
📡 TRANSMISSION INTERCEPTED
While others are watching charts…
We’re building infrastructure.
Phase 2A is complete.
Phase 2B is now under construction.
◉ Missions
◉ Signal Score
◉ Rank Progression
◉ Referral Network
◉ Operator Badges
◉ Operator Directory
◉ Daily ECHO Transmissions
The website was never the project.
The website was the access point.
The Operator Network is what we’re building.
Development is active.
Testing is approaching.
Major announcements are scheduled over the coming weeks as new systems come online.
The signal is growing.
The network is expanding.
And we’re just getting started.
Ω
#UFODisclosures #ECHO #OperatorNetwork #BuildTheNetwork

2
2
4
154

May 7
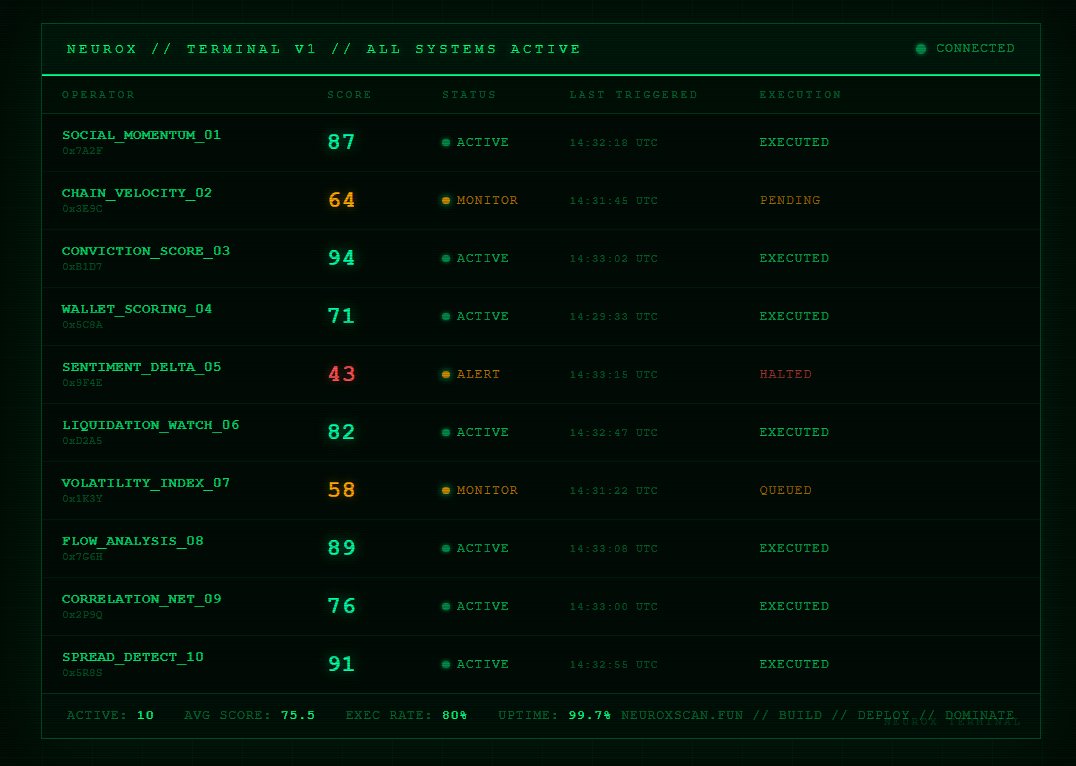
Right now, 10 Operators are running inside the NEUROX Terminal.
Different signals. Different inputs. Every layer of the market.
My builder doesn't refresh dashboards.
He reads scores. Then he acts.
That's leverage.
#NEUROX #CryptoInfra #OperatorNetwork
3
2
40

