
Jun 13
6/ CTOs and Ops Leaders, audit your AI spend. Ask which tools make humans faster versus which eliminate work completely. Reallocate budget toward custom operational automation that compounds. #EnterpriseAI #Automation #OperationalAI
7

AI isn't just a chatbot.
It’s your hardest-working employee.
We build custom workflows that automate the grind and save you hours.
Real utility. Zero fluff.
Let’s work.
Until next time, Stef
#OperationalAI #Scale #Efficiency #5FTView
6

Most manufacturing finance problems are not caused by missing data.
They are caused by slow operational understanding.
Finance sees the variance.
Operations sees the disruption.
Engineering sees the process issue.
But connecting those signals still takes days.
So organizations spend more time reconstructing causality than acting on it.
Operational AI changes that.
Not by generating more reports.
By connecting financial outcomes directly to operational context.
So a margin decline stops being just a number.
It becomes traceable instantly:
• Which asset changed
• Which shift was affected
• Which process drift occurred
• Which material issue created the impact
The next generation of manufacturing finance advantage may not come from better reporting.
It may come from reducing the time between economic signal and operational action.
#Manufacturing #ManufacturingFinance #OperationalAI #IndustrialAI #SmartManufacturing #Industry40 #OperationalExcellence #FinanceTransformation #DigitalTransformation #FactoryOperations #ManufacturingLeadership #DecisionIntelligence

6

Growth doesn't always create a technology problem—it often creates a workflow problem.
This healthcare client improved responsiveness by unifying intake, CRM, and operational workflows.
See how operational AI drives efficiency. sigma-infosolutions.shp.so/l…
#OperationalAI
6

Jun 11
SWARM Engineering Raises $10M Series A
#DecisionIntelligence #AgriFood #Manufacturing
#OperationalAI #SupplyChain #AgenticAI #EnterpriseAI #SeriesA #Funding #SWARMEngineering
thesaasnews.com/news/swarm-e…
14
Most workforce systems track activity.
Very few explain operational impact.
HR systems can tell you:
• Who worked
• Who completed training
• Who reports to whom
• Who has the certification
But they rarely explain:
• Which operators improve yield
• Which expertise reduces downtime
• Which training changes production outcomes
• Which workforce gaps create operational risk
So manufacturers still rely on proxies like tenure, titles, and supervisor observations.
Not because they lack workforce data.
Because workforce systems were never designed to connect people with operational performance.
Operational AI changes that.
Not by monitoring employees more aggressively.
By identifying which human capabilities consistently influence operational outcomes.
The next workforce advantage in manufacturing may not come from hiring more people.
It may come from understanding which expertise actually drives plant performance — and scaling it systematically.
#Manufacturing #IndustrialAI #OperationalAI #SmartManufacturing #Industry40 #DigitalTransformation #ManufacturingLeadership #FactoryOperations #FutureOfWork #OperationalExcellence #IndustrialTransformation

4

Deploy trained models directly into workflows to automate decisions.
#OperationalAI #Automation (1/1)

1
4

Jun 9
Chatbots answered questions. Copilots helped people work faster.
One of the most important ideas behind Cairo Conscious Harness is software-first intelligence. Most AI systems default to more tokens, bigger models, and larger context windows.
Cairo is being built around a different philosophy:
Use software first.
Use workflows first.
Use memory first.
Use structured data first.
Use local models first.
Escalate to frontier models only when needed. That is how AI becomes more efficient, reliable, and scalable.
Better systems > bigger models.
Do you think AI teams are too focused on model size?
hashtag#SoftwareFirstAI hashtag#CairoAI hashtag#AIInfrastructure hashtag#OperationalAI
1

As enterprises move beyond AI experimentation, a new challenge is emerging: turning successful pilots into solutions that employees use, business teams trust, and organisations can scale. While technical capability remains essential, sustained value increasingly depends on adoption, governance, workflow integration, and measurable outcomes. As GCCs take on larger mandates across innovation, product ownership, and enterprise transformation, AI product management is gaining relevance as the bridge between technology and business impact. The next phase of AI maturity may not be defined by the number of models built, but by the ability to operationalize AI at scale and translate capability into lasting business value.
Read More: etedge-insights.com/gcc/why-…
#ETEdgeInsights #TransformationSeries #AIProductManagement #OperationalAI #EnterpriseTransformation #AIAtScale #ProductOwnership #GCCLeadership

1
17
Jun 8
AI should not only complete a task.
It should know:
what changed
what failed
what needs review
what should happen next
what should be remembered
That is the Cairo Conscious Harness direction.
#AIHarness #FutureOfWork #OperationalAI
cairo.colomboai.com
1
3
Jun 8
Long AI tasks break because context gets bloated and reasoning gets stale.
Cairo’s Chain Swarm Intelligence approach is different:
New swarm generations inherit the goal, memory, learning, and execution state.
Then keep going cleaner.
#LongHorizonAI #AIAgents #OperationalAI
cairo.colomboai.com

