.
Confirms that the position of relevant information should be placed near the query. The model will struggle to attend to the information if this is not the case.
Surprisingly, it finds that related documents don't necessarily lead to improved performance for the RAG system. Even more unexpectedly, irrelevant and noisy documents can actually help drive up accuracy if placed correctly.
We need more systematic studies around RAG. The hard part of a RAG system is typically the retriever component. Just dumping relevant docs into the context is not an effective approach but it's what a lot of LLM devs do.
I like that the Ragas library proposes the use of several metrics for assessing a RAG system at both the generation and retrieval stages, including an end-to-end evaluation. It's a good first step but we still need better ways to integrate external information that can be effectively leveraged by the generative component.

10
180
883
88,906
Cesare Campagnano retweeted

23 Jul 2023
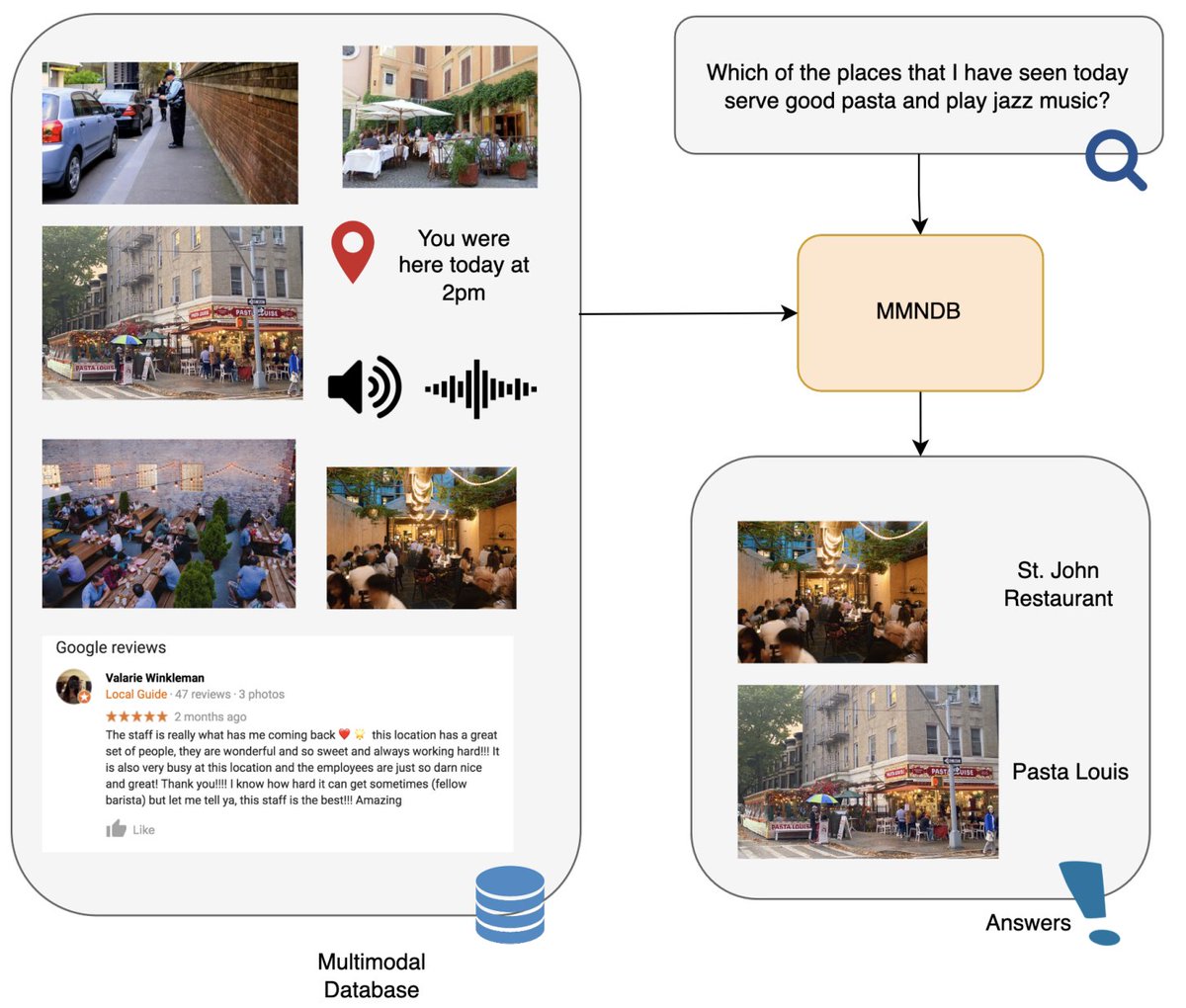
Still can't handle the indecisiveness between Barbie and Oppenheimer? 😫💥 Don't fret!
Come to the presentation of our new perspective paper, "Multimodal Neural Databases", where we lay out the vision for database-like queries on multimodal data.
Tomorrow @SIGIR2023, 1.30pm GMT 8
1
5
21
2,710
Cesare Campagnano retweeted

