




May 27
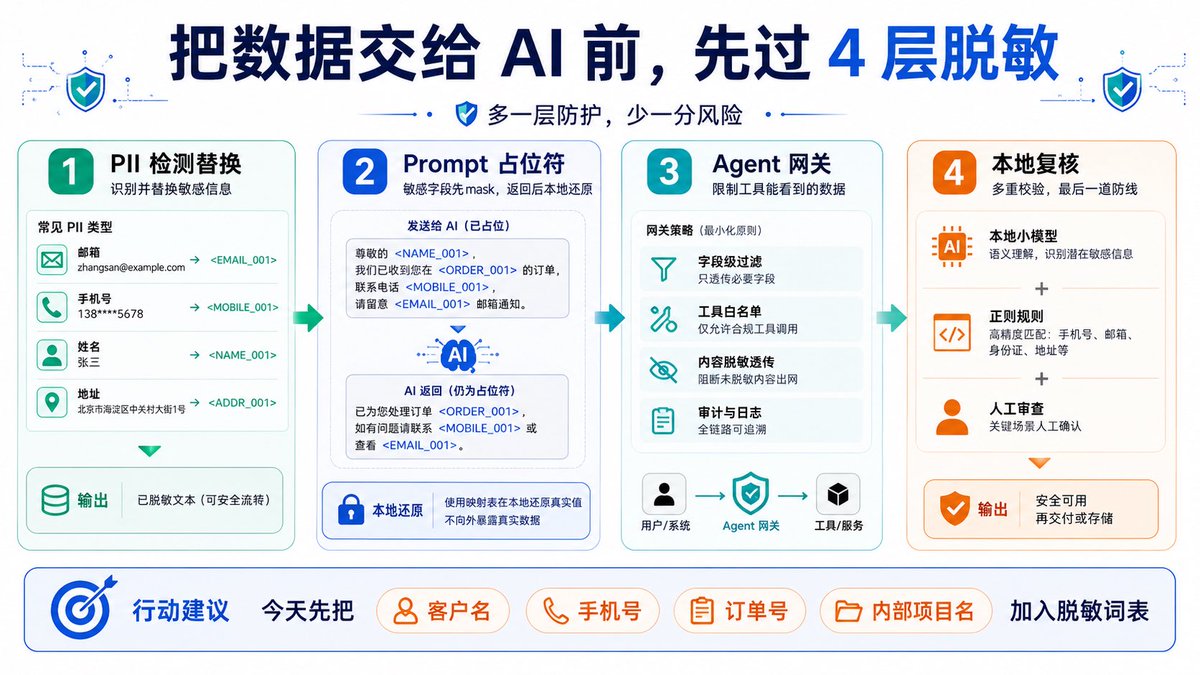
把资料丢给 AI 之前,先脱敏。这个习惯以后会越来越重要。
现在Codex或者其他Agent工具是方便了,但是很多人现在直接把客户记录、聊天截图、合同片段、日志、表格扔给 ChatGPT / Claude / Agent,让它总结、改写、分析。
问题是:你以为只是问一次,实际可能进了日志、插件、中间层、第三方工具调用链。
这里有几个脱敏建议:
1. 先替换明显敏感信息
邮箱、手机号、姓名、地址、身份证、订单号……
能替换的先替换。
(OpenPipe/pii-redaction 这类工具就是干这个的)
2. Prompt 里别直接放真实数据
比如把“腾讯”改成 {公司A},
把“张三”改成 {客户B}。
AI 返回后,再本地替换回来。
(PromptMask 就是这种思路)
3.给 Agent 加一道“数据网关”
不是每个工具都能看到原始数据。
只给它“完成任务必须的数据”。
有点像 AI 世界里的权限系统 / 防火墙。
4. 重要内容别全自动
最后再过一遍:
本地小模型 正则规则 人工检查。
慢一点,但安全很多。
2
1
7
830


May 22
あ、吉原さんAIMO3出てたんですねー。私もOpenPipe ART試してみたくてちょっとだけsubmitしましたが同じく41.5点でした。ぶっちゃけGPT-OSS-120Bの完成度が高過ぎてあまり出来ることがなかったです。性能もそうですが、コンパクトなactive parameter数、MXFP4ネイティヴと速度とも高い次元で両立していてさすがOpenAI謹製だなぁと感心しました。 #関西Kaggler会
1
6
634