2
Jun 8
Chatbots answered.
Copilots assisted.
Agents acted.
Harnesses managed.
Cairo Conscious Harness is being built for the next stage:
AI that operates.
Operational Consciousness Infrastructure for the agentic era.
#CairoAI #ConsciousAI #OperationalAI
cairo.colomboai.com

3
Jun 3
Unpopular opinion:
The most valuable AI use cases are not always the flashy ones.
Sometimes it’s just:
“Please keep track of this.”
“Please update the record.”
“Please remind the right person.”
“Please make sure the next step happens.”
That’s real business value.
#OperationalAI #AIForWork
1
2
7

AI creates value when it runs real business workflows — securely, reliably, and at scale. Codvo.ai helps enterprises move from AI pilots to production-grade operational systems.
#EnterpriseAI #AgenticAI #OperationalAI #CodvoAI @Codvo2

1
2
12

May 27
The shift happening in insurance right now is not about
chatbots or copilots.
It's about agents that execute full workflows end-to-end without a human in the loop for every step.
65% of insurers are deploying scaled AI agents for claims in 2026.
The ones who move first will define the decade. #MGARenewal #AIinInsurance #OperationalAI #GenerativeAI #FutureOfInsurance
1
1
2
72

May 22
People keep asking whether their AI tool is "accurate enough" to deploy. That's the wrong question. The question is whether you can tell when it's wrong.
Here's the distinction that matters: verification cost versus error rate.
An AI that's wrong 5% of the time but whose failures are obvious costs you far less than one that's wrong 2% of the time but whose failures are invisible.
I see this play out constantly. A team evaluates a summarization model. It gets 97% of facts right. They approve it. Six months later, a client catches a subtle misattribution — the model said "the CFO noted" when the original said "the CFO was asked about." Different verb, different agency, different meaning. Nobody caught it in review because it read smoothly.
That's the real cost structure: not how often the model is wrong, but how much effort it takes to notice when it is.
This is why the "human in the loop" conversation is mostly broken. It treats human review as a checkbox rather than designing for what human review actually requires: salient signals that something might be off.
Consider two deployment scenarios:
Scenario A: A legal team uses AI to extract contract clauses. The model highlights every clause it extracted with medium confidence in yellow. Reviewers know exactly where to look. Error rate: 8%. Time to verify: 12 minutes per contract.
Scenario B: A legal team uses a more accurate model that presents all clauses with equal confidence. No highlighting. Everything looks equally certain. Error rate: 3%. Time to verify: 45 minutes per contract, because the reviewer has to re-read everything to find the quiet failures.
Scenario A wins on total cost. Not because it's more accurate. Because it makes verification cheaper.
The architecture of a good AI deployment decision isn't "pick the lowest error rate." It's "minimize the product of error rate × verification cost × consequence of missed errors." Three variables, not one. Most teams only optimize the first.
This reframes the build-vs-buy question too. A vendor model with higher error rates but better explainability and confidence calibration often beats a fine-tuned model with lower error rates and opaque outputs. Not because the vendor model is better. Because the total cost of running it in production is lower.
The teams I've seen succeed with AI deployments share one trait: they spend as much time designing the verification surface as they do evaluating the model. They ask: "When this fails, will we know? How quickly? What makes a failure visible versus silent?"
They treat confidence scores not as accuracy metrics but as triage signals. They build review workflows around uncertainty, not around tasks. They'd rather have a model that says "I'm not sure about this one" than one that's slightly more accurate but equally confident about everything.
The operational insight: accuracy is a model property. Verifiability is a system property. You design the system. The model gives you one input. If your deployment decision stops at the model's accuracy number, you've made the most common and most expensive mistake in AI operations — you've confused what you can measure with what actually matters.
The reframe: don't ask "how often is this wrong?" Ask "when this is wrong, how much does it cost me to find out?"
#OperationalAI #AIDeployment #VerificationCost
1
2
65
May 22