24 May 2023
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
Paper: arxiv.org/abs/2305.14314
Code Demo: github.com/artidoro/qlora
Samples: colab.research.google.com/dr…
Colab: colab.research.google.com/dr…

81
901
3,622
1,631,722
Cesare Campagnano retweeted

22 May 2023
LIMA :
LLaMA 65B 1000 supervised samples = {GPT4, Bard} level performance.
From @MetaAI
arxiv.org/abs/2305.11206
75
429
2,766
628,951
Cesare Campagnano retweeted
22 May 2023
MMS: Massively Multilingual Speech.
- Can do speech2text and text speech in 1100 languages.
- Can recognize 4000 spoken languages.
- Code and models available under the CC-BY-NC 4.0 license.
- half the word error rate of Whisper.
Code Models: github.com/facebookresearch/…
Paper: scontent-lga3-2.xx.fbcdn.net…
Blog: ai.facebook.com/blog/multili…
160
1,090
5,206
1,568,134
Cesare Campagnano retweeted

8 Apr 2023
Presentiamo il più grande LLM italiano realizzato dal gruppo di ricerca RSTLess della Sapienza Università di Roma.
Il team di ricerca dietro Fauno comprende @Andrea_Bacciu, @GioTrappolini, Prof @EmanueleRodola , @teelinsan e il Prof @fabreetseo .
github.com/RSTLess-research/…
1
15
43
8,672
Cesare Campagnano retweeted

15 Sep 2022
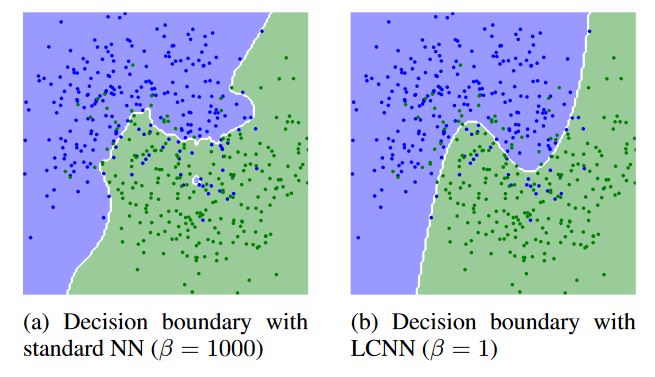
Three papers accepted at NeurIPS'22 (!!)
1) Efficiently training low-curvature neural networks (arxiv.org/abs/2206.07144), w/ Kyle Matoba, @hima_lakkaraju, @francoisfleuret
We propose to build NNs that are "as linear as possible", and thus eliminate excess model curvature.
5
34
218
Cesare Campagnano retweeted