May 22
🥳 Karpathy's RL bottleneck prediction just got solved.
RULER. Natural language reward functions. 10,000 GitHub stars.
RL was always bottlenecked by reward engineering. GRPO fixed it for math and code, binary signals are easy. But for real agent tasks, someone still hand-codes the scoring function. Days of work. Breaks on every pipeline change.
→ RULER lets you define reward criteria in plain English
→ An LLM evaluates each agent trajectory against that spec
→ No custom scoring code, no fragile functions
→ Plugs directly into GRPO training via OpenPipe ART
Karpathy said a single reward number is too low dimensional for complex tasks. RULER replaces that number with an LLM-as-judge. Higher-dimensional feedback, zero hand-coding.
RLHF replaced manual rankings. GRPO replaced the critic model. Natural language rewards are replacing hand-coded scoring functions.
RL reward engineering is now prompt engineering.
100% Open Source. github.com/OpenPipe/ART
#RL #LLM #AI #OpenSource

2
11
24
1,291

May 21
One thing I have noticed is that while natural language has ease of use, there's also reward hacking risk.
OpenPipe shared an example where they trained a model to write Hacker News headlines and it learned to always title stories like "Google to lay off 80% of workforce" because that maximized the score.
NL reward definitions are easier to write, but they still need careful rubric design. Yes, the iteration loop is much faster now.
9
2,597

May 21
Karpathy's prediction about RL is coming true now!
He called reward functions unreliable and argued that a single reward number is too low-dimensional to teach an agent what "good" means for complex tasks. To solve this, Agents need a knowledge-guided review as a higher-dimensional feedback channel.
Every major AI lab trains models with RL today (OpenAI, Anthropic, DeepSeek).
And their key bottleneck has always been the reward functions.
GRPO by DeepSeek worked well for math and code because the environment gave a binary signal.
But for real agent tasks, someone still has to hand-code the scoring function. That takes days and breaks every time the pipeline changes.
RULER (implemented in OpenPipe ART, 10k stars) addresses the exact problem Karpathy identified.
The reward criteria are defined in plain English, and an LLM evaluates each trajectory against that description to provide feedback for training.
I trained a Qwen3 1.4B agent that plays 2048 using GRPO with this exact workflow.
In this case, the agent saw the board, picked a direction, and RULER evaluated the outcome, all from this natural language definition.
You can see the full implementation on GitHub and try it yourself.
Here's the ART Repo: github.com/OpenPipe/ART
(don't forget to star it ⭐ )
Just like RLHF replaced manual rankings and GRPO replaced the critic model, natural language rewards are replacing hand-coded scoring functions.
RL reward engineering is now prompt engineering.
I wrote a full walkthrough covering RL for LLM agents, from RLHF to GRPO to RULER, in the article below.

57
187
1,609
348,123

May 16
16 best GitHub repos to build AI engineering projects!
(star bookmark them):
The open-source AI ecosystem has 4.3M repos now.
New repos blow up every month, and the tools developers build with today look nothing like what we had a year ago.
I put together a visual covering the 16 repos that make up the modern AI developer toolkit right now.
The goal was to cover key layers of the stack:
1) OpenClaw
↳ Personal AI agent that runs on your devices and connects to 50 messaging platforms
2) AutoGPT
↳ Platform for building, deploying, and running autonomous AI agents
3) Hugging Face Transformers
↳ The model framework for state-of-the-art ML across text, vision, audio, and multimodal
4) Ollama
↳ Run powerful LLMs locally on your hardware with a single command
5) LangChain
↳ The foundational framework for building agents and LLM-powered applications
6) Open WebUI
↳ Self-hosted, offline-capable ChatGPT alternative with built-in RAG and plugin system
7) ComfyUI
↳ Node-based visual workflow builder for AI image and video generation
8) Sim
↳ Open-source drag-and-drop workflow builder for creating and deploying AI agent pipelines
9) Opik
↳ Open-source platform to trace, evaluate, and monitor LLM apps and agentic workflows
10) Firecrawl
↳ Turn any website into LLM-ready markdown or structured data
11) Airweave
↳ Open-source context retrieval layer that syncs 50 data sources for AI agents
12) vLLM
↳ High-throughput, memory-efficient LLM serving engine for production deployments
13) Unsloth
↳ Fine-tune and run open models 2x faster with 70% less memory
14) OpenPipe ART
↳ Train multi-step AI agents for real-world tasks using reinforcement learning
15) OpenCode
↳ Open-source, provider-agnostic AI coding agent built for the terminal
16) Chandra OCR (by Datalab)
↳ State-of-the-art OCR model for complex tables, forms, handwriting, and 90 languages
These aren't just repos with high star counts but rather the building blocks behind most AI products shipping today.
If you're building anything with LLMs, agents, or RAG in 2026, you're probably already using a few of these.
P.S. This visual was inspired by a similar one from the ByteByteGo team. I extended it to be more engineering and builder-focused.