Most businesses deploying AI hit a wall at exactly three production agents. Not one, not two — three. That's the threshold where the architecture that got you from zero to functional becomes the architecture that prevents you from going further. And almost nobody talks about it because the people writing about AI adoption have never run three agents in production at the same time.
Here's what actually happens. Your first AI agent is a customer service chatbot. It works. It deflects 40% of tickets. The ROI is clear, the metrics are clean, and your board wants you to "scale AI across the organization." So you deploy agent two — maybe a content generation pipeline, maybe a sales research assistant. It also works. The metrics are good in isolation. You feel momentum.
Then you deploy agent three. And everything breaks. Not the models — the *system*.
What breaks is the orchestration layer. Your agents start producing conflicting outputs. The content agent references information the customer service agent gave a different answer about yesterday. The sales assistant pulls data that the content agent reformatted into a different schema. Your single sign-on works for the humans, but your agents authenticate to APIs with different token lifecycles, and now you have three separate failure modes that your monitoring doesn't catch because you're monitoring model latency, not orchestration integrity.
Nobody told you this because the AI deployment narrative is "start small, prove value, scale." That narrative assumes that scaling means more volume of the same thing. It doesn't. Scaling AI agents means moving from independent tools to an interdependent system, and interdependent systems have fundamentally different failure modes.
The specific threshold is three because of a property of distributed systems that engineers know well but business strategists don't: the number of potential interaction paths between N nodes grows as N(N-1)/2. One agent: zero interaction paths. Two agents: one path, manageable. Three agents: three paths, and now you have a triangle of dependencies where a failure in any edge affects the whole shape. This isn't theoretical — it's the same reason three-server microservice architectures are notoriously fragile before you invest in proper service meshes.
I've seen this play out operationally. A mid-market SaaS company I worked with had two clean AI wins — a support triage agent and a meeting summarizer. Both delivered measurable value. When they added a third agent for automated proposal drafting, the proposal agent started pulling pricing data that the support agent had already corrected in the knowledge base but that hadn't synced to the proposal agent's context window. Proposals went out with wrong pricing. The fix wasn't "better prompts" — it was building a shared context layer, a real-time state synchronization system, and conflict resolution protocols between agents. In other words, the third agent didn't cost one agent's worth of engineering. It cost the equivalent of building infrastructure for an entire agent ecosystem.
This is the operational insight that separates companies that scale AI from those that plateau: you don't budget for agents, you budget for the orchestration layer. The agent itself — the prompt, the model, the API — is maybe 20% of the total cost of ownership at scale. The other 80% is the plumbing: shared context, state management, conflict resolution, observability, fallback routing, and the governance framework that decides which agent speaks for the company when answers diverge.
Most AI budgets allocate exactly backwards. They fund the 20% that's visible and demo-able and leave the 80% that actually makes the system work as an afterthought. Then they wonder why their third deployment feels like a step backward.
The companies getting AI right at scale didn't start by picking use cases. They started by investing in the orchestration infrastructure — the shared context layer, the agent communication protocols, the unified observability stack — before they needed it. That sounds like over-engineering when you have one agent. It looks like genius when you have five, because you're not rebuilding your architecture every time you add a node.
So here's the reframe: the question isn't "which AI use case should we deploy next?" The question is "are we building toward a system where the next agent is cheaper to deploy than the last one, or more expensive?" If the answer is more expensive, you've hit the three-agent wall without realizing it, and your architecture is already working against you. The fix isn't better agents. It's better infrastructure.
#AIBusinessStrategy #AgentOrchestration #OperationalAI
1
3
87