15 Sep 2022
YouTube is free education.
But 99% don’t know the best spots on its virtual campus.
Here are the top channels to accelerate your learning:
1,579
48,202
232,382
Cesare Campagnano retweeted

7 Jul 2022
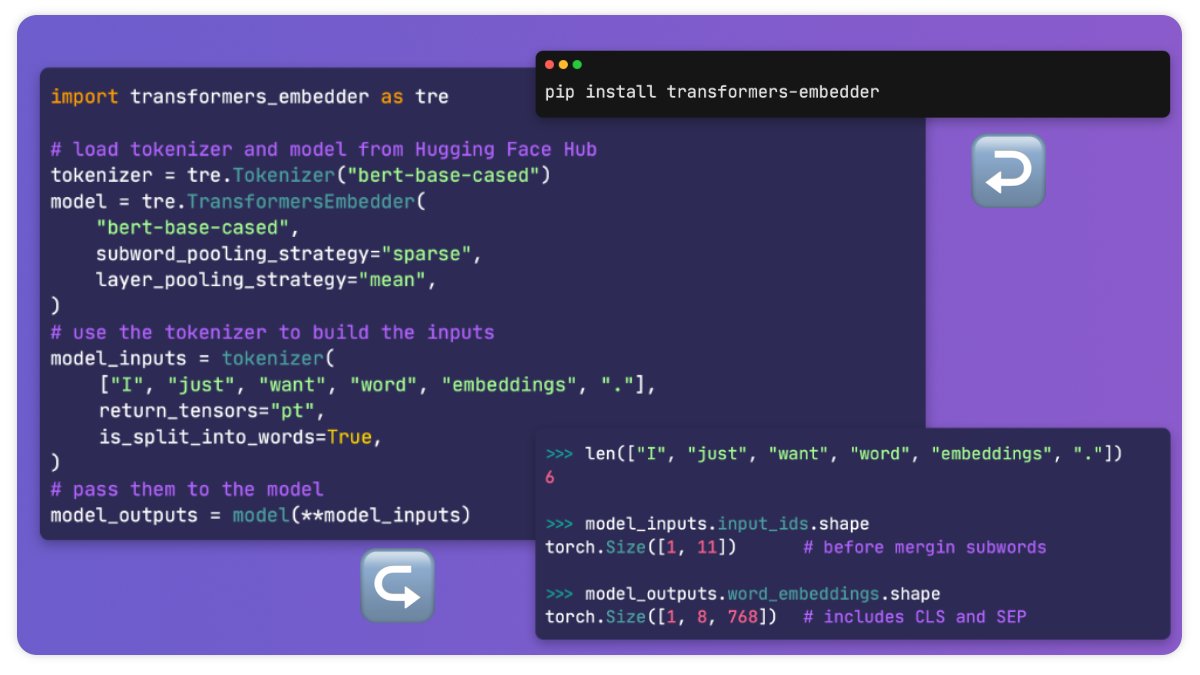
Hey #NLProc, I built this little tool to make working with @huggingface 🤗Transformers a bit easier. If you want to directly access whole-word embeddings hassle-free, give it a try!
👉GitHub: github.com/Riccorl/transform…
9
22
Cesare Campagnano retweeted

2 Jul 2022
This week @Google researchers announced Minerva, an internally developed project that can answer mathematical questions and tackle other complex topics such as physics.
1/5

18
357
1,887
Cesare Campagnano retweeted

1 Jul 2022
BTW.... dalle-mega from @borisdayma is now openly accessible on @huggingface
⚡️ To download it (10GB): git clone huggingface.co/dalle-mini/da…

23
177
1,328
Cesare Campagnano retweeted

25 May 2022
Presenting in front of a live audience was an amazing experience :) hope we nailed it! Thanks @aclmeeting
25 May 2022

#acl2022 nlp Best Resource Paper
DiBiMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation
(Niccolò Campolungo, Federico Martelli, Francesco Saina and Roberto Navigli)
#acl2022 #NLProc

1
14