The AI industry has a dirty little secret:
Half of “AI engineering” is just fighting CUDA errors.
Wrong PyTorch wheels.
Broken NVIDIA drivers.
Mismatched CUDA versions.
Dependency hell that destroys your entire environment overnight.
Meanwhile you’re sitting there wondering why your GPU suddenly stopped existing.
This open-source project fixes that chaos in one command.
It scans your entire AI stack:
GPU → CUDA → cuDNN → PyTorch → TensorFlow → Docker
Then tells you exactly what’s broken and how to fix it.
Honestly one of the most useful AI dev tools I’ve seen this year.
github.com/mitulgarg/env-doc…

3
5
26
1,865
May 3
LeRobot と OpenPipe ART を接続し、Physical AI 向けに trajectory-level GRPO/GSPO を扱えるようにする実験的 fork「ART-Embodied」を作成中です。
既存の LeRobot workflow をなるべく崩さず、trajectory 全体の報酬・logprob・動画・W&B/Weave trace を扱える基盤を目指しています。
github.com/nejumi/ART-Embodi…
#wandb #LeRobot #PhysicalAI
1
7
35
3,068

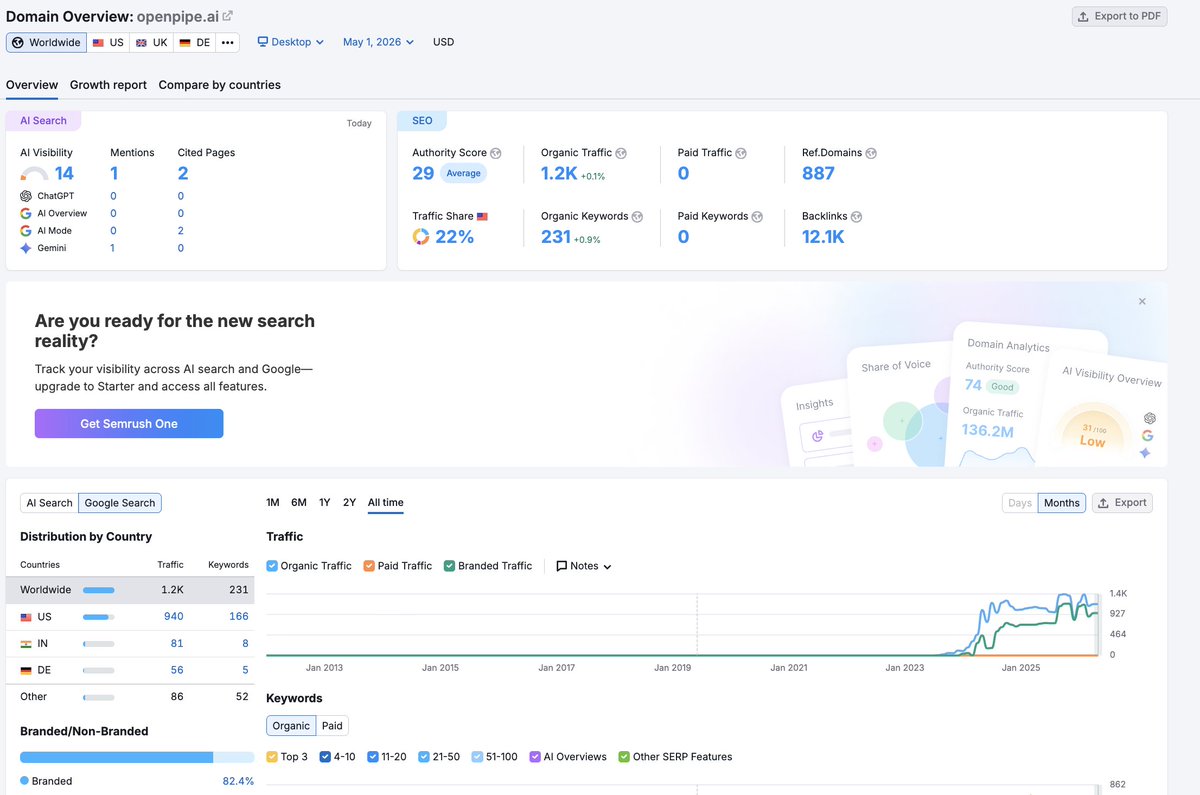
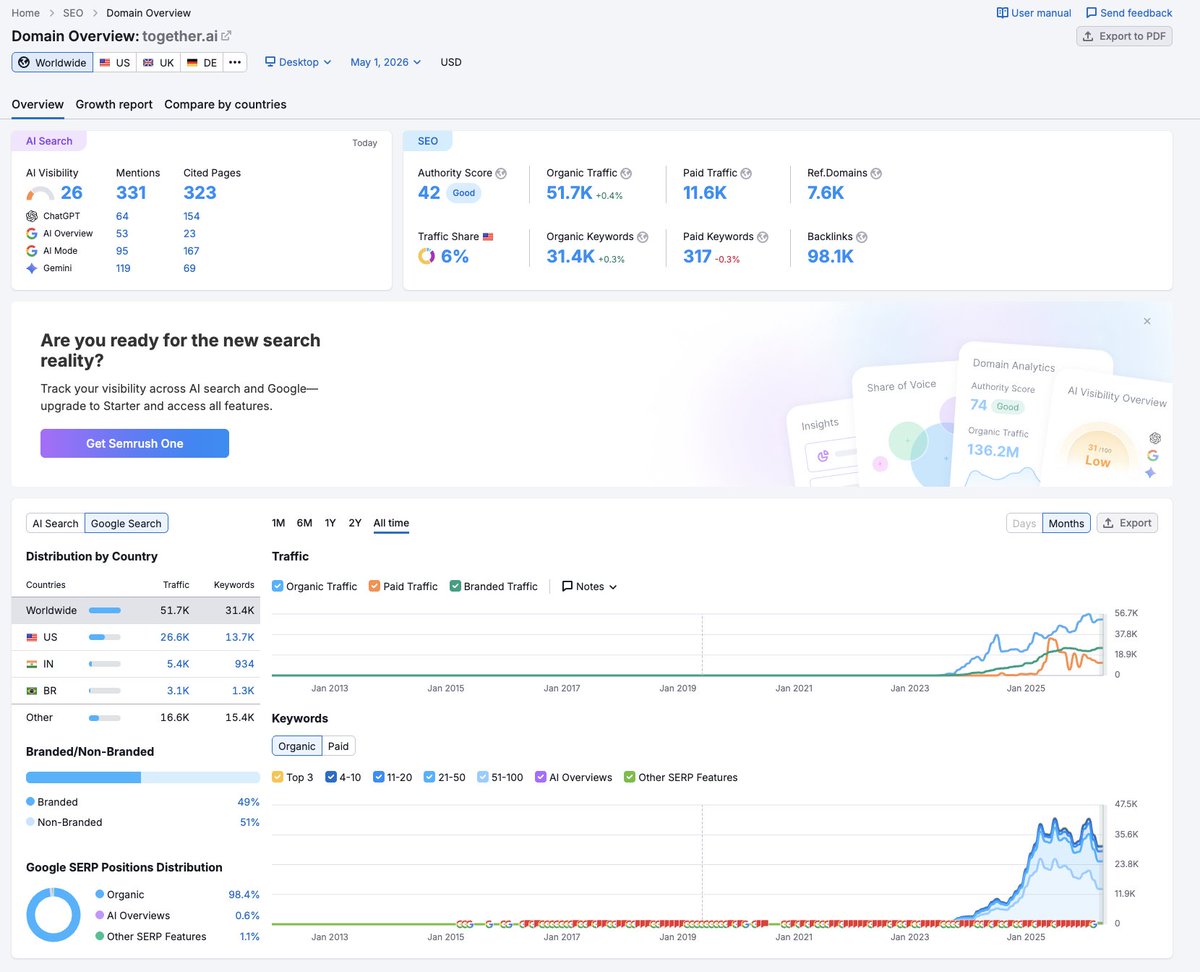
I think model distillation becomes an aggressive part of the future stack of developers.
OpenPipe — openpipe.ai
distil labs — distillabs.ai
Predibase — predibase.com
Lamini — lamini.ai
Together AI — together.ai
Fireworks AI — fireworks.ai
Arcee AI — arcee.ai