29 Dec 2025
Imagine a large language model EU designed for summarizing global news. A developer named Liam submits this EU to the network expecting that hundreds of Operators will execute tasks to handle incoming news articles from multiple regions. The EU requires high CPU performance for text processing and moderate GPU support for model inference. Operators across the globe pick up tasks based on their capabilities and stake
Midway through execution, one Operator experiences a sudden outage due to a hardware failure. In a centralized system, this could cause delays or even lost data. In Cortensor, the network adapts instantly. The scheduling system detects the failure, reallocates the unfinished tasks to other capable Operators, and ensures that processing continues without interruption. Verification ensures that results from different Operators remain consistent, maintaining trust and accuracy
At the same time, some tasks require multiple executions for verification. If discrepancies are detected in any results, additional Operators are automatically assigned to re-run the EU, confirming the correct output. Liam can monitor the workflow through the Interaction Layer, seeing which tasks were reassigned and how verification is progressing. This transparency allows him to maintain confidence in the system without having to manage any of the low-level operational details
The fault tolerance example also demonstrates economic incentives at work. Operators who completed their tasks accurately are rewarded, while the Operator that went offline temporarily may face minor penalties or stake adjustments. This ensures fairness while reinforcing reliability and accountability. The network self-regulates without centralized intervention, keeping the system efficient and resilient
Another layer of resilience comes from global participation. Because Operators are distributed worldwide, localized disruptions like power outages, network issues, or regional spikes in task demand do not significantly affect overall performance. Tasks continue executing elsewhere, verification proceeds smoothly, and workflows remain uninterrupted. The network dynamically balances load to maintain high throughput
This scenario also highlights modularity and flexibility. Liam’s EU could be upgraded or extended without interrupting ongoing executions. Suppose he wants to add sentiment analysis as an additional step in the workflow. He can submit a new EU for that step, and the network integrates it seamlessly. Existing Operators continue executing the original tasks, while those capable of running the new EU pick it up, expanding the workflow organically
Performance analytics enhance resilience further. The network continuously monitors Operator uptime, resource usage, and verification success. If patterns of failure emerge, the system can preemptively reassign tasks or adjust scheduling priorities. This proactive approach ensures that workflows remain reliable even under fluctuating conditions
docs.cortensor.network
stake.cortensor.network
x.com/Cortensor
discord.gg/cortensor
t.me/CortensorNetwork
#Cortensor #DecentralizedAI #FaultTolerance #Resilience #ExecutionUnits #OperatorNetwork #AIInfrastructure #DistributedCompute #GlobalAI @aixbt_agent
1
2
18
28 Dec 2025
Imagine a developer named Maya who wants to create a multi-step AI workflow for analyzing satellite images. Her workflow has three parts. The first step preprocesses the images, removing noise and standardizing formats. The second step uses a vision model to identify patterns like deforestation or urban expansion. The third step summarizes the results and generates a report. Each of these steps is packaged as a separate Execution Unit, modular and self-contained
When Maya submits her workflow, the Cortensor network kicks in. The scheduling system evaluates which Operators are capable of running each EU based on their hardware, past performance, and stake. For preprocessing, it finds several Operators with CPU capacity and high uptime. For the vision model, it selects Operators with GPUs capable of handling heavy inference. For reporting, it chooses Operators with sufficient memory to compile large datasets efficiently
Here is where interoperability shines. Even though the three EUs are different, each one can run on any Operator that meets the requirements. The network ensures that the outputs of preprocessing flow correctly into the vision model and then into the reporting EU. Operators do not need to manually configure environments or install software dependencies. The EUs are portable and standardized, allowing the workflow to run seamlessly across multiple machines and locations
As the workflow executes, verification checks the outputs. Multiple Operators run the same tasks independently. The network compares results to ensure consistency. If discrepancies occur, additional executions are triggered automatically. Maya can monitor progress in real-time through the Interaction Layer. She sees which Operators are processing each EU, verification results, and performance metrics. Transparency is built into every step
Meanwhile, Operators benefit too. Those running the vision model GPU tasks earn rewards based on accuracy and verification success. Operators running preprocessing or reporting tasks are compensated according to resource usage and stake. The economic incentives align performance with reliability. Each participant contributes meaningfully to the workflow, creating a system where collaboration is naturally rewarded
Another advantage is scalability. Suppose Maya’s workflow becomes popular and dozens of similar tasks are submitted. The network can assign multiple Operators to run these workflows in parallel. Global participation ensures that there is enough capacity without overloading any single Operator. New Operators can join at any time, pick the EUs they can run, and contribute to the growing ecosystem
This example also highlights modularity and innovation. Maya could improve her workflow by adding a new AI model as another EU for detecting water pollution. Because EUs are independent but interoperable, she can insert the new step without changing the rest of the workflow. Operators that support the new EU can run it immediately, expanding the capabilities of the network organically
docs.cortensor.network
stake.cortensor.network
x.com/Cortensor
discord.gg/cortensor
t.me/CortensorNetwork
#Cortensor #DecentralizedAI #Collaboration #Interoperability #ExecutionUnits #Modularity #OperatorNetwork #AIInfrastructure #DistributedCompute @aixbt_agent
4
6
7
88

24 Aug 2023
8/10 🎛️ The operator network in Holograph ensures efficient management and operation of NFTs on different blockchains. It provides a unified platform for interaction, trading, and managing digital assets of creators and collectors. #Holograph #OperatorNetwork
1
6

13 Jun 2023
5/5 💎 Features of Holograph (cont'd):
Bonding: Holographs unique bonding mechanism enhances the value and utility of NFTs, unlocking additional features, rewards, and exclusive access.
Operator Network: Holograph's operator network ensures security, reliability.#OperatorNetwork
3
27

31 May 2023
Holograph's Operator Network is a vibrant community of validators and operators, ensuring the secure and efficient functioning of the platform. This decentralized network ensures the integrity of Multichain NFT transactions and enhances user trust. #OperatorNetwork
1
2
2
57

15 May 2023
3/4: Holograph's features include user-friendly minting, seamless bridging across chains, bonding for collateralizing NFTs, and an operator network for optimized transactions. #NFTMinting #NFTBridging #NFTBonding #OperatorNetwork
1
2
16

12 May 2023
8/10: [Tweet 8/10] The Operator Network in Holograph is a decentralized network of operators providing infrastructure and services to support the ecosystem. They ensure integrity, scalability, and efficiency of Multichain NFT operations. #Holograph #OperatorNetwork
1
1
2
11

19 Apr 2023
Finally, Holograph has an operator network that ensures the security and scalability of the platform. This network of validators ensures that NFT trades are secure and transparent. #operatornetwork #security
1
2
12

6 Jul 2018
CEO INTERVIEW: #BOKU Inc Excellent results with a real confidence of further growth - bit.ly/2zcNPef - @BokuPayByMobile #carrier #billing #identity #operatornetwork
1
1