May 11
𝗔𝗜 𝗮𝗴𝗲𝗻𝘁𝘀 𝗻𝗲𝗲𝗱 𝗷𝗼𝗯 𝗱𝗲𝘀𝗰𝗿𝗶𝗽𝘁𝗶𝗼𝗻𝘀
AI agents should not be treated as vague “do everything” assistants.
In enterprise workflows, role clarity matters.
- What is the agent responsible for?
- What systems can it access?
- When does it escalate?
- Who reviews its work?
- How is success measured?
AI-Harness helps teams define role-based AI agents with clear responsibilities, permissions, review paths, and accountability inside governed workflows.
Because the more important the work, the clearer the role needs to be.
#EnterpriseAI #AIGovernance #AIAgents #AIWorkflows #HumanInTheLoop #AIWorkforce #WorkflowAutomation #OperationalAI #AIAdoption #EnterpriseAutomation #ResponsibleAI #RiskManagement #AICompliance #AIOperations #OperationalExcellence #AIAnalytics #OutcomeTelemetry #FutureOfWork #HumanAI #AIExecution #AIHarness

4
33

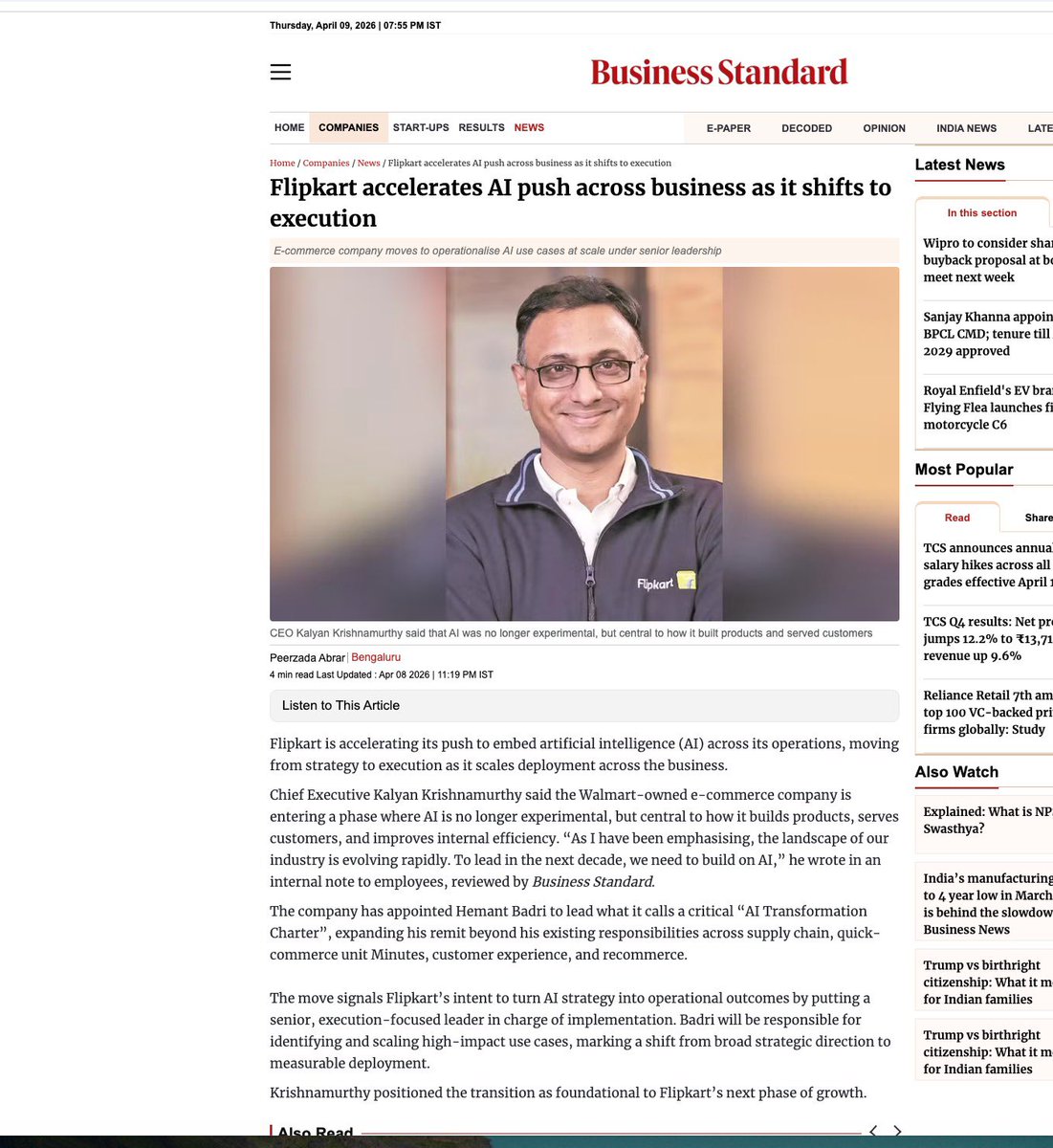
Is India’s e-commerce market entering the phase where execution will matter more than capability?
@Flipkart just drew a line in the sand for Indian e-commerce, and that line runs straight through the difference between having AI and deploying it at population scale.
CEO Kalyan Krishnamurthy was clear: AI at Flipkart has moved past the experimental phase. Intelligent systems now sit at the core of every product built, every customer served, and every internal process improved. This marks the shift from AI as a feature to AI as operational infrastructure.
That distinction creates compounding advantage. AI features get launched, while operational AI integration deepens. Every transaction makes the platform smarter, every seller interaction improves the next, and every logistics decision builds on the last. This is how platform resilience is built and how structural moats take shape over time.
India’s market is racing from $90 billion to $250 billion. Flipkart’s choice is clear, embed AI deeper across every layer at population scale and strengthen its long-term position. Watch how this plays out 🔥
#Flipkart #AIFirst #IndiaEcommerce #DigitalIndia #OperationalAI
business-standard.com/compan…
13
1
5
52,975

Mar 26
An AI can't go to jail, nor can it stand before a board to explain its reasoning.
This creates a real ceiling for adoption. The system can do the work, but it can't carry the consequences. So companies keep AI in low-stakes corners, where the risk of being unable to explain a decision stays manageable.
Moving AI into the core of your operations requires something most platforms don't offer: a clear line of sight from every action back to the data that drove it.
That's what Danny Lange gets into, and the thinking behind why Complexio is built the way it is.
#EnterpriseAI #Complexio #OperationalAI
1
2
40