2
2
426

CoreWeave $CRWV 주주 서한
$NVDA, $NBIS, $IREN, $BE, $APLD, $ORCL
CoreWeave & Meta: 210억 달러 규모 AI 인프라 파트너십 및 2025년 성과
CoreWeave의 CEO 마이클 인트레이터(Michael Intrator)는 2025년 연례 보고서를 통해 회사가 'AI를 위한 필수 클라우드(The Essential Cloud for AI™)'로 자리 잡았음을 선언했습니다.
1. 주요 재무 및 사업 성과 (2025년 회계연도)
역대급 매출 성장: 연간 매출 50억 달러($5B)를 달성하며 클라우드 플랫폼 역사상 가장 빠른 성장세를 기록했습니다. (전년 대비 168% 성장)
수주 잔고(Backlog) 폭증: 2025년 초 150억 달러였던 수주 잔고가 668억 달러($66.8B)로 크게 늘어났습니다.
고객 다변화: 특정 고객에 대한 의존도를 낮추고(최대 고객 비중 85% → 35%), 10대 주요 AI 모델 개발사 중 9곳을 고객으로 확보했습니다.
자본 효율성: 약 180억 달러의 자본을 조달하면서도 부채 조달 비용을 300bp(3%) 이상 낮추어 연간 7억 달러의 비용을 절감했습니다.
2. 기술력 및 인프라 확장
글로벌 발자국: 현재 43개 데이터 센터에서 850MW 이상의 전력을 운용 중입니다.
하드웨어 선점: NVIDIA의 차세대 칩인 GB200 및 GB300을 시장에 가장 먼저 도입했으며, 업계 최초로 'GB200 엑셈플러(Exemplar) 클라우드' 지위를 획득했습니다.
전략적 인수합병(M&A): Weights & Biases: 모델 개발 및 평가 역량 강화.
OpenPipe: 강화 학습(RL) 및 에이전트형 워크로드 최적화.
플랫폼 고도화: AI 워크로드 벤치마킹 툴인 'CoreWeave ARENA™'와 운영 표준인 'Mission Control™'을 출시했습니다.
3. 미래 비전: 2030년을 향한 로드맵
인프라 확장: 2030년까지 5GW 이상의 용량을 추가하여 총 8GW 이상의 활성 전력을 확보할 계획입니다.
추론(Inference)의 시대: 모델 학습을 넘어, 경제적 수익을 창출하는 '추론'과 '에이전트형(Agentic) 워크로드'가 다음 성장의 핵심이 될 것으로 전망합니다.
지역 사회 상생: 데이터 센터 건립 시 지역 유틸리티 및 규제 당국과 협력하여 일자리 창출 및 세수 증대에 기여하는 지속 가능한 모델을 지향합니다.
"AI는 더 이상 미래에 대한 도박이 아니라, 현재 그 자체입니다."
"우리는 클라우드를 처음부터 다시 정의했습니다. 일반적인 목적으로 설계된 기존 클라우드와 달리, CoreWeave는 AI에 필수적인 대규모 병렬 계산을 지원하기 위해 탄생했습니다. 한때 우리의 무모함을 의심하던 이들도 있었지만, 이제 우리는 세계에서 가장 정교한 빌더들이 신뢰하는 파트너가 되었습니다."
"우리는 이제 막 시작했을 뿐입니다."
"단순히 회사를 세우는 것은 드문 일이지만, 세상에 중요한 영향을 미치는 회사를 세우는 것은 더욱 드문 일입니다. CoreWeave는 AI 시대의 '힘의 승수(Force Multiplier)'가 되어 고객의 야망을 현실로 만들 것입니다."
1
1
9
1,174

Apr 22
인공지능 인프라 전문 기업 코어위브가 2025 회계연도에 기록적인 성장을 달성하며 글로벌 AI 컴퓨팅 시장의 선두 주자로 입지를 굳혔습니다.
코어위브는 지난해 전년 대비 168% 급증한 51억 달러의 매출을 기록했으며, 업계를 주도하는 9개의 주요 모델 제공업체 모두가 코어위브 클라우드를 채택하며 기술력을 증명했습니다.
현재 43개의 데이터 센터에서 850MW 이상의 전력을 운영 중인 코어위브는 탄탄한 시장 신뢰를 바탕으로 평균 계약 기간 5년에 달하는 668억 달러 규모의 잔여 이행 의무를 확보했습니다.
재무 구조 면에서도 약 180억 달러의 부채 및 지분 자본을 조달하는 동시에 부채 비용을 300bp 이상 절감하며 운영 효율성을 높였습니다.
나아가 웨이츠 앤 바이어스(Weights & Biases), 오픈파이프(OpenPipe), 모놀리스 AI(Monolith AI) 등의 전략적 인수를 통해 AI 최적화 플랫폼 역량을 한층 강화한 코어위브는 2030년까지 8기가와트 이상의 데이터 센터 용량을 추가로 확충하여 장기적인 성장세를 이어갈 전망입니다. $CRWV

Apr 22

오라클을 비롯한 네오 클라우드의 ROI 이슈는 사실상 해소된 것으로 보입니다. 이런 흐름을 보면, 마이클 버리는 사실상 머저리라는 결론에 이르게 됩니다. $ORCL, $CRWV, $NBIS, $IREN

1
